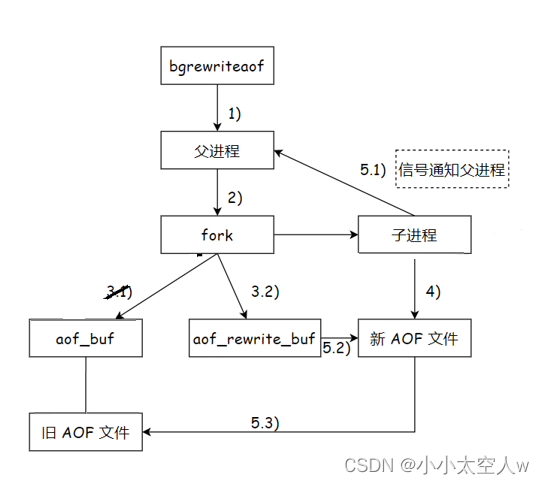
上一节介绍了如何审查分类算法,并介绍了六种不同的分类算法,还
用同一个数据集按照相同的方式对它们做了审查,本章将用相同的方式对回归算法进行审查。
在本节将学到:
- 如何审查机器学习的回归算法。
- 如何审查四种线性分类算法。
- 如何审查三种非线性分类算法。
算法概述
本章将审查七种回归算法。首先介绍四种线性算法:
- 线性回归算法。
- 岭回归算法(脊回归算法)。
- 套索回归算法。
- 弹性网络(Elastic Net)回归算法。
然后介绍三种非线性算法:
- K近邻算法(KNN)。
- 分类与回归树算法。
- 支持向量机(SVM)。
本章将使用波士顿房价的数据集来审查回归算法,采用10折交叉验证来分离数据,并应用到所有的算法上。另外,还会通过均方误差来评估算法模型。scikit-learn 中的cross_val_score()函数能够帮助评估算法模型,我们就用这个函数来评估算法模型。
线性算法分析
首先介绍scikit-learn中用来处理机器学习中的回归问题的四种算法。
线性回归算法
线性回归算法是利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达式为y=w’x+e,e表示误差服从均值为 0 的正态分布。在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
在scikit-learn中实现线性回归算法的是LinearRegression类。
代码如下:
数据集下载地址
import pandas as pd
from sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import KFold, cross_val_score#数据预处理
path = 'D:\down\\BostonHousing.csv'
data = pd.read_csv(path)array = data.valuesX = array[:, 0:13]
Y = array[:, 13]n_splits = 10seed = 7kflod = KFold(n_splits=n_splits, random_state=seed, shuffle=True)
#
model = LinearRegression()scoring = 'neg_mean_squared_error'results = cross_val_score(model, X, Y, cv=kflod, scoring=scoring)print("LinearRegression MSE: %.3f (%.3f)" % (results.mean(), results.std()))运行结果:
LinearRegression MSE: -23.747 (11.143)
岭回归算法
岭回归算法是一种专门用于共线性数据分析的有偏估计回归方法,实际上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损
失部分信息、降低精度为代价,获得回归系数更符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。在scikit-learn中实现岭回归算法的是Ridge类。
代码如下:
import pandas as pd
from sklearn.linear_model import LinearRegression, Ridgefrom sklearn.model_selection import KFold, cross_val_score#数据预处理
path = 'D:\down\\BostonHousing.csv'
data = pd.read_csv(path)array = data.valuesX = array[:, 0:13]
Y = array[:, 13]n_splits = 10seed = 7kflod = KFold(n_splits=n_splits, random_state=seed, shuffle=True)
#
model = Ridge()scoring = 'neg_mean_squared_error'results = cross_val_score(model, X, Y, cv=kflod, scoring=scoring)print("Ridge MSE: %.3f (%.3f)" % (results.mean(), results.std()))运行结果:
Ridge MSE: -23.890 (11.407)
套索回归算法
套索回归算法和岭回归算法类似,套索回归算法也会惩罚回归系数,在套索回归中会惩罚回归系数的绝对值大小。此外,它能够减少变化程度并提高线性回归模型的精度。套索回归算法和岭回归算法有一点不同,它使用的惩罚函数是绝对值,而不是平方。这导致惩罚(或等于约束估计的绝对值之和)值使一些参数估计结果等于零。使用惩罚值越大,进一步估计会使缩小值越趋近零。这将导致我们要从给定的n个变量中选择变量。如果预测的一组变量高度相似,套索回归算法会选择其中的一个变量,并将其他的变量收缩为零。
在scikit-learn中的实现类是Lasso。
代码如下:
import pandas as pd
from sklearn.linear_model import LinearRegression, Ridge, Lassofrom sklearn.model_selection import KFold, cross_val_score#数据预处理
path = 'D:\down\\BostonHousing.csv'
data = pd.read_csv(path)array = data.valuesX = array[:, 0:13]
Y = array[:, 13]n_splits = 10seed = 7kflod = KFold(n_splits=n_splits, random_state=seed, shuffle=True)
#
model = Lasso()scoring = 'neg_mean_squared_error'results = cross_val_score(model, X, Y, cv=kflod, scoring=scoring)print("Lasso MSE: %.3f (%.3f)" % (results.mean(), results.std()))运行结果:
Lasso MSE: -28.746 (12.002)
弹性网络回归算法
弹性网络回归算法是套索回归算法和岭回归算法的混合体,在模型训练时,弹性网络回归算法综合使用L1和L2两种正则化方法。当有多个相关的特征时,弹性网络回归算法是很有用的,套索回归算法会随机挑选算法中的一个,而弹性网络回归算法则会选择两个。与套索回归算法和岭回归算法相比,弹性网络回归算法的优点是,它允许弹性网络回归继承循环状态下岭回归的一些稳定性。另外,在高度相关变量的情况下,它会产生群体效应;选择变量的数目没有限制;可以承受双重收缩。
在 scikit-learn中的实现类是ElasticNet。
代码如下:
import pandas as pd
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNetfrom sklearn.model_selection import KFold, cross_val_score#数据预处理
path = 'D:\down\\BostonHousing.csv'
data = pd.read_csv(path)array = data.valuesX = array[:, 0:13]
Y = array[:, 13]n_splits = 10seed = 7kflod = KFold(n_splits=n_splits, random_state=seed, shuffle=True)
#
model = ElasticNet()scoring = 'neg_mean_squared_error'results = cross_val_score(model, X, Y, cv=kflod, scoring=scoring)print("ElasticNet MSE: %.3f (%.3f)" % (results.mean(), results.std()))运行结果:
ElasticNet MSE: -27.908 (11.484)