CVPR2023-PyramidFlow-zero shot异常检测网络 代码调试记录
- 一.论文以及开源代码
- 二.前期代码准备
- 三.环境配置
- 四.bug调试
- num_samples should be a positive integer value, but got num_samples=0
- AttributeError: Can't pickle local object 'fix_randseed.<locals>.seed_worker'
- 五.数据集准备
- 六.训练
- 七.推理
一.论文以及开源代码
PyramidFlow一篇2023年发表于CVPR的关于无监督异常检测算法的论文,由浙江大学出品,下面附上论文和代码链接:
论文链接:PyramidFlow论文
代码链接:PyramidFlow源代码
二.前期代码准备
首先,我们需要把我在一中提到的代码先git clone到我们的项目路径中,这是我们接下去的训练代码,当然其中也包括了验证和测试(推理过程也包含在内部了,需要自己写一小部分)。然后我们还需要去作者的官网git clone一份名为autoFlow的项目代码,这里面包含了训练代码中将会调用的一些函数,十分重要:
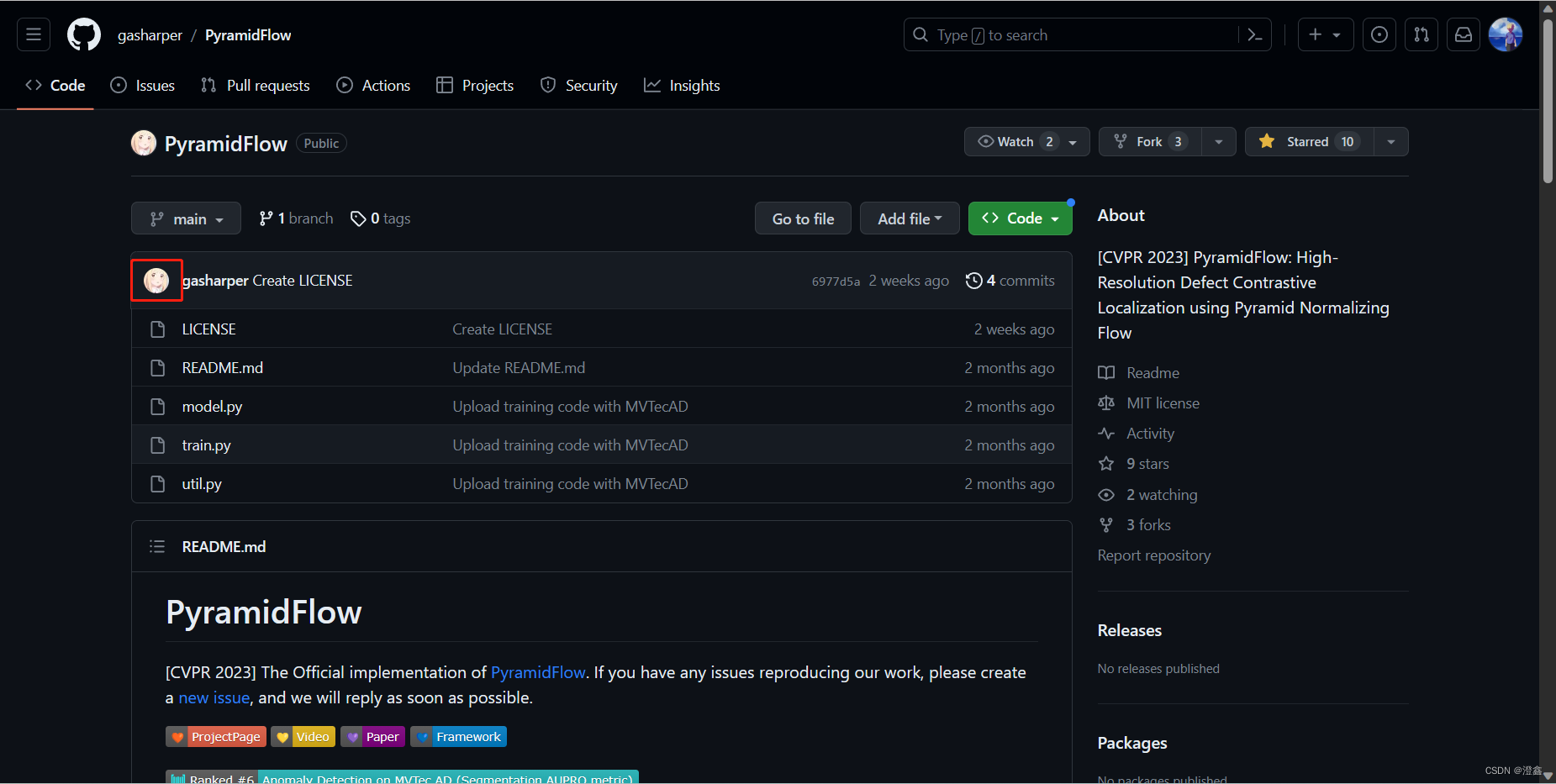
进入训练代码的链接后,点击作者头像,如图所示。然后我们便进入了作者的github主页,点击主页下方的这个链接:
就可以跳转到这个页面:
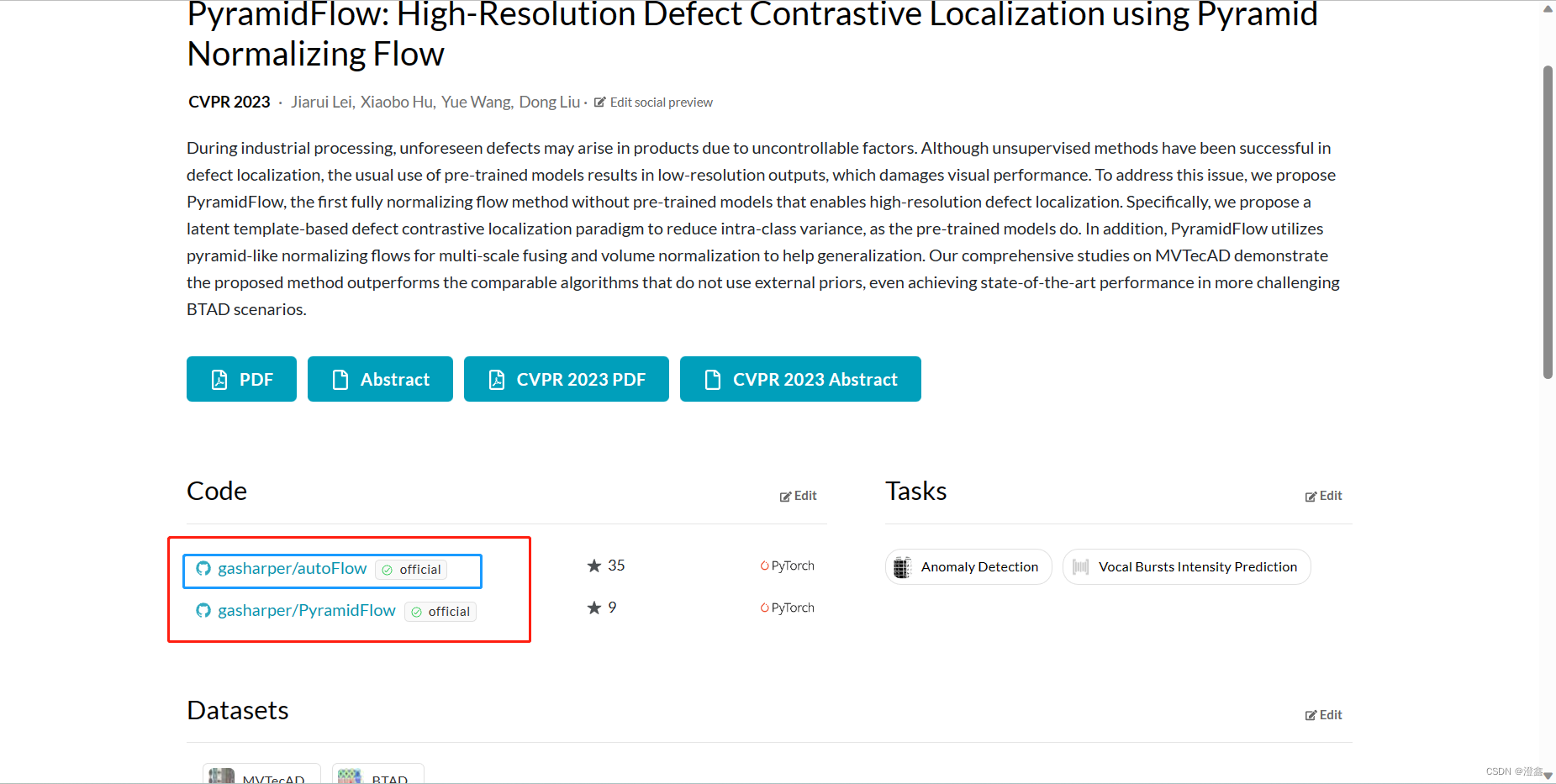
红框中包含了两个链接,其中一个是我们在第一步就已经clone好的训练代码,不用管他了,现在我们点击蓝色框中的链接:

点击code然后复制链接,然后打开git工具使用git clone命令行即可:
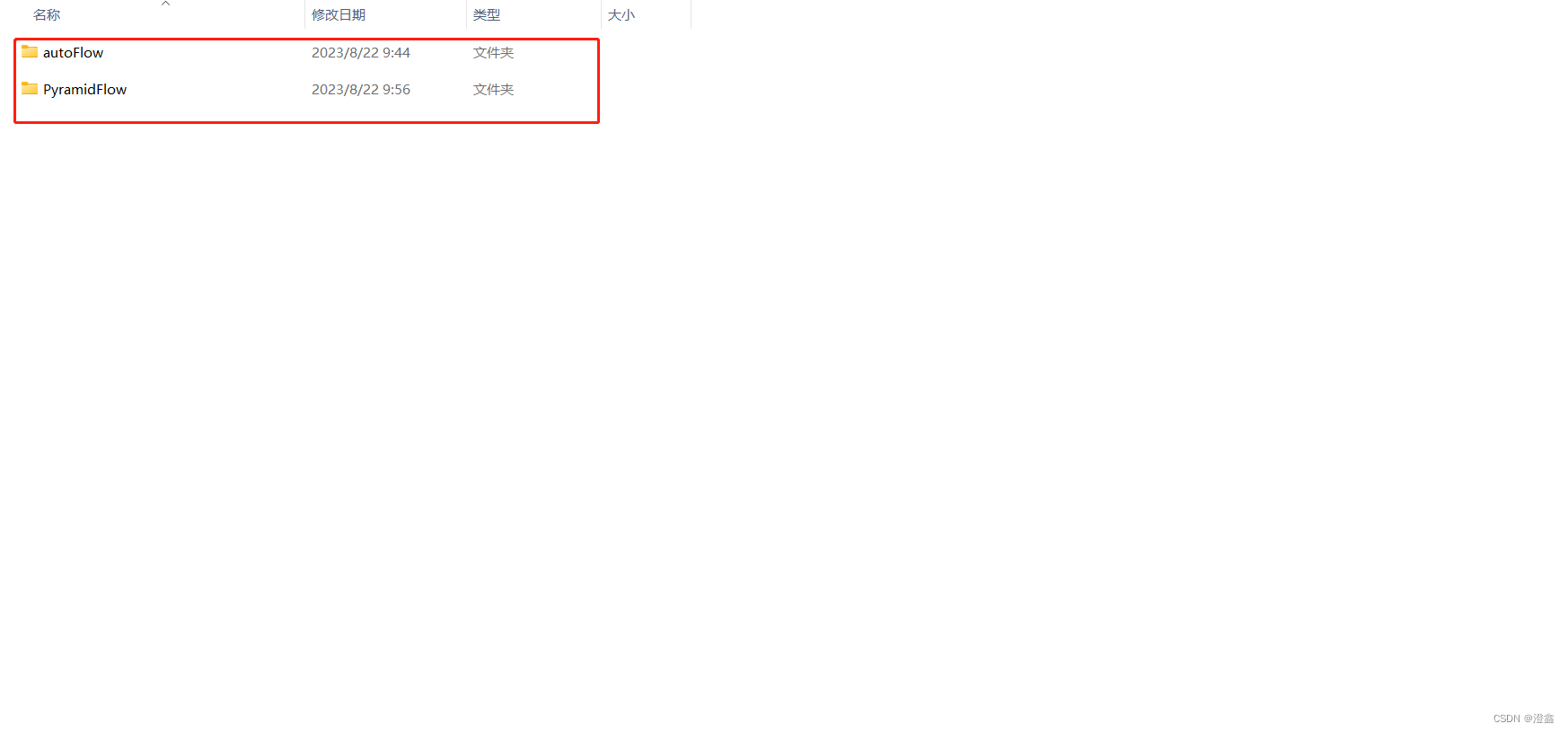
此时,两个项目都已经拷贝下来了,我这里选择将autoflow这个文件夹直接复制到了PyramidFlow里面,这样方便PyramidFlow中代码的调用:
三.环境配置
PyramidFlow的环境,作者已经在Readme中给出,按照里面的版本pip install即可,如果下载速度过慢,可以设置默认源为清华源,可以大大方便我们配置环境。
四.bug调试
这里默认大家的环境已经按照要求配置好了。
num_samples should be a positive integer value, but got num_samples=0
这时候我们直接运行PyramidFlow中的train.py时一般会报这个错误:

这个问题的原因主要是torch库中的DataLoader函数加载数据时,如果已经设置了batch_size,就不需要设置shuffle=True来打乱数据了,此时需要把shuffle设置为False,DataLoader的具体参数可以参考如下:
DataLoader(train_dataset, batch_size=batch_size, shuffle=False, num_workers=1, persistent_workers=True, pin_memory=True, drop_last=True, **loader_dict)
参数解释:
dataset:包含所有数据的数据集,加载的数据集(Dataset对象)
batch_size :每个batch包含的数据数量
Shuffle : 是否打乱数据位置。
sampler : 自定义从数据集中采样的策略,如果制定了采样策略,shuffle则必须为False.
Batch_sampler:和sampler一样,但是每次返回一组的索引,和batch_size, shuffle, sampler, drop_last 互斥。
num_workers : 使用线程的数量,当为0时数据直接加载到主程序,默认为0。
collate_fn:如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可
pin_memory:s 是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些
drop_last: dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃
AttributeError: Can’t pickle local object ‘fix_randseed..seed_worker’
打开util.py:
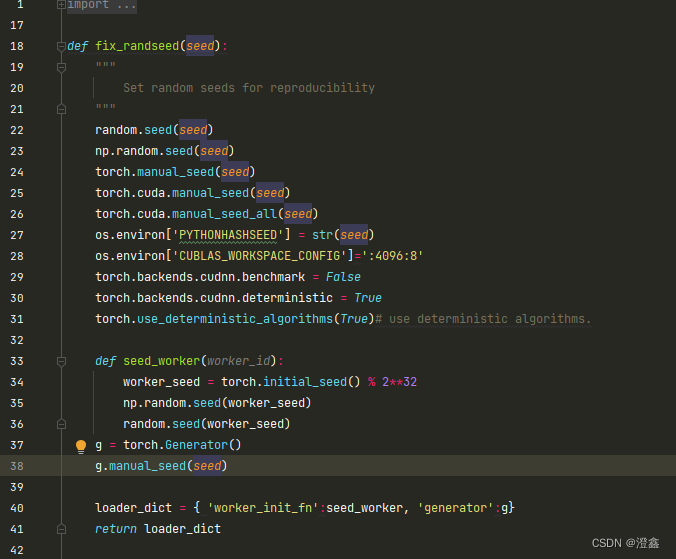
我将这段代码中的seed_worker直接独立出来:
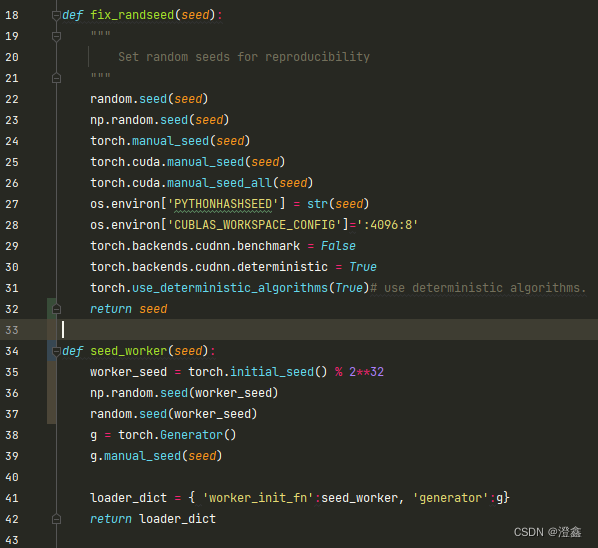
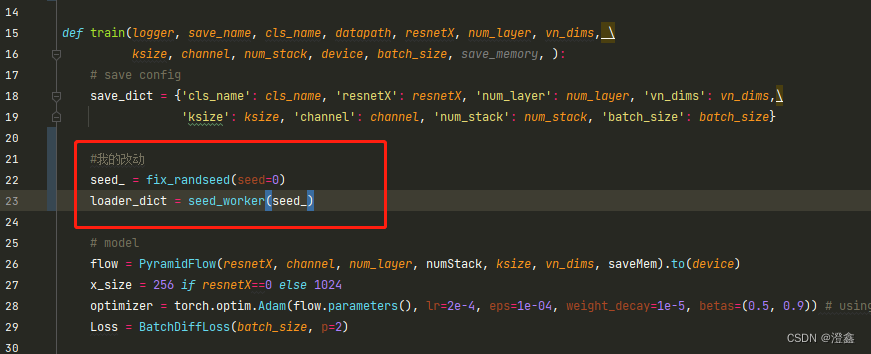
然后在train.py代码中,我们需要创建一个变量接收fix_randseed的返回值,然后将这个返回值作为seed_worker的参数传入:
五.数据集准备
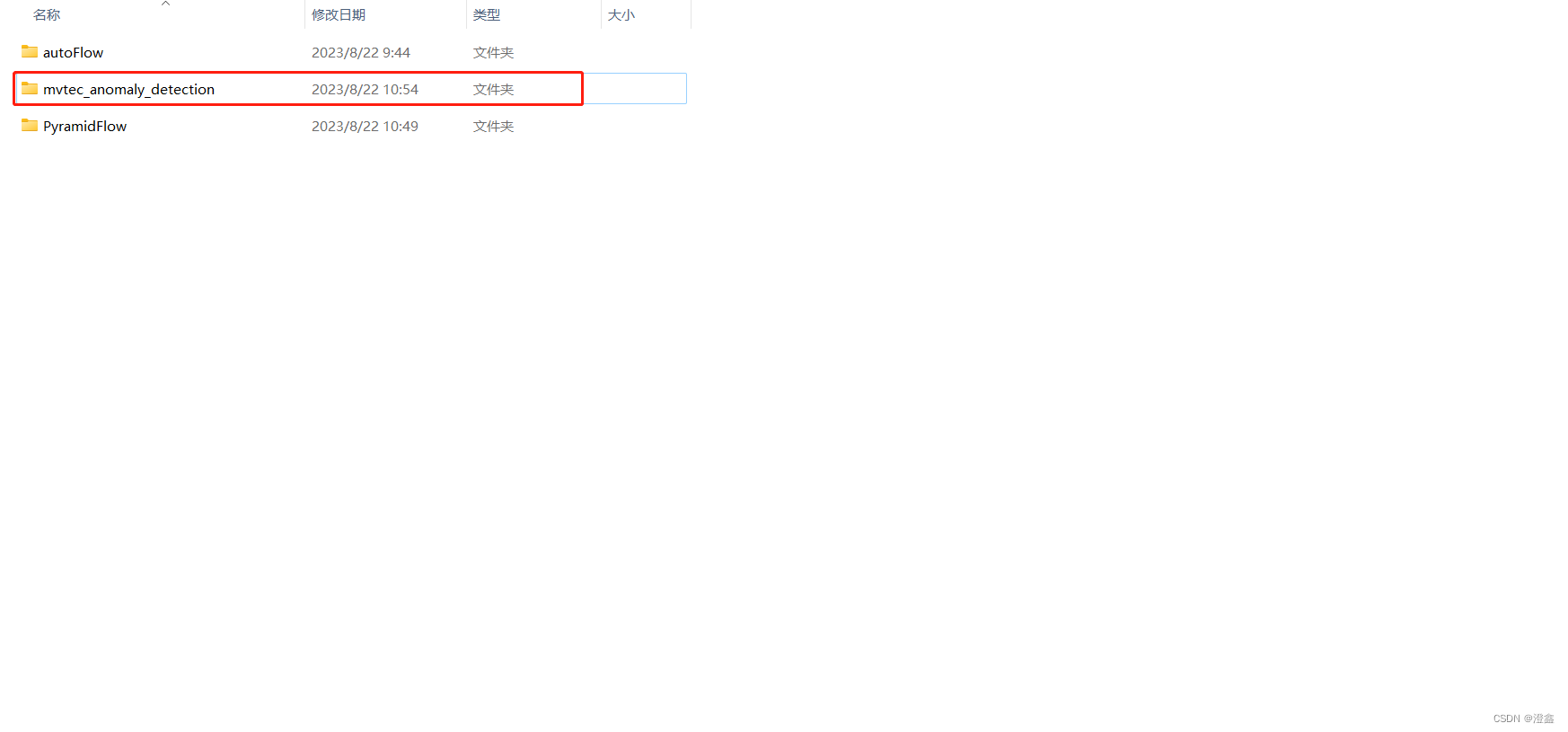
用到的是Mvtec数据集,放在项目文件夹的同一级路径下,改名为如下所示:
六.训练
作者在源代码中是在训练代码的最后一npz的形式保存了模型的权重,由于我对这个npz了解甚少,并且我平时推理常用的都是pt,onnx或者tensorRT的engine等,因此,我在训练代码的最后加了一句torch.save()来将模型以pt的方式保存,见110行代码:
import torch
import torch.nn as nn
from torch.utils.data import DataLoaderimport numpy as np
import time, argparse
from sklearn.metrics import roc_auc_scorefrom model import PyramidFlow
from util import MVTecAD, BatchDiffLoss
from util import fix_randseed, compute_pro_score_fast, getLogger, seed_worker
import cv2def train(logger, save_name, cls_name, datapath, resnetX, num_layer, vn_dims, \ksize, channel, num_stack, device, batch_size, save_memory, ):# save configsave_dict = {'cls_name': cls_name, 'resnetX': resnetX, 'num_layer': num_layer, 'vn_dims': vn_dims,\'ksize': ksize, 'channel': channel, 'num_stack': num_stack, 'batch_size': batch_size}#我的改动seed_ = fix_randseed(seed=0)loader_dict = seed_worker(seed_)# model flow = PyramidFlow(resnetX, channel, num_layer, numStack, ksize, vn_dims, saveMem).to(device)x_size = 256 if resnetX==0 else 1024optimizer = torch.optim.Adam(flow.parameters(), lr=2e-4, eps=1e-04, weight_decay=1e-5, betas=(0.5, 0.9)) # using cs-flow optimizerLoss = BatchDiffLoss(batch_size, p=2)# datasettrain_dataset = MVTecAD(cls_name, mode='train', x_size=x_size, y_size=256, datapath=datapath)val_dataset = MVTecAD(cls_name, mode='val', x_size=x_size, y_size=256, datapath=datapath)test_dataset = MVTecAD(cls_name, mode='test', x_size=x_size, y_size=256, datapath=datapath)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1, persistent_workers=True, pin_memory=True, drop_last=True, **loader_dict)val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False, num_workers=1, persistent_workers=True, pin_memory=True, drop_last=False, **loader_dict)test_loader = DataLoader(test_dataset, batch_size=4, shuffle=False, num_workers=1, persistent_workers=True, pin_memory=True, **loader_dict)# training & evaluationpixel_auroc_lst = [0]pixel_pro_lst = [0]image_auroc_lst = [0]losses_lst = [0]t0 = time.time()for epoch in range(15):# trainflow.train()losses = []for train_dict in train_loader:image, labels = train_dict['images'].to(device), train_dict['labels'].to(device)optimizer.zero_grad()pyramid2= flow(image)diffes = Loss(pyramid2)diff_pixel = flow.pyramid.compose_pyramid(diffes).mean(1) loss = torch.fft.fft2(diff_pixel).abs().mean() # Fourier lossloss.backward()nn.utils.clip_grad_norm_(flow.parameters(), max_norm=1e0) # Avoiding numerical explosionsoptimizer.step()losses.append(loss.item())mean_loss = np.mean(losses)logger.info(f'Epoch: {epoch}, mean_loss: {mean_loss:.4f}, time: {time.time()-t0:.1f}s')losses_lst.append(mean_loss)# val for template flow.eval()feat_sum, cnt = [0 for _ in range(num_layer)], 0for val_dict in val_loader:image = val_dict['images'].to(device)with torch.no_grad():pyramid2= flow(image) cnt += 1feat_sum = [p0+p for p0, p in zip(feat_sum, pyramid2)]feat_mean = [p/cnt for p in feat_sum]# testflow.eval()diff_list, labels_list = [], []for test_dict in test_loader:image, labels = test_dict['images'].to(device), test_dict['labels']with torch.no_grad():pyramid2 = flow(image) pyramid_diff = [(feat2 - template).abs() for feat2, template in zip(pyramid2, feat_mean)]diff = flow.pyramid.compose_pyramid(pyramid_diff).mean(1, keepdim=True)# b,1,h,wdiff_list.append(diff.cpu())labels_list.append(labels.cpu()==1)# b,1,h,wlabels_all = torch.concat(labels_list, dim=0)# b1hw amaps = torch.concat(diff_list, dim=0)# b1hw amaps, labels_all = amaps[:, 0], labels_all[:, 0] # both b,h,wpixel_auroc = roc_auc_score(labels_all.flatten(), amaps.flatten()) # pixel scoreimage_auroc = roc_auc_score(labels_all.amax((-1,-2)), amaps.amax((-1,-2))) # image scorepixel_pro = compute_pro_score_fast(amaps, labels_all) # pro scorelogger.info(f' TEST Pixel-AUROC: {pixel_auroc}, time: {time.time()-t0:.1f}s')logger.info(f' TEST Image-AUROC: {image_auroc}, time: {time.time()-t0:.1f}s')logger.info(f' TEST Pixel-PRO: {pixel_pro}, time: {time.time()-t0:.1f}s')if pixel_auroc > np.max(pixel_auroc_lst):save_dict['state_dict_pixel'] = {k: v.cpu() for k, v in flow.state_dict().items()} # save ckptif pixel_pro > np.max(pixel_pro_lst):save_dict['state_dict_pro'] = {k: v.cpu() for k, v in flow.state_dict().items()} # save ckptpixel_auroc_lst.append(pixel_auroc)pixel_pro_lst.append(pixel_pro)image_auroc_lst.append(image_auroc)del amaps, labels_all, diff_list, labels_listsave_dict['pixel_auroc_lst'] = pixel_auroc_lstsave_dict['image_auroc_lst'] = image_auroc_lstsave_dict['pixel_pro_lst'] = pixel_pro_lstsave_dict['losses_lst'] = losses_lsttorch.save(flow, "best.pt")np.savez(f'saveDir/{save_name}.npz', **save_dict) # save allif __name__ == '__main__':parser = argparse.ArgumentParser(description='Training on MVTecAD')parser.add_argument('--cls', type=str, default='bottle', choices=\['tile', 'leather', 'hazelnut', 'toothbrush', 'wood', 'bottle', 'cable', \'capsule', 'pill', 'transistor', 'carpet', 'zipper', 'grid', 'screw', 'metal_nut'])parser.add_argument('--datapath', type=str, default='../mvtec_anomaly_detection')# hyper-parameters of architectureparser.add_argument('--encoder', type=str, default='resnet18', choices=['none', 'resnet18', 'resnet34'])parser.add_argument('--numLayer', type=str, default='auto', choices=['auto', '2', '4', '8'])parser.add_argument('--volumeNorm', type=str, default='auto', choices=['auto', 'CVN', 'SVN'])# non-key parameters of architectureparser.add_argument('--kernelSize', type=int, default=7, choices=[3, 5, 7, 9, 11])parser.add_argument('--numChannel', type=int, default=16)parser.add_argument('--numStack', type=int, default=4)# other parametersparser.add_argument('--gpu', type=int, default=0)parser.add_argument('--batchSize', type=int, default=2)parser.add_argument('--saveMemory', type=bool, default=True) args = parser.parse_args()cls_name = args.clsresnetX = 0 if args.encoder=='none' else int(args.encoder[6:])if args.volumeNorm == 'auto':vn_dims = (0, 2, 3) if cls_name in ['carpet', 'grid', 'bottle', 'transistor'] else (0, 1)elif args.volumeNorm == 'CVN':vn_dims = (0, 1)elif args.volumeNorm == 'SVN':vn_dims = (0, 2, 3)if args.numLayer == 'auto':num_layer = 4if cls_name in ['metal_nut', 'carpet', 'transistor']:num_layer = 8elif cls_name in ['screw',]:num_layer = 2else:num_layer = int(args.numLayer)ksize = args.kernelSizenumChannel = args.numChannelnumStack = args.numStackgpu_id = args.gpubatchSize = args.batchSizesaveMem = args.saveMemorydatapath = args.datapathlogger, save_name = getLogger(f'./saveDir')logger.info(f'========== Config ==========')logger.info(f'> Class: {cls_name}')logger.info(f'> MVTecAD dataset root: {datapath}')logger.info(f'> Encoder: {args.encoder}')logger.info(f"> Volume Normalization: {'CVN' if len(vn_dims)==2 else 'SVN'}")logger.info(f'> Num of Pyramid Layer: {num_layer}')logger.info(f'> Conv Kernel Size in NF: {ksize}')logger.info(f'> Num of Channels in NF: {numChannel}')logger.info(f'> Num of Stack Block: {numStack}')logger.info(f'> Batch Size: {batchSize}')logger.info(f'> GPU device: cuda:{gpu_id}')logger.info(f'> Save Training Memory: {saveMem}')logger.info(f'============================')train(logger, save_name, cls_name, datapath,\resnetX, num_layer, vn_dims, \ksize=ksize, channel=numChannel, num_stack=numStack, \device=f'cuda:{gpu_id}', batch_size=batchSize, save_memory=saveMem)
到这里,训练完之后,我们就得到了模型的权重pt文件,为我们后面的推理做准备。
七.推理
未完待续