字符串哈希
- 1.原理
- 2.实现
- 3.应用
1.原理
从主串中找目标串,一种思路是枚举所有的子串,判断子串是否与目标串相同,子串长度过长,
substr方法耗时过长;
考虑另外一种方法,字符串哈希。使用前缀和的形式为每个子串进行编码,得到每个子串的hash_code; 例如:s = “abcd”,假设字符串中都是小写字母,字符串可以用26进制表示,s的哈希编码可以表示为:
hashcode = 'a'*26^3 + 'b'*26^2 + 'c'*26^1 + 'd'*26^0
即越左边的字符,位数越高;s="abcd"也可以表示为10进制数
hashcode = ('a'-'a')*10^3 + ('b'-'a')*10^2 + ('c'-'a')*10^1 + ('d'-'a')*10^0
子串s1 = “bcd” 的哈希编码可以用前缀和之差表示, 假设编码函数为hash_code(x)
hash_code("bcd") = hash_code("abcd") - hash_code("a") * 26^(3-1+1)
即"bcd"的哈希编码可由“abcd”的哈希编码减去“a”的哈希编码; 26^(3-1+1)表示,我们要减去的是最高位的“a”,因位越是左边的字符,在表示过程中数位实际是越高的,比如
1234, 1对应的是千位,1*10^3,2是百位,2*10 ^2,依次类推
2.实现
#include<iostream>
#include<string>
#include<vector>
using namespace std;
typedef unsigned long long ULL;ULL X = 13331;
vector<ULL> h, x;void Hash(string &s) {int n = s.length();//初始化 h[0] = s[0];x[0] = 1;//进位 abc = a*26^2 + b*26^1 + c*26^0for (int i = 1; i < n; i++) {h[i] = h[i-1]*X + s[i];x[i] = x[i-1]*X;}
}ULL getHashCode(int left, int right) {if (!left) {return h[right];}//前缀和求子子串的哈希code
// "abcde" right = 3 'd', left = 1 'b'
// h[right] - h[left-1] = abcd - a = bcd 的哈希 ULL ans = h[right] - h[left-1] * x[right-left+1];return ans;// return left ? h[right] - h[left-1] * x[right-left+1] : h[right];
}int main() {string s1;cin >> s1;h.resize(s1.length());x.resize(s1.length());Hash(s1);string s2;cin >> s2;ULL hash2 = 0;for (int i = 0; i < s2.length(); i++) {hash2 = hash2 * X + s2[i];}for (int i = 0; i < s1.length(); i++) {int start = i;int end = min(s1.length()-1,i+s2.length()-1);cout << getHashCode(start,end) << " ";}cout << endl;cout << hash2 << endl;return 0;
}
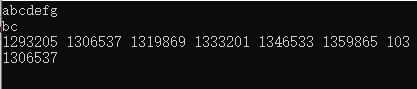
输入 s = “abcdefg”, t = "bc"可以看到s中包含t的编码; 以通过字符串哈希的预处理方式,以o(n)的时间复杂度可以判断主串中是否包含目标字符串t。
3.应用
力扣1044 最长重复子串
方法:字符串哈希 + 二分
题目要求从字符串中找到最长的重复子串,重复子串是指出现两次或两次以上的子串,例如
输入:s = “banana”
输出:“ana”
这道题分为两步:
第一步:枚举子串;
第二步:判断子串是否重复出现过。这一步可以用hashset存子串,如果子字符串在hashset中出现过,则看其是否为更长的重复子串,于是可以写出第一版代码:
string longestDupSubstring1(string s) {int n = s.length();unordered_set<string> st;int start = 0, maxlen = 0;for (int i = 0; i < n; i++) {for (int j = i; j < n; j++) {string substr = s.substr(i,j-i+1);if (st.find(substr) != st.end()) {if (j-i+1 > maxlen) {maxlen = j-i+1;start = i;} }st.insert(substr);}}cout << start << endl;return s.substr(start,maxlen);}
但是,上述代码的时间复杂度为 O(n^2) * substr * find; 两重for循环,取子串的函数substr,都有较高的时间复杂度;unordered_set底层实现的数据结构为哈希表,数据插入和查找的时间接近常数,对象在容器中的位置由它们的哈希值决定。
初始化方式:
std::unordered_set<string> things {16}; // 16 buckets
std::unordered_set<string> words {"one", "two", "three", "four"};// Initializer list
std::unordered_set<string> some_words {++std::begin(words), std::end (words)}; // Range
std::unordered_set<string> copy_wrds {words}; // Copy constructor
需要改进时间复杂度。使用二分法枚举子串长度,替代二重for循环;检查每个长度为len的子串中最长的重复子串长度,
从s中找出长度为mid的重复的子串
若s存在长度为mid的重复子串,则移动左指针,mid(子串长度)也进一步增加,判断s中有更长的重复子串;
若s不存在长度为mid的重复的子串,移动右指针,使得子串长度mid缩小。
二分法的过程如下
初始化 left = 0, right = n-1
while (left <= right) {int mid = (left + right) / 2;//在s中查找是长度为mid的重复子串string str = check(s,mid); if (str.size() != 0 ){left = mid + 1;}else{right = mid - 1;}//比较ans和str哪个更长,str更长则更新ansans = ans.length() > str.length() ? ans : str;
}
第一步,时间复杂度,二分查找O(log n), 重复子串查找,O(n), 时间复杂度O(nlogn)。
第二步,在s中查找是长度为mid的重复子串。实现check(s,mid)函数,需要用到字符串哈希,用map存子串的hash值及出现次数,如果子串出现次数>=2; 说明重复返回长度为mid的子串。
具体实现,字符串哈希对字符串做预处理,这样在check(s,mid)函数时,check s中长度为mid的子串,可以用前缀和之差形式表示 子串的哈希值。具体实现:
class Solution {
private:typedef unsigned long long ULL;vector<ULL> h;vector<ULL> x;int X = 13331;void hash_func(string &s) {int n = s.length();h.resize(n);x.resize(n);h[0] = s[0];x[0] = 1;for (int i = 1; i < n; i++) {h[i] = h[i-1] * X + s[i];x[i] = x[i-1] * X;}}public:string longestDupSubstring(string s) {int n = s.length();hash_func(s);int left = 0, right = n;string ans = "";while (left < right) {int mid = (left+right+1)>>1;string str = check(s,mid);if (str.size() != 0) {left = mid;} else {right = mid - 1;}ans = ans.length() > str.length() ? ans : str;}return ans;}string check(string &s, int len){int n = s.length();string ans = "";unordered_map<ULL,int> mp;for (int i = 0; i + len <= n; i++) {int j = i + len -1;ULL hash = (i>0) ? h[j] - h[i-1] * x[j-i+1] : h[j];if (mp[hash]) {ans = s.substr(i,len);;break;}++mp[hash];}return ans;}
};
参考:
STUACM-算法讲堂-字符串哈希(hash)
字符串双哈希 + 二分
C++ unordered_set定义及初始化详解