大家好,我是带我去滑雪!
自编码器是一种无监督学习的神经网络,是一种数据压缩算法,主要用于数据降维和特征提取。它的基本思想是将输入数据经过一个编码器映射到隐藏层,再通过一个解码器映射到输出层,使得输出层的结果与输入层的结果尽可能相似。自编码器的主要优点在于可以发现数据中的潜在模式和特征,进而用于特征提取或者压缩数据。它的主要应用领域包括图像去噪,识别和生成等。我们可以使用MLP或者CNN实现自编码器,在实战中自编码器可以应用在机器学习中的主成分分析,在保留主要特征下减少数据集的维数,也可以应用在CNN中,当处理尺寸很大的图片时,可以先使用自编码器来降维提取主要特征,使用主要特征进行学习。本期利用自编码器实现图像去噪。
目录
1、使用MLP创建自编码器
(1)导入相关模块和MNIST手写数据集
(2)数据预处理
(3)定义自编码器模型
(4)创建编码器模型
(5)创建解码器模型
(6)编译模型
(7)训练模型
(8)使用自编码器来编码和解码手写数字图片
2、使用CNN创建自编码器
(1)定义自编码器模型、编码器、解码器
(2)计算压缩图片和解码图片,画图展示
(3)使用CNN自编码器去除图片噪声
1、使用MLP创建自编码器
(1)导入相关模块和MNIST手写数据集
import numpy as np
import pandas as pd
from keras.datasets import mnist
import matplotlib.pyplot as plt
from keras.models import Model
from keras.layers import Input, Dense
# 载入数据集
(X_train, _), (X_test, _) = mnist.load_data()
(2)数据预处理
首先将特征数据转化成28*28的向量,再将数据进行归一化:
#转换成 28*28 = 784 的向量
X_train = X_train.reshape(X_train.shape[0], 28*28).astype("float32")
X_test = X_test.reshape(X_test.shape[0], 28*28).astype("float32")
# 因为是固定范围, 所以执行归一化, 将 0~255 的灰度值转化成 0~1
X_train = X_train / 255
X_test = X_test / 255
X_train.shape输出结果:
(60000, 784)
(3)定义编码器模型
input_img = Input(shape=(784,))
x = Dense(128, activation="relu")(input_img)
encoded = Dense(64, activation="relu")(x)
x = Dense(128, activation="relu")(encoded)
decoded = Dense(784, activation="sigmoid")(x)
autoencoder = Model(input_img, decoded)
autoencoder.summary() # 显示模型信息输出结果:
Model: "model" _________________________________________________________________Layer (type) Output Shape Param # =================================================================input_2 (InputLayer) [(None, 784)] 0 dense_2 (Dense) (None, 128) 100480 dense_3 (Dense) (None, 64) 8256 dense_4 (Dense) (None, 128) 8320 dense_5 (Dense) (None, 784) 101136 ================================================================= Total params: 218,192 Trainable params: 218,192 Non-trainable params: 0
(4)创建编码器模型
编码器模型是自编码器模型的前半段。
encoder = Model(input_img, encoded)
encoder.summary() # 显示编码器模型信息输出结果:
Model: "model_1" _________________________________________________________________Layer (type) Output Shape Param # =================================================================input_2 (InputLayer) [(None, 784)] 0 dense_2 (Dense) (None, 128) 100480 dense_3 (Dense) (None, 64) 8256 ================================================================= Total params: 108,736 Trainable params: 108,736 Non-trainable params: 0
(5)创建解码器模型
decoder_input = Input(shape=(64,))
decoder_layer = autoencoder.layers[-2](decoder_input)
decoder_layer = autoencoder.layers[-1](decoder_layer)
decoder = Model(decoder_input, decoder_layer)
decoder.summary() # 显示解码器模型信息输出结果:
Model: "model_2" _________________________________________________________________Layer (type) Output Shape Param # =================================================================input_3 (InputLayer) [(None, 64)] 0 dense_4 (Dense) (None, 128) 8320 dense_5 (Dense) (None, 784) 101136 ================================================================= Total params: 109,456 Trainable params: 109,456 Non-trainable params: 0 _________________________________________________________________
(6)编译模型
from tensorflow.keras import optimizers
autoencoder.compile(loss="binary_crossentropy", optimizer= optimizers.Adam(),metrics=["accuracy"])
(7)训练模型
autoencoder.fit(X_train, X_train, validation_data=(X_test, X_test),epochs=30, batch_size=256, shuffle=True, verbose=1)
输出结果:
Epoch 23/30 235/235 [==============================] - 1s 6ms/step - loss: 0.0748 - accuracy: 0.0131 - val_loss: 0.0743 - val_accuracy: 0.0131 Epoch 24/30 235/235 [==============================] - 1s 6ms/step - loss: 0.0746 - accuracy: 0.0134 - val_loss: 0.0743 - val_accuracy: 0.0126 Epoch 25/30 235/235 [==============================] - 1s 6ms/step - loss: 0.0745 - accuracy: 0.0130 - val_loss: 0.0739 - val_accuracy: 0.0142 Epoch 26/30 235/235 [==============================] - 1s 6ms/step - loss: 0.0744 - accuracy: 0.0143 - val_loss: 0.0738 - val_accuracy: 0.0119 Epoch 27/30 235/235 [==============================] - 2s 6ms/step - loss: 0.0742 - accuracy: 0.0132 - val_loss: 0.0738 - val_accuracy: 0.0139 Epoch 28/30 235/235 [==============================] - 1s 6ms/step - loss: 0.0741 - accuracy: 0.0139 - val_loss: 0.0738 - val_accuracy: 0.0149 Epoch 29/30 235/235 [==============================] - 1s 6ms/step - loss: 0.0740 - accuracy: 0.0138 - val_loss: 0.0736 - val_accuracy: 0.0135 Epoch 30/30 235/235 [==============================] - 1s 6ms/step - loss: 0.0739 - accuracy: 0.0141 - val_loss: 0.0734 - val_accuracy: 0.0143
(8)使用自编码器来编码和解码手写数字图片
# 压缩图片
encoded_imgs = encoder.predict(X_test)
# 还原图片
decoded_imgs = decoder.predict(encoded_imgs)
# 显示原始, 压缩和还原图片
n = 10 #绘制测试集的前10张图片
plt.figure(figsize=(20, 6))
for i in range(n):
# 原始图片
ax = plt.subplot(3, n, i + 1)
ax.imshow(X_test[i].reshape(28, 28), cmap="gray")
ax.axis("off")
#压缩图片
ax = plt.subplot(3, n, i + 1 + n)
ax.imshow(encoded_imgs[i].reshape(8, 8), cmap="gray")
ax.axis("off")
# 还原图片
ax = plt.subplot(3, n, i + 1 + 2*n)
ax.imshow(decoded_imgs[i].reshape(28, 28), cmap="gray")
ax.axis("off")
plt.savefig("E:\工作\硕士\博客\博客35-深度学习之自编码器实现——实现图像去噪/squares1.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:
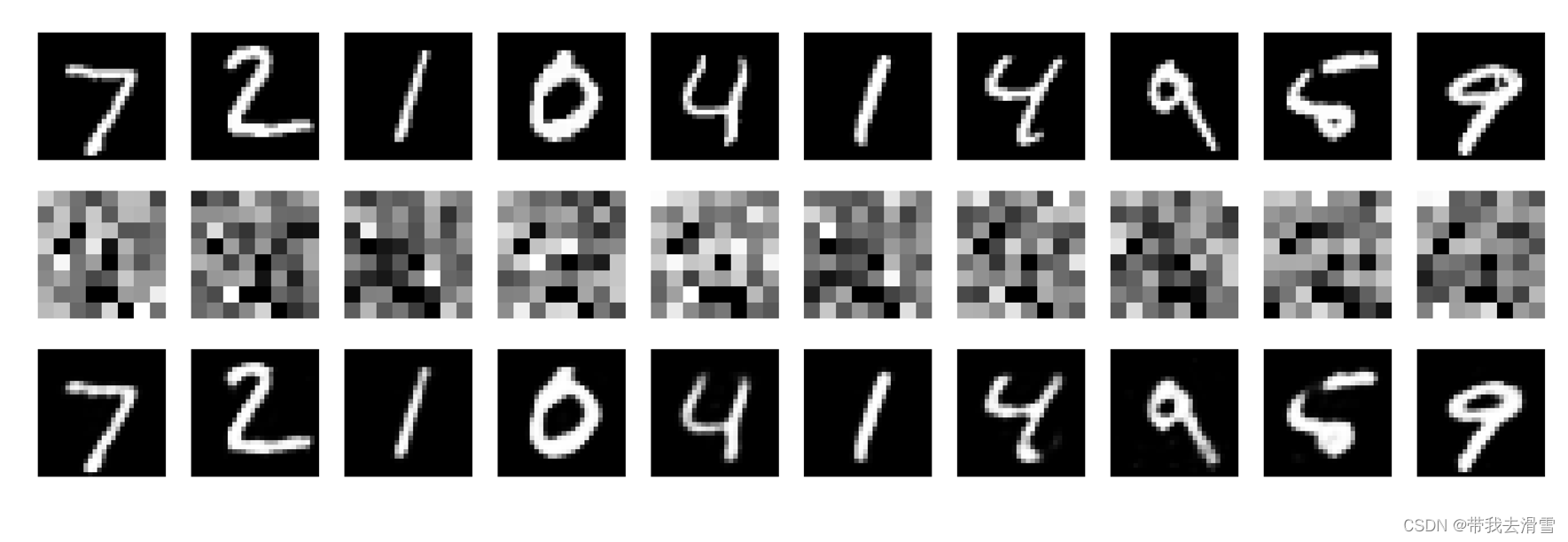
2、使用CNN创建自编码器
(1)定义自编码器模型、编码器、解码器
import numpy as np
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D(X_train, _), (X_test, _) = mnist.load_data()
#转换成4D 张量
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype("float32")
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype("float32")
X_train = X_train / 255
X_test = X_test / 255# 定义 autoencoder 模型
input_img = Input(shape=(28,28,1))
x = Conv2D(16, (3,3), activation="relu", padding="same")(input_img)
x = MaxPooling2D((2,2), padding="same")(x)
x = Conv2D(8, (3,3), activation="relu", padding="same")(x)
x = MaxPooling2D((2,2), padding="same")(x)
x = Conv2D(8, (3,3), activation="relu", padding="same")(x)
encoded = MaxPooling2D((2,2), padding="same")(x)
x = Conv2D(8, (3,3), activation="relu", padding="same")(encoded)
x = UpSampling2D((2,2))(x)
x = Conv2D(8, (3,3), activation="relu", padding="same")(x)
x = UpSampling2D((2,2))(x)
x = Conv2D(16, (3,3), activation="relu")(x)
x = UpSampling2D((2,2))(x)
decoded = Conv2D(1, (3, 3), activation="sigmoid", padding="same")(x)
autoencoder = Model(input_img, decoded)
autoencoder.summary() # 显示自编码器模型信息
#定义 编码器encoder 模型
encoder = Model(input_img, encoded)
encoder.summary() #显示编码器模型信息#定义解码器 decoder 模型
decoder_input = Input(shape=(4,4,8))
decoder_layer = autoencoder.layers[-7](decoder_input)
decoder_layer = autoencoder.layers[-6](decoder_layer)
decoder_layer = autoencoder.layers[-5](decoder_layer)
decoder_layer = autoencoder.layers[-4](decoder_layer)
decoder_layer = autoencoder.layers[-3](decoder_layer)
decoder_layer = autoencoder.layers[-2](decoder_layer)
decoder_layer = autoencoder.layers[-1](decoder_layer)
decoder = Model(decoder_input, decoder_layer)
decoder.summary() # 显示解码器模型信息输出结果:
Model: "model_6" _________________________________________________________________Layer (type) Output Shape Param # =================================================================input_6 (InputLayer) [(None, 28, 28, 1)] 0 conv2d_14 (Conv2D) (None, 28, 28, 16) 160 max_pooling2d_6 (MaxPooling (None, 14, 14, 16) 0 2D) conv2d_15 (Conv2D) (None, 14, 14, 8) 1160 max_pooling2d_7 (MaxPooling (None, 7, 7, 8) 0 2D) conv2d_16 (Conv2D) (None, 7, 7, 8) 584 max_pooling2d_8 (MaxPooling (None, 4, 4, 8) 0 2D) conv2d_17 (Conv2D) (None, 4, 4, 8) 584 up_sampling2d_6 (UpSampling (None, 8, 8, 8) 0 2D) conv2d_18 (Conv2D) (None, 8, 8, 8) 584 up_sampling2d_7 (UpSampling (None, 16, 16, 8) 0 2D) conv2d_19 (Conv2D) (None, 14, 14, 16) 1168 up_sampling2d_8 (UpSampling (None, 28, 28, 16) 0 2D) conv2d_20 (Conv2D) (None, 28, 28, 1) 145 ================================================================= Total params: 4,385 Trainable params: 4,385 Non-trainable params: 0 _________________________________________________________________ Model: "model_7" _________________________________________________________________Layer (type) Output Shape Param # =================================================================input_6 (InputLayer) [(None, 28, 28, 1)] 0 conv2d_14 (Conv2D) (None, 28, 28, 16) 160 max_pooling2d_6 (MaxPooling (None, 14, 14, 16) 0 2D) conv2d_15 (Conv2D) (None, 14, 14, 8) 1160 max_pooling2d_7 (MaxPooling (None, 7, 7, 8) 0 2D) conv2d_16 (Conv2D) (None, 7, 7, 8) 584 max_pooling2d_8 (MaxPooling (None, 4, 4, 8) 0 2D) ================================================================= Total params: 1,904 Trainable params: 1,904 Non-trainable params: 0 _________________________________________________________________ Model: "model_8" _________________________________________________________________Layer (type) Output Shape Param # =================================================================input_7 (InputLayer) [(None, 4, 4, 8)] 0 conv2d_17 (Conv2D) (None, 4, 4, 8) 584 up_sampling2d_6 (UpSampling (None, 8, 8, 8) 0 2D) conv2d_18 (Conv2D) (None, 8, 8, 8) 584 up_sampling2d_7 (UpSampling (None, 16, 16, 8) 0 2D) conv2d_19 (Conv2D) (None, 14, 14, 16) 1168 up_sampling2d_8 (UpSampling (None, 28, 28, 16) 0 2D) conv2d_20 (Conv2D) (None, 28, 28, 1) 145 ================================================================= Total params: 2,481 Trainable params: 2,481 Non-trainable params: 0 _________________________________________________________________
(2)计算压缩图片和解码图片,画图展示
# 压缩图片
encoded_imgs = encoder.predict(X_test)
#解压图片
decoded_imgs = decoder.predict(encoded_imgs)
# 显示原始, 压缩和还原图片
import matplotlib.pyplot as plt
n = 10 #显示测试集前10张图片
plt.figure(figsize=(20, 8))
for i in range(n):
# 原始图片
ax = plt.subplot(3, n, i + 1)
ax.imshow(X_test[i].reshape(28, 28), cmap="gray")
ax.axis("off")
# 压缩图片
ax = plt.subplot(3, n, i + 1 + n)
ax.imshow(encoded_imgs[i].reshape(4, 4*8).T, cmap="gray")
ax.axis("off")
# 还原图片
ax = plt.subplot(3, n, i + 1 + 2*n)
ax.imshow(decoded_imgs[i].reshape(28, 28), cmap="gray")
ax.axis("off")
plt.savefig("E:\工作\硕士\博客\博客35-深度学习之自编码器实现——实现图像去噪/squares2.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:

(3)使用CNN自编码器去除图片噪声
import numpy as np
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D
(X_train, _), (X_test, _) = mnist.load_data()
# 转换成4D 张量
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype("float32")
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype("float32")
X_train = X_train / 255
X_test = X_test / 255
# 添加噪声
nf = 0.5
size_train = X_train.shape
X_train_noisy = X_train+nf*np.random.normal(loc=0.0, scale=1.0,size=size_train)
X_train_noisy = np.clip(X_train_noisy, 0., 1.)
size_test = X_test.shape
X_test_noisy = X_test+nf*np.random.normal(loc=0.0,scale=1.0,size=size_test)
X_test_noisy = np.clip(X_test_noisy, 0., 1.)
# 定义自编码器 autoencoder 模型
input_img = Input(shape=(28,28,1))
x = Conv2D(16, (3,3), activation="relu", padding="same")(input_img)
x = MaxPooling2D((2,2), padding="same")(x)
x = Conv2D(8, (3,3), activation="relu", padding="same")(x)
x = MaxPooling2D((2,2), padding="same")(x)
x = Conv2D(8, (3,3), activation="relu", padding="same")(x)
encoded = MaxPooling2D((2,2), padding="same")(x)
x = Conv2D(8, (3,3), activation="relu", padding="same")(encoded)
x = UpSampling2D((2,2))(x)
x = Conv2D(8, (3,3), activation="relu", padding="same")(x)
x = UpSampling2D((2,2))(x)
x = Conv2D(16, (3,3), activation="relu")(x)
x = UpSampling2D((2,2))(x)
decoded = Conv2D(1, (3, 3), activation="sigmoid", padding="same")(x)
autoencoder = Model(input_img, decoded)
autoencoder.summary()
# 定义编码器encoder 模型
encoder = Model(input_img, encoded)
encoder.summary()
# 定义解码器 decoder 模型
decoder_input = Input(shape=(4,4,8))
decoder_layer = autoencoder.layers[-7](decoder_input)
decoder_layer = autoencoder.layers[-6](decoder_layer)
decoder_layer = autoencoder.layers[-5](decoder_layer)
decoder_layer = autoencoder.layers[-4](decoder_layer)
decoder_layer = autoencoder.layers[-3](decoder_layer)
decoder_layer = autoencoder.layers[-2](decoder_layer)
decoder_layer = autoencoder.layers[-1](decoder_layer)
decoder = Model(decoder_input, decoder_layer)
decoder.summary()
# 编译模型
autoencoder.compile(loss="binary_crossentropy", optimizer="adam",metrics=["accuracy"])
# 训练模型
autoencoder.fit(X_train_noisy, X_train,
validation_data=(X_test_noisy, X_test),
epochs=10, batch_size=128, shuffle=True, verbose=2)
# 压缩图片
encoded_imgs = encoder.predict(X_test_noisy)
#解压缩图片
decoded_imgs = decoder.predict(encoded_imgs)
# 显示原始, 压缩和还原图片
import matplotlib.pyplot as plt
n = 10
plt.figure(figsize=(20, 8))
for i in range(n):
# 原始图片
ax = plt.subplot(3, n, i + 1)
ax.imshow(X_test_noisy[i].reshape(28, 28), cmap="gray")
ax.axis("off")
#压缩图片
ax = plt.subplot(3, n, i + 1 + n)
ax.imshow(encoded_imgs[i].reshape(4, 4*8).T, cmap="gray")
ax.axis("off")
# 还原图片
ax = plt.subplot(3, n, i + 1 + 2*n)
ax.imshow(decoded_imgs[i].reshape(28, 28), cmap="gray")
ax.axis("off")
plt.savefig("E:\工作\硕士\博客\博客35-深度学习之自编码器实现——实现图像去噪/squares3.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:

更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!