布隆过滤器BloomFilter
先看看大厂真实需求+面试题反馈
1.现有50亿个电话号码,现有10万个电话号码,如何要快速准确的判断这些电话号码是否已经存在?
2.判断是否存在,布隆过滤器了解过吗?
3.安全连接网址,全球数10亿的网址判断
4.黑名单校验,识别垃圾邮件
5.白名单校验,识别出合法用户进行后续处理
是什么:
由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素

设计思想:设计:减少内存占用。方式:不保存数据信息,只是在内存中做一个是否存在的标记flag
布隆过滤器是—种类似set的数据结构,只是统计结果在巨量数据下有点小瑕疵,不够完美
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。
它实际上是一个很长的二进制数组(00000000)+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生

能干嘛:
高效地插入和查询,占用空间少,返回的结果是不确定性+不够完美。一个元素如果判断结果:存在时,元素不一定存在,但是判断结果为不存在时,则一定不存在。布隆过滤器可以添加元素,但是不能删除元素,由于涉及hashcode判断依据,删掉元素会导致误判率增加。
小总结:
有,是可能有。无,是肯定无。可以保证的是,如果布隆过滤器判断一个元素不在一个集合中,那这个元素一定不会在集合中
布隆过滤器原理:
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率。

添加Key、查询key
添加key时
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
查询key时
只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
结论:有,是可能有 无,是肯定无
hash冲突导致数据不精准:
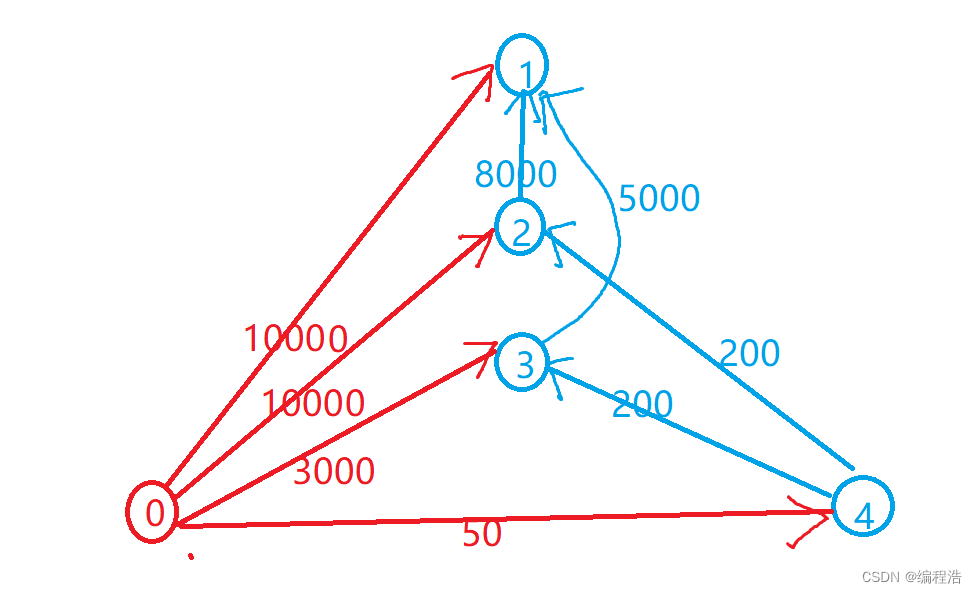
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,把它们置为 1(假定有两个变量都通过 3 个映射函数)。

查询某个变量的时候我们只要看看这些点是不是都是 1, 就可以大概率知道集合中有没有它了。如果这些点,有任何一个为零则被查询变量一定不在,如果都是 1,则被查询变量很可能存在,为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。(见上图3号坑两个对象都1)

hash冲突导致数据不精准2:
哈希函数:
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值

如果两个散列值是不相同的(根据同一函数)那么这两个散列值的原始输入也是不相同的。这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,
这种情况称为“散列碰撞(collision)”。
用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞。
Java中hash冲突java案例:
public class HashCodeConflictDemo
{public static void main(String[] args){Set<Integer> hashCodeSet = new HashSet<>();for (int i = 0; i <200000; i++) {int hashCode = new Object().hashCode();if(hashCodeSet.contains(hashCode)) {System.out.println("出现了重复的hashcode: "+hashCode+"\t 运行到"+i);break;}hashCodeSet.add(hashCode);}System.out.println("Aa".hashCode());
System.out.println("BB".hashCode());
System.out.println("柳柴".hashCode());
System.out.println("柴柕".hashCode());}
}
使用3步骤:
初始化bitmap:布隆过滤器 本质上 是由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0
添加占坑位:当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个 hash 函数对 key 进行运算,算得一个下标索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
例如,我们添加一个字符串wmyskxz,对字符串进行多次hash(key) → 取模运行→ 得到坑位

判断是否存在:
向布隆过滤器查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,只要有一个位为零,那么说明布隆过滤器中这个 key 不存在;如果这几个位置全都是 1,那么说明极有可能存在;因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是前面说过的hash冲突。。。。。
就比如我们在 add 了字符串wmyskxz数据之后,很明显下面1/3/5 这几个位置的 1 是因为第一次添加的 wmyskxz 而导致的;
此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5 ,这就是误判了

布隆过滤器误判率,为什么不要删除:布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素
特性
布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
小总结:
1.是否存在:有,是很可能有。无,是肯定无,100%无
2.使用时最好不要让实际元素数量远大于初始化数量,一次给够避免扩容
3.当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个size更大的过滤器,再将所有的历史元素批量add 进行
布隆过滤器的使用场景
1.解决缓存穿透的问题,和redis结合bitmap使用
缓存穿透是什么
一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库。
当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
缓存透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
可以使用布隆过滤器解决缓存穿透的问题
把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在:
如果布隆过滤器中不存在该条数据则直接返回;
如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则再查询Mysql数据库

2.黑名单校验,识别垃圾邮件
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
布隆过滤器优缺点:
优点:高效地插入和查询,内存占用bit空间少
缺点:不能删除元素。因为删掉元素会导致误判率增加,因为hash冲突同一个位置可能存的东西是多个共有的你删除一个元素的同时可能也把其它的删除了。
存在误判,不能精准过滤。有,是很可能有。无,是肯定无,100%无
为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世(目前用的比较多比较成熟的就是布隆过滤器)
缓存预热+缓存雪崩+缓存击穿+缓存穿透
面试题:
缓存预热、雪崩、穿透、击穿分别是什么?你遇到过那几个情况?
缓存预热你是怎么做的?
如何避免或者减少缓存雪崩?
穿透和击穿有什么区别?他两是一个意思还是截然不同?
穿透和击穿你有什么解决方案?如何避免?
假如出现了缓存不一致,你有哪些修补方案?
缓存预热
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题。
缓存雪崩
发生:
1.redis主机挂了,Redis全盘崩溃,偏硬件运维
2.redis中有大量key同时过期大面积失效,偏软件开发
预防+解决:
1.redis中key设置为永不过期or过期时间错开
2.redis缓存集群实现高可用
主从+哨兵
Redis Cluster
开启Redis持久化机制aof/rdb,尽快恢复缓存集群
3.多缓存结合预防雪崩:ehcache本地缓存+redis缓存
4.服务降级:Hystrix或者阿里sentinel限流&降级
5.阿里云-云数据库Redis版
缓存穿透
请求去查询一条记录,先查redis无,后查mysql无,都查询不到该条记录,但是请求每次都会打到数据库上面去,导致后台数据库压力暴增,这种现象我们称为缓存穿透,这个redis变成了一个摆设。简单说就是,本来无一物,两库都没有。既不在Redis缓存库,也不在mysql,数据库存在被多次暴击风险
解决:


方案1:空对象缓存或者缺省值
第一种解决方案,回写增强
如果发生了缓存穿透,我们可以针对要查询的数据,在Redis里存一个和业务部门商量后确定的缺省值(比如,零、负数、defaultNull等)。比如,键uid:abcdxxx,值defaultNull作为案例的key和value
先去redis查键uid:abcdxxx没有,再去mysql查没有获得 ,这就发生了一次穿透现象。
but,可以增强回写机制
mysql也查不到的话也让redis存入刚刚查不到的key并保护mysql。第一次来查询uid:abcdxxx,redis和mysql都没有,返回null给调用者,但是增强回写后第二次来查uid:abcdxxx,此时redis就有值了。
可以直接从Redis中读取default缺省值返回给业务应用程序,避免了把大量请求发送给mysql处理,打爆mysql。但是,此方法架不住黑客的恶意攻击,有缺陷…,只能解决key相同的情况
But:客或者恶意攻击,黑客会对你的系统进行攻击,拿一个不存在的id去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉
key相同打你系统:第一次打到mysql,空对象缓存后第二次就返回defaultNull缺省值,避免mysql被攻击,不用再到数据库中去走一圈了
key不同打你系统:由于存在空对象缓存和缓存回写(看自己业务不限死),redis中的无关紧要的key也会越写越多(记得设置redis过期时间)
方案2: Google布隆过滤器Guava解决缓存穿透
Guava中布隆过滤器的实现算是比较权威的,所以实际项目中我们可以直接使用Guava布隆过滤器
Guava’s BloomFilter源码出处:https://github.com/google/guava/blob/master/guava/src/com/google/common/hash/BloomFilter.java
案例:白名单过滤器
误判问题,但是概率小可以接受,不能从布隆过滤器删除。全部合法的key都需要放入Guava版布隆过滤器+redis里面,不然数据就是返回null

GuavaBloomFilterService
package com.atguigu.redis7.service;import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;import java.util.ArrayList;
import java.util.List;/*** @auther zzyy* @create 2022-12-30 16:50*/
@Service
@Slf4j
public class GuavaBloomFilterService{public static final int _1W = 10000;//布隆过滤器里预计要插入多少数据public static int size = 100 * _1W;//误判率,它越小误判的个数也就越少(思考,是不是可以设置的无限小,没有误判岂不更好)//fpp the desired false positive probabilitypublic static double fpp = 0.03;// 构建布隆过滤器private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size,fpp);public void guavaBloomFilter(){//1 先往布隆过滤器里面插入100万的样本数据for (int i = 1; i <=size; i++) {bloomFilter.put(i);}//故意取10万个不在过滤器里的值,看看有多少个会被认为在过滤器里List<Integer> list = new ArrayList<>(10 * _1W);for (int i = size+1; i <= size + (10 *_1W); i++) {if (bloomFilter.mightContain(i)) {log.info("被误判了:{}",i);list.add(i);}}log.info("误判的总数量::{}",list.size());}
}
GuavaBloomFilterController
package com.atguigu.redis7.controller;import com.atguigu.redis7.service.GuavaBloomFilterService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;/*** @auther zzyy* @create 2022-12-30 16:50*/
@Api(tags = "google工具Guava处理布隆过滤器")
@RestController
@Slf4j
public class GuavaBloomFilterController
{@Resourceprivate GuavaBloomFilterService guavaBloomFilterService;@ApiOperation("guava布隆过滤器插入100万样本数据并额外10W测试是否存在")@RequestMapping(value = "/guavafilter",method = RequestMethod.GET)public void guavaBloomFilter(){guavaBloomFilterService.guavaBloomFilter();}
}取样本100W数据,查查不在100W范围内,其它10W数据是否存在
现在总共有10万数据是不存在的,误判了3033次,
原始样本:100W
不存在数据:1000001W—1100000W

布隆过滤器说明:

缓存击穿
大量的请求同时查询一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。简单说就是热点key突然失效了,暴打mysql。穿透和击穿,截然不同
危害:会造成某一时刻数据库请求量过大,压力剧增。一般技术部门需要知道热点key是那些个?做到心里有数防止击穿
解决:

热点key失效:1.时间到了自然清除但还被访问到 .2.delete掉的key,刚巧又被访问
方案1:差异失效时间,对于访问频繁的热点key,干脆就不设置过期时间
方案2:互斥更新,采用双检加锁策略。
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。

案例:模拟高并发的天猫聚划算案例code
问题,热点key突然失效导致了缓存击穿
技术方案实现:
分析过程:

redis数据类型选型:

springboot+redis实现高并发的聚划算业务V2
业务类:
entity:
package com.atguigu.redis7.entities;import io.swagger.annotations.ApiModel;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @auther zzyy* @create 2022-12-31 14:24*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel(value = "聚划算活动producet信息")
public class Product
{//产品IDprivate Long id;//产品名称private String name;//产品价格private Integer price;//产品详情private String detail;
}
JHSTaskService:采用定时器将参与聚划算活动的特价商品新增进入redis中
package com.atguigu.redis7.service;import cn.hutool.core.date.DateUtil;
import com.atguigu.redis7.entities.Product;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.TimeUnit;/*** @auther zzyy* @create 2022-12-31 14:26*/
@Service
@Slf4j
public class JHSTaskService
{public static final String JHS_KEY="jhs";public static final String JHS_KEY_A="jhs:a";public static final String JHS_KEY_B="jhs:b";@Autowiredprivate RedisTemplate redisTemplate;/*** 偷个懒不加mybatis了,模拟从数据库读取100件特价商品,用于加载到聚划算的页面中* @return*/private List<Product> getProductsFromMysql() {List<Product> list=new ArrayList<>();for (int i = 1; i <=20; i++) {Random rand = new Random();int id= rand.nextInt(10000);Product obj=new Product((long) id,"product"+i,i,"detail");list.add(obj);}return list;}@PostConstructpublic void initJHS(){log.info("启动定时器淘宝聚划算功能模拟.........."+ DateUtil.now());new Thread(() -> {//模拟定时器一个后台任务,定时把数据库的特价商品,刷新到redis中while (true){//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中List<Product> list=this.getProductsFromMysql();//采用redis list数据结构的lpush来实现存储this.redisTemplate.delete(JHS_KEY);//lpush命令this.redisTemplate.opsForList().leftPushAll(JHS_KEY,list);//间隔一分钟 执行一遍,模拟聚划算每3天刷新一批次参加活动try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }log.info("runJhs定时刷新..............");}},"t1").start();}
}JHSProductController
package com.atguigu.redis7.controller;import com.atguigu.redis7.entities.Product;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.util.CollectionUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;import java.util.List;/*** @auther zzyy* @create 2022-12-31 14:29*/
@RestController
@Slf4j
@Api(tags = "聚划算商品列表接口")
public class JHSProductController
{public static final String JHS_KEY="jhs";public static final String JHS_KEY_A="jhs:a";public static final String JHS_KEY_B="jhs:b";@Autowiredprivate RedisTemplate redisTemplate;/*** 分页查询:在高并发的情况下,只能走redis查询,走db的话必定会把db打垮* @param page* @param size* @return*/@RequestMapping(value = "/pruduct/find",method = RequestMethod.GET)@ApiOperation("按照分页和每页显示容量,点击查看")public List<Product> find(int page, int size) {List<Product> list=null;long start = (page - 1) * size;long end = start + size - 1;try {//采用redis list数据结构的lrange命令实现分页查询list = this.redisTemplate.opsForList().range(JHS_KEY, start, end);if (CollectionUtils.isEmpty(list)) {//TODO 走DB查询}log.info("查询结果:{}", list);} catch (Exception ex) {//这里的异常,一般是redis瘫痪 ,或 redis网络timeoutlog.error("exception:", ex);//TODO 走DB查询}return list;}
}
至此步骤,上述聚划算的功能算是完成,请思考在高并发下有什么经典生产问题?
Bug和隐患说明:
1.热点key突然失效导致可怕的缓存击穿
delete命令执行的一瞬间有空隙,其它请求线程继续找Redis为null,打到了mysql,暴击…

最终目的:
2条命令原子性还是其次,主要是防止热key突然失效暴击mysql打爆系统,
进—步升级加固案例:
互斥跟新,采用双检加锁策略:
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。

差异失效时间:

JHSTaskService:
package com.atguigu.redis7.service;import cn.hutool.core.date.DateUtil;
import com.atguigu.redis7.entities.Product;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.TimeUnit;/*** @auther zzyy* @create 2022-12-31 14:26*/
@Service
@Slf4j
public class JHSTaskService
{public static final String JHS_KEY="jhs";public static final String JHS_KEY_A="jhs:a";public static final String JHS_KEY_B="jhs:b";@Autowiredprivate RedisTemplate redisTemplate;/*** 偷个懒不加mybatis了,模拟从数据库读取100件特价商品,用于加载到聚划算的页面中* @return*/private List<Product> getProductsFromMysql() {List<Product> list=new ArrayList<>();for (int i = 1; i <=20; i++) {Random rand = new Random();int id= rand.nextInt(10000);Product obj=new Product((long) id,"product"+i,i,"detail");list.add(obj);}return list;}//@PostConstructpublic void initJHS(){log.info("启动定时器淘宝聚划算功能模拟.........."+ DateUtil.now());new Thread(() -> {//模拟定时器,定时把数据库的特价商品,刷新到redis中while (true){//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中List<Product> list=this.getProductsFromMysql();//采用redis list数据结构的lpush来实现存储this.redisTemplate.delete(JHS_KEY);//lpush命令this.redisTemplate.opsForList().leftPushAll(JHS_KEY,list);//间隔一分钟 执行一遍try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }log.info("runJhs定时刷新..............");}},"t1").start();}@PostConstructpublic void initJHSAB(){log.info("启动AB定时器计划任务淘宝聚划算功能模拟.........."+DateUtil.now());new Thread(() -> {//模拟定时器,定时把数据库的特价商品,刷新到redis中while (true){//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中List<Product> list=this.getProductsFromMysql();//先更新B缓存this.redisTemplate.delete(JHS_KEY_B);this.redisTemplate.opsForList().leftPushAll(JHS_KEY_B,list);this.redisTemplate.expire(JHS_KEY_B,20L,TimeUnit.DAYS);//再更新A缓存this.redisTemplate.delete(JHS_KEY_A);this.redisTemplate.opsForList().leftPushAll(JHS_KEY_A,list);this.redisTemplate.expire(JHS_KEY_A,15L,TimeUnit.DAYS);//间隔一分钟 执行一遍try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }log.info("runJhs定时刷新双缓存AB两层..............");}},"t1").start();}
}
JHSProductController:
package com.atguigu.redis7.controller;import com.atguigu.redis7.entities.Product;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.util.CollectionUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;import java.util.List;/*** @auther zzyy* @create 2022-12-31 14:29*/
@RestController
@Slf4j
@Api(tags = "聚划算商品列表接口")
public class JHSProductController
{public static final String JHS_KEY="jhs";public static final String JHS_KEY_A="jhs:a";public static final String JHS_KEY_B="jhs:b";@Autowiredprivate RedisTemplate redisTemplate;/*** 分页查询:在高并发的情况下,只能走redis查询,走db的话必定会把db打垮* @param page* @param size* @return*/@RequestMapping(value = "/pruduct/find",method = RequestMethod.GET)@ApiOperation("按照分页和每页显示容量,点击查看")public List<Product> find(int page, int size) {List<Product> list=null;long start = (page - 1) * size;long end = start + size - 1;try {//采用redis list数据结构的lrange命令实现分页查询list = this.redisTemplate.opsForList().range(JHS_KEY, start, end);if (CollectionUtils.isEmpty(list)) {//TODO 走DB查询}log.info("查询结果:{}", list);} catch (Exception ex) {//这里的异常,一般是redis瘫痪 ,或 redis网络timeoutlog.error("exception:", ex);//TODO 走DB查询}return list;}@RequestMapping(value = "/pruduct/findab",method = RequestMethod.GET)@ApiOperation("防止热点key突然失效,AB双缓存架构")public List<Product> findAB(int page, int size) {List<Product> list=null;long start = (page - 1) * size;long end = start + size - 1;try {//采用redis list数据结构的lrange命令实现分页查询list = this.redisTemplate.opsForList().range(JHS_KEY_A, start, end);if (CollectionUtils.isEmpty(list)) {log.info("=========A缓存已经失效了,记得人工修补,B缓存自动延续5天");//用户先查询缓存A(上面的代码),如果缓存A查询不到(例如,更新缓存的时候删除了),再查询缓存Bthis.redisTemplate.opsForList().range(JHS_KEY_B, start, end);//TODO 走DB查询}log.info("查询结果:{}", list);} catch (Exception ex) {//这里的异常,一般是redis瘫痪 ,或 redis网络timeoutlog.error("exception:", ex);//TODO 走DB查询}return list;}
}总结: