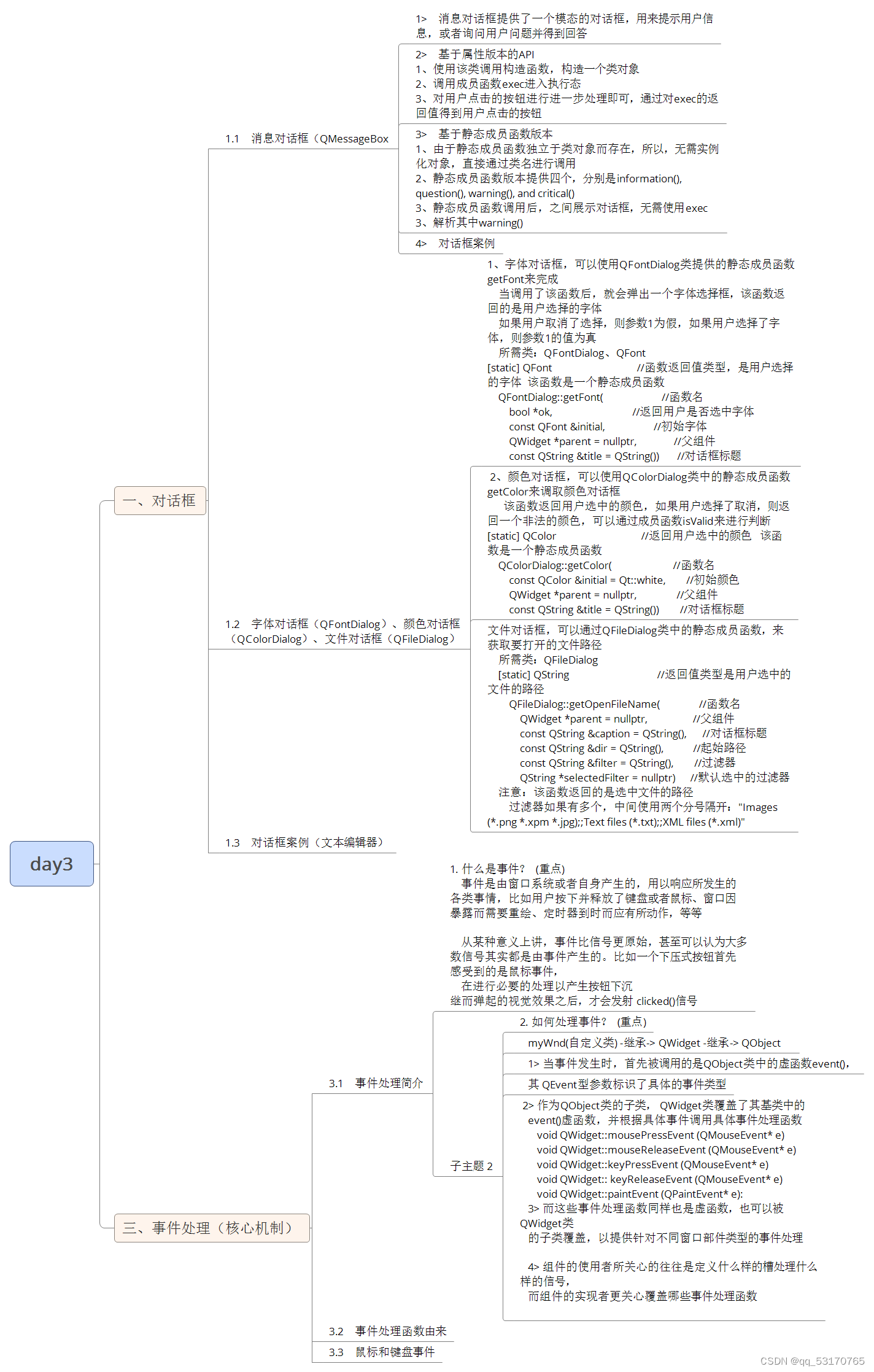
Kafka的Kraft模式
概述
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。其核心组件包含Producer、Broker、Consumer,以及依赖的Zookeeper集群。其中Zookeeper集群是Kafka用来负责集群元数据的管理、控制器的选举等。
用过kafka的开发者应该知道,每次启动kafka服务时,都是需要先把Zookeeper启动,然后启动kafka,步骤相当繁琐。
Kafka在使用的过程当中,会出现一些问题。由于重度依赖Zookeeper集群,当Zookeeper集群性能发生抖动时,Kafka的性能也会收到很大的影响。因此,在Kafka发展的过程当中,为了解决这个问题,提供KRaft模式3.0+版本,来取消Kafka对Zookeeper的依赖。
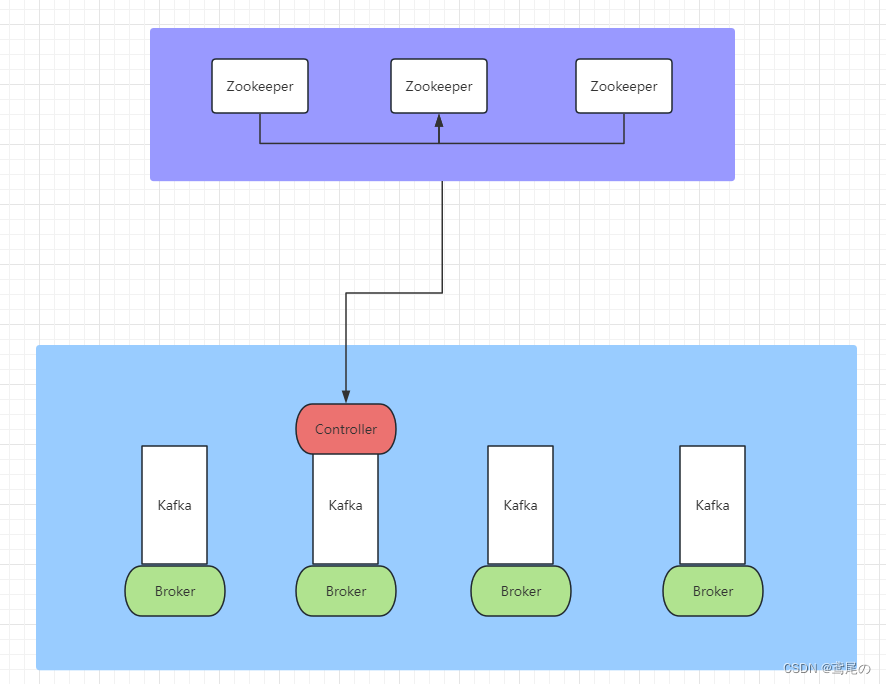
上图是未使用kraft模式时,依赖Zookeeper集群的一个架构图,做元数据管理、Controller的选举都需要依赖Zookeeper集群。
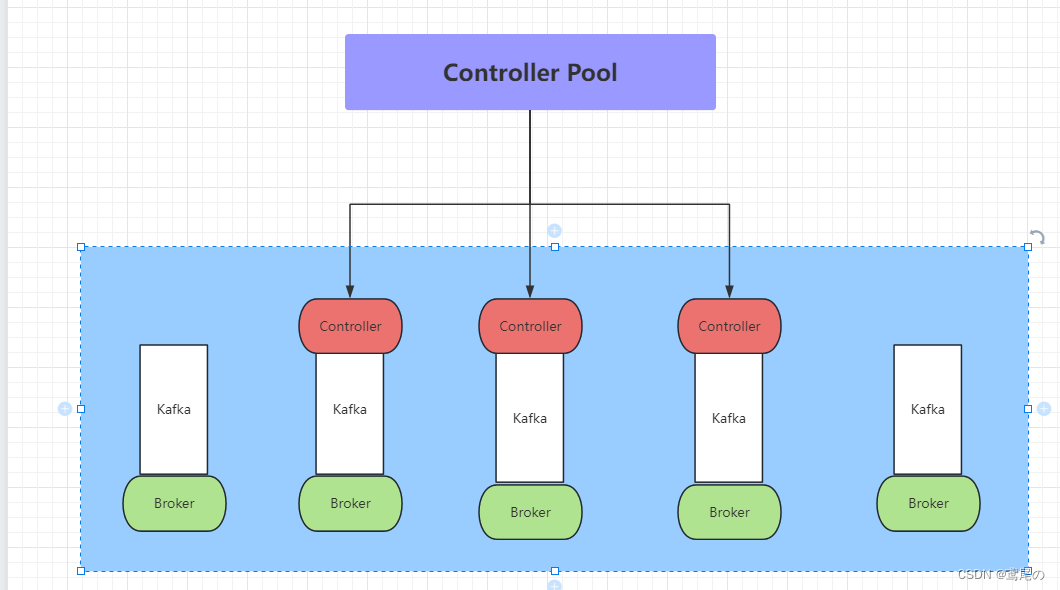
在Kafka引入Kraft新内部功能后,对Zookeeper的依赖将会被取消。在 Kraft中,一部分 broker 被指定为控制器,这些控制器提供过去由 ZooKeeper 提供的共识服务。所有集群元数据都将存储在 Kafka 主题中并在内部进行管理。
优势
- 更简单的部署和管理:通过只安装和管理一个应用程序,Kafka 现在的运营足迹要小得多。这也使得在边缘的小型设备中更容易利用 Kafka;
- 提高可扩展性:KRaft 的恢复时间比 ZooKeeper 快一个数量级。这使我们能够有效地扩展到单个集群中的数百万个分区。ZooKeeper 的有效限制是数万;
- 更有效的元数据传播:基于日志、事件驱动的元数据传播可以提高 Kafka 的许多核心功能的性能
Kraft集群节点角色
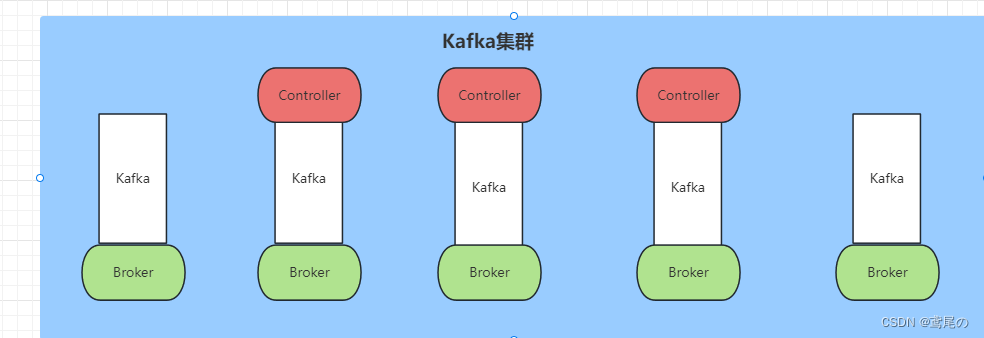
在 Kraft 模式下,Kafka 集群可以走专用模式或共享模式运行。
在专用模式下,一些节点将其process.roles配置设置为controller,而其余节点将其设置为broker。
对于共享模式,一些节点将process.roles设置为controller, broker并且这些节点将执行双重任务。采用哪种方式取决于集群的大小。
controller
在KRaft模式下,只有一小部分特别指定的服务器可以作为控制器,在server.properties的process.roles 参数里面配置。不像基于ZooKeeper的模式,任何服务器都可以成为控制器
Process Roles
每个Kafka服务器现在都有一个新的配置项,叫做process.roles, 这个参数可以有以下值:
- 如果process.roles = broker, 服务器在KRaft模式中充当 broker。
- 如果process.roles = controller, 服务器在KRaft模式下充当 controller。
- 如果process.roles = broker,controller,服务器在KRaft模式中同时充当 broker 和controller。
- 如果process.roles 没有设置。那么集群就假定是运行在ZooKeeper模式下。
Quorum Voters
系统中的所有节点都必须设置 controller.quorum.voters 配置。这个配置标识有哪些节点是 Quorum 的投票者节点。所有想成为控制器的节点都需要包含在这个配置里面。
controller.quorum.voters 配置需要包含每个节点的id。格式为: id1@host1:port1,id2@host2:port2
那么假如有7个broker和3个controller,分别是controller1、controller2、controller3,那么在controller1中的server.properties中会有如下配置:
process.roles=controller
node.id=1
listeners=CONTROLLER://controller1.example.com:9093
controller.quorum.voters=1@controller1:9093,2@controller2:9093,3@controller3:9093
每个broker和每个controller 都必须设置 controller.quorum.voters。需要注意的是,controller.quorum.voters 配置中提供的节点ID必须与提供给服务器的节点ID匹配。
Kraft单机模式
Kafka是依赖于JDK的,需要先把java环境配置一下
到kafka官方地址下载需要的kafka版本即可。下载地址
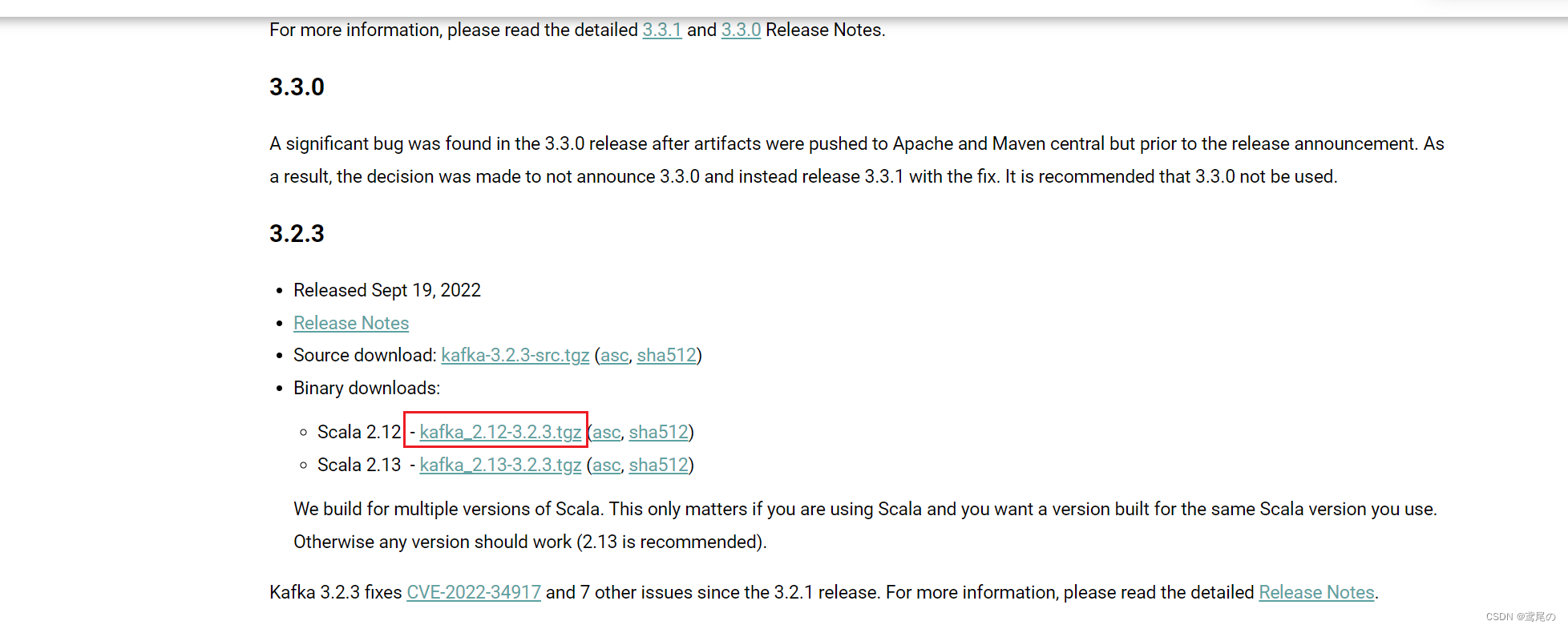
# 下载
wget https://archive.apache.org/dist/kafka/3.2.3/kafka_2.12-3.2.3.tgz# 解压
tar -zxvf kafka_2.12-3.2.3.tgz
解压完毕后,到里面看下目录结构
可以配置一下hosts域名解析(不配置也可以,后面需要用到的配置中直接写localhost就行)
hostnamectl set-hostname kafka1
然后去修改config/kraft/server.properties
# 表示此节点,既是broker又可以当controller
process.roles=broker,controller
# 节点id,不重名即可
node.id=1
# controller竞争者,也就是controller将从它们之中诞生(这里的kafka1是刚刚设置的本机的域名解析,或者直接写localhost也行)
controller.quorum.voters=1@kafka1:9093
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# 监听地址(也就是客户端连接时访问的地址)
advertised.listeners=PLAINTEXT://192.168.1.38:9092
controller.listener.names=CONTROLLER
# kafka数据存放地址
log.dirs=/wlh/kafka/data
整理完毕后,初始化一下数据存储目录
# 生成一个uuid,后面需要用
./bin/kafka-storage.sh random-uuid
# 示例如下:
NxAPV0sdTtSDsMN2IwDgPA# 格式化存储
./bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c ./config/kraft/server.properties
格式化完毕后,可以启动节点了(守护进程启动加-daemon 参数)。
./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
启动完毕后,可以进行连接访问kafka服务器了。记得把防火墙关了,或者只开放9092端口即可。
systemctl stop firewalld
若跨机器访问,如使用windows连接,可以先tcping一下,看看kafka服务器的状态是否正常。
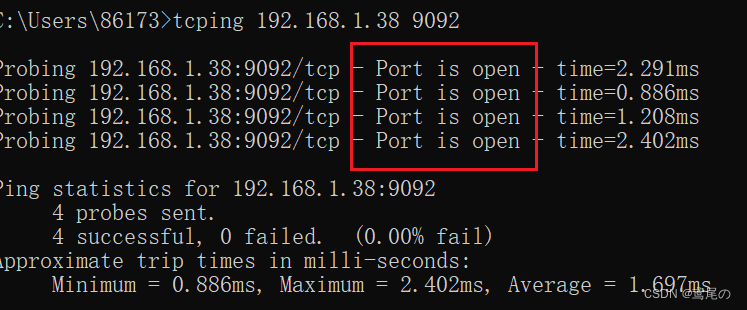
可以看到,没有问题。kafka可视化管理页面https://gitee.com/dushixiang/kafka-map/,有兴趣可以自行搭建。
这里用cmd命令行测试下。
-
服务器创建topic–
kafka-testbin/kafka-topics.sh --create --topic kafka-test --partitions 1 --replication-factor 1 --bootstrap-server kafka1:9092 -
创建生产者、消费者
# 生产者 kafka-console-producer.bat --broker-list 192.168.1.38:9092 --topic kafka-test# 消费者 kafka-console-consumer.bat --bootstrap-server 192.168.1.38:9092 --topic kafka-test
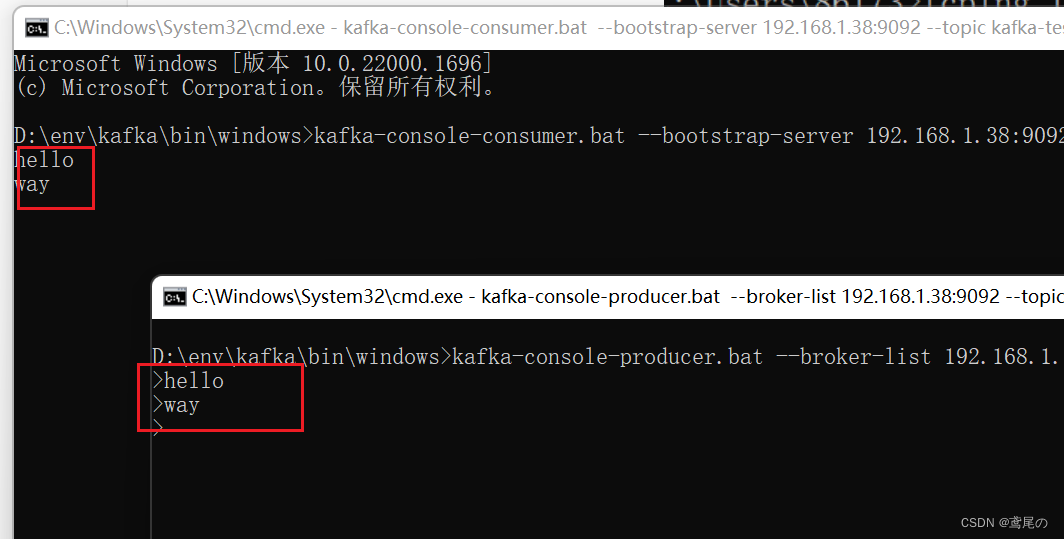
完事儿收工。
kraft集群模式
集群模式和单机模式大差不差,就是配置文件多了的问题。由于机器数量有限,这里就不展示多台服务器的了,看下单台机器部署集群。
准备好3个kafka,分别是kafka01、kafka02、kafka03,分别到它们的config/kraft/server.properties中做配置
kafka01
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@localhost:19093,2@localhost:29093,3@localhost:39093
listeners=PLAINTEXT://:19092,CONTROLLER://:19093
advertised.listeners=PLAINTEXT://192.168.1.38:19092
controller.listener.names=CONTROLLER
log.dirs=/wlh/kafka01/data
kafka02
process.roles=broker,controller
node.id=2
controller.quorum.voters=1@localhost:19093,2@localhost:29093,3@localhost:39093
listeners=PLAINTEXT://:29092,CONTROLLER://:29093
advertised.listeners=PLAINTEXT://192.168.1.38:29092
controller.listener.names=CONTROLLER
log.dirs=/wlh/kafka02/data
kafka03
process.roles=broker,controller
node.id=3
controller.quorum.voters=1@localhost:19093,2@localhost:29093,3@localhost:39093
listeners=PLAINTEXT://:39092,CONTROLLER://:39093
advertised.listeners=PLAINTEXT://192.168.1.38:39092
controller.listener.names=CONTROLLER
log.dirs=/wlh/kafka03/data
配置做完后,生成uuid且格式化它们的存储目录
# 生成一个uuid,后面需要用
/wlh/kafka01/bin/kafka-storage.sh random-uuid
# 示例如下:
NxAPV0sdTtSDsMN2IwDgPA# 格式化存储
/wlh/kafka01/bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c /wlh/kafka01/config/kraft/server.properties
/wlh/kafka02/bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c /wlh/kafka02/config/kraft/server.properties
/wlh/kafka03/bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c /wlh/kafka03/config/kraft/server.properties# 分别启动它们
/wlh/kafka01/bin/kafka-server-start.sh -daemon /wlh/kafka01/config/kraft/server.properties
/wlh/kafka02/bin/kafka-server-start.sh -daemon /wlh/kafka01/config/kraft/server.properties
/wlh/kafka03/bin/kafka-server-start.sh -daemon /wlh/kafka01/config/kraft/server.properties
命令测试一下kafka集群。
kafka1/bin/kafka-topics.sh --create --topic kafka-test --partitions 1 --replication-factor 1 --bootstrap-server 192.168.1.38:19092
# 生产者
kafka-console-producer.bat --broker-list 192.168.1.38:19092,192.168.1.38:29092,192.168.1.38:39092 --topic kafka-test# 消费者
kafka-console-consumer.bat --bootstrap-server 192.168.1.38:19092,192.168.1.38:29092,192.168.1.38:39092 --topic kafka-test
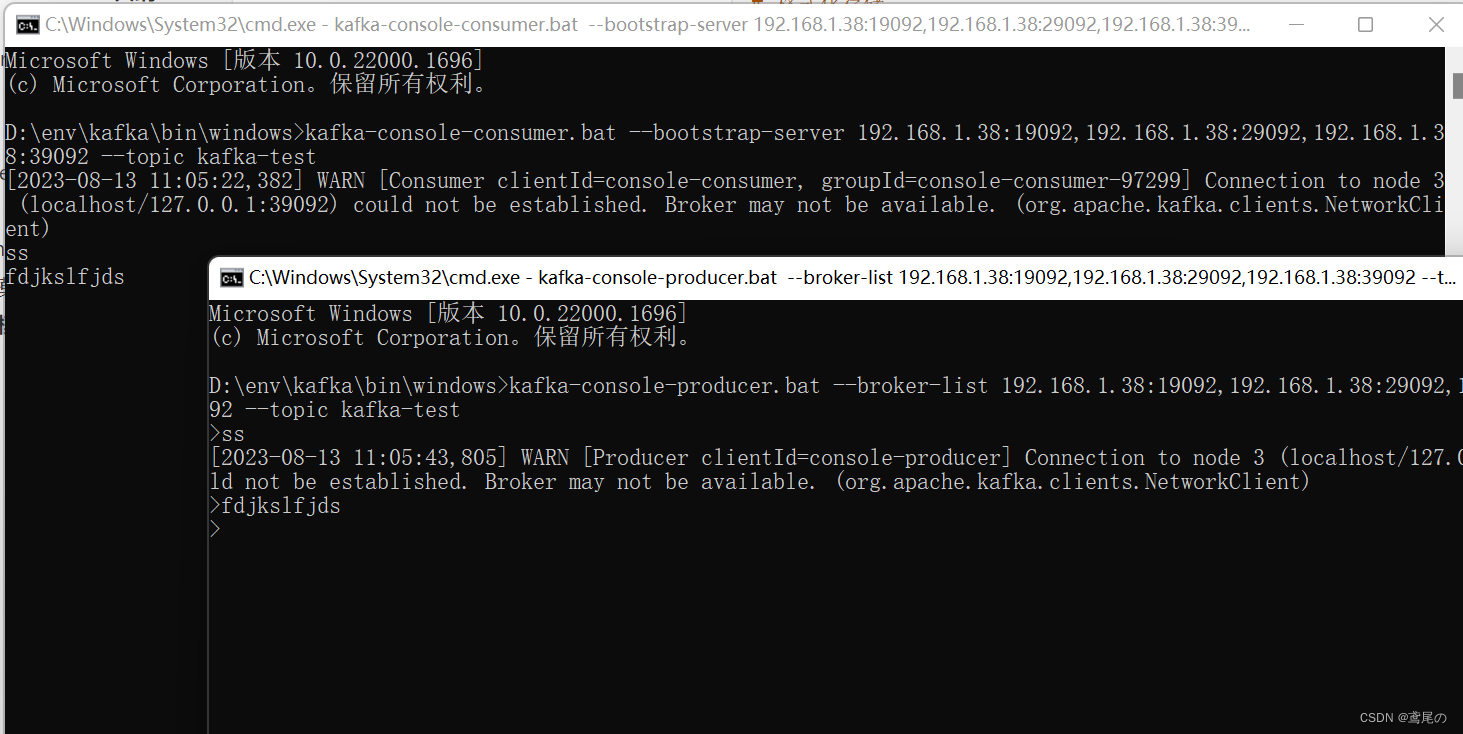
完事儿,大功告成!!