【Bert、T5、GPT】fine tune transformers 文本分类/情感分析
- 0、前言
- text classification
- emotions 数据集
- data visualization analysis
- dataset to dataframe
- label analysis
- text length analysis
- text => tokens
- tokenize the whole dataset
- fine-tune transformers
- distilbert-base-uncased
- trainer
- result analysis
- to huggingface hub
0、前言
是一个情感分类的项目,前面是对emotion数据集的处理和分析,以及将整个数据集分词以及处理成模型的输入形式。
主要是通过加载一个文本分类的预训练模型,然后在数据集上面进emotion数据集上面的fine-tuning。然后对训练好的模型进行效果的分析,包括F1,Precision和Recall等。
colab完整代码:https://drive.google.com/file/d/1miHJRZp0vusYrSslQ52_HOWLizrYfOkN/view?usp=sharing
稍后挂上完整的代码下载链接。
首先安装所需要的包
!pip install transformers==4.28.0
pip install datasets
导入包:
import torch
from torch import nn
import transformers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
预定义一些辅助函数。
# import importlib
# importlib.reload(py_file)
# import torch
# import numpy as np
# import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix# for classification
def plot_confusion_matrix(y_preds, y_true, labels):cm = confusion_matrix(y_true, y_preds, normalize="true")fig, ax = plt.subplots(figsize=(4, 4))disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)disp.plot(cmap="Blues", values_format=".2f", ax=ax, colorbar=False)plt.title("Normalized confusion matrix") # trainable parameters of the model
def get_params(model):model_parameters = filter(lambda p: p.requires_grad, model.parameters())# 用filter函数过滤掉那些不需要梯度更新的参数,只保留那些需要梯度更新的参数,然后把它们放在一个变量,叫做model_parameters。这个变量也是一个迭代器。params = sum([np.prod(p.size()) for p in model_parameters])# 用一个列表推导式遍历model_parameters中的每个参数,然后用np.prod函数计算每个参数的元素个数。np.prod函数的作用是把一个序列中的所有元素相乘。例如,如果一个参数的形状是(2, 3),那么它的元素个数就是2 * 3 = 6。然后把所有参数的元素个数加起来,得到一个总和,放在一个变量,叫做params。return paramsdef compute_classification_metrics(pred):# pred: PredictionOutput, from trainer.predict(dataset)# true labellabels = pred.label_ids# predpreds = pred.predictions.argmax(-1)f1 = f1_score(labels, preds, average="weighted")acc = accuracy_score(labels, preds)precision = precision_score(labels, preds, average='macro')return {"accuracy": acc, "f1": f1, 'precision': precision}
print(torch.__version__)
print(transformers.__version__) # transformers==4.28.0
2.0.1+cu118
4.28.0
import matplotlib as mpl
# default: 100
mpl.rcParams['figure.dpi'] = 200 # 增加图像的分辨率
text classification
- 也叫 sequence classification
- sentiment analysis
- 情感分析,就是一种文本/序列分类
- 电商评论
- social web:weibo/tweet
- 情感分析,就是一种文本/序列分类
emotions 数据集
加载数据集:
from datasets import load_dataset
emotions = load_dataset('emotion')
# DatasetDict
# 8:1:1
emotions
DatasetDict({
train: Dataset({
features: [‘text’, ‘label’],
num_rows: 16000
})
validation: Dataset({
features: [‘text’, ‘label’],
num_rows: 2000
})
test: Dataset({
features: [‘text’, ‘label’],
num_rows: 2000
})
})
emotions.keys()
dict_keys([‘train’, ‘validation’, ‘test’])
emotions['train'][0]
{‘text’: ‘i didnt feel humiliated’, ‘label’: 0}
print(emotions['train'], type(emotions['train']))
# 继续支持key
print(emotions['train']['text'][:5])
print(emotions['train']['label'][:5])
# 支持 index
print(emotions['train'][:5])
Dataset({
features: [‘text’, ‘label’],
num_rows: 16000
}) <class ‘datasets.arrow_dataset.Dataset’>
[‘i didnt feel humiliated’, ‘i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake’, ‘im grabbing a minute to post i feel greedy wrong’, ‘i am ever feeling nostalgic about the fireplace i will know that it is still on the property’, ‘i am feeling grouchy’]
[0, 0, 3, 2, 3]
{‘text’: [‘i didnt feel humiliated’, ‘i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake’, ‘im grabbing a minute to post i feel greedy wrong’, ‘i am ever feeling nostalgic about the fireplace i will know that it is still on the property’, ‘i am feeling grouchy’], ‘label’: [0, 0, 3, 2, 3]}
print(emotions['train'].features)
print(emotions['train'].features['label'])
print(emotions['train'].features['label'].int2str(3))
{‘text’: Value(dtype=‘string’, id=None), ‘label’: ClassLabel(names=[‘sadness’, ‘joy’, ‘love’, ‘anger’, ‘fear’, ‘surprise’], id=None)}
ClassLabel(names=[‘sadness’, ‘joy’, ‘love’, ‘anger’, ‘fear’, ‘surprise’], id=None)
anger
emotions['train'].features['label'].names[1]
joy
labels = emotions['train'].features['label'].names
print(labels)
# 下游任务(downstream task)
num_classes = len(labels)
num_classes
[‘sadness’, ‘joy’, ‘love’, ‘anger’, ‘fear’, ‘surprise’]
def int2str(x):
# return emotions['train'].features['label'].int2str(x)return labels[x]
想必经过上面的一些参数的打印大家对于数据集的也有进一步的了解。
data visualization analysis
- dataset => dataframe
- text length
- label freq
下面进行数据的可视化分析
dataset to dataframe
emotions_df = pd.DataFrame.from_dict(emotions['train'])
print(emotions_df.shape, emotions_df.columns)
emotions_df[:5] # 前五个
(16000, 2) Index([‘text’, ‘label’], dtype=‘object’)
text label
0 i didnt feel humiliated 0
1 i can go from feeling so hopeless to so damned… 0
2 im grabbing a minute to post i feel greedy wrong 3
3 i am ever feeling nostalgic about the fireplac… 2
4 i am feeling grouchy 3
emotions_df['label']
0 0
1 0
2 3
3 2
4 3
…
15995 0
15996 0
15997 1
15998 3
15999 0
Name: label, Length: 16000, dtype: int64
# emotions_df['label_name'] = emotions_df['label'].apply(lambda x: emotions['train'].features['label'].int2str(x))
emotions_df['label_name'] = emotions_df['label'].apply(lambda x: labels[x])
emotions_df[:5]
text label label_name
0 i didnt feel humiliated 0 sadness
1 i can go from feeling so hopeless to so damned… 0 sadness
2 im grabbing a minute to post i feel greedy wrong 3 anger
3 i am ever feeling nostalgic about the fireplac… 2 love
4 i am feeling grouchy 3 anger
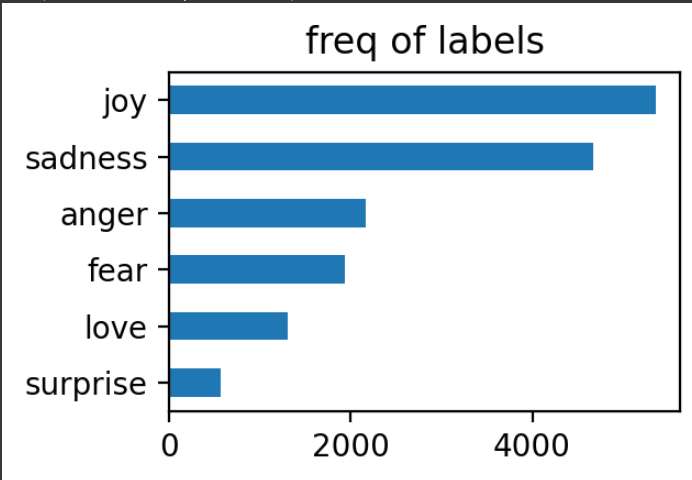
label analysis
emotions_df.label.value_counts() # 类别不是特别均匀
1 5362
0 4666
3 2159
4 1937
2 1304
5 572
Name: label, dtype: int64
emotions_df.label_name.value_counts()
joy 5362
sadness 4666
anger 2159
fear 1937
love 1304
surprise 572
Name: label_name, dtype: int64
plt.figure(figsize=(3, 2))
emotions_df['label_name'].value_counts(ascending=True).plot.barh()
plt.title('freq of labels')
Text(0.5, 1.0, ‘freq of labels’)
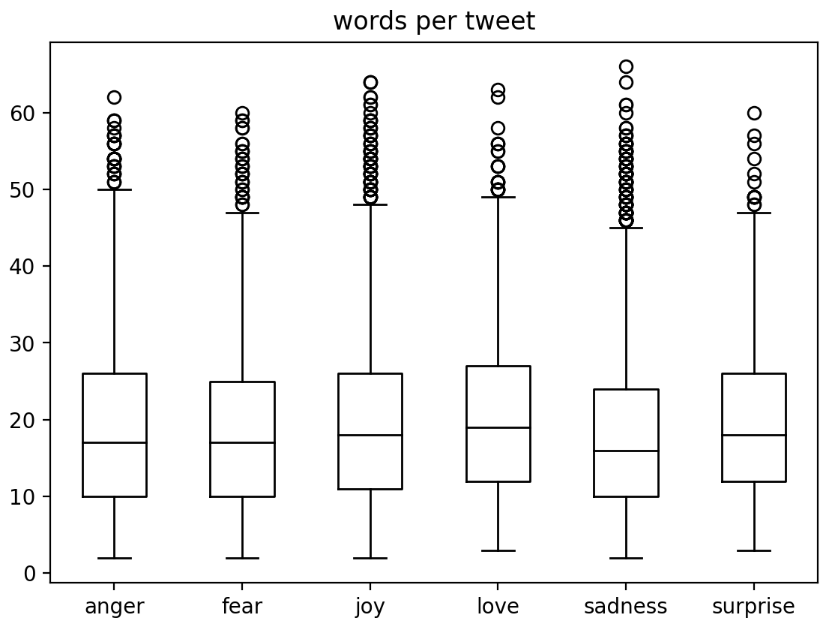
text length analysis
plt.figure(figsize=(1, 0.5))
emotions_df['words per tweet'] = emotions_df['text'].str.split().apply(len) # 每个单词的数量
emotions_df.boxplot('words per tweet', by='label_name',
# showfliers=False, # 如果注释会显示异常点,即个别的样例grid=False, color='black')
plt.suptitle('')
plt.xlabel('')
Text(0.5, 0, ‘’)
< Figure size 200x100 with 0 Axes>
print(emotions_df['words per tweet'].max())
print(emotions_df['words per tweet'].idxmax())
66
6322
print(emotions_df.iloc[6322])
emotions_df.iloc[6322]['text']
emotions_df['text'][6322]
text i guess which meant or so i assume no photos n…
label 0
label_name sadness
words per tweet 66
Name: 6322, dtype: object
i guess which meant or so i assume no photos no words or no other way to convey what it really feels unless you feels it yourself or khi bi t au th m i bi t th ng ng i b au i rephrase it to a bit more gloomy context unless you are hurt yourself you will never have sympathy for the hurt ones
print(emotions_df['words per tweet'].min())
print(emotions_df['words per tweet'].idxmin())
2
4150
emotions_df.iloc[4150]
text earth crake
label 4
label_name fear
words per tweet 2
Name: 4150, dtype: object
text => tokens
from transformers import AutoTokenizer
model_ckpt = 'distilbert-base-uncased' # base版 uncased表示对大小写不敏感
tokenizer = AutoTokenizer.from_pretrained(model_ckpt) # 子词分词
# uncased
print(tokenizer.encode('hello world'))
print(tokenizer.encode('HELLO WORLD'))
print(tokenizer.encode('Hello World'))
[101, 7592, 2088, 102]
[101, 7592, 2088, 102]
[101, 7592, 2088, 102]
# 101([CLS]) classification开始,以 102 ([SEP]) (seperation)结束
tokenizer.encode(emotions_df.iloc[6322]['text'])
这里输出太长了,建议大家自己跑一遍学习学习
print(tokenizer.vocab_size) #字典大小
print(tokenizer.model_max_length) # 模型接收的最大长度
print(tokenizer.model_input_names) # 模型接收的输入名称
30522
512
[‘input_ids’, ‘attention_mask’]
for special_id in tokenizer.all_special_ids:print(special_id, tokenizer.decode(special_id))# [UNK]:文本中的元素不在词典中,用该符号表示生僻字。此标记用于表示未知或词汇外的单词。当一个模型遇到一个它以前没有见过/无法识别的词时,它会用这个标记替换它。
# [SEP]:用于分隔两个句子,例如在文本分类问题中,将两个句子拼接成一个输入序列时,可以使用 [SEP] 来分隔这两个句子。
# [PAD]:在batch中对齐序列长度时,用 [PAD]进行填充以使所有序列长度相同。可以通过将其添加到较短的序列末尾来实现对齐。
# [CLS]:在输入序列的开头添加 [CLS] 标记,以表示该序列的分类结果。用于分类场景,该位置可表示整句话的语义。
# [MASK] :表示这个词被遮挡。需要带着[],并且mask是大写。
100 [UNK]
102 [SEP]
0 [PAD]
101 [CLS]
103 [MASK]
tokenize the whole dataset
def batch_tokenize(batch):return tokenizer(batch['text'], padding=True, truncation=True)
# batch_tokenize(emotions['train'])
emotions_encoded = emotions.map(batch_tokenize, batched=True, batch_size=None)
数据集增加模型的输入。input_ids就是编码后的序列(将输入到的词映射到模型当中的字典ID),attention_mask顾名思义就是注意力机制的位置(在 self-attention 过程中,这一块 mask 用于标记 subword 所处句子和 padding 的区别,将 padding 部分填充为 0;)
emotions_encoded
DatasetDict({
train: Dataset({
features: [‘text’, ‘label’, ‘input_ids’, ‘attention_mask’],
num_rows: 16000
})
validation: Dataset({
features: [‘text’, ‘label’, ‘input_ids’, ‘attention_mask’],
num_rows: 2000
})
test: Dataset({
features: [‘text’, ‘label’, ‘input_ids’, ‘attention_mask’],
num_rows: 2000
})
})
print(type(emotions_encoded['train']['input_ids'])) # list
# emotions_encoded['train']['input_ids'][:3]
# emotions_encoded['train']['attention_mask'][:3] # 取消注释打印看看
<class ‘list’>
# list to tensor
emotions_encoded.set_format('torch', columns=['label', 'input_ids', 'attention_mask'])
type(emotions_encoded['train']['input_ids'])
# emotions_encoded['train']['input_ids'][:3]
torch.Tensor
fine-tune transformers
distilbert-base-uncased
- distilbert 是对 bert 的 distill 而来
- 模型结构更为简单,
- bert-base-uncased 参数量:109482240
- distilbert-base-uncased 参数量:66362880
from transformers import AutoModel
model_ckpt = 'distilbert-base-uncased'
model = AutoModel.from_pretrained(model_ckpt)
model # 打印出模型的一些参数
输出如下:
Some weights of the model checkpoint at distilbert-base-uncased were not used when initializing DistilBertModel: ['vocab_layer_norm.bias', 'vocab_transform.weight', 'vocab_projector.bias', 'vocab_layer_norm.weight', 'vocab_transform.bias', 'vocab_projector.weight']
- This IS expected if you are initializing DistilBertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DistilBertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
DistilBertModel((embeddings): Embeddings((word_embeddings): Embedding(30522, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(transformer): Transformer((layer): ModuleList((0-5): 6 x TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True)(activation): GELUActivation())(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))))
)
这个是前面预定义的函数
get_params(model) # 6千万
66362880
from transformers import AutoModel
model_ckpt = 'bert-base-uncased'
model = AutoModel.from_pretrained(model_ckpt)
get_params(model) # 1亿零900万
输出如下
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertModel: ['cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.weight', 'cls.seq_relationship.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.bias', 'cls.predictions.bias']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
109482240
大约是1.65倍
109482240/66362880
1.6497511862053003
model
输出如下:
BertModel((embeddings): BertEmbeddings((word_embeddings): Embedding(30522, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(token_type_embeddings): Embedding(2, 768)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(encoder): BertEncoder((layer): ModuleList((0-11): 12 x BertLayer((attention): BertAttention((self): BertSelfAttention((query): Linear(in_features=768, out_features=768, bias=True)(key): Linear(in_features=768, out_features=768, bias=True)(value): Linear(in_features=768, out_features=768, bias=True)(dropout): Dropout(p=0.1, inplace=False))(output): BertSelfOutput((dense): Linear(in_features=768, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))(intermediate): BertIntermediate((dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation())(output): BertOutput((dense): Linear(in_features=3072, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))))(pooler): BertPooler((dense): Linear(in_features=768, out_features=768, bias=True)(activation): Tanh())
)
下面用一个文本分类的预训练模型,我们进行fine-tuning
from transformers import AutoModelForSequenceClassification #有下游任务,区别在分类头num_labels指定
model_ckpt = 'distilbert-base-uncased'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# model = AutoModelForSequenceClassification.from_pretrained(model_ckpt)
model = AutoModelForSequenceClassification.from_pretrained(model_ckpt, num_labels=num_classes).to(device) #前面定义的num_classes
model
# Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['pre_classifier.weight', 'pre_classifier.bias', 'classifier.weight', 'classifier.bias']
# You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
# 即需要fine tune,对下游任务进行训练更新这些参数。这里参数是是随机初始化的
这里参数是是随机初始化的,即需要fine tune,对下游任务进行训练更新这些参数
newly initialized: [‘pre_classifier.weight’, ‘pre_classifier.bias’, ‘classifier.weight’, ‘classifier.bias’]
也就是DistilBertModel的最后两层
输出如下:
Some weights of the model checkpoint at distilbert-base-uncased were not used when initializing DistilBertForSequenceClassification: ['vocab_layer_norm.bias', 'vocab_transform.weight', 'vocab_projector.bias', 'vocab_layer_norm.weight', 'vocab_transform.bias', 'vocab_projector.weight']
- This IS expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['pre_classifier.bias', 'classifier.weight', 'pre_classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
DistilBertForSequenceClassification((distilbert): DistilBertModel((embeddings): Embeddings((word_embeddings): Embedding(30522, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(transformer): Transformer((layer): ModuleList((0-5): 6 x TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True)(activation): GELUActivation())(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)))))(pre_classifier): Linear(in_features=768, out_features=768, bias=True)(classifier): Linear(in_features=768, out_features=6, bias=True)(dropout): Dropout(p=0.2, inplace=False)
)
!nvidia-smi
这里将模型挂到GPU上了,大家可以看看显存情况。
trainer
# 去下面这个网站,找到New token按钮,然后Role选择write,名字随意。然后把一串代码复制过来登入即可。
# https://huggingface.co/settings/tokens
# (write)
from huggingface_hub import notebook_login
notebook_login()
# https://huggingface.co/docs/transformers/main_classes/trainer
# https://huggingface.co/docs/transformers/v4.28.1/en/main_classes/trainer#transformers.TrainingArguments
from transformers import TrainingArguments, Trainer
pip install --upgrade accelerate # Using the `Trainer` with `PyTorch` requires `accelerate`: Run `pip install --upgrade accelerate`
batch_size = 64
logging_steps = len(emotions_encoded['train']) // batch_size # batch_size数
model_name = f'{model_ckpt}_emotion_ft_0520'
training_args = TrainingArguments(output_dir=model_name, num_train_epochs=4, learning_rate=2e-5, # 学习率weight_decay=0.01, # 权重衰减per_device_train_batch_size=batch_size,per_device_eval_batch_size=batch_size,evaluation_strategy="epoch", # 参数更新disable_tqdm=False,logging_steps=logging_steps,# writepush_to_hub=True, log_level="error")
- trainer默认自动开启 torch 的多gpu模式,
per_device_train_batch_size: 这里是设置每个gpu上的样本数量,- 一般来说,多gpu模式希望多个gpu的性能尽量接近,否则最终多gpu的速度由最慢的gpu决定,
- 比如快gpu 跑一个batch需要5秒,跑10个batch 50秒,慢的gpu跑一个batch 500秒,则快gpu还要等慢gpu跑完一个batch然后一起更新weights,速度反而更慢了。
- 同理
per_device_eval_batch_size类似
learning_rate/weight_decay- 默认使用AdamW的优化算法
# from transformers_utils import compute_classification_metrics
trainer = Trainer(model=model, tokenizer=tokenizer,train_dataset=emotions_encoded['train'],eval_dataset=emotions_encoded['validation'],args=training_args, compute_metrics=compute_classification_metrics# 定义的计算recall、precision和f1的函数)
开始训练:
trainer.train()
输出如下:
/usr/local/lib/python3.10/dist-packages/transformers/optimization.py:391: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warningwarnings.warn([1000/1000 08:03, Epoch 4/4]
Epoch Training Loss Validation Loss Accuracy F1 Precision
1 0.796600 0.266074 0.908500 0.906949 0.889141
2 0.210400 0.177573 0.926500 0.926440 0.909252
3 0.141200 0.153692 0.937000 0.937603 0.903995
4 0.110400 0.150301 0.934500 0.934908 0.910215
TrainOutput(global_step=1000, training_loss=0.31463860511779784, metrics={'train_runtime': 487.5809, 'train_samples_per_second': 131.26, 'train_steps_per_second': 2.051, 'total_flos': 1440685723392000.0, 'train_loss': 0.31463860511779784, 'epoch': 4.0})
注意:这里的损失函数见:为了从头开始,让我们先看看Trainer类中的默认compute_loss()函数是什么样子的。你可以找到相应的函数here如果你想自己看一下(在撰写本文时的当前版本是4.17)。 指南将以默认参数返回的实际损失是取自模型的输出值。
loss = outputs["loss"] if isinstance(outputs, dict) else outputs[0]
这意味着模型本身(默认)负责计算某种损失并以outputs返回。
在这之后,我们可以研究一下BERT的实际模型定义。here,特别是检查出将用于你的情感分析任务的模型(我假设是一个BertForSequenceClassification model.
The 定义损失函数的相关代码 looks like this:
if labels is not None:if self.config.problem_type is None:if self.num_labels == 1:self.config.problem_type = "regression"elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):self.config.problem_type = "single_label_classification"else:self.config.problem_type = "multi_label_classification"if self.config.problem_type == "regression":loss_fct = MSELoss()if self.num_labels == 1:loss = loss_fct(logits.squeeze(), labels.squeeze())else:loss = loss_fct(logits, labels)elif self.config.problem_type == "single_label_classification":loss_fct = CrossEntropyLoss()loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))elif self.config.problem_type == "multi_label_classification":loss_fct = BCEWithLogitsLoss()loss = loss_fct(logits, labels)
基于这些信息,你应该能够自己设置正确的损失函数(通过相应地改变model.config.problem_type),或者至少能够根据你的任务的超参数(标签数量、标签分数等)来确定将选择哪种损失。
可见是BECWithLogitsLoss
preds_output = trainer.predict(emotions_encoded["validation"])
preds_output
PredictionOutput(predictions=array([[ 5.4677515 , -1.1017808 , -1.410908 , -1.269935 , -1.6951537 ,
-2.153927 ],
[ 5.4839664 , -1.3900928 , -2.0582473 , -1.1541718 , -1.0805937 ,
-2.1704757 ],
[-1.7551718 , 2.4400585 , 3.5053616 , -1.7942224 , -2.009818 ,
-1.9759804 ],
…,
[-1.5938126 , 5.7911706 , -0.53696257, -1.6969242 , -1.4921831 ,
-1.4446386 ],
[-2.094282 , 3.558918 , 2.9182825 , -1.8695072 , -2.0942342 ,
-1.9140248 ],
[-1.738551 , 5.732262 , -0.8148034 , -1.8223345 , -1.6316185 ,
-0.4583993 ]], dtype=float32), label_ids=array([0, 0, 2, …, 1, 1, 1]), metrics={‘test_loss’: 0.1503012627363205, ‘test_accuracy’: 0.9345, ‘test_f1’: 0.9349083985078741, ‘test_precision’: 0.9102153158834606, ‘test_runtime’: 3.9207, ‘test_samples_per_second’: 510.11, ‘test_steps_per_second’: 8.162})
两千条,还可以看到一些预测的指标如accuracy,f1,precision
preds_output = trainer.predict(emotions_encoded["validation"])
y_preds = np.argmax(preds_output.predictions, axis=-1)
y_true = emotions_encoded['validation']['label']
labels
[‘sadness’, ‘joy’, ‘love’, ‘anger’, ‘fear’, ‘surprise’]
画出confusion矩阵
plot_confusion_matrix(y_preds, y_true, labels)
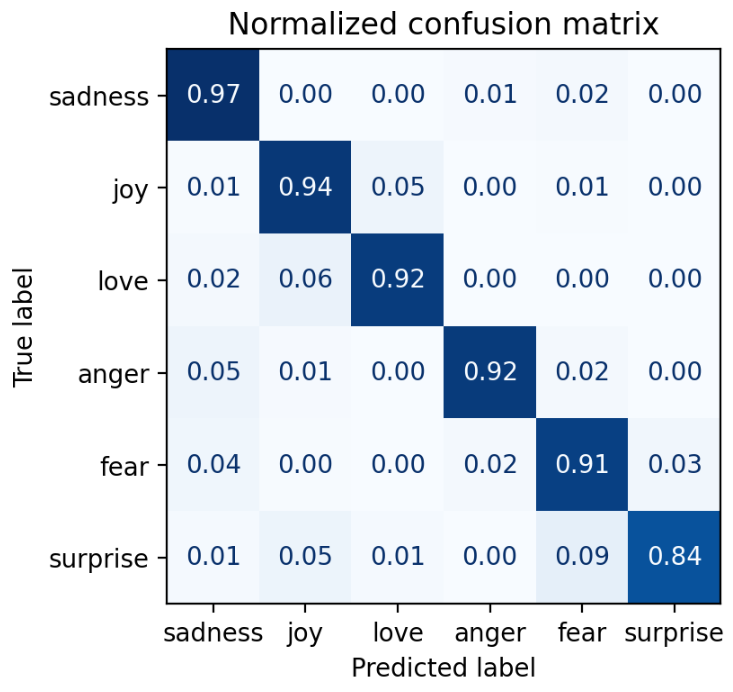
可以看到fear和surprise之间容易混淆。
下面是测试集
preds_output = trainer.predict(emotions_encoded["test"])
y_preds = np.argmax(preds_output.predictions, axis=-1)
y_true = emotions_encoded["test"]['label']
plot_confusion_matrix(y_preds, y_true, labels)
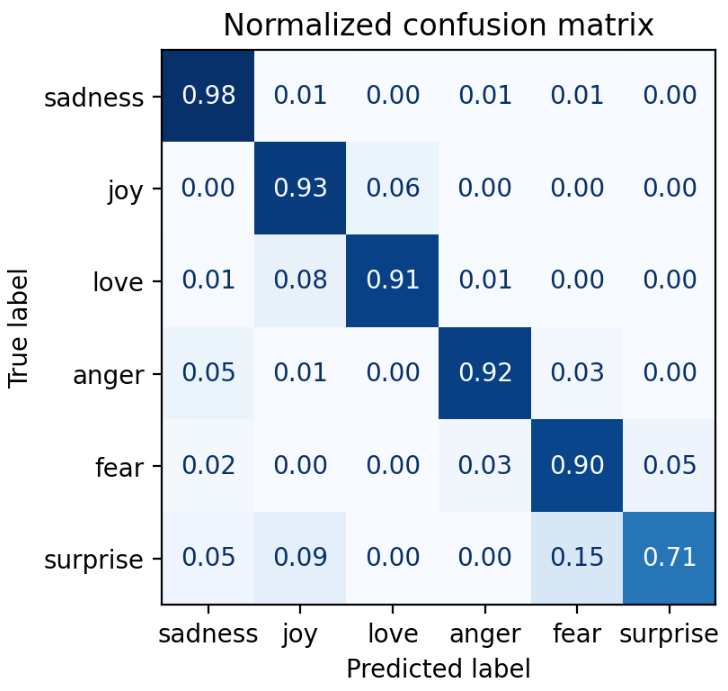
结果差不多。
result analysis
from torch.nn.functional import cross_entropy
def forward_pass_with_label(batch):# Place all input tensors on the same device as the modelinputs = {k:v.to(device) for k,v in batch.items() if k in tokenizer.model_input_names}with torch.no_grad():output = model(**inputs)pred_label = torch.argmax(output.logits, axis=-1)loss = cross_entropy(output.logits, batch["label"].to(device), reduction="none")# Place outputs on CPU for compatibility with other dataset columns return {"loss": loss.cpu().numpy(), "predicted_label": pred_label.cpu().numpy()}
emotions_encoded["validation"] = emotions_encoded["validation"].map(forward_pass_with_label, batched=True, batch_size=16)
emotions_encoded['validation']
Dataset({
features: [‘text’, ‘label’, ‘input_ids’, ‘attention_mask’, ‘loss’, ‘predicted_label’],
num_rows: 2000
})
可见加上了loss和predicted_label
selected_cols = ['text', 'label', 'predicted_label', 'loss']
valid_df = pd.DataFrame.from_dict({'text': emotions_encoded["validation"]['text'], 'label': emotions_encoded['validation']['label'].numpy(), 'pred_label': emotions_encoded['validation']['predicted_label'].numpy(), 'loss': emotions_encoded["validation"]['loss'].numpy()})
valid_df['label'] = valid_df['label'].apply(lambda x: labels[x])
valid_df['pred_label'] = valid_df['pred_label'].apply(lambda x: labels[x])
输出的最后两列是对应的预测标签和Loss,一般loss越低置信度越高,vice versa
valid_df
text label pred_label loss
0 im feeling quite sad and sorry for myself but … sadness sadness 0.004870
1 i feel like i am still looking at a blank canv… sadness sadness 0.004746
2 i feel like a faithful servant love love 0.309687
3 i am just feeling cranky and blue anger anger 0.009625
4 i can have for a treat or if i am feeling festive joy joy 0.004084
… … … … …
1995 im having ssa examination tomorrow in the morn… sadness sadness 0.006484
1996 i constantly worry about their fight against n… joy joy 0.004199
1997 i feel its important to share this info for th… joy joy 0.004363
1998 i truly feel that if you are passionate enough… joy joy 0.433443
1999 i feel like i just wanna buy any cute make up … joy joy 0.005196
2000 rows × 4 columns
打印预测错误的行:
valid_df[valid_df['label'] != valid_df['pred_label']]
text label pred_label loss
17 i know what it feels like he stressed glaring … anger sadness 2.165960
27 i feel as if i am the beloved preparing hersel… joy love 1.349030
35 i am feeling very blessed today that they shar… joy love 0.980191
55 i didn t feel accepted joy love 1.160610
83 i feel stressed or my family is being negative… sadness anger 0.830531
… … … … …
1950 i as representative of everything thats wrong … surprise sadness 7.413787
1958 i so desperately want to be able to help but i… fear sadness 1.073220
1963 i called myself pro life and voted for perry w… joy sadness 5.690224
1981 i spent a lot of time feeling overwhelmed with… fear surprise 1.122861
1990 i just feel too overwhelmed i can t see the fo… fear surprise 0.993149
131 rows × 4 columns
1-131/2000
0.9345
# most labels incorrectly
valid_df[valid_df['label'] != valid_df['pred_label']].label.value_counts()
joy 45
anger 21
fear 20
sadness 18
love 14
surprise 13
Name: label, dtype: int64
可见joy预测错误的最多。
取loss最高的10个
valid_df.sort_values('loss', ascending=False).head(10)
text label pred_label loss
1950 i as representative of everything thats wrong … surprise sadness 7.413787
882 i feel badly about reneging on my commitment t… love sadness 7.051113
1840 id let you kill it now but as a matter of fact… joy fear 5.745034
1509 i guess this is a memoir so it feels like that… joy fear 5.730564
1963 i called myself pro life and voted for perry w… joy sadness 5.690224
1111 im lazy my characters fall into categories of … joy fear 5.448301
405 i have been feeling extraordinarily indecisive… fear joy 5.421506
1870 i guess i feel betrayed because i admired him … joy sadness 4.863584
1801 i feel that he was being overshadowed by the s… love sadness 4.854661
1836 i got a very nasty electrical shock when i was… fear anger 4.292095
看上面结果第二行 即882
# mislabeld
valid_df.iloc[882].text
i feel badly about reneging on my commitment to bring donuts to the faithful at holy family catholic church in columbus ohio(我对违背承诺将甜甜圈带给俄亥俄州哥伦布圣家天主教堂的信徒感到难过)
真实标签是love,但显然是sadness,即存在mislabeld
# less loss means more confident
# sadness/joy
valid_df.sort_values('loss', ascending=True).head(20)
text label pred_label loss
452 i manage to complete the lap not too far behin… joy joy 0.003656
578 i got to christmas feeling positive about the … joy joy 0.003671
1513 i have also been getting back into my gym rout… joy joy 0.003696
1263 i feel this way about blake lively joy joy 0.003700
11 i was dribbling on mums coffee table looking o… joy joy 0.003720
1873 i feel practically virtuous this month i have … joy joy 0.003727
1172 i feel like i dont need school to be intelligent joy joy 0.003727
1476 i finally decided that it was partially due to… joy joy 0.003732
856 i feel is more energetic in urban singapore th… joy joy 0.003733
1619 i sat in the car and read my book which suited… joy joy 0.003749
1531 i forgive stanley hes not so quick to forgive … sadness sadness 0.003750
961 i really didnt feel like going out at all but … joy joy 0.003769
1523 i dont give a fuck because i feel like i canno… joy joy 0.003778
1198 i feel like i should also mention that there w… joy joy 0.003787
1723 i know how much work goes into the creation an… joy joy 0.003793
604 i don t like to use the h word recklessly but … joy joy 0.003794
1017 i will be happy when someone i know from acros… joy joy 0.003794
1421 i feel undeservingly lucky to be surrounded by… joy joy 0.003804
456 im feeling rather festive here in south florida joy joy 0.003811
632 i feel he is an terrific really worth bet joy joy 0.003811
to huggingface hub
上传到huggingface
trainer.push_to_hub(commit_message="Training completed!")
Upload file runs/May29_08-23-51_83151de6e3f9/events.out.tfevents.1685349040.83151de6e3f9.25428.0: 100%
6.71k/6.71k [00:09<?, ?B/s]
To https://huggingface.co/Zhouzk/distilbert-base-uncased_emotion_ft_0520
c2bce32…05d8544 main -> main
WARNING:huggingface_hub.repository:To https://huggingface.co/Zhouzk/distilbert-base-uncased_emotion_ft_0520
c2bce32…05d8544 main -> main
To https://huggingface.co/Zhouzk/distilbert-base-uncased_emotion_ft_0520
05d8544…3626c97 main -> main
WARNING:huggingface_hub.repository:To https://huggingface.co/Zhouzk/distilbert-base-uncased_emotion_ft_0520
05d8544…3626c97 main -> main
https://huggingface.co/Zhouzk/distilbert-base-uncased_emotion_ft_0520/commit/05d8544e5b9c25fe75f4e4f549018a7aa3c12c8e
#hide_output
from transformers import pipeline# Change `transformersbook` to your Hub username
model_id = "Zhouzk/distilbert-base-uncased_emotion_ft_0520" # 你上传模型的名字
classifier = pipeline("text-classification", model=model_id)
Downloading (…)lve/main/config.json: 100%
888/888 [00:00<00:00, 61.9kB/s]
Downloading pytorch_model.bin: 100%
268M/268M [00:03<00:00, 58.0MB/s]
Downloading (…)okenizer_config.json: 100%
320/320 [00:00<00:00, 13.6kB/s]
Downloading (…)solve/main/vocab.txt: 100%
232k/232k [00:00<00:00, 4.14MB/s]
Downloading (…)/main/tokenizer.json: 100%
712k/712k [00:00<00:00, 26.0MB/s]
Downloading (…)cial_tokens_map.json: 100%
125/125 [00:00<00:00, 5.55kB/s]
试试直接上传后的预训练模型的效果
# custom_tweet = "I saw a movie today and it was really good."
custom_tweet = "I saw a movie today and it suck."
preds = classifier(custom_tweet, return_all_scores=True)
preds
/usr/local/lib/python3.10/dist-packages/transformers/pipelines/text_classification.py:104: UserWarning:
return_all_scoresis now deprecated, if want a similar funcionality usetop_k=Noneinstead ofreturn_all_scores=Trueortop_k=1instead ofreturn_all_scores=False.
warnings.warn(
[[{‘label’: ‘LABEL_0’, ‘score’: 0.29513901472091675},
{‘label’: ‘LABEL_1’, ‘score’: 0.08960112929344177},
{‘label’: ‘LABEL_2’, ‘score’: 0.017728766426444054},
{‘label’: ‘LABEL_3’, ‘score’: 0.40038347244262695},
{‘label’: ‘LABEL_4’, ‘score’: 0.1750381886959076},
{‘label’: ‘LABEL_5’, ‘score’: 0.02210947312414646}]]
labels
[‘sadness’, ‘joy’, ‘love’, ‘anger’, ‘fear’, ‘surprise’]
preds_df = pd.DataFrame(preds[0])
plt.bar(labels, 100 * preds_df["score"], color='C0')
plt.title(f'"{custom_tweet}"')
plt.ylabel("Class probability (%)")
plt.show()
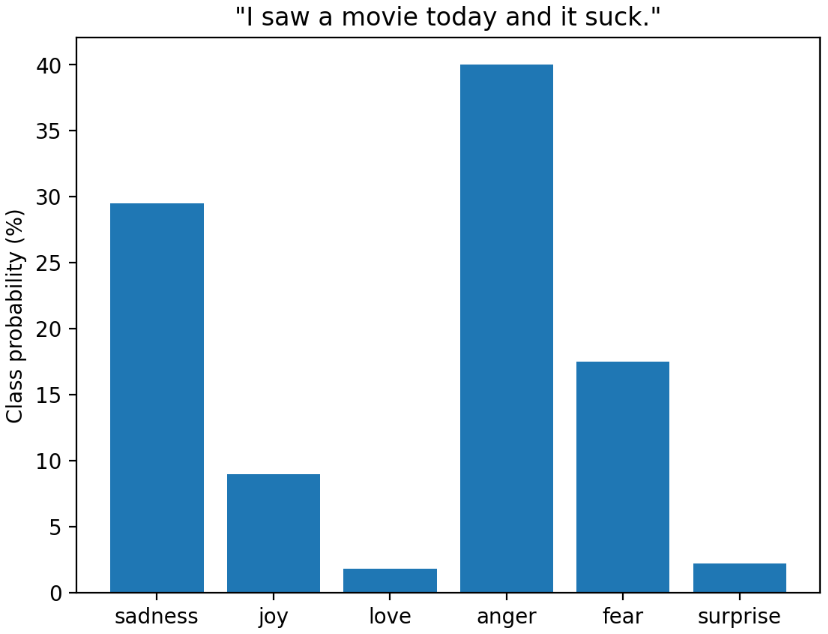
这也就是模型的结果。anger的概论最大。
参考: