'''
思路:
定义一个函数,使用open函数,将文本内容打开。
定义一个空字典和空列表,进行循环及条件判断操作
'''
def count_word(file_path):dict_data = {} #定义一个空字典f = open(file_path,"r",encoding="UTF-8")list_data = f.read()list_data = list_data.split() #默认是空格为分隔符for i in list_data:if i in dict_data:dict_data[i] += 1else:dict_data[i] = 1f.close()while True:word = input("please input your word(input 'q' or 'Q'):")if word == 'Q' or word == 'q':print("Bye~")breakif dict_data.get(word) == None:print(f"{word}'s count is 0")breakelse:print(f"{word}'s count is {dict_data.get(word)}")count_word("C:/1.txt")
效果图:
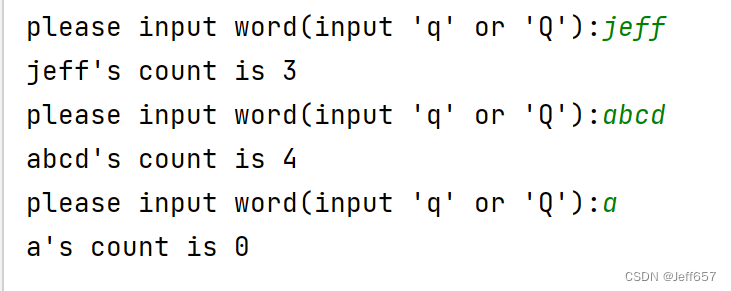
利用PySpark第三方库,进行统计(人机交互暂未编写):
# 1.构建执行环境入口对象
from pyspark import SparkContext,SparkConf
import os
os.environ['PYSPARK_PYTHON'] = "python.exe文件位置"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)# 2.读取数据文件
rdd = sc.textFile("C:/1.txt")# 3.获取全部单词,默认以空格为分隔符
word_rdd = rdd.flatMap(lambda x:x.split(" "))# 4.将单词转换为二元元祖
word_withone_add = word_rdd.map(lambda word:(word,1))# 5.分组求和
result_add = word_withone_add.reduceByKey(lambda a,b:a+b)# 6.打印出结果
print(result_add.collect())