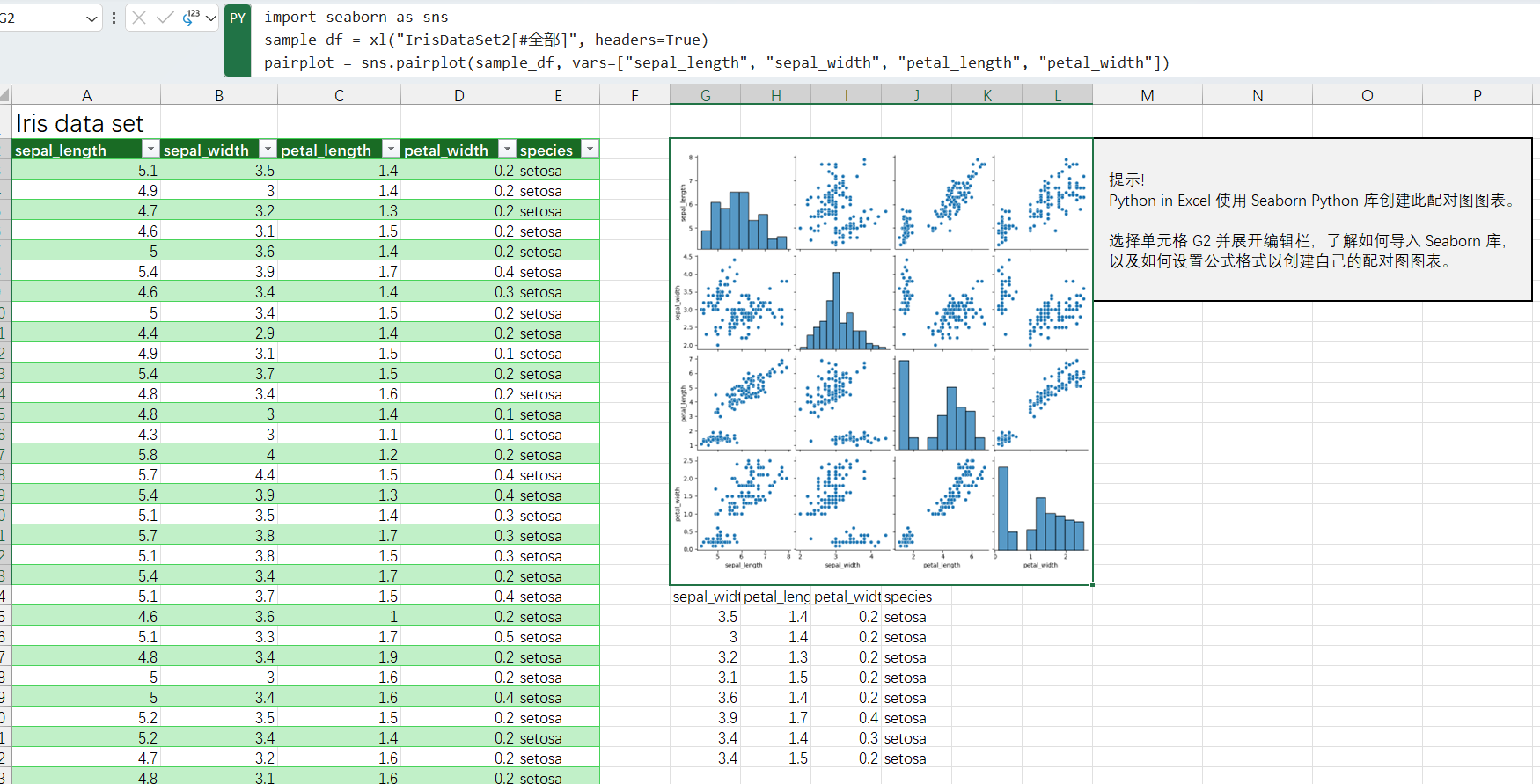
Langchain提供了多种文本分割器,包括CharacterTextSplitter(),MarkdownHeaderTextSplitter(),RecursiveCharacterTextSplitter()等,各种Splitter的作用如下图所示:

TextSplitter
下面的代码是使用RecursiveCharacterTextSplitter对一段文字进行分割。
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitterchunk_size = 20
chunk_overlap = 4r_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
c_splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)text = "hello world, how about you? thanks, I am fine. the machine learning class. So what I wanna do today is just spend a little time going over the logistics of the class, and then we'll start to talk a bit about machine learning"
rs = r_splitter.split_text(text)
print(type(rs))
print(len(rs))
for item in rs:print(item)分割后,得到的结果如下所示,每一段chunk尽量和chunk_size贴近,每个chunk之间也有overlap。RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置.在项目中也推荐使用RecursiveCharacterTextSplitter来进行分割。
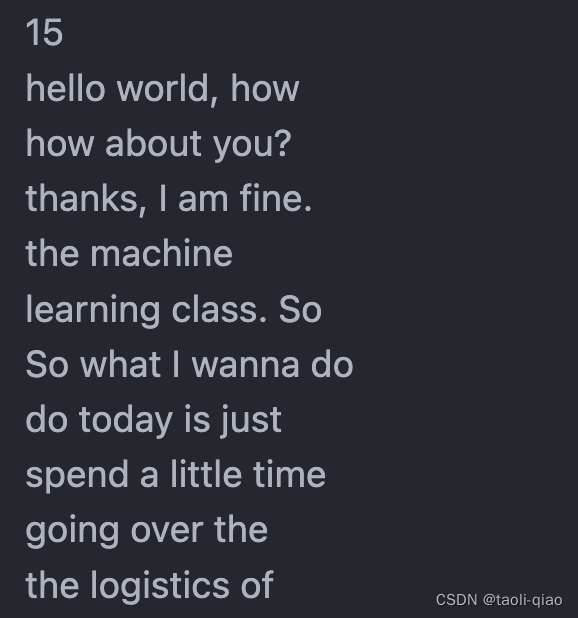
如果直接用CharacterSplitter进行分割,分割后的List长度是1,分割后得到的内容如下所示:为什么没有被分割呢?因为CharacterSpliter的默认分割符号是换行符号\n,上面的句子没有多个换行符号,所以,分割后还有List的长度仍然是1.

如果将splitter设置为空格,那么拆分后的List长度等于14,可以看到会按空格拆分,且每个chunk的大小尽量和chunk_size的值贴近。
c_splitter = CharacterTextSplitter(separator=' ',chunk_size=chunk_size, chunk_overlap=chunk_overlap)
TokenSplitter
接下来再来看看基于Token对文本进行切割,下面的代码调用TokenTextSplitter对一段文本进行分割,也就是按照token的数量大小来对文本进行分割。为什么会有按token来切割文本的方式呢?因为,很多LLM的上下文窗口长度限制是按照Token来计数的。因此,以LLM的视角,按照Token对文本进行分隔,通常可以得到更好的结果。
from langchain.text_splitter import TokenTextSplittertext = "hello world, how about you? thanks, I am fine. the machine learning class. So what I wanna do today is just spend a little time going over the logistics of the class, and then we'll start to talk a bit about machine learning"
token_splitter = TokenTextSplitter(chunk_size=20, chunk_overlap=5)
rs = token_splitter.split_text(text)
print(len(rs))
for item in rs:print(item)执行上面的代码,切割后的List的大小是4,每一部分是按照token数量=20的范围来对文本进行切分的。

MarkdownHeaderSplitText
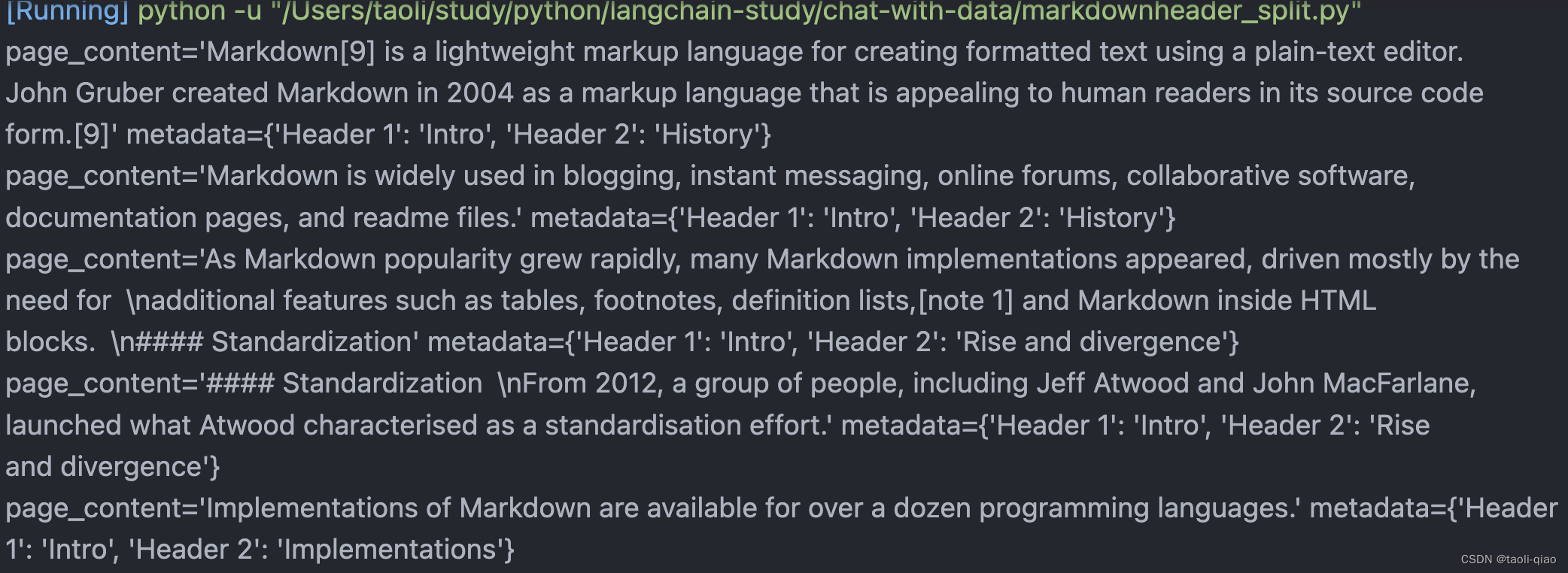
接下来再看看基于MarkdownHeader的分割方式,分块的目的是把具有上下文的文本放在一起,我们可以通过使用指定分隔符来进行分隔,但有些类型的文档(例如 Markdown)本身就具有可用于分割的结构(如标题)。Markdown标题文本分割器会根据标题或子标题来分割一个Markdown文档,并将标题作为元数据添加到每个块中。下面的这段代码来自官网的例子,通过#和##对一段文本进行拆分,因为文本中出现了一次#,和两次##,拆分后,文本被切分成了三段。
from langchain.text_splitter import MarkdownHeaderTextSplittermarkdown_document = "# Intro \n\n ## History \n\n Markdown[9] is a lightweight markup language for creating formatted text using a plain-text editor. John Gruber created Markdown in 2004 as a markup language that is appealing to human readers in its source code form.[9] \n\n Markdown is widely used in blogging, instant messaging, online forums, collaborative software, documentation pages, and readme files. \n\n ## Rise and divergence \n\n As Markdown popularity grew rapidly, many Markdown implementations appeared, driven mostly by the need for \n\n additional features such as tables, footnotes, definition lists,[note 1] and Markdown inside HTML blocks. \n\n #### Standardization \n\n From 2012, a group of people, including Jeff Atwood and John MacFarlane, launched what Atwood characterised as a standardisation effort. \n\n ## Implementations \n\n Implementations of Markdown are available for over a dozen programming languages."headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
rs = markdown_splitter.split_text(markdown_document)
print(len(rs))
for item in rs:print(item)代码执行结果如下图所示,List的lenth是3.

对于markdown文档而言,如果只对一二级标题进行切割,切割后的文本可能会过大,比如超过LLM的上下文窗口大小,所以,切割后的内容,还可以继续使用RecursiveCharacterSplitter做进一步的切分。
chunk_size = 250
chunk_overlap = 30
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
# Split
splits = text_splitter.split_documents(rs)
for item in splits:print(item)切分后的结果如下图所示:
以上就是对Langchain提供的文本切割使用的介绍。