ViT(Vision Transformer)
- ABSTRACT
- 1 INTRODUCTION
- 2 RELATED WORK
- 4 EXPERIMENTS
- 4.1 SETUP
- 4.2 COMPARISON TO STATE OF THE ART
- 4.3 PRE-TRAINING DATA REQUIREMENTS
- 5 CONCLUSION
- 4.4 SCALING STUDY
- 4.5 INSPECTING VISION TRANSFORMER
- 5 CONCLUSION
- 声明
ABSTRACT
While the Transformer architecture has become the de-facto standard for natural
language processing tasks, its applications to computer vision remain limited. In
vision, attention is either applied in conjunction with convolutional networks, or
used to replace certain components of convolutional networks while keeping their
overall structure in place. We show that this reliance on CNNs is not necessary
and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
虽然Transformer体系结构已成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们表明,这种对细胞神经网络的依赖是不必要的,并且直接应用于图像补丁序列的纯变换器可以在图像分类任务中表现得很好。当在大量数据上进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB等)时,与最先进的卷积网络相比,视觉转换器(ViT)获得了优异的结果,同时需要更少的计算资源进行训练。1
1 INTRODUCTION
Self-attention-based architectures, in particular Transformers (Vaswani et al., 2017), have become the model of choice in natural language processing (NLP). The dominant approach is to pre-train on a large text corpus and then fine-tune on a smaller task-specific dataset (Devlin et al., 2019). Thanks to Transformers’ computational efficiency and scalability, it has become possible to train models of
unprecedented size, with over 100B parameters (Brown et al., 2020; Lepikhin et al., 2020). With the models and datasets growing, there is still no sign of saturating performance.
基于自我注意的架构,特别是Transformers(Vaswani et al.,2017),已经成为自然语言处理(NLP)中的首选模型。主要的方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调(Devlin等人,2019)。由于Transformers的计算效率和可扩展性,训练具有超过100B参数的空前规模的模型成为可能(Brown等人,2020;Lepikhin等人,2020)。随着模型和数据集的增长,性能仍然没有饱和的迹象。
In computer vision, however, convolutional architectures remain dominant (LeCun et al., 1989; Krizhevsky et al., 2012; He et al., 2016). Inspired by NLP successes, multiple works try combining CNN-like architectures with self-attention (Wang et al., 2018; Carion et al., 2020), some replacing the convolutions entirely (Ramachandran et al., 2019; Wang et al., 2020a). The latter models, while theoretically efficient, have not yet been scaled effectively on modern hardware accelerators due to the use of specialized attention patterns. Therefore, in large-scale image recognition, classic ResNetlike architectures are still state of the art (Mahajan et al., 2018; Xie et al., 2020; Kolesnikov et al., 2020).
然而,在计算机视觉中,卷积架构仍然占主导地位(LeCun等人,1989;Krizhevsky等人,2012;He等人,2016)。受NLP成功的启发,多部作品尝试将类似CNN的架构与自我关注相结合(Wang等人,2018;Carion等人,2020),其中一些作品完全取代了卷积(Ramachandran等人,2019;Wang等人,2020a)。后一种模型虽然理论上有效,但由于使用了专门的注意力模式,尚未在现代硬件加速器上有效扩展。因此,在大规模图像识别中,经典的ResNetlike架构仍然是最先进的(Mahajan等人,2018;谢等人,2020;Kolesnikov等人,2020)。
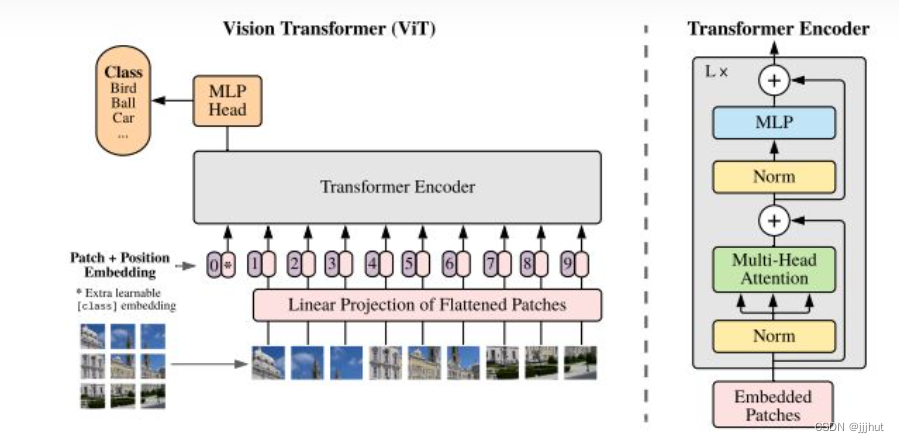
Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images, with the fewest possible modifications. To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in supervised fashion.
受NLP中Transformer缩放成功的启发,我们尝试将标准Transformer直接应用于图像,并尽可能减少修改。为此,我们将图像分割为多个补丁,并提供这些补丁的线性嵌入序列作为Transformer的输入。图像补丁的处理方式与NLP应用程序中的标记(单词)相同。我们以监督的方式对模型进行图像分类训练。
When trained on mid-sized datasets such as ImageNet without strong regularization, these models yield modest accuracies of a few percentage points below ResNets of comparable size. This seemingly discouraging outcome may be expected: Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well when trained on insufficient amounts of data.
当在没有强正则化的中型数据集(如ImageNet)上训练时,这些模型的精度比同等大小的ResNets低几个百分点。这种看似令人沮丧的结果是意料之中的:Transformers缺乏一些细胞神经网络固有的归纳偏差,如平移不变性和局部性,因此在数据量不足的情况下训练时不能很好地泛化。
However, the picture changes if the models are trained on larger datasets (14M-300M images). We find that large scale training trumps inductive bias. Our Vision Transformer (ViT) attains excellent results when pre-trained at sufficient scale and transferred to tasks with fewer datapoints. When pre-trained on the public ImageNet-21k dataset or the in-house JFT-300M dataset, ViT approaches
or beats state of the art on multiple image recognition benchmarks. In particular, the best model reaches the accuracy of 88:55% on ImageNet, 90:72% on ImageNet-ReaL, 94:55% on CIFAR-100, and 77:63% on the VTAB suite of 19 tasks.
然而,如果在较大的数据集(14M-300M图像)上训练模型,则图片会发生变化。我们发现大规模训练胜过归纳偏见。我们的视觉转换器(ViT)在进行足够规模的预训练并转移到数据点较少的任务中时,会取得优异的效果。当在公共ImageNet-21k数据集或内部JFT-300M数据集上进行预训练时,ViT在多个图像识别基准上接近或优于现有技术。特别是,最佳模型在ImageNet上达到88:55%的准确率,在ImageNet-ReaL上达到90:72%,在CIFAR-100上达到94:55%,在VTAB 19个任务套件上达到77:63%。
2 RELATED WORK
Transformers were proposed by Vaswani et al. (2017) for machine translation, and have since become the state of the art method in many NLP tasks. Large Transformer-based models are often pre-trained on large corpora and then fine-tuned for the task at hand: BERT (Devlin et al., 2019) uses a denoising self-supervised pre-training task, while the GPT line of work uses language modeling as its pre-training task (Radford et al., 2018; 2019; Brown et al., 2020).
Vaswani等人(2017)提出了用于机器翻译的变压器,并已成为许多NLP任务的最先进方法。基于大型变压器的模型通常在大型身体上进行预培训,然后对手头的任务进行微调:Bert(Devlin等人,2019年)使用非自我监督的培训前任务,而GPT工作线使用语言建模作为培训前任务(Radford等人,2018年;2019;Brown等人,2020年)。
Naive application of self-attention to images would require that each pixel attends to every other pixel. With quadratic cost in the number of pixels, this does not scale to realistic input sizes. Thus, to apply Transformers in the context of image processing, several approximations have been tried in the past. Parmar et al. (2018) applied the self-attention only in local neighborhoods for each query
pixel instead of globally. Such local multi-head dot-product self attention blocks can completely replace convolutions (Hu et al., 2019; Ramachandran et al., 2019; Zhao et al., 2020). In a different line of work, Sparse Transformers (Child et al., 2019) employ scalable approximations to global selfattention in order to be applicable to images. An alternative way to scale attention is to apply it in blocks of varying sizes (Weissenborn et al., 2019), in the extreme case only along individual axes (Ho et al., 2019; Wang et al., 2020a). Many of these specialized attention architectures demonstrate promising results on computer vision tasks, but require complex engineering to be implemented efficiently on hardware accelerators.
将自我关注力机制单纯地应用于图像需要每个像素关注其他像素。在像素数量为二次方成本的情况下,这不会扩展到现实的输入大小。因此,为了将Transformers应用于图像处理,过去已经尝试了几种近似方法。Parmar等人(2018)仅在每个查询像素的局部邻域中应用自关注,而不是全局应用。这种局部多头点-产物自我注意块可以完全取代卷积(Hu et al.,2019;Ramachandran et al.,2017;赵et al.,2020)。在另一项工作中,稀疏变换器(Child等人,2019)对全局自注意采用了可扩展的近似值,以便适用于图像。另一种扩大注意力的方法是将其应用于不同大小的区块(Weissenborn et al.,2019),在极端情况下,仅沿单个轴应用(Ho等人,2019;王等人,2020a)。这些专门的注意力架构中的许多在计算机视觉任务上表现出了有希望的结果,但需要在硬件加速器上有效地实现复杂的工程。
Most related to ours is the model of Cordonnier et al. (2020), which extracts patches of size 2 × 2 from the input image and applies full self-attention on top. This model is very similar to ViT, but our work goes further to demonstrate that large scale pre-training makes vanilla transformers competitive with (or even better than) state-of-the-art CNNs. Moreover, Cordonnier et al. (2020)
use a small patch size of 2 × 2 pixels, which makes the model applicable only to small-resolution images, while we handle medium-resolution images as well.
最相关的是我们的模型的Cordonnier et al. (2020年),其中提取的补丁的大小2×2从输入图像和适用充分自关注的顶上。 这种模式的是非常类似于维生素,但是,我们的工作更进一步,以证明大规模的预培训,使香草变压器的竞争力(或者甚至比)国家的技术CNNs. 此外,Cordonnier et al. (2020年)使用一小片大小为2×2的像素,这使得该模型只适用于小型分辨率的图像,虽然我们处理中等分辨率的图像。
There has also been a lot of interest in combining convolutional neural networks (CNNs) with forms of self-attention, e.g. by augmenting feature maps for image classification (Bello et al., 2019) or by further processing the output of a CNN using self-attention, e.g. for object detection (Hu et al., 2018; Carion et al., 2020), video processing (Wang et al., 2018; Sun et al., 2019), image classification (Wu
et al., 2020), unsupervised object discovery (Locatello et al., 2020), or unified text-vision tasks (Chen et al., 2020c; Lu et al., 2019; Li et al., 2019).
4 EXPERIMENTS
We evaluate the representation learning capabilities of ResNet, Vision Transformer (ViT), and the hybrid. To understand the data requirements of each model, we pre-train on datasets of varying size and evaluate many benchmark tasks. When considering the computational cost of pre-training the model, ViT performs very favourably, attaining state of the art on most recognition benchmarks at a lower pre-training cost. Lastly, we perform a small experiment using self-supervision, and show that self-supervised ViT holds promise for the future.
我们评估了ResNet、Vision Transformer(ViT)和hybrid的表示学习能力。为了了解每个模型的数据需求,我们在不同大小的数据集上进行预训练,并评估许多基准任务。当考虑到预训练模型的计算成本时,ViT表现得非常好,以较低的预训练成本在大多数识别基准上达到了最先进的水平。最后,我们使用自我监督进行了一个小实验,并表明自我监督的ViT对未来充满希望。
4.1 SETUP
Datasets. To explore model scalability, we use the ILSVRC-2012 ImageNet dataset with 1k classes and 1.3M images (we refer to it as ImageNet in what follows), its superset ImageNet-21k with 21k classes and 14M images (Deng et al., 2009), and JFT (Sun et al., 2017) with 18k classes and 303M high-resolution images. We de-duplicate the pre-training datasets w.r.t. the test sets of the
downstream tasks following Kolesnikov et al. (2020). We transfer the models trained on these dataset to several benchmark tasks: ImageNet on the original validation labels and the cleaned-up ReaL labels (Beyer et al., 2020), CIFAR-10/100 (Krizhevsky, 2009), Oxford-IIIT Pets (Parkhi et al., 2012), and Oxford Flowers-102 (Nilsback & Zisserman, 2008). For these datasets, pre-processing
follows Kolesnikov et al. (2020).
数据集。为了探索模型的可扩展性,我们使用了ILSVRC-2012 ImageNet数据集,该数据集具有1k个类和1.3M个图像(我们在下文中将其称为ImageNet),其超集ImageNet-21k具有21k个类和14M个图像,(Deng et al.,2009),以及JFT(Sun et al.,2017)具有18k个类和303M个高分辨率图像。在Kolesnikov等人(2020)之后,我们将预训练数据集与下游任务的测试集进行了去重。我们将在这些数据集上训练的模型转移到几个基准任务中:原始验证标签和清理后的ReaL标签上的ImageNet(Beyer等人,2020)、CIFAR-10/100(Krizhevsky,2009)、Oxford IIIT Pets(Parkhi等人,2012)和Oxford Flowers-102(Nilsback&Zisserman,2008)。对于这些数据集,按照Kolesnikov等人(2020)进行预处理。
We also evaluate on the 19-task VTAB classification suite (Zhai et al., 2019b). VTAB evaluates low-data transfer to diverse tasks, using 1 000 training examples per task. The tasks are divided into three groups: Natural – tasks like the above, Pets, CIFAR, etc. Specialized – medical and satellite imagery, and Structured – tasks that require geometric understanding like localization.
我们还对19任务VTAB分类套件进行了评估(Zhai et al.,2019b)。VTAB评估不同任务的低数据传输,每个任务使用1000个训练示例。任务分为三组:自然任务(如上述)、宠物、CIFAR等。专业任务(如医疗和卫星图像)和结构化任务(如定位),需要几何理解。
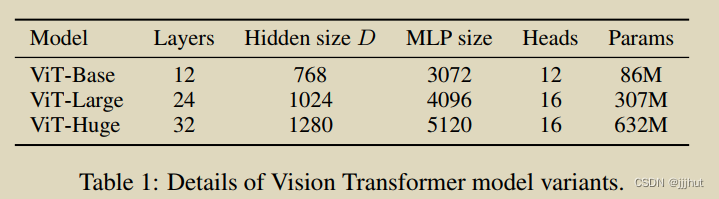
Model Variants. We base ViT configurations on those used for BERT (Devlin et al., 2019), as summarized in Table 1. The “Base” and “Large” models are directly adopted from BERT and we add the larger “Huge” model. In what follows we use brief notation to indicate the model size and the input patch size: for instance, ViT-L/16 means the “Large” variant with 16×16 input patch size. Note that the Transformer’s sequence length is inversely proportional to the square of the patch size, thus models with smaller patch size are computationally more expensive.
模型变体。如表1所示,我们基于用于BERT的ViT配置(Devlin等人,2019)。“基本”和“大”模型直接采用了BERT,我们添加了更大的“巨大”模型。在下文中,我们使用简短的符号来表示模型大小和输入补丁大小:例如,ViT-L/16表示输入补丁大小为16×16的“大”变体。请注意,Transformer的序列长度与补丁大小的平方成反比,因此具有较小补丁大小的模型在计算上更昂贵。
For the baseline CNNs, we use ResNet (He et al., 2016), but replace the Batch Normalization layers (Ioffe & Szegedy, 2015) with Group Normalization (Wu & He, 2018), and used standardized convolutions (Qiao et al., 2019). These modifications improve transfer (Kolesnikov et al., 2020),and we denote the modified model “ResNet (BiT)”. For the hybrids, we feed the intermediate feature maps into ViT with patch size of one “pixel”. To experiment with different sequence lengths,we either (i) take the output of stage 4 of a regular ResNet50 or (ii) remove stage 4, place the samenumber of layers in stage 3 (keeping the total number of layers), and take the output of this extended stage 3. Option (ii) results in a 4x longer sequence length, and a more expensive ViT model.
对于基线细胞神经网络,我们使用ResNet(He et al.,2016),但用组归一化(Wu&He,2018)代替批归一化层(Ioffe&Szegedy,2015),并使用标准化卷积(Qiao et al.,2019)。这些修改改善了转移(Kolesnikov等人,2020),我们将修改后的模型称为“ResNet(BiT)”。对于混合体,我们将中间特征图输入到ViT中,补丁大小为一个“像素”。为了用不同的序列长度进行实验,我们要么(i)取常规ResNet50的第4阶段的输出,要么(ii)去除第4阶段,在第3阶段中放置相同数量的层(保持层的总数),并取该扩展的第3阶段的输出。选项(ii)导致4倍长的序列长度和更昂贵的ViT模型。
Training & Fine-tuning. We train all models, including ResNets, using Adam (Kingma & Ba,2015) with β1 = 0:9, β2 = 0:999, a batch size of 4096 and apply a high weight decay of 0:1, which we found to be useful for transfer of all models (Appendix D.1 shows that, in contrast to common practices, Adam works slightly better than SGD for ResNets in our setting). We use a linear learning rate warmup and decay, see Appendix B.1 for details. For fine-tuning we use SGD with momentum, batch size 512, for all models, see Appendix B.1.1. For ImageNet results in Table 2, we fine-tuned at higher resolution: 512 for ViT-L/16 and 518 for ViT-H/14, and also used Polyak & Juditsky (1992) averaging with a factor of 0:9999 (Ramachandran et al., 2019; Wang et al., 2020b).
训练和微调。我们使用Adam(Kingma&Ba,2015)训练包括ResNets在内的所有模型,其中β1=0:9,β2=0:999,批量大小为4096,并应用0:1的高权重衰减,我们发现这对所有模型的转移都很有用(附录D.1显示,与常见做法相比,Adam在我们的设置中比用于ResNets的SGD工作得稍好)。我们使用线性学习率预热和衰减,详见附录B.1。对于微调,我们对所有型号使用具有动量的SGD,批量大小为512,请参阅附录B.1.1。对于表2中的ImageNet结果,我们以更高的分辨率进行了微调:ViT-L/16为512,ViT-H/14为518,还使用了Polyak&Juditsky(1992)的平均值,因子为0:9999(Ramachandran等人,2019;王等人,2020b)。
Metrics. We report results on downstream datasets either through few-shot or fine-tuning accuracy. Fine-tuning accuracies capture the performance of each model after fine-tuning it on the respective dataset. Few-shot accuracies are obtained by solving a regularized least-squares regression problem that maps the (frozen) representation of a subset of training images to f−1; 1gK target vectors. This formulation allows us to recover the exact solution in closed form. Though we mainly focus on fine-tuning performance, we sometimes use linear few-shot accuracies for fast on-the-fly evaluatio where fine-tuning would be too costly.
度量。我们通过少镜头或微调精度在下游数据集上报告结果。微调精度捕捉每个模型在各自数据集上进行微调后的性能。通过求解正则化最小二乘回归问题,将训练图像子集的(冻结)表示映射到f−1,可以获得很少的镜头精度;1gK目标载体。该公式使我们能够以闭合形式恢复精确解。虽然我们主要关注微调性能,但有时我们会使用线性少镜头精度进行快速飞行评估,因为微调成本太高。
4.2 COMPARISON TO STATE OF THE ART
We first compare our largest models – ViT-H/14 and ViT-L/16 – to state-of-the-art CNNs from the literature. The first comparison point is Big Transfer (BiT) (Kolesnikov et al., 2020), which performs supervised transfer learning with large ResNets. The second is Noisy Student (Xie et al.,2020), which is a large EfficientNet trained using semi-supervised learning on ImageNet and JFT-
300M with the labels removed. Currently, Noisy Student is the state of the art on ImageNet and BiT-L on the other datasets reported here. All models were trained on TPUv3 hardware, and we report the number of TPUv3-core-days taken to pre-train each of them, that is, the number of TPU v3 cores (2 per chip) used for training multiplied by the training time in days.
我们首先将我们最大的模型——ViT-H/14和ViT-L/16——与文献中最先进的细胞神经网络进行比较。第一个比较点是大迁移(BiT)(Kolesnikov et al.,2020),它使用大型ResNets执行监督迁移学习。第二个是Noisy Student(Xie et al.,2020),这是一个在ImageNet和JFT-300M上使用半监督学习进行训练的大型高效网络,去掉了标签。目前,Noisy Student在ImageNet和BiT-L的其他数据集上是最先进的。所有模型都在TPUv3硬件上进行了训练,我们报告了预训练每个模型所需的TPUv3核心天数,即用于训练的TPU v3核心数量(每个芯片2个)乘以训练时间(天)。
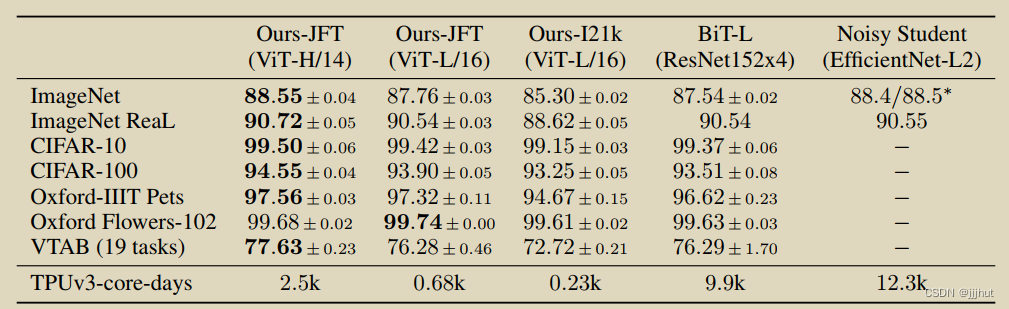
Table 2 shows the results. The smaller ViT-L/16 model pre-trained on JFT-300M outperforms BiT-L (which is pre-trained on the same dataset) on all tasks, while requiring substantially less computational resources to train. The larger model, ViT-H/14, further improves the performance, especially on the more challenging datasets – ImageNet, CIFAR-100, and the VTAB suite. Interestingly, this Table 2: Comparison with state of the art on popular image classification benchmarks. We report mean and standard deviation of the accuracies, averaged over three fine-tuning runs. VisionTransformer models pre-trained on the JFT-300M dataset outperform ResNet-based baselines on all datasets, while taking substantially less computational resources to pre-train. ViT pre-trained on the smaller public ImageNet-21k dataset performs well too. ∗Slightly improved 88:5% result reported in Touvron et al. (2020).
结果如表2所示。在JFT-300M上预训练的较小的ViT-L/16模型在所有任务上都优于BiT-L(在同一数据集上预训练),同时训练所需的计算资源要少得多。更大的模型ViT-H/14进一步提高了性能,尤其是在更具挑战性的数据集上——ImageNet、CIFAR-100和VTAB套件。有趣的是,这个表2:与流行图像分类基准上的最新技术进行比较。我们报告了精度的平均值和标准偏差,三次微调的平均值。在JFT-300M数据集上预训练的Vision Transformer模型在所有数据集上都优于基于ResNet的基线,同时预训练所需的计算资源要少得多。在较小的公共ImageNet-21k数据集上预训练的ViT也表现良好。*Touvron等人报告的结果略有改善88:5%。(2020)。
model still took substantially less compute to pre-train than prior state of the art. However, we note that pre-training efficiency may be affected not only by the architecture choice, but also other parameters, such as training schedule, optimizer, weight decay, etc. We provide a controlled study of performance vs. compute for different architectures in Section 4.4. Finally, the ViT-L/16 model
pre-trained on the public ImageNet-21k dataset performs well on most datasets too, while taking fewer resources to pre-train: it could be trained using a standard cloud TPUv3 with 8 cores in approximately 30 days.
与现有技术相比,模型预训练所需的计算量仍然大大减少。 然而,我们注意到,预训练效率不仅可能受到架构选择的影响,还可能受到其他参数的影响,如训练计划、优化器、权重衰减等。我们在第4.4节中提供了不同架构的性能与计算的对照研究。最后,在公共ImageNet-21k数据集上预训练的ViT-L/16模型在大多数数据集上也表现良好,同时预训练所需资源较少:它可以在大约30天内使用8种颜色的标准云TPU3进行训练。
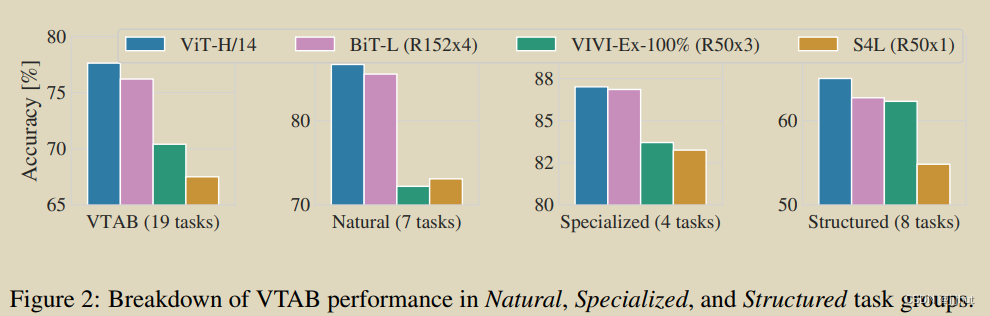
Figure 2 decomposes the VTAB tasks into their respective groups, and compares to previous SOTA methods on this benchmark: BiT, VIVI – a ResNet co-trained on ImageNet and Youtube (Tschannen et al., 2020), and S4L – supervised plus semi-supervised learning on ImageNet (Zhai et al., 2019a). ViT-H/14 outperforms BiT-R152x4, and other methods, on the Natural and Structured tasks. On the Specialized the performance of the top two models is similar.
图2将VTAB任务分解为各自的组,并与该基准上以前的SOTA方法进行比较:BiT、VIVI——在ImageNet和Youtube上共同训练的ResNet(Tschannen et al.,2020),以及S4L——在ImageNet上监督加半监督学习(Zhai et al.,2019a)。ViT-H/14在自然和结构化任务上优于BiT-R152x4和其他方法。在Specialized上,前两款车型的性能相似。
4.3 PRE-TRAINING DATA REQUIREMENTS
The Vision Transformer performs well when pre-trained on a large JFT-300M dataset. With fewer inductive biases for vision than ResNets, how crucial is the dataset size? We perform two series of experiments.
这个视觉自注意力机制在大型JFT-300M数据集上进行预训练时表现良好。与ResNets相比,视觉的归纳偏差更少,数据集的大小有多重要?我们进行了两个系列的实验。
First, we pre-train ViT models on datasets of increasing size: ImageNet, ImageNet-21k, and JFT-300M. To boost the performance on the smaller datasets, we optimize three basic regularization parameters – weight decay, dropout, and label smoothing. Figure 3 shows the results after finetuning to ImageNet (results on other datasets are shown in Table 5)2. When pre-trained on the smallest dataset, ImageNet, ViT-Large models underperform compared to ViT-Base models, despite (moderate) regularization. With ImageNet-21k pre-training, their performances are similar. Only with JFT-300M, do we see the full benefit of larger models. Figure 3 also shows the performance region spanned by BiT models of different sizes. The BiT CNNs outperform ViT on ImageNet, but
with the larger datasets, ViT overtakes.
首先,我们在不断增加的数据集上预训练ViT模型:ImageNet、ImageNet-21k和JFT-300M。为了提高较小数据集的性能,我们优化了三个基本的正则化参数——权重衰减、丢弃和标签平滑。图3显示了微调到ImageNet后的结果(其他数据集的结果如表5所示)2。当在最小的数据集ImageNet上预训练时,尽管(适度)正则化,但与ViT-Base模型相比,ViT-Large模型表现不佳。通过ImageNet-21k的预训练,他们的表现是相似的。只有JFT-300M,我们才能看到更大型号的全部好处。图3还显示了性能由不同大小的BiT模型跨越的区域。BiT细胞神经网络在ImageNet上的表现优于ViT,但在更大的数据集中,ViT超过了它。
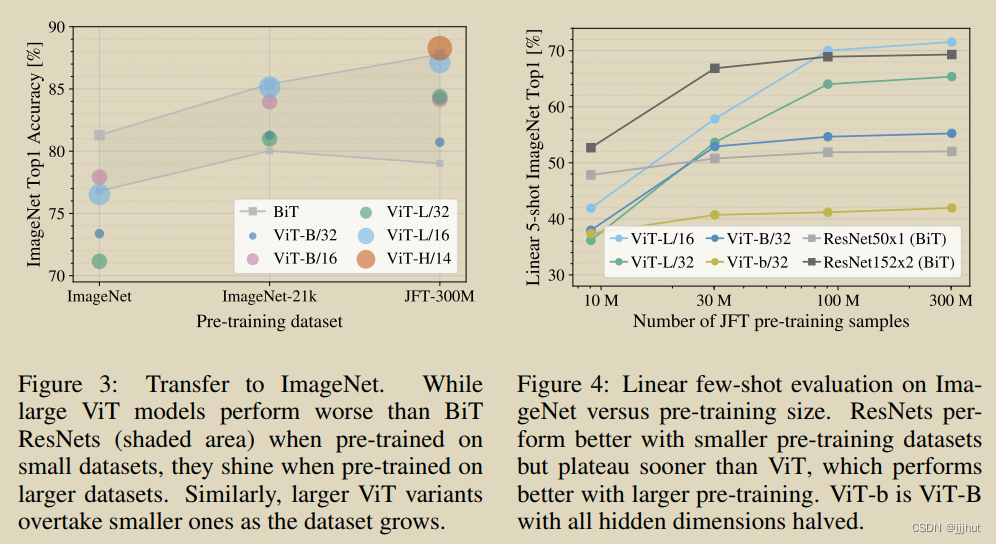

Second, we train our models on random subsets of 9M, 30M, and 90M as well as the full JFT-300M dataset. We do not perform additional regularization on the smaller subsets and use the same hyper-parameters for all settings. This way, we assess the intrinsic model properties, and not the effect of regularization. We do, however, use early-stopping, and report the best validation accuracy
achieved during training. To save compute, we report few-shot linear accuracy instead of full finetuning accuracy. Figure 4 contains the results. Vision Transformers overfit more than ResNets with comparable computational cost on smaller datasets. For example, ViT-B/32 is slightly faster than ResNet50; it performs much worse on the 9M subset, but better on 90M+ subsets. The same is true for ResNet152x2 and ViT-L/16. This result reinforces the intuition that the convolutional inductive bias is useful for smaller datasets, but for larger ones, learning the relevant patterns directly from data is sufficient, even beneficial.
其次,我们在9M、30M和90M的随机子集以及完整的JFT-300M数据集上训练我们的模型。我们不对较小的子集执行额外的正则化,并对所有设置使用相同的超参数。通过这种方式,我们评估了固有的模型属性,而不是正则化的影响。然而,我们确实使用了早期停止,并报告了在训练过程中实现的最佳验证准确性。为了节省计算,我们报告了很少的线性精度,而不是完全的微调精度。图4包含了结果。在较小的数据集上,视觉转换器比具有可比计算成本的ResNets过拟合更多。例如,ViT-B/32比ResNet50稍快;它在9M子集上表现得更差,但在90M+子集上表现更好。ResNet152x2和ViT-L/16也是如此。这一结果强化了这样一种直觉,即卷积归纳偏差对较小的数据集是有用的,但对于较大的数据集,直接从数据中学习相关模式是足够的,甚至是有益的。
Overall, the few-shot results on ImageNet (Figure 4), as well as the low-data results on VTAB(Table 2) seem promising for very low-data transfer. Further analysis of few-shot properties of ViT is an exciting direction of future work.
总体而言,ImageNet上的少量拍摄结果(图4)以及VTAB上的低数据结果(表2)似乎有希望实现非常低的数据传输。进一步分析ViT的few-shot特性是未来工作的一个令人兴奋的方向。
5 CONCLUSION
We have explored the direct application of Transformers to image recognition. Unlike prior works using self-attention in computer vision, we do not introduce image-specific inductive biases into the architecture apart from the initial patch extraction step. Instead, we interpret an image as a sequence of patches and process it by a standard Transformer encoder as used in NLP. This simple,
yet scalable, strategy works surprisingly well when coupled with pre-training on large datasets.Thus, Vision Transformer matches or exceeds the state of the art on many image classification datasets, whilst being relatively cheap to pre-train.
我们已经探索了变形金刚在图像识别中的直接应用。与先前在计算机视觉中使用自注意的工作不同,除了最初的补丁提取步骤外,我们没有在架构中引入图像特定的归纳偏差。相反,我们将图像解释为一系列补丁,并通过NLP中使用的标准Transformer编码器进行处理。这种简单但可扩展的策略与大型数据集上的预训练相结合,效果出奇地好。因此,视觉转换器在许多图像分类数据集上匹配或超过了现有技术,同时预训练相对便宜。
While these initial results are encouraging, many challenges remain. One is to apply ViT to other computer vision tasks, such as detection and segmentation. Our results, coupled with those in Carion et al. (2020), indicate the promise of this approach. Another challenge is to continue exploring selfsupervised pre-training methods. Our initial experiments show improvement from self-supervised
pre-training, but there is still large gap between self-supervised and large-scale supervised pretraining. Finally, further scaling of ViT would likely lead to improved performance.
虽然这些初步成果令人鼓舞,但仍然存在许多挑战。一种是将ViT应用于其他计算机视觉任务,如检测和分割。我们的结果,加上Carion等人的结果。(2020),表明了这种方法的前景。另一个挑战是继续探索自我监督的预训练方法。我们的初步实验表明,自监督预训练有所改进,但与大规模监督预训练相比仍有很大差距。最后,ViT的进一步扩展可能会提高性能。
4.4 SCALING STUDY
We perform a controlled scaling study of different models by evaluating transfer performance from JFT-300M. In this setting data size does not bottleneck the models’ performances, and we assess performance versus pre-training cost of each model. The model set includes: 7 ResNets, R50x1, R50x2 R101x1, R152x1, R152x2, pre-trained for 7 epochs, plus R152x2 and R200x3 pre-trained
for 14 epochs; 6 Vision Transformers, ViT-B/32, B/16, L/32, L/16, pre-trained for 7 epochs, plus L/16 and H/14 pre-trained for 14 epochs; and 5 hybrids, R50+ViT-B/32, B/16, L/32, L/16 pretrained for 7 epochs, plus R50+ViT-L/16 pre-trained for 14 epochs (for hybrids, the number at the end of the model name stands not for the patch size, but for the total dowsampling ratio in the ResNet backbone).
我们通过评估JFT-300M的传输性能,对不同模型进行了受控缩放研究。在这种情况下,数据大小不会成为模型性能的瓶颈,我们评估每个模型的性能和预训练成本。模型集包括:7个ResNets,R50x1,R50x2 R101x1,R152x1,R152x2,预训练7个时期,加上R152x2和R200x3预训练14个时期;6个视觉转换器,ViT-B/32,B/16,L/32,L/16,预训练7个时期,加上L/16和H/14预训练14个时期;和5个杂交种,R50+ViT-B/32,B/16,L/32,L/16预训练7个时期,加上R50+ViT-L/16预培训14个时期(对于杂交种,模型名称末尾的数字不是代表补丁大小,而是代表ResNet主干中的总下采样率)。
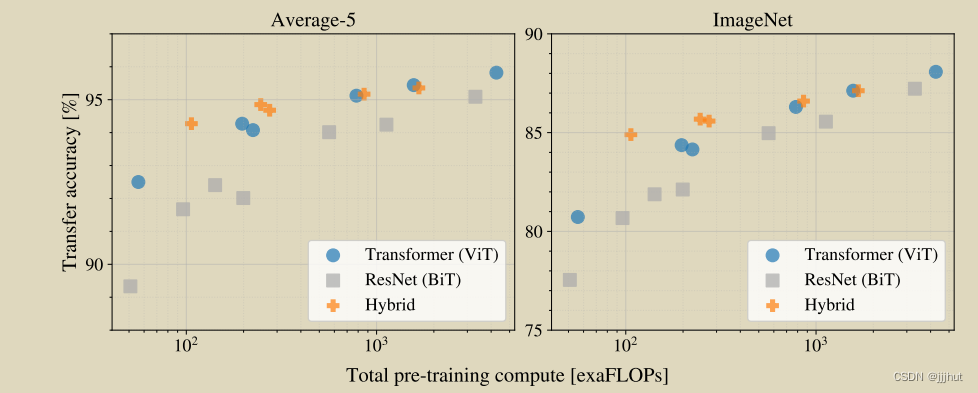
Figure 5 contains the transfer performance versus total pre-training compute (see Appendix D.5 for details on computational costs). Detailed results per model are provided in Table 6 in the Appendix. A few patterns can be observed. First, Vision Transformers dominate ResNets on the performance/compute trade-off. ViT uses approximately 2 − 4× less compute to attain the same performance (average over 5 datasets). Second, hybrids slightly outperform ViT at small computational budgets, but the difference vanishes for larger models. This result is somewhat surprising, since one might expect convolutional local feature processing to assist ViT at any size. Third, Vision Transformers appear not to saturate within the range tried, motivating future scaling efforts.
图5包含转移性能与训练前总计算的对比(有关计算成本的详细信息,请参见附录D.5)。每个模型的详细结果见附录中的表6。可以观察到一些模式。首先,视觉转换器在性能/计算权衡方面占据了ResNets的主导地位。ViT使用大约2−4×更少的计算来获得相同的性能(5个数据集的平均值)。其次,在较小的计算预算下,混合动力车的表现略优于ViT,但对于较大的模型,这种差异会消失。这一结果有些令人惊讶,因为人们可能期望卷积局部特征处理在任何大小下都能帮助ViT。第三,视觉变形金刚似乎没有在尝试的范围内饱和,这激励了未来的扩展努力。
4.5 INSPECTING VISION TRANSFORMER
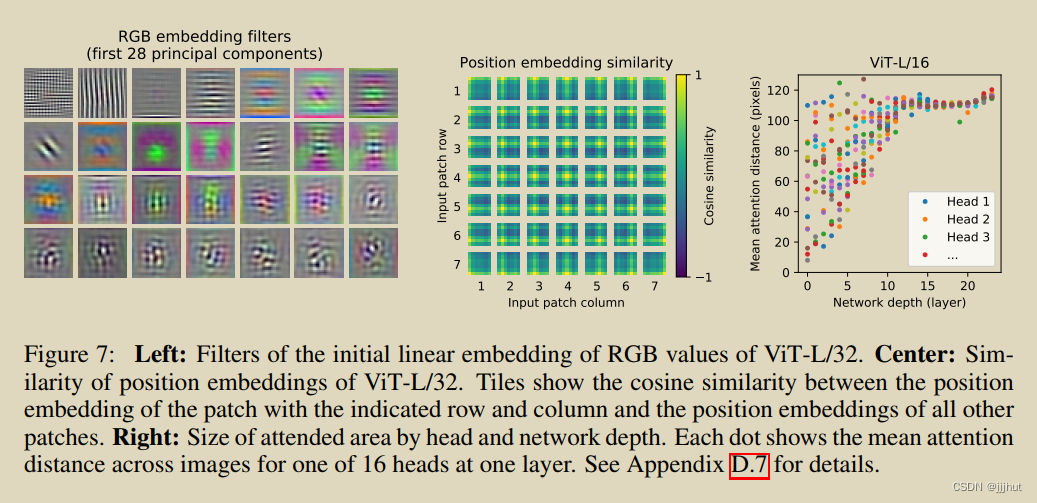
To begin to understand how the Vision Transformer processes image data, we analyze its internal representations. The first layer ofthe Vision Transformer linearly projects the flattened patches into a lower-dimensional space (Eq. 1). Figure 7 (left) shows the top principal components of the the learned embedding filters. The components resemble plausible basis functions for a low-dimensional
representation of the fine structure within each patch.
为了开始了解视觉转换器是如何处理图像数据的,我们分析了它的内部表示。视觉转换器的第一层将平坦的贴片线性投影到较低维空间中(等式1)。图7(左)显示了学习的嵌入滤波器的顶部主要组件。这些成分类似于每个贴片内精细结构的低维表示的合理基函数。

After the projection, a learned position embedding is added to the patch representations. Figure 7 (center) shows that the model learns to encode distance within the image in the similarity of position embeddings, i.e. closer patches tend to have more similar position embeddings. Further, the row-column structure appears; patches in the same row/column have similar embeddings. Finally, a sinusoidal structure is sometimes apparent for larger grids (Appendix D). That the position embeddings learn to represent 2D image topology explains why hand-crafted 2D-aware embedding variants do not yield improvements (Appendix D.4).
在预测之后,学习的位置嵌入被添加到补丁表示中。图7(中心)显示,该模型学习在位置嵌入的相似性中对图像内的距离进行编码,即,更接近的补丁往往具有更相似的位置嵌入。此外,出现行-列结构;同一行/列中的补丁具有相似的嵌入。最后,正弦结构有时对于较大的网格是明显的(附录D)。位置嵌入学会了表示2D图像拓扑,这解释了为什么手工制作的2D感知嵌入变体不能产生改进(附录D.4)。
Self-attention allows ViT to integrate information across the entire image even in the lowest layers. We investigate to what degree the network makes use of this capability. Specifically, we compute the average distance in image space across which information is integrated, based on the attention weights (Figure 7, right). This “attention distance” is analogous to receptive field size in CNNs.
自关注允许ViT在整个图像中集成信息,即使是在最底层。我们调查网络在多大程度上利用了这种能力。具体来说,我们根据注意力权重计算图像空间中信息整合的平均距离(图7,右)。这种“注意距离”类似于细胞神经网络中的感受野大小。
We find that some heads attend to most of the image already in the lowest layers, showing that the ability to integrate information globally is indeed used by the model. Other attention heads have consistently small attention distances in the low layers. This highly localized attention is less pronounced in hybrid models that apply a ResNet before the Transformer (Figure 7, right), suggesting that it may serve a similar function as early convolutional layers in CNNs. Further, the
attention distance increases with network depth. Globally, we find that the model attends to image regions that are semantically relevant for classification (Figure 6).
我们发现,一些头部已经处理了最底层的大部分图像,这表明模型确实使用了全局集成信息的能力。其他注意力头部在低层中的注意力距离一直很小。这种高度本地化的注意力在转换器之前应用ResNet的混合模型中不太明显(图7,右),这表明它可能与细胞神经网络中的早期卷积层具有类似的功能。此外,注意力距离随着网络深度的增加而增加。在全球范围内,我们发现该模型关注与分类在语义上相关的图像区域(图6)。
4.6 SELF-SUPERVISION
Transformers show impressive performance on NLP tasks. However, much of their success stems not only from their excellent scalability but also from large scale self-supervised pre-training (Devlinet al., 2019; Radford et al., 2018). We also perform a preliminary exploration on masked patch prediction for self-supervision, mimicking the masked language modeling task used in BERT. With
self-supervised pre-training, our smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant improvement of 2% to training from scratch, but still 4% behind supervised pre-training. Appendix B.1.2 contains further details. We leave exploration of contrastive pre-training (Chen et al., 2020b; He et al., 2020; Bachman et al., 2019; Henaff et al., 2020) to future work.
Transformers显示的令人印象深刻的业绩,在自然语言的任务。 然而,从他们的成功源不仅仅从它们的优良的可伸缩性,也来自于大规模的自我监督的预训练(Devlinet al., 2019年;拉德福et al., 2018年). 我们还执行一个初步的勘探上贴片掩盖预测的自我监督,模仿的掩蔽的语言模特任务中使用的伯特。 与自监督下的预培训、我们的小型维生素B/16型,实现了79.9%的精确度上ImageNet,显着改善的2%,以培训从头开始,但仍有4%的背后监督的预培训。 附录B.1.2包含进一步的细节。 我们离开的探索对比前培训(Chen等人, 2020b;他et al., 2020年;Bachman et al., 2019年;Henaff et al., 2020年)以来的工作。
5 CONCLUSION
We have explored the direct application of Transformers to image recognition. Unlike prior works using self-attention in computer vision, we do not introduce image-specific inductive biases into the architecture apart from the initial patch extraction step. Instead, we interpret an image as a sequence of patches and process it by a standard Transformer encoder as used in NLP. This simple,
yet scalable, strategy works surprisingly well when coupled with pre-training on large datasets. Thus, Vision Transformer matches or exceeds the state of the art on many image classification datasets, whilst being relatively cheap to pre-train.
我们已经探索了注意力机制在图像识别中的直接应用。与先前在计算机视觉中使用自注意的工作不同,除了最初的补丁提取步骤外,我们没有在架构中引入图像特定的归纳偏差。相反,我们将图像解释为一系列补丁,并通过NLP中使用的标准Transformer编码器进行处理。这种简单但可扩展的策略与大型数据集上的预训练相结合,效果出奇地好。因此,视觉转换器在许多图像分类数据集上匹配或超过了现有技术,同时预训练相对便宜。
While these initial results are encouraging, many challenges remain. One is to apply ViT to other computer vision tasks, such as detection and segmentation. Our results, coupled with those in Carion et al. (2020), indicate the promise of this approach. Another challenge is to continue exploring selfsupervised pre-training methods. Our initial experiments show improvement from self-supervised
pre-training, but there is still large gap between self-supervised and large-scale supervised pretraining. Finally, further scaling of ViT would likely lead to improved performance.
虽然这些初步成果令人鼓舞,但仍然存在许多挑战。一种是将ViT应用于其他计算机视觉任务,如检测和分割。我们的结果,加上Carion等人的结果。(2020),表明了这种方法的前景。另一个挑战是继续探索自我监督的预训练方法。我们的初步实验表明,自监督预训练有所改进,但与大规模监督预训练相比仍有很大差距。最后,ViT的进一步扩展可能会提高性能。
声明
本文的内容和图来自论文AN IMAGE IS WORTH 16X16 WORDS:
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE.