一文了解应用层协议:HTTP协议
- 一、HTTP协议
- 二、URL
- 2.1 urlencode和urldecode
- 三、HTTP协议格式
- 3.1 HTTP请求方法
- 3.2 HTTP状态码
- 3.3 HTTP响应报头
- 四、结合代码理解HTTP通信流程
- 五、长连接
- 六、http会话保持
- 七、postman和fiddler
一、HTTP协议
在上篇文章中我们模拟了一个应用层协议,HTTP(超文本传输协议)就是其中之一。http就是通过http协议从服务器上读取对应的“资源”,这里所说的资源是在网络上看到的一切都可以看成资源文件;访问资源就是根据路径,从服务器磁盘上拿取资源
二、URL
平时我们俗称的 “网址” 其实就是说的 URL

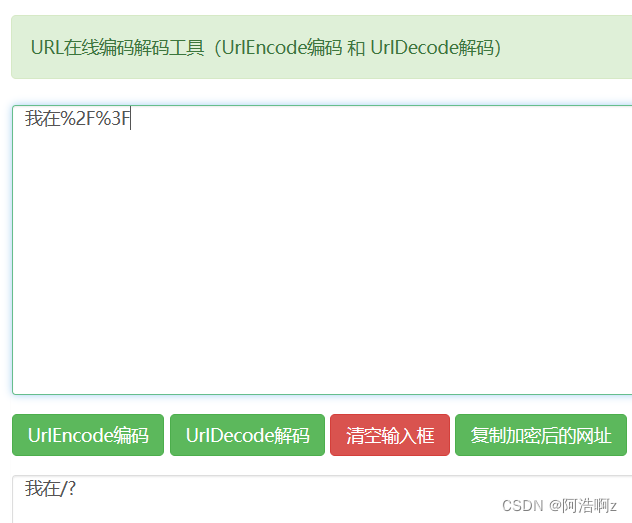
2.1 urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY,如下图
三、HTTP协议格式
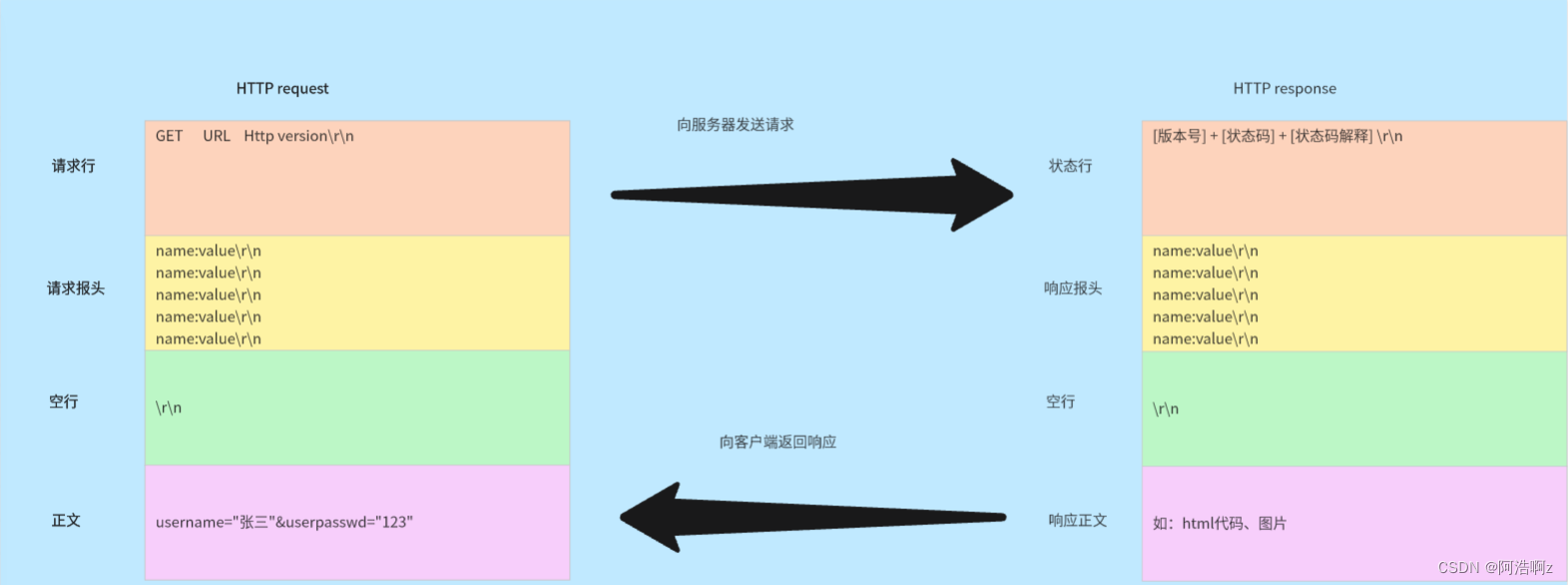
细节问题;
- 请求和响应怎么保证应用层完整读取完毕
a.读取完整的一行
b. while(每次读取完整的一行);将所有的请求行和请求报头全部读完,直到空行!
c.报头有一个属性:Content-Length:得到正文长度
d.解析出来内容长度,根据内容长度,读取正文即可 - 请求和响应是怎么做到序列化和反序列化的?
a.http自己根据特殊字符(\r\n)实现的,序列化的时候挨个进入流里,反序列化以\r\n作为分隔符
b.正文不需要
3.1 HTTP请求方法
| 方法 | 说明 | 支持版本 |
|---|---|---|
| GET | 获取资源 | 1.0/1.1 |
| POST | 传输实体主体 | 1.0/1.1 |
二者区别:
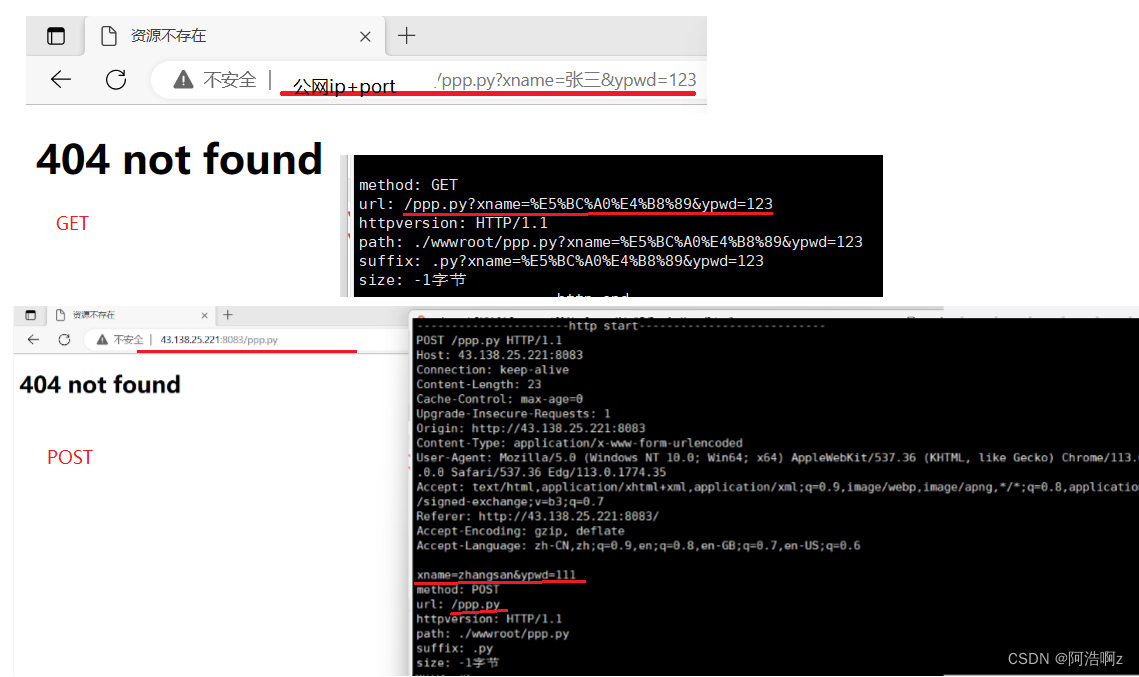
get:通过url传递参数,具体如上图,这也注定传递的参数不能太大
post:提交参数通过http请求的正文提交参数,一般用户看不到,私密性很好不等于安全性;正文可以很大,也可以是其他东西
3.2 HTTP状态码
HTTP状态码是由服务器返回给客户端的三位数字代码,用于表示客户端请求的处理状态。以下是常见的HTTP状态码及其描述:
-
1xx(信息性状态码):表示请求已被接收,继续处理。
-
2xx(成功状态码):表示请求已成功被服务器接收、理解、并接受。
200 OK:请求成功。 -
3xx(重定向状态码):客户端发送请求,服务器返回3XX状态码和一个新的URL,客户端拿着这个新的URL再次请求服务器,这就是重定向。
301 Moved Permanently:永久性重定向。
302 Found:临时性重定向。 -
4xx(客户端错误状态码):表示客户端请求出错,服务器无法处理请求。
404 Not Found:服务器无法找到请求的资源。(属于客户端错误,客户端请求资源在服务器不存在) -
5xx(服务器错误状态码):表示服务器处理请求出错。
500 Internal Server Error:服务器内部错误。
这里重点说一下重定向
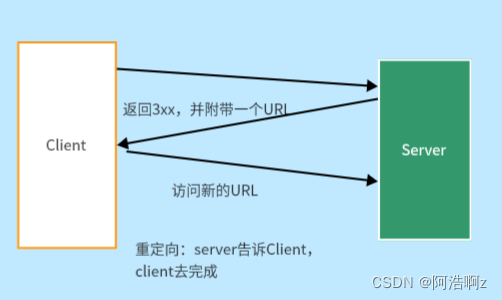
永久重定向:新旧网站,如果有人访问旧网站,会自动调到新网站
临时重定向:
std::string respline = "HTTP/1.1 307 Temporary Redirect\r\n";//临时重定向状态行// 搭配响应报头重定向到指定页面
respheader += "Location: https://mp.csdn.net/?spm=1030.2200.3001.8539\r\n";3.3 HTTP响应报头
HTTP协议常见的响应报头包括:
- Content-Type: 数据类型(text/html等)
- Content-Length: 正文的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- Location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问(上述重定向);
- Set-Cookie: 指定会话中的信息
四、结合代码理解HTTP通信流程
完整版代码参考我的码云
一、服务器收到请求,调用处理方法HandlerHttp
void HandlerHttp(int sock)
{char buffer[4096];HttpRequst req;HttpResponse resp;//读取请求size_t n=recv(sock,buffer,sizeof(buffer)-1,0);if(n>0){buffer[n]=0;req.inbuffer=buffer;req.parse();func_(req,resp);send(sock,resp.outbuffer.c_str(),resp.outbuffer.size(),0);}
}
二、函数内部开始执行相应操作:
- 读取请求并放入缓冲区,将缓冲区数据赋值给请求类对象的成员inbuffer;
- 调用请求类的parse()函数,parse函数调用工具类中的getOneLine方法读取到请求行内容,将读取内容反序列化到成员变量中,得到请求方法,URL,版本号
//Protocol.hpp
#pragma once#include <iostream>
#include <string>
#include <sstream>
#include <sys/types.h>
#include <unistd.h>
#include <sys/stat.h>
#include "Util.hpp"const std::string sep = "\r\n";
const std::string default_root = "./wwwroot";
const std::string home_page = "index.html";
const std::string html_404 = "wwwroot/404.html";class HttpRequst
{
public:HttpRequst() {}~HttpRequst() {}void parse(){// 1.从inbuffer中拿到第一行,分隔符\r\nstd::string line = Util::getOneLine(inbuffer, sep);if (line.empty())return;// 2.从请求行提取三个字段//2.1 /aa.py?name=zhangsan&pwd=123//通过?将左右分离//post自动分离,get需要手动分离 //左边:PATH 右边parm std::stringstream ss(line);ss >> method >> url >> httpversion;// 3.添加web默认路径//客户端所有请求路径前都会被加上./wwwroot前导目录字符串path = default_root; // ./wwwrootpath += url; //./wwwroot/a.html//如果请求的是web根目录/,默认路径改为./wwwroot/index.htmlif (path[path.size() - 1] == '/') // 默认路径,path += home_page;// 4.获取path对应的后缀auto pos = path.rfind(".");if (pos == std::string::npos)suffix = ".html";elsesuffix = path.substr(pos);// 5.根据路径获取获取正文大小【即客户端请求资源的大小】struct stat st;int n = stat(path.c_str(), &st);if (n == 0)size = st.st_size;elsesize = -1;}public:std::string inbuffer;std::string method; // 请求方式std::string url; // 网址std::string httpversion; // 版本号std::string path; // 路径std::string suffix; // 后缀int size;//资源大小
};class HttpResponse
{
public:std::string outbuffer;
};
- 回调函数,调用提供的Get方法:
a.先打印出服务端所读取到的完整内容inbuffer;再挨个打印不同的属性
b.手动编写状态行respline;
c.构建响应报头,多个{key:value}组合而成,包括Content-Type,Content-Length;Set-Cookie
d.构建空行respblank
e.调用工具类方法readFile(),通过文件路径找到文件,以二进制的方式将数据读取到body正文里面
c.将以上内容添加到响应类的成员变量outbuffer
//根据访问资源后缀,选择不同的数据类型
std::string suffixToDesc(const std::string suffix)
{std::string ct = "Content-Type: ";if (suffix == ".html")ct += "text/html";else if (suffix == ".jpg")ct += "application/x-jpg;image/jpeg";ct += "\r\n";return ct;
}// 1.服务器与网页分离
// 2.url中的/是web根目录,不是linux的根目录
// 3.正确的给客户端返回资源类型,根据后缀辨别
bool Get(const HttpRequst &req, HttpResponse &resp)
{cout << "----------------------http start---------------------------" << endl;cout << req.inbuffer << endl;std::cout << "method: " << req.method << std::endl;std::cout << "url: " << req.url << std::endl;std::cout << "httpversion: " << req.httpversion << std::endl;std::cout << "path: " << req.path << std::endl;std::cout << "suffix: " << req.suffix << std::endl;std::cout << "size: " << req.size << "字节" << std::endl;cout << "----------------------http end---------------------------" << endl;std::string respline = "HTTP/1.0 200 OK\r\n"; // 状态行// std::string respline = "HTTP/1.1 307 Temporary Redirect\r\n";//临时重定向std::string respheader = suffixToDesc(req.suffix); // 根据后缀编写响应报头//添加cookierespheader += "Set-Cookie: name=1234567abcdefg; Max-Age=120\r\n";// 重定向到指定页面// respheader += "Location: https://mp.csdn.net/?spm=1030.2200.3001.8539\r\n";std::string respblank = "\r\n"; // 空行std::string body; // 正文body.resize(req.size + 1);// 根据访问文件路径,读取文件内容放到body里if (!Util::readFile(req.path, (char *)body.c_str(), req.size)){Util::readFile(html_404, (char *)body.c_str(), req.size); // 读不到返回404}respheader += "Content-Length: "; // 正文部分大小respheader += std::to_string(body.size());respheader += "\r\n";resp.outbuffer += respline;resp.outbuffer += respheader;resp.outbuffer += respblank;cout << "-----------------http response stat-----------" << endl;cout << resp.outbuffer << endl;cout << "-----------------http response end-----------" << endl;resp.outbuffer += body;return true;
}
- 发送给客户端
五、长连接
访问一个网页,网页中包含多个元素,需要多次发起http请求,但是http请求是基于tcp的,tcp又是面向连接的,存在频繁创建问题;为了减少连接次数,需要客户端和服务器均支持长链接:建立一条连接,传输一份大的资源通过同一条连接完成。
Connection: keep-alive//开启长连接
Connection: close//关闭长连接
六、http会话保持
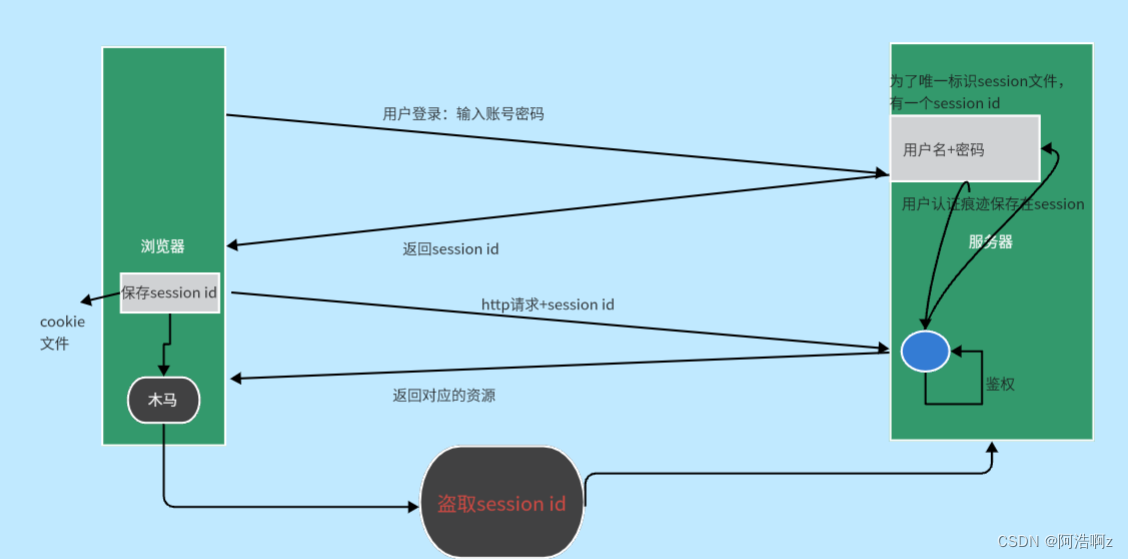
会话保持:当我们登录一个网页的时候,短时间内再打开是不需要再次输入账号密码的;在同一个网站发生页面跳转,浏览器会记住上一次登录的信息,也不需要重新登陆,这就是会话保持。
http是无状态的:他不会记录历史曾经访问过的请求;但是用户需要,所以浏览器为了满足用户的使用需求,做了相应的工作(缓存)。
用户在首次输入账号和密码时,浏览器会将账号密码进行保存(Cookie技术),近期再次访问同一个网站,浏览器会自动将用户信息推送给服务器。这样就变成了服务器与浏览器进行交互,客户只要关心的只有登录一次短期内不登录了
新方案中,服务器会对每个用户创建一份独有的session文件,并且有唯一标识该文件的session id,并将其返回给浏览器,浏览器会把session id保存。但这样只能保证服务端存储的账号密码不会被泄漏,黑客利用木马盗取了用户的session id后仍可以非法登录,只能靠服务端的安全策略保障安全。
例如账号被异地登录了,服务端察觉后只要让session id失效即可,一定程度保证了安全。
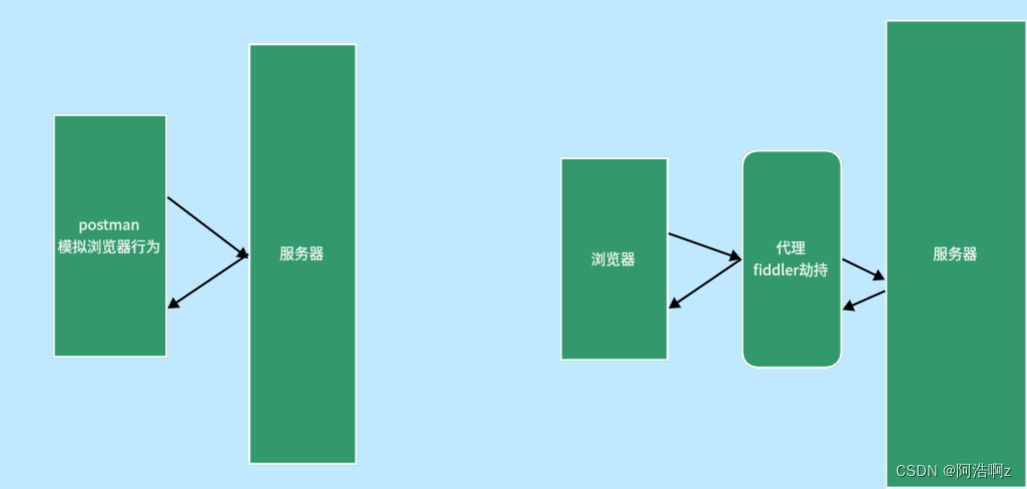
七、postman和fiddler
postman:能够模拟客户端浏览器的行为
fiddler:一个本地抓包工具,作为http调试使用,能够明文抓到本地的POST方法请求正文!