一、前期准备
1、设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasetsimport os,PIL,pathlibdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device)![]()
2.导入数据
data_dir = pathlib.Path('D:/P5data/weather_photos')
data_paths = list(data_dir.glob('*'))
classNames = [path.name for path in data_paths]
print(classNames)
data_dir = pathlib.Path('./data/') : 使用pathlib.Path处理路径,它提供了更多关于路径的方法和属性
data_paths = list(data_dir.glob('*')) : 使用Path.glob方法搜索当前目录下的所有文件/文件夹。这个方法返回一个迭代器,所以使用list()将其转换为列表。
classNames = [path.name for path in data_paths] #:使用列表推导式从每个路径中提取名称(即最后一个部分)。例如,路径./data/cloudy将提取为cloudy。

3.预处理和加载数据集
total_datadir = 'D:/P5data/weather_photos' ## train_transforms 进行图像预处理
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸224 x 224大小transforms.ToTensor(), # 转换为tensor格式, 且归一化transforms.Normalize( # 标准化处理-->转换为标准正态分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中mean=[0.485, 0.456, 0.406]与std=[0.229, 0.224, 0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(total_datadir,transform=train_transforms) # 加载数据集并应用预处理
print(total_data)
4.划分数据集
train_size = int(0.8 * len(total_data)) # 训练数据集80%
test_size = len(total_data) - train_size # 测试集 20%# 使用 torch.utils.data.random_split 将数据集分为训练集和测试集
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])print(train_dataset)
print(test_dataset)
print(train_size)
print(test_size)
5.数据加载器
batch_size = 32 # 定义每个批次中包含的样本数量# 使用DataLoader创建训练和测试的数据加载器,用于从数据集中加载批次的数据
train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=0)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=0)for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break
二、构建简单的CNN网络
定义一个带有批量归一化(Batch Normalization) 的卷积神经网络结构,该网络可以对输入的图像进行特征提取和分类。
# 导入PyTorch的函数式模块,其中包含了一些常用的非线性激活函数,如ReLU。
import torch.nn.functional as F # 定义网络模型:
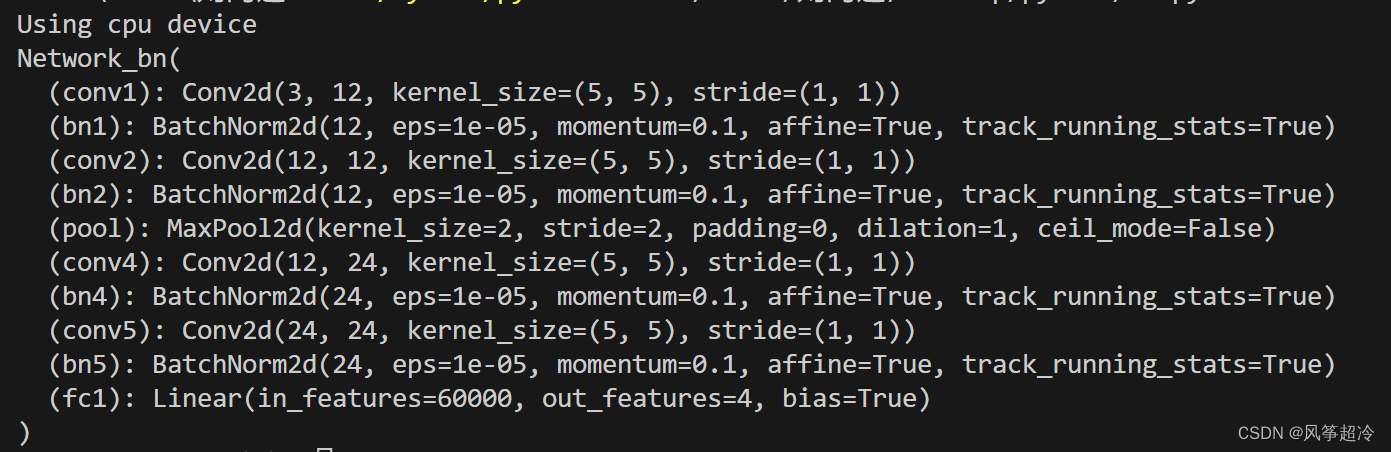
class Network_bn(nn.Module): # 定义了一个名为'Network_bn'的类,继承自'nn.Module',这是Pytorch中构建神经网络模型的基类。def __init__(self): # 构造函数,用于初始化网络结构和参数super(Network_bn, self).__init__() # 调用父类(nn.Module)的构造函数self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(12)self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn2 = nn.BatchNorm2d(12)self.pool = nn.MaxPool2d(2,2)self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn4 = nn.BatchNorm2d(24)self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn5 = nn.BatchNorm2d(24)self.fc1 = nn.Linear(24*50*50, len(classNames))def forward(self, x): # 前向传播函数x = F.relu(self.bn1(self.conv1(x))) # 对输入应用卷积、批量归一化和ReLU激活函数。x = F.relu(self.bn2(self.conv2(x)))x = self.pool(x) # 使用最大池化层对特征图进行下采样。在网络的不同部分进行,形成特征提取过程。x = F.relu(self.bn4(self.conv4(x)))x = F.relu(self.bn5(self.conv5(x)))x = self.pool(x)x = x.view(-1, 24*50*50)x = self.fc1(x) # 最后进行全连接层,将提取的特征映射到分类标签。return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = Network_bn().to(device) # 创建Network_bn的实例,将模型移动到指定的设备上。
print(model)
三、训练模型
1.设置超参数
loss_fn = nn.CrossEntropyLoss() # 创建交叉熵损失函数,用于计算模型输出与真实标签之间的差距
learn_rate = 1e-4 # 学习率,即优化器在更新模型参数时使用的步长
opt = torch.optim.SGD(model.parameters(), lr=learn_rate) # opt, 创建SGD优化器,用于更新模型的参数。(传入模型的参数和学习率)
loss_fn = nn.CrossEntropyLoss() #:创建交叉熵损失函数,用于计算模型输出与真实标签之间的差距
learn_rate = 1e-4 : 学习率,即优化器在更新模型参数时使用的步长
opt = torch.optim.SGD(model.parameters(), lr=learn_rate) : opt, 创建SGD优化器,用于更新模型的参数。(传入模型的参数和学习率)
2.编写训练函数
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 获取训练集的大小num_batches = len(dataloader) # 获取批次数量train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 遍历训练集的每个批次,获取图片及其标签X, y = X.to(device), y.to(device) # 将数据移动到设备上# 计算预测误差pred = model(X) # 网络输出,前向传播得到模型预测值loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值, 计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零,清除之前的梯度loss.backward() # 反向传播,计算梯度optimizer.step() # 每一步自动更新模型参数# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss3.编写测试函数
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 获取测试集的大小num_bathes = len(dataloader) # 获取批次数量test_loss, test_acc = 0, 0 # 初始化测试损失和测试准确率# 当不进行训练时,停止梯度更新, 节省计算内存消耗with torch.no_grad(): # 在测试过程中,不需要计算梯度for imgs, target in dataloader: 遍历测试数据集的每个批次imgs, target = imgs.to(device), target.to(device) # 将数据移动到设备上# 计算losstarget_pred = model(imgs) # 模型预测loss = loss_fn(target_pred, target) # 计算损失test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_bathesreturn test_acc, test_loss
4.编写训练函数
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train() # 设置模型为训练模式epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval() # 设置模型为评估模式,不启用Batch Normalization 和Dropoutepoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print("Done")
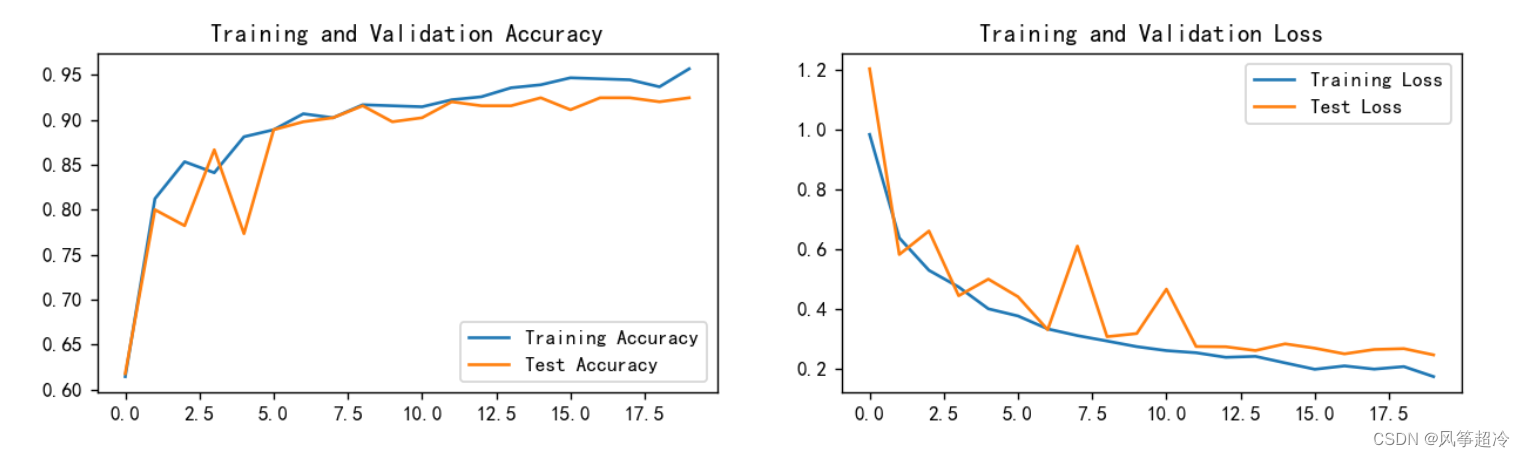
5.结果可视化
# 隐藏警告
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
四、 实验总结
本次深度学习实验的主要目标是学习如何使用 PyTorch 框架构建、训练和验证卷积神经网络(CNN)模型,以解决彩色图片识别问题。我们选择了经典的 CIFAR-10 数据集作为实验的数据源,该数据集包含10个不同类别的彩色图片,是一个适合深度学习初学者的挑战性任务。在实验中,我们将了解数据加载与预处理、模型构建、模型训练、模型验证以及超参数设置等关键概念和技术。
一、方法与步骤
1. 数据加载与预处理
我们首先使用 PyTorch 的 torchvision 库中提供的 `CIFAR10` 方法加载 CIFAR-10 数据集,并通过 `ToTensor()` 转换将图像数据转化为 PyTorch Tensor 格式。这一步骤是为了将原始图像数据转化为神经网络可处理的数据格式。
2. 模型构建
我们定义了一个卷积神经网络(CNN)模型,该模型包含了三个卷积层(`Conv2d`)、三个最大池化层(`MaxPool2d`)和两个全连接层(`Linear`)。ReLU 激活函数被应用于卷积层和全连接层,以引入非线性性质。
3. 模型训练
训练过程在 `train` 函数中完成。在每个训练轮次(epoch)中,该函数迭代训练数据集,计算模型的预测结果与真实标签之间的交叉熵损失,并使用随机梯度下降(SGD)优化器更新模型参数。这一步骤是为了使模型能够逐渐学习如何正确地对图像进行分类。
4. 模型验证
测试函数(`test`)用于在每个训练轮次结束后,在测试数据集上验证模型的性能。它计算模型的准确率和损失,以评估模型在未见过的数据上的表现,以防止过拟合。这个步骤帮助我们了解模型的泛化能力。
5. 结果可视化
为了更好地了解模型在训练过程中的表现,我们使用 `matplotlib` 库绘制了训练和验证准确率以及损失的曲线。这些曲线帮助我们观察模型的收敛情况以及是否存在训练不足或过拟合等问题。
6. 超参数设置
在实验中,我们调整了一些关键的超参数,如学习率、批次大小和训练轮次等。超参数的合适设置对模型的性能具有重要影响,因此我们进行了多次实验来找到最佳的超参数组合。
二、实验结果与讨论
经过多次实验和调整超参数,我们得到了一个在 CIFAR-10 数据集上表现良好的卷积神经网络模型。该模型在测试集上达到了令人满意的准确率,证明了其在彩色图片识别任务上的有效性。
在实验过程中,我们也发现了一些有趣的现象和挑战。例如,适当的学习率和训练轮次能够促进模型的收敛,但如果学习率设置过高,可能导致模型无法收敛或者陷入局部最小值。此外,合适的数据增强技术可以提高模型的泛化能力,减少过拟合的风险。