前言
本篇文章我们先会学习快速排序这个算法,之后我们会学习sort这个函数
分治算法
在学习快速排序之前,我们先来学习一下分治算法,快速排序就是分治算法的一种,下面是分治算法的介绍,
分治算法,就是”分而治之“
分为分解、治理和合并这三个步骤
后面我们学习快速排序也是从这三个步骤入手
简单来说,分治算法就是将一个大问题分解成许多小的问题,
又因为这些小的问题的解决方案与大问题相同,只是规模更小而已
所以当子问题划分得足够小时,就可以用很简单的方法来解决原本看起来很复杂的大问题。
通过上面的学习,我们可以看出,快速排序就是分治算法中的一种
快速排序算法(可优化版本)
基本步骤
分解
首先将数组中的一个元素作为pivot(轴点 / 基准点,可以理解为分界点)
之后从最左侧的元素和最右侧的元素开始遍历,比轴点大的放到最右侧,比轴点小的就放到最左侧
对于轴点的选择
我们可以选择数组首元素作为轴点,或者最后一个元素,又或者是数组中的任意一个元素
治理
一次排序完成后,分别对轴点左侧和右侧的剩余元素进行排序(使用递归重复上面的步骤)
合并
将最终排序好的各个子串合并到一起,就实现了快速排序这个算法

基本思想就是这样,下面,让我们来逐步实现
分步实现
排序一次
首先以首元素作为基准点(一般都是第一个元素),赋值给pivot变量,数组最左侧元素下标赋值给left变量,最右侧下标赋值给right这个变量
然后,从右向左开始逐个与轴点比较,当其小于轴点时,将这个元素与这个串中left下标指向的元素位置互换,left向右移动一位
然后,从左向右开始逐个与轴点比较,当其大于轴点时,将这个元素与这个串中right指向的那个元素互换,right向左移动一位
重复二三步,直到left与right重合,一次排序完成
对分割后的子串进行排序
排序完一次之后,轴点左侧的元素比轴点小,右侧的元素比轴点大,
之后,分别对左侧的子串和右侧的子串进行排序,
此处需要使用递归,直到传入的参数:left==right时,开始回归,又因为函数返回类型是void,那么也就可以理解为函数调用结束,数组排序完成
例子图解
下面,通过对一个数组进行排序,来更生动的去学习这个算法
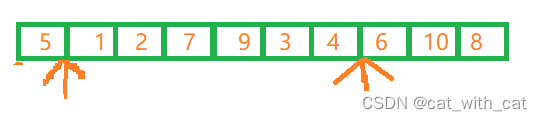
以数组6 1 2 7 9 3 4 5 10 8为例
下面只解释第一次排序的过程
选取轴点
首先,选取首元素6,作为轴点,进行第一次排序,如图所示

从右向左开始排序
从8开始向左逐个查找,查找到5的时候,发现5比轴点小,那么就将5这个元素与轴点(也就是left下标指向的元素)互换,left++,向右移动一位(跳过已经排序完的元素),right变为轴点所在的下标
如图:
从右向左排序
从left所指向的元素开始与轴点比较,当遇到比轴点大的就与轴点互换,然后right–,向左移动一位(跳过已经排序完的元素),left变为轴点所在的下标

继续排序
重复以上两步:先从右侧开始向左查找,替换、再从左向右开始查找,替换
当left和right重合时,说明本次查找完成
递归查找剩下的子串
通过上面的学习,我们可以知道,对与一个串的排序,其基本操作是一样的,只不过规模大小不同罢了,这就是分治算法中提到的分解与治理
代码实现
基本步骤和具体思路都介绍完了,剩下的就是通过代码去实现它了
函数主体
int main()
{int a[10001];int N;cout << "请输入要排序的元素个数" << endl;cin >> N;cout << "请输入要排序的元素" << endl;for (int i = 0; i < N; i++){cin >> a[i];}cout << endl;//可有可无,此处换行只是为了美观Quicksort(a, 0, N - 1);cout << "排序后的数组结果" << endl;for (int i = 0; i < N; i++){cout << a[i] << " ";//这里输入一个空格也是为了美观,方便阅读}cout << endl;return 0;
}
Quicksort函数就是实现递归排序的函数
Quicksort函数
void Quicksort(int* r, int left, int right)
{int mid = 0;if (left < right){mid = part(r, left, right);Quicksort(r, left, mid - 1);Quicksort(r, mid + 1, right);}
}part函数是实现一次排序的函数
part函数
part函数是实现一次排序的函数,并且part函数返回的是一次排序完成后的新的基准值(就是left和right下标重合的位置)
int part(int* r, int left, int right)
{int i = left;int j = right;int pivot = r[left];//选择首元素作为基准点while (i < j){while (i<j && r[j]>pivot)//从右向左查找小于基准点的元素{j--;}if (i < j){swap(r[i++], r[j]);//交换基准点和left下标的元素,并且left下标向右移动一位}while (i < j && r[i] <= pivot)//从左向右查找大于基准点的元素{i++;}if (i < j){swap(r[i], r[j--]);交换基准点和right下标的元素,并且right下标向左移动一位}return i;//返回的是最终划分完成后人(即left和right重合)的新的基准点,//作为字串的left或right的下标}}swap函数
在part函数中,为了更快捷的将两个元素互换,我们使用到了swap函数,下面,就对swap函数做一个简单的介绍
swap(a, b);
这个函数很厉害,
它不仅可以交换整型、浮点型
它还可以交换结构体(当然,成员个数得一样)
下面给一个交换结构体的例子
#include<iostream>
#include<string>
#include<algorithm>//sort函数包含的头文件
using namespace std;
//定义一个学生类型的结构体
typedef struct student
{string name; //学生姓名int achievement; //学生成绩
} student;//用来显示学生信息的函数
void show(student * stu, int n)
{for (int i = 0; i < n; i++){cout << "姓名:" << stu[i].name << '\t' << "成绩:" << stu[i].achievement << endl;}
}int main()
{student stu1[] = { {"李四",87},{"王二",100} };student stu2[] = { {"22",2},{"33",3} };cout << "交换前:" << endl;show(stu1, 3);show(stu2, 3);swap(stu1, stu2);cout << "交换后:" << endl;show(stu1, 3);show(stu2, 3);return 0;
}并且,使用swap函数,不用担心精度的损失
补充说明
对于排序方式的解释
对于为什么要先从右向左开始查找,同学们可能会有疑惑,那么我们不妨试一试先从左向右查找,看看结果如何
还是以“6 1 2 7 9 3 4 5 10 8”这个数组为例子
第一次排序时:
我们先让left从左边开始,遇到小于等于6的继续走,大于6的停下,于是left停在了7的位置;
再让right从右边走,小于6的时候停下,于是right停在5的位置;
这个时候left < right
于是7和5交换位置变成“6 1 2 5 9 3 4 7 10 8”;
继续上面的操作,9和4交换,变成“6 1 2 5 4 3 9 7 10 8”,继续,left先移动,停在了9的位置,这个时候left == right了,那么这一轮就比较完了,最后需要交换left和pivot位置的数(基准数归位),
这个时候,6与9交换,变成了下面的序列:“9 1 2 5 4 3 6 7 10 8”,
这个序列并不是完成了一轮处理之后,基准数左边的都比基准数小,右边的都比它大。所以这样先从左边开始搜索得不到正确结果的。
因此,我们可以得到下面的结论:当基准数选择最左边的数字时,那么就应该先从右边开始搜索;当基准数选择最右边的数字时,那么就应该先从左边开始搜索。不论是从小到大排序还是从大到小排序!
快速排序的优化
其实,我们不需要每次遇到比轴点大 / 比轴点小的元素就与轴点进行交换,可以直接将这两个元素交换,再移动left与right直到二者相等,这就完成了一次排序
再将轴点更新为left下标所在的位置,进行递归排序
至于具体的代码,我还没想明白,在此只是提出这个思路,之后再去实现
快速排序与冒泡排序
冒泡排序我们都知道,这里就不再重复叙述
快速排序与冒泡排序相比,快速排序的优点是
快速排序的每次交换是跳跃式的,就是距离很大
当轴点左侧的元素大于轴点时,会被直接放到右侧right指针所指向的位置,这样交换时跨越的距离是很大的,
而冒泡排序,每次只能是相邻的两个元素进行比较,这样就比较低效了
结语
关于快速排序这个算法知识就介绍到这里了,希望大家都有所收获,我们下篇文章见~