机器学习技术(十)——决策树算法实操

文章目录
- 机器学习技术(十)——决策树算法实操
- 一、引言
- 二、数据集介绍
- 三、导入相关依赖库
- 四、读取并查看数据
- 1、读取数据
- 2、查看数据
- 五、数据预处理
- 1、选择数据
- 2、数据转码
- 六、建模与参数优化
- 1、训练模型
- 2、评估模型
- 3、调参优化
- 七、模型可视化
- 八、决策树实操总结
一、引言
决策树部分主要包含基于python的决策树模型的实现及调用。基于运营商过往数据,采用决策树算法,对用户离网情况进行预测。

二、数据集介绍
该数据集包含了3333条数据,每条数据有21个属性,包括是否离网以及地区、参与套餐的情况、每天通话量、国际通话量、客服交流情况等。其中我们将离网情况作为标签因变量,其中十九列数据作为自变量,通过探索用户属性将其进行分类预测。
数据集下载:https://download.csdn.net/download/tianhai12/88275733
三、导入相关依赖库
将所需模型以及可视化依赖包导入。
import pandas as pd
from sklearn import model_selection
import pydotplus
import graphviz
from sklearn import tree
from IPython.display import Image
from sklearn.tree import export_graphviz
import os
#os.environ["PATH"] += os.pathsep + 'D:\\Program Files\\Graphviz\\bin' #graphviz对应的bin文件路径
四、读取并查看数据
1、读取数据
将数据读取显示数据结构
输入:
#使用pandas读取csv文件数据
data=pd.read_csv("./ml/churn.csv",encoding='utf-8',sep=',')
#观察数据形状
print("SHAPE=",data.shape)
结果显示如下,共有3333名用户,每位用户有21组特征。
SHAPE= (3333, 21)
输入:
#查看数据前五行内容
data.head(5)
2、查看数据
查看数据缺失值以及基本数据结构
#利用info函数对数据类型,缺失情况进行查看
data.info()
info函数输出结果如下所示,发现没有数据缺失,较为完整。数据结构如平均值或方差也如下所示。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3333 entries, 0 to 3332
Data columns (total 21 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 State 3333 non-null object 1 Account Length 3333 non-null int64 2 Area Code 3333 non-null int64 3 Phone 3333 non-null object 4 Int'l Plan 3333 non-null object 5 VMail Plan 3333 non-null object 6 VMail Message 3333 non-null int64 7 Day Mins 3333 non-null float648 Day Calls 3333 non-null int64 9 Day Charge 3333 non-null float6410 Eve Mins 3333 non-null float6411 Eve Calls 3333 non-null int64 12 Eve Charge 3333 non-null float6413 Night Mins 3333 non-null float6414 Night Calls 3333 non-null int64 15 Night Charge 3333 non-null float6416 Intl Mins 3333 non-null float6417 Intl Calls 3333 non-null int64 18 Intl Charge 3333 non-null float6419 CustServ Calls 3333 non-null int64 20 Churn? 3333 non-null object
dtypes: float64(8), int64(8), object(5)
memory usage: 546.9+ KB
利用describe对不同条目数据进行定量刻画
data.describe()
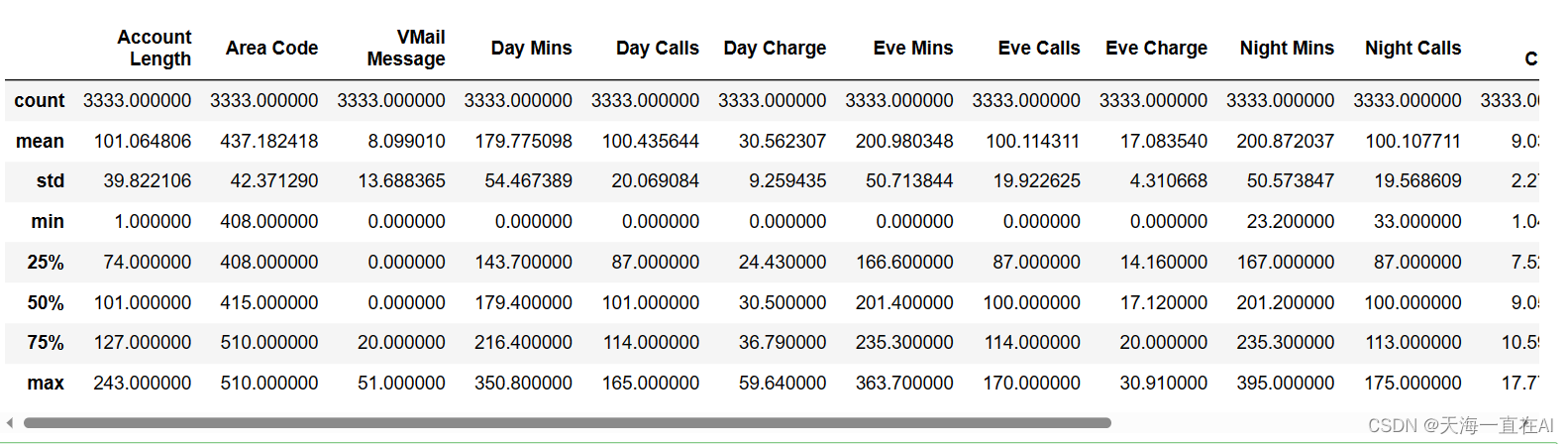
五、数据预处理
1、选择数据
除最后的是否离网信息外,每位用户还有其他20项特征,其中有电话号码这一项具有唯一性,所以我们将其舍弃。还有一些属性不适合直接处理,所以在进行训练之前先进行转码
#注意到电话号码”Phone”这一属性。由于该属性具有唯一性,考虑在数据中舍弃该条目
data=data.drop('Phone',axis=1)
data.info()
输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3333 entries, 0 to 3332
Data columns (total 20 columns):
State 3333 non-null object
Account Length 3333 non-null int64
Area Code 3333 non-null int64
Int'l Plan 3333 non-null object
VMail Plan 3333 non-null object
VMail Message 3333 non-null int64
Day Mins 3333 non-null float64
Day Calls 3333 non-null int64
Day Charge 3333 non-null float64
Eve Mins 3333 non-null float64
Eve Calls 3333 non-null int64
Eve Charge 3333 non-null float64
Night Mins 3333 non-null float64
Night Calls 3333 non-null int64
Night Charge 3333 non-null float64
Intl Mins 3333 non-null float64
Intl Calls 3333 non-null int64
Intl Charge 3333 non-null float64
CustServ Calls 3333 non-null int64
Churn? 3333 non-null object
dtypes: float64(8), int64(8), object(4)
memory usage: 520.9+ KB
2、数据转码
一些特征为yes和no,先将其进行转码。
'''
注意到存在非数值的属性,例如是否参加Vmail套餐-VMail Plan的值为yes与no,需要将其转化为数值。
'''
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
data.iloc[:,0]=encoder.fit_transform(data.iloc[:,0])
data.iloc[:,3]=encoder.fit_transform(data.iloc[:,3])
data.iloc[:,4]=encoder.fit_transform(data.iloc[:,4])
data.iloc[:,-1]=encoder.fit_transform(data.iloc[:,-1])
data.head(5)
转码后输出结果如下。
| State | Account Length | Area Code | Int’l Plan | VMail Plan | VMail Message | Day Mins | Day Calls | Day Charge | Eve Mins | Eve Calls | Eve Charge | Night Mins | Night Calls | Night Charge | Intl Mins | Intl Calls | Intl Charge | CustServ Calls | Churn? | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 16 | 128 | 415 | 0 | 1 | 25 | 265.1 | 110 | 45.07 | 197.4 | 99 | 16.78 | 244.7 | 91 | 11.01 | 10.0 | 3 | 2.70 | 1 | 0 |
| 1 | 35 | 107 | 415 | 0 | 1 | 26 | 161.6 | 123 | 27.47 | 195.5 | 103 | 16.62 | 254.4 | 103 | 11.45 | 13.7 | 3 | 3.70 | 1 | 0 |
| 2 | 31 | 137 | 415 | 0 | 0 | 0 | 243.4 | 114 | 41.38 | 121.2 | 110 | 10.30 | 162.6 | 104 | 7.32 | 12.2 | 5 | 3.29 | 0 | 0 |
| 3 | 35 | 84 | 408 | 1 | 0 | 0 | 299.4 | 71 | 50.90 | 61.9 | 88 | 5.26 | 196.9 | 89 | 8.86 | 6.6 | 7 | 1.78 | 2 | 0 |
| 4 | 36 | 75 | 415 | 1 | 0 | 0 | 166.7 | 113 | 28.34 | 148.3 | 122 | 12.61 | 186.9 | 121 | 8.41 | 10.1 | 3 | 2.73 | 3 | 0 |
划分自变量和标签变量,并设为X和Y。并将数据集按7:3划分为训练集和测试集用于训练模型。
#数据集划分
#最后一列数据Churn?代表是否离网的标签,作为整体输出,前19列数据作为输入
col_dicts = {}
cols = data.columns.values.tolist()
X=data.loc[:,cols[1:-1]]
y=data[cols[-1]]
# 30%的数据划分用于测试,70%用于训练
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.3, random_state=0)
print(y_train.value_counts()/len(y_train))
print(y_test.value_counts()/len(y_test))
输出测试集,训练集中两个标签的所占概率。
0 0.852122
1 0.147878
Name: Churn?, dtype: float64
0 0.862
1 0.138
Name: Churn?, dtype: float64
六、建模与参数优化
1、训练模型
导入决策树模型,并基于上述所得训练集训练模型。
# 训练决策树模型
from sklearn.tree import DecisionTreeClassifier
tree_clf = DecisionTreeClassifier()
tree_clf.fit(X_train, y_train)
DecisionTreeClassifier的参数如下
criterion="gini",splitter="best",max_depth=None,min_samples_split=2,min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features=None,random_state=None,max_leaf_nodes=None,min_impurity_decrease=0.0,class_weight=None,ccp_alpha=0.0,
下面是每个参数的解释说明,仅供参考。
-
criterion:string类型,可选(默认为"gini") 衡量分类的质量。支持的标准有"gini"代表的是Gini impurity(不纯度)与"entropy"代表的是information gain(信息增益)。
-
splitter:string类型,可选(默认为"best") 一种用来在节点中选择分类的策略。支持的策略有"best",选择最好的分类,"random"选择最好的随机分类。
-
max_features:int,float,string or None 可选(默认为None),在进行分类时需要考虑的特征数。
1.如果是int,在每次分类是都要考虑max_features个特征。
2.如果是float,那么max_features是一个百分率并且分类时需要考虑的特征数是int(max_features*n_features,其中n_features是训练完成时发特征数)。
3.如果是auto,max_features=sqrt(n_features)
4.如果是sqrt,max_features=sqrt(n_features)
5.如果是log2,max_features=log2(n_features)
6.如果是None,max_features=n_features -
max_depth:int or None,可选(默认为"None")表示树的最大深度。如果是"None",则节点会一直扩展直到所有的叶子都是纯的或者所有的叶子节点都包含少于min_samples_split个样本点。忽视max_leaf_nodes是不是为None。
-
min_samples_split:int,float,可选(默认为2)区分一个内部节点需要的最少的样本数。
1.如果是int,将其最为最小的样本数。
2.如果是float,min_samples_split是一个百分率并且ceil(min_samples_split*n_samples)是每个分类需要的样本数。ceil是取大于或等于指定表达式的最小整数。
-
min_samples_leaf:int,float,可选(默认为1)一个叶节点所需要的最小样本数:
1.如果是int,则其为最小样本数
2.如果是float,则它是一个百分率并且ceil(min_samples_leaf*n_samples)是每个节点所需的样本数。
-
min_weight_fraction_leaf:float,可选(默认为0)一个叶节点的输入样本所需要的最小的加权分数。
-
max_leaf_nodes:int,None 可选(默认为None)在最优方法中使用max_leaf_nodes构建一个树。最好的节点是在杂质相对减少。如果是None则对叶节点的数目没有限制。如果不是None则不考虑max_depth.
-
class_weight:dict,list of dicts,“Banlanced” or None,可选(默认为None)表示在表{class_label:weight}中的类的关联权值。如果没有指定,所有类的权值都为1。对于多输出问题,一列字典的顺序可以与一列y的次序相同。"balanced"模型使用y的值去自动适应权值,并且是以输入数据中类的频率的反比例。如:n_samples/(n_classes*np.bincount(y))。对于多输出,每列y的权值都会想乘。如果
sample_weight已经指定了,这些权值将于samples以合适的方法相乘。 -
random_state:int,RandomState instance or None如果是int,random_state 是随机数字发生器的种子;如果是RandomState,random_state是随机数字发生器,如果是None,随机数字发生器是np.random使用的RandomState instance.
-
persort:bool,可选(默认为False)是否预分类数据以加速训练时最好分类的查找。在有大数据集的决策树中,如果设为true可能会减慢训练的过程。当使用一个小数据集或者一个深度受限的决策树中,可以减速训练的过程。
2、评估模型
进行模型评估,输出结果为精确率,召回率等指标。
#模型评估
#采用测试集,基于精确率、召回率等指标对模型效果进行评估
from sklearn.metrics import classification_reporty_true = y_test
y_pred = tree_clf.predict(X_test)
target_names = ['class 0', 'class 1']
print(classification_report(y_true, y_pred, target_names=target_names))
由结果可知,对class 0的预测率高于对class 1 的预测率。其中原因可能是因为class 0的所占比例要远高于class 1
precision recall f1-score supportclass 0 0.96 0.93 0.95 862class 1 0.64 0.78 0.70 138accuracy 0.91 1000macro avg 0.80 0.85 0.83 1000
weighted avg 0.92 0.91 0.91 1000
3、调参优化
显然上述模型表现还不够好,我们通过交叉检验法进行决策树深度,内部划分最小样本数和叶子节点最小样本数的调整。
#参数优化
'''
调用GridSearchCV进行参数调优,调整的参数主要有
max_depth:树的最大深度
min_samples_split:内部节点划分的最小样本数
min_samples_leaf:叶子节点最小样本数
'''from sklearn.model_selection import GridSearchCVmodel_to_set = DecisionTreeClassifier()
parameters = {'criterion':['entropy'],
#设置树的深度,在其中去选择一个表现最好的深度
"max_depth": [3,4,5,6,7,8,9,10,11,12,13],
#设置内部节点划分的最小样本数,在其中去选择一个表现最好的内部节点划分的最小样本数
"min_samples_split": [5,10,15,20,25,30,35,40,45,50],
#设置叶子节点最小样本数,在其中去选择一个表现最好的叶子节点最小样本数 "min_samples_leaf": [5,10,15,20,25,30,35,40,45,50],
}
model_tunning = GridSearchCV(model_to_set, param_grid = parameters, cv=5)
model_tunning.fit(X_train, y_train.values.ravel())
print(model_tunning.best_score_)
print(model_tunning.best_params_)
输出为最高的评估参数,以及与之对应的最优参数。
0.9417053422907611
{'criterion': 'entropy', 'max_depth': 8, 'min_samples_leaf': 5, 'min_samples_split': 15}
由以上所得最优参数,再次进行建模,在测试集上进行测试,输出结果。
#基于参数调优的结果构建决策树,最终的性能要比未经调参的结果有明显提升tree_clf = DecisionTreeClassifier(max_depth=5,min_samples_leaf=5,min_samples_split=15)
tree_clf.fit(X_train, y_train)y_true = y_test
y_pred = tree_clf.predict(X_test)
target_names = ['class 0', 'class 1']
print(classification_report(y_true, y_pred, target_names=target_names))
经过调优后,在测试集上的表现比之前好了很多,正确率达到0.94,满足业务需求。
precision recall f1-score supportclass 0 0.96 0.97 0.97 862class 1 0.82 0.75 0.78 138accuracy 0.94 1000macro avg 0.89 0.86 0.87 1000
weighted avg 0.94 0.94 0.94 1000
七、模型可视化
对上诉所得模型进行可视化
#树的可视化
#获得各输入Feature的名称
feature_names = X.columns[:]
class_names = ['0','1']# 创建 Dot 数据
dot_data = tree.export_graphviz(tree_clf, out_file=None, feature_names=feature_names, class_names=class_names,filled = True, impurity = False)
# 生成图片
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
#graph.write_png("tree.png")
输出结果如下,该图显示每个节点如何区分样本。
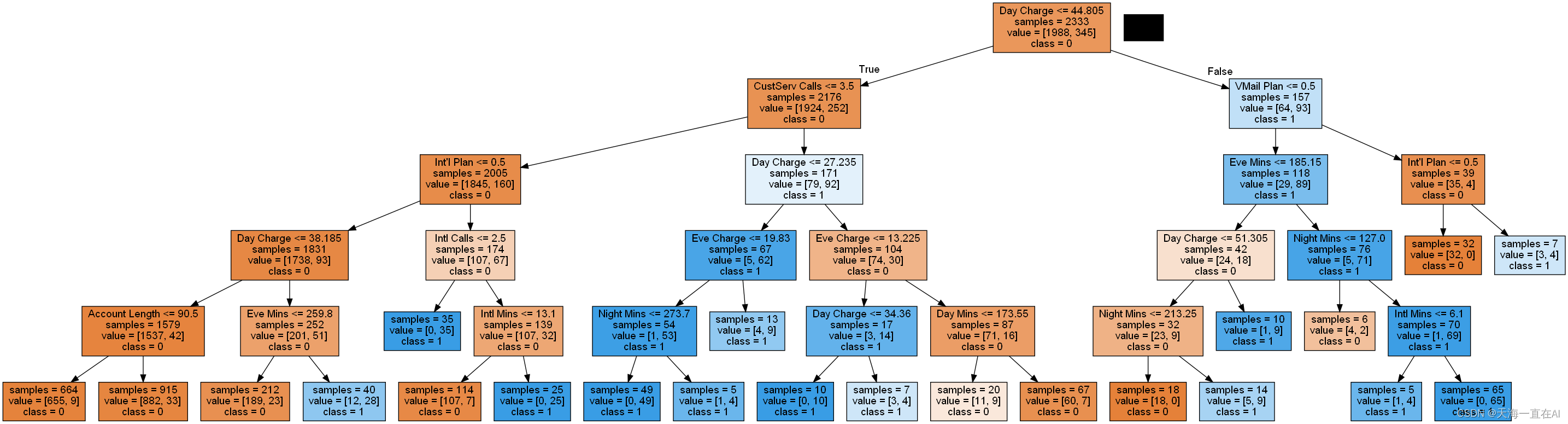
八、决策树实操总结
该数据集包含了3333条数据,每条数据有21个属性,包括是否离网以及地区、参与套餐的情况、每天通话量、国际通话量、客服交流情况等。其中我们将离网情况作为标签因变量,对其他属性进行预处理,舍弃电话号码这一属性,并将一些特征进行转码以便于数据处理。而后进行决策树模型搭建以及调参优化模型,最后模型准确率可以达到0.94,初步满足业务需求,最后进行决策树的可视化,知道每个节点如何去决策。