问题前提
之前做过数据入湖,建表的时候匆忙,没有做主键,导致入湖出现了重复数据。举个例子:
| id | name | age | sex |
| 1 | 用户1 | 21 | 男 |
| 1 | 用户1 | 21 | 男 |
| 1 | 用户1 | 21 | 男 |
存在了如上两条及两条数据,目的是要去除重复数据,只保留一条,从而设置id为主键。
Oracle
Oracle如果存在重复数据,id设置主键时,会有02437报错。
对于Oracle去处重复数据是最简单的,每行自带rowid。
DELETE
FROMuser
WHEREid IN ( SELECT id FROM user GROUP BY id HAVING count( id ) > 1 ) AND rowid NOT IN (SELECTmin( rowid ) FROMuser GROUP BYid
HAVINGcount( id )> 1)执行如上语句即可删除重复数据。
因为本地没有Oracle数据库,就不做演示了。
MySQL
MySQL没有rowid,那么MySQL解决办法只有一种,把A表的数据去重添加到B表中,在B表中设置id为主键,最后把B表重命名为A表。
INSERT INTO user1 ( SELECT DISTINCT * FROM user );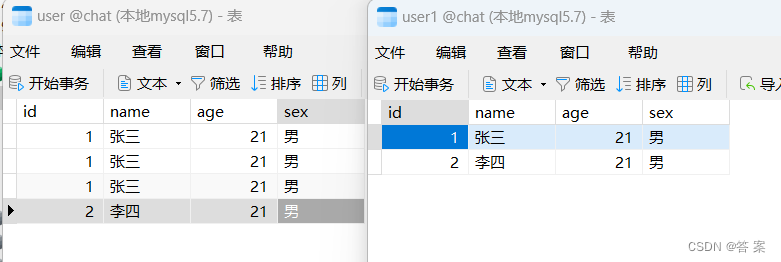
暂不清楚,数据量大的情况下会不会出现崩溃,可以通过limit截取。
如果不确定A表的数据是否全部添加到B表,可以添加完成后,执行
DELETE FROM user WHERE user.id IN (SELECT user1.id FROM user1)这种方式当然也适用于其他数据库。
当然MySQL还有另外一种方式,就是新增一个字段为自增字段且不为null,让其自动填充,类似充当Orcal中的rowid。
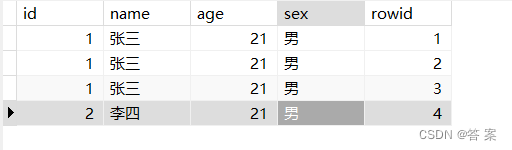
填充完成后。
DELETE
FROMuser
WHEREuser.rowid NOT IN (SELECTdt.minid FROM( SELECT MIN( user.rowid ) AS minid FROM user GROUP BY name ) dt )有多种方式,可参考【mysql】mysql删除重复记录并且只保留一条_mysql删除完全重复数据只保留一条_千g的博客-CSDN博客
SQL Server
SQL Server 和MySQL逻辑是一样的,但语法上稍有变化
SELECT DISTINCT * INTO [dbo].[user1] FROM [dbo].[user]SQL Server是不需要创建user1表的,会自动创建,数据导入到新表后再设置主键即可。
另外一种设置自增rowid,执行:
DELETE
FROM[dbo].[user]
WHERE[dbo].[user].rowid NOT IN (SELECTdt.minid FROM( SELECT MIN( [dbo].[user].rowid ) AS minid FROM [dbo].[user] GROUP BY name ) dt )后续
后续研究其他数据库,mongo等其他用到的数据库再做更新,