在上一讲中,介绍了消息的存储,生产者向Broker发送消息之后,数据会写入到CommitLog中,这一讲,就来看一下消费者是如何从Broker拉取消息的。
RocketMQ消息的消费以组为单位,有两种消费模式:
广播模式:同一个消息队列可以分配给组内的每个消费者,每条消息可以被组内的消费者进行消费。

集群模式:同一个消费组下,一个消息队列同一时间只能分配给组内的一个消费者,也就是一条消息只能被组内的一个消费者进行消费。
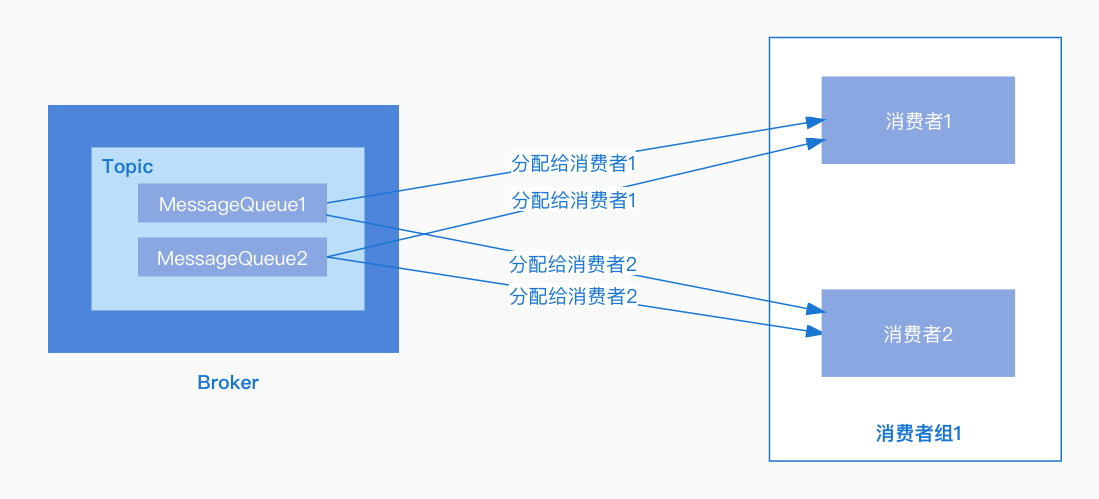
通常使用集群模式的情况比较多,接下来以集群模式(Push模式)为例看一下消息的拉取过程。
消费者启动时处理
消费者在启动的时候主要做了以下几件事情:
- Topic订阅处理;
- MQClientInstance实例创建;
- 加载消费进度存储对象,里面存储了每个消息队列的消费进度;
- 从NameServer更新Topic路由信息;
- 向Broker进行注册;
- 触发负载均衡;
主题订阅处理
RocketMQ消费者以组为单位,启用消费者时,需要设置消费者组名称以及要订阅的Topic信息(需要知道要消费哪个Topic上面的消息):
@RunWith(MockitoJUnitRunner.class)
public class DefaultMQPushConsumerTest {@Mockprivate MQClientAPIImpl mQClientAPIImpl;private static DefaultMQPushConsumer pushConsumer;@Beforepublic void init() throws Exception {// ...// 消费者组名称String consumerGroup = "FooBarGroup";// 实例化DefaultMQPushConsumerpushConsumer = new DefaultMQPushConsumer(consumerGroup);pushConsumer.setNamesrvAddr("127.0.0.1:9876");// ...// 设置订阅的主题pushConsumer.subscribe("FooBar", "*");// 启动消费者pushConsumer.start();}
}所以消费者启动的时候,首先会获取订阅的Topic信息,由于一个消费者可以订阅多个Topic,所以消费者使用一个Map存储订阅的Topic信息,KEY为Topic名称,VALUE为对应的表达式,之后会遍历每一个订阅的Topic,然后将其封装为SubscriptionData对象,并加入到负载均衡对象RebalanceImpl中,等待进行负载均衡。
MQClientInstance实例创建
MQClientInstance中有以下几个关键信息:
- 消息拉取服务:对应实现类为
PullMessageService,是用来从Broker拉取消息的服务; - 负载均衡服务:对应的实现类为
RebalanceService,是用来进行负载均衡,为每个消费者分配对应的消费队列; - 消费者列表(consumerTable):记录该实例上的所有消费者信息,key为消费者组名称,value为消费者对应的
MQConsumerInner对象,每一个消费者启动的时候会向这里注册,将自己加入到consumerTable中;

需要注意MQClientInstance实例是以clientId为单位创建的,相同的clientId共用一个MQClientInstance实例,clientId由以下信息进行拼装:
(1)服务器的IP;
(2)实例名称(instanceName);
(3)单元名称(unitName)(不为空的时候才拼接);
最终拼接的clientId字符串为:服务器IP + @ + 实例名称 + @ + 单元名称。
所以在同一个服务器上,如果实例名称和单元名称也相同的话,所有的消费者会共同使用一个MQClientInstance实例。
MQClientInstance启动的时候会把消息拉取服务和负载均衡服务也启动(启动对应的线程)。
获取Topic路由信息
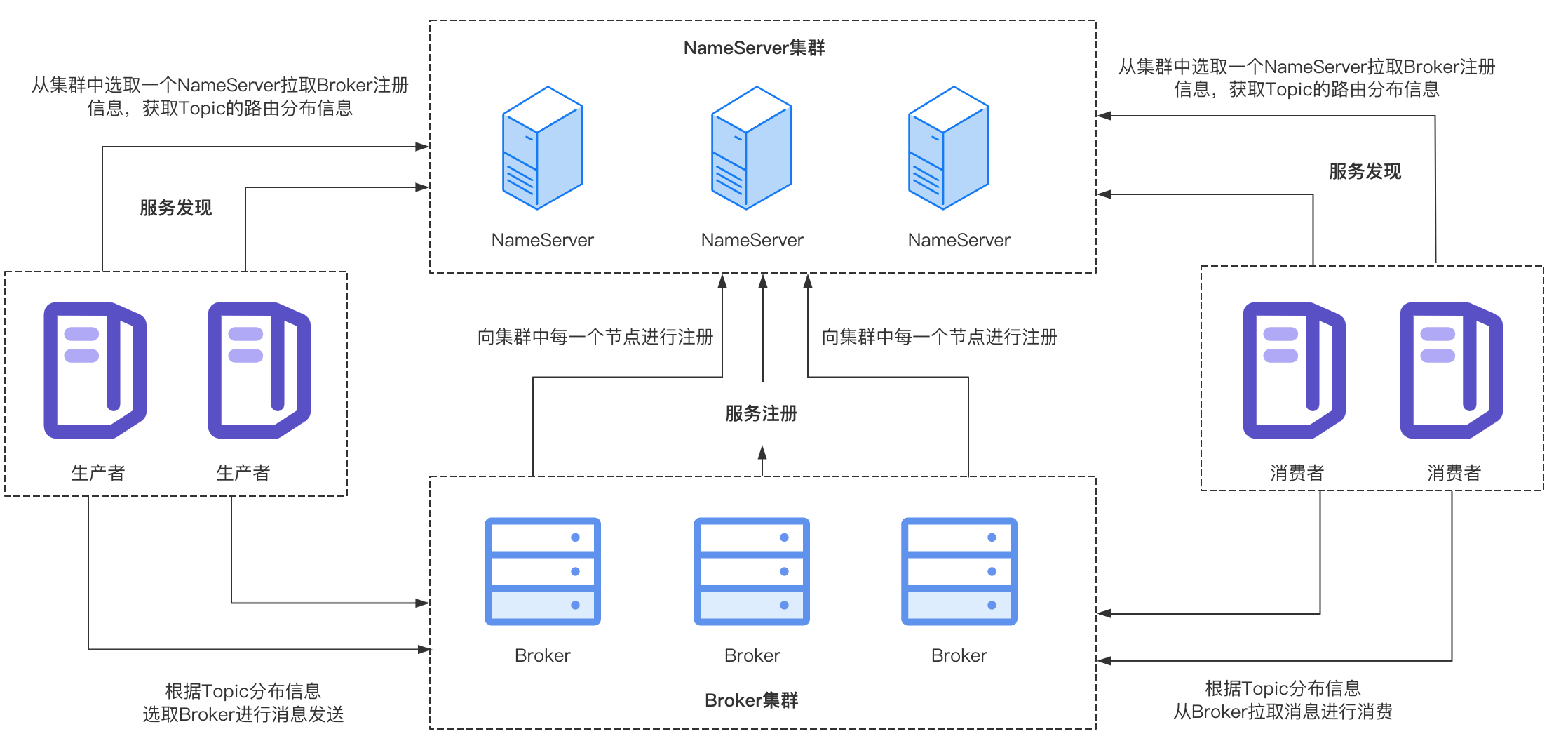
前面已经得知了当前消费者订阅的Topic信息,接下来需要知道这些Topic的分布情况,也就是分布在哪些Broker上,Topic的分布信息可以从NameServer中获取到,因为Broker会向NameServer进行注册,上报自己负责的Topic信息,所以这一步消费者向NameServer发送请求,从NameServer中拉取最新的Topic的路由信息缓存在本地。
加载消费进度
消费者在进行消费的时候,需要知道应该从哪个位置开始拉取消息,OffsetStore类中记录这些数据,不同的模式对应的实现类不同:
- 集群模式:消息的消费进度保存在Broker中,由Broker记录每个消费队列的消费进度,对应实现类为
RemoteBrokerOffsetStore。 - 广播模式:消息的消费进度保存在消费者端,对应实现类为
LocalFileOffsetStore。
这里关注集群模式,在集群模式下,加载消费进度时,会进入RemoteBrokerOffsetStore的load方法,load方法是从本地加载文件读取消费进度,因为集群模式下需要从Broker获取,所以load方法什么也没干,在负载均衡分配了消息队列,进行消息拉取的时候再向Broker发送请求获取消费进度。
向Broker进行注册
由于消费者增加或者减少会影响消息队列的分配,所以Broker需要感知消费者的上下线情况,消费者在启动时会向所有的Broker发送心跳包进行注册,通知Broker消费者上线。
Broker收到消费者发送的心跳包之后,会从请求中解析相关信息,将该消费者注册到Broker维护的消费者列表consumerTable中,其中KEY为消费者组名称,Value为该消费组的详细信息(ConsumerGroupInfo对象),里面记录了该消费组下所有消费者的Channel信息。

触发负载均衡
启动最后一步,会立即触发一次负载均衡,为消费者分配消息队列。
负载均衡
负载均衡是通过消费者启动时创建的MQClientInstance实例实现的(doRebalance方法),它的处理逻辑如下:
-
MQClientInstance中有一个消费者列表consumerTable,存放了该实例上注册的所有消费者对象,Key为组名称,Value为消费者,所以会遍历所有的消费者,对该实例上注册的每一个消费者进行负载均衡; -
对于每一个消费者,需要获取其订阅的所有Topic信息,然后再对每一个Topic进行负载均衡,前面可知消费者订阅的Topic信息被封装为了
SubscriptionData对象,所以这里获取到所有的SubscriptionData对象进行遍历,开始为每一个消费者分配消息队列;
分配消息队列
这里我们关注集群模式下的分配,它的处理逻辑如下:
- 根据Topic获取该Topic下的所有消费队列(
MessageQueue对象);
消费者在启动时向NameServer发送请求获取Topic的路由信息,从中解析中每个主题对应的消息队列,放入负载均衡对象的
topicSubscribeInfoTable变量中,所以这一步直接从topicSubscribeInfoTable中获取主题对应的消息队列即可。
-
根据主题信息和消费者组名称,查找订阅了该主题的所有消费者的ID:
(1)根据主题选取Broker:从NameServer中拉取的主题路信息中可以找到每个主题分布在哪些Broker上,从中随机选取一个Broker;
(2)向Broker发送请求:根据上一步获取到的Broker,向其发送请求,查找订阅了该主题的所有消费者的ID(消费者会向Broker注册,所以可以通过Broker查找订阅了某个Topic的消费者); -
如果主题对应的消息队列集合和获取到的消费者ID都不为空,对消息队列集合和消费ID集合进行排序;
-
获取分配策略,根据具体的分配策略,为当前的消费者分配对应的消费队列,RocketMQ默认提供了以下几种分配策略:
-
AllocateMessageQueueAveragely:平均分配策略,根据消息队列的数量和消费者的个数计算每个消费者分配的队列个数。

-
AllocateMessageQueueAveragelyByCircle:平均轮询分配策略,将消息队列逐个分发给每个消费者。

-
AllocateMessageQueueConsistentHash:根据一致性 hash进行分配。
-
AllocateMessageQueueByConfig:根据配置,为每一个消费者配置固定的消息队列 。
-
AllocateMessageQueueByMachineRoom:分配指定机房下的消息队列给消费者。
-
AllocateMachineRoomNearby:优先分配给同机房的消费者。
-
-
根据最新分配的消息队列,更新当前消费者负责的消息处理队列;
更新消息处理队列
每个消息队列(MessageQueue)对应一个处理队列(ProcessQueue),后续使用这个ProcessQueue记录的信息进行消息拉取:

分配给当前消费者的所有消息队列,由一个Map存储(processQueueTable),KEY为消息队列,value为对应的处理队列:

由于负载均衡之后,消费者负责的消息队列可能发生变化,所以这里需要更新当前消费者负责的消息队列,它主要是拿负载均衡后重新分配给当前消费的消息队列集合与上一次记录的分配信息做对比,有以下两种情况:
(1)某个消息队列之前分配给了当前消费者,但是这次没有,说明此队列不再由当前消费者消负责,需要进行删除,此时将该消息队列对应的处理队列中的dropped状态置为true即可;
(2)某个消费者之前未分配给当前消费者,但是本次负载均衡之后分配给了当前消费者,需要进行新增,会新建一个处理队列(ProcessQueue)加入到processQueueTable中;
对于情况2,由于是新增分配的消息队列,消费者还需要知道从哪个位置开始拉取消息,所以需要通过OffsetStore来获取存储的消费进度,也就是上次消费到哪条消息了,然后判断本次从哪条消息开始拉取。前面在消费者启动的提到集群模式下对应的实现类为RemoteBrokerOffsetStore,再进入到这一步的时候,才会向Broker发送请求,获取消息队列的消费进度,并更新到offsetTable中。

从Broker获取消费进度之后,有以下几种拉取策略:
(1)CONSUME_FROM_LAST_OFFSET(上次消费位置开始拉取):从OffsetStore获取消息队列对应的消费进度值lastOffset,判断是否大于等于0,如果大于0则返回lastOffset的值,从这个位置继续拉取;
(2)CONSUME_FROM_FIRST_OFFSET(第一个位置开始拉取):从OffsetStore获取消息队列对应的消费进度值lastOffset,如果大于等于0,依旧从这个位置继续拉取,否则才从第一条消息拉取,此时返回值为0;
(3)CONSUME_FROM_TIMESTAMP(根据时间戳拉取):从OffsetStore获取消息队列对应的消费进度值lastOffset,如果大于等于0,依旧从这个位置继续拉取,否则在不是重试TOPIC的情况下,根据消费者的启动时间查找应该从什么位置开始消费;
nextOffset拉取偏移量的值确定之后,会将ProcessQueue加入到processQueueTable中,并构建对应的消息拉取请求PullRequest,并设置以下信息:
- consumerGroup:消费者组名称;
- nextOffset:从哪条消息开始拉取,设置的是上面计算的消息拉取偏移量
nextOffset的值; - MessageQueue:消息队列,从哪个消息队列上面消费消息;
- ProcessQueue:处理队列,消息队列关联的处理队列;
PullRequest构建完毕之后会将其加入到消息拉取服务中的一个阻塞队列中,等待消息拉取服务进行处理。
消息拉取
消费者发送拉取请求
消息拉取服务中,使用了一个阻塞队列,阻塞队列中存放的是消息拉取请求PullRequest对象,如果有消息拉取请求到来,就会从阻塞队列中取出对应的请求进行处理,从Broker拉取消息,拉取消息的处理逻辑如下:
- 从拉取请求
PullRequest中获取对应的处理队列ProcessQueue,先判断是否置为Dropped删除状态,如果处于删除状态不进行处理; - 从处理队列中获取缓存的消息的数量及大小进行验证判断是否超过了设定的值,因为处理队列中之前可能已经拉取了消息还未处理完毕,为了不让消息堆积需要先处理之前的消息,所以会延迟50毫秒后重新加入到拉取请求队列中处理;
- 判断是否是顺序消费,这里先不讨论顺序消费,如果是非顺序消费,判断processQueue中队列最大偏移量和最小偏移量的间距是否超过
ConsumeConcurrentlyMaxSpan的值,如果超过需要进行流量控制,延迟50毫秒后重新加入队列中进行处理; - 向Broker发送拉取消息请求,从Broker拉取消息:
(1)ProcessQueue关联了一个消息队列MessageQueue对象,消息队列对象中有其所在的Broker名称,根据名称再查找该Broker的详细信息;
(2)根据第(1)步的查找结果,构建消息拉取请求,在请求中设置本次要拉取消息的Topic名称、消息队列ID等信息,然后向Broker发送请求; - 消费者处理拉取请求返回结果,上一步向Broker发送请求的时候可以同步发送也可以异步发送请求,对于异步发送请求当请求返回成功之后,会有一个回调函数,在回调函数中处理消息拉取结果。

Broker处理消息拉取请求
ConsumeQueue
RocketMQ在消息存储的时候将消息顺序写入CommitLog文件,如果想根据Topic对消息进行查找,需要扫描所有CommitLog文件,这种方式性能低下,所以RocketMQ又设计了ConsumeQueue存储消息的逻辑索引,在RocketMQ的存储文件目录下,有一个consumequeue文件夹,里面又按Topic分组,每个Topic一个文件夹,Topic文件夹内是该Topic的所有消息队列,以消息队列ID命名文件夹,每个消息队列都有自己对应的ConsumeQueue文件:

ConsumeQueue中存储的每条数据大小是固定的,总共20个字节:

- 消息在CommitLog文件的偏移量,占用8个字节;
- 消息大小,占用4个字节;
- 消息Tag的hashcode值,用于tag过滤,占用8个字节;

Broker在收到消费发送的拉取消息请求后,会根据拉取请求中的Topic名称和消息队列ID(queueId)查找对应的消费信息ConsumeQueue对象:
Broker中的consumeQueueTable中存储了每个Topic对应的消费队列信息,Key为Topic名称,Value为Topic对应的消费队列信息,它又是一个MAP,其中Key为消息队列ID(queueId),value为该消息队列的消费消费信息(ConsumeQueue对象)。
在获取到息ConsumeQueue之后,从中可以获取其中记录的最小偏移量minOffset和最大偏移量maxOffset,然后与拉取请求中携带的消息偏移量offset的值对比进行合法校验,校验通过才可以查找消息,对于消息查找结果大概有如下几种状态:
nextOffsetCorrection方法:用于校正消费者的拉取偏移量,不过需要注意,当前Broker是主节点或者开启了
OffsetCheckInSlave校验时,才会对拉取偏移量进行纠正,所以以下几种状态中如果调用了此方法进行校正,前提是满足此条件。
- NO_MESSAGE_IN_QUEUE:如果
CommitLog中的最大偏移量maxOffset值为0,说明当前消息队列中还没有消息,返回NO_MESSAGE_IN_QUEUE状态; - OFFSET_TOO_SMALL:如果待拉取偏移量
offset的值小于CommitLog文件的最小偏移量minOffset,说明拉取进度值过小,调用nextOffsetCorrection校正下一次的拉取偏移量为CommitLog文件的最小偏移量(需要满足校正的条件),并将这个偏移量放入nextBeginOffset变量; - OFFSET_OVERFLOW_ONE:如果待拉取偏移量
offset等于CommitLog文件的最大偏移量maxOffset,依旧调用nextOffsetCorrection方法进行校正(需要满足校正的条件),只不过校正的时候使用的还是offset的值,可以理解为这种情况什么也没干。 - OFFSET_OVERFLOW_BADLY:如果待拉取偏移量
offset大于CommitLog文件最大偏移量maxOffset,说明拉取偏移量越界,此时有以下两种情况:- 如果最小偏移
minOffset量为0,调用nextOffsetCorrection方法校正下一次拉取偏移量为minOffset的值(需要满足校正的条件),也就是告诉消费者,下次从偏移量为0的位置开始拉取消息; - 如果最小偏移量
minOffset不为0,调用nextOffsetCorrection方法校正下一次拉取偏移量为maxOffset的值(需要满足校正的条件),将下一次拉取偏移量的值设置为最大偏移量;
- 如果最小偏移
- NO_MATCHED_LOGIC_QUEUE:如果根据主题未找到消息队列,返回此状态;
- FOUND:待拉取消息偏移量
offset的值介于最大最小偏移量之间,此时可以正常查找消息;
需要注意以上是消息查找的结果状态,Broker并没有使用这个状态直接返回给消费者,而是又做了一次处理。
经过以上步骤后,除了查找到的消息内容,Broker还会在消息返回结果中设置以下信息:
- 查找结果状态;
- 下一次拉取的偏移量,也就是
nextBeginOffset变量的值; CommitLog文件的最小偏移量minOffset和最大偏移量maxOffset;
消费者对拉取结果的处理
消费者收到Broker返回的响应后,对响应结果进行处理:
- FOUND:消息拉取请求成功,此时从响应中获取Broker返回的下一次拉取偏移量的值,更新到拉取请求中,然后进行以下判断:
- 如果拉取到的消息内容为空,将拉取请求放入到阻塞队列中再进行一次拉取;
- 如果拉取到的消息内容不为空,将消息提交到
ConsumeMessageService中进行消费(异步处理),然后判断拉取间隔的值是否大于0,如果大于0,会延迟一段时间进行下一次拉取,如果拉取间隔小于0表示需要立刻进行下一次拉取,此时将拉取请求加入阻塞队列中进行下一次拉取。
- NO_MATCHED_MSG:没有匹配的消息,使用Broker返回的下一次拉取偏移量的值作为新的拉取消息偏移量,然后将拉取请求加入阻塞队列中立刻进行下一次进行拉取。
- OFFSET_ILLEGAL:拉取偏移量不合法,此时使用Broker返回的下一次拉取偏移量的值,更新到消费者记录的消息拉取偏移量中(
offsetStore),并持久化保存,然后将当前的拉取请求中的处理队列状态置为dorp并删除处理队列,等待下一次重新构建拉取请求进行处理。
RocketMQ消息拉取相关源码可参考:【RocketMQ】【源码】消息的拉取