系列文章目录
机器学习之SVM分类器介绍——核函数、SVM分类器的使用
机器学习的一些常见算法介绍【线性回归,岭回归,套索回归,弹性网络】
机器学习相关概念思维导图
文章目录
系列文章目录
前言
Adaboost算法的简单介绍
Adaboost算法相关函数简介
案例介绍
1、简单的Adaboost回归的示例
2、案例二
总结
前言
本文主要介绍Adaboost集成学习算法,以及一些案例举例
Adaboost算法的简单介绍
Adaboost是一种集成学习算法,用于构建一个强大的分类器或回归器。在Adaboost中,每个弱分类器/回归器都是由弱学习算法(例如决策树或线性回归)构成的。每个弱分类器/回归器都对样本进行分类或预测,并根据分类/预测的准确性进行加权。然后,所有弱分类器/回归器的加权和被用作最终分类器/回归器。Adaboost算法通过迭代地训练弱分类器/回归器,并调整样本的权重来提高整体模型的准确性。
Adaboost算法相关函数简介
Adaboost的相关函数包括AdaBoostClassifier和AdaBoostRegressor。这些函数都可以在sklearn.ensemble中找到。其中AdaBoostClassifier用于分类问题,AdaBoostRegressor用于回归问题。这些函数都包含许多参数,例如弱学习器,学习率和迭代次数。
案例介绍
1、简单的Adaboost回归的示例
import numpy as np
from sklearn.ensemble import AdaBoostRegressor
from sklearn.tree import DecisionTreeRegressor# 生成训练数据
X = np.linspace(-np.pi, np.pi, 200)
y = np.sin(X)# 创建决策树回归器
dt = DecisionTreeRegressor(max_depth=2)# 创建Adaboost回归器
abr = AdaBoostRegressor(dt, n_estimators=100, learning_rate=0.1)# 训练模型
abr.fit(X.reshape(-1, 1), y)# 绘制结果
import matplotlib.pyplot as plt
plt.scatter(X, y, c='b', label='data')
plt.plot(X, abr.predict(X.reshape(-1, 1)), c='r', label='Adaboost Regressor')
plt.legend()
plt.show()
在这个例子中,我们使用Adaboost回归器来拟合正弦函数。我们使用决策树回归器作为弱学习器,并设置迭代次数为100,学习率为0.1。在训练完模型后,我们绘制了训练数据和拟合结果。
2、案例二
使用Adaboost分类器(基于SVM、决策树)对乳腺癌数据进行对比分析
#使用Adaboost分类器(基于SVM、决策树)对乳腺癌数据进行对比分析
#导入sklearn内置数据集
from sklearn.datasets import load_breast_cancer
#导入乳腺癌数据
cancer =load_breast_cancer()
#导入sklearn中的模型验证类
from sklearn.model_selection import train_test_split
#使用train_ test_split函数自动分割训练数据集和测试数据集
x_train,x_test,y_train,y_test = train_test_split(cancer.data,cancer.target,test_size=0.3)
#导人sklearn模块中的SVM包
from sklearn import svm
svc = svm.SVC(kernel='linear',gamma=5)
svc.fit(x_train,y_train)
print("单个sVC在训练集上的性能:%.3f"%svc.score(x_train,y_train))
print("单个sVC在测试集上的性能:%.3f"%svc.score(x_test,y_test))
#导人sklearn模块中的AdaBoost分类器类
from sklearn.ensemble import AdaBoostClassifier
#定义一个AdaBoost分类器对象,使用SVC分类器作为基分类器
abcl = AdaBoostClassifier(svm.SVC(kernel='linear',gamma=5),algorithm="SAMME",n_estimators=50,learning_rate=0.1)
abcl.fit(x_train,y_train)
print("nAdaBoot(SVC)在训练集上的性能:%.3f"%(abcl.score(x_train,y_train)))
print("AdaBoot(SVC)在测试集上的性能:%.3f"%(abcl.score(x_test,y_test)))
#导入sklearn模块中的决策树分类器类
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(x_train,y_train)
print("单棵决策树在训练集上的性能:%.3f"%dtc.score(x_train,y_train))
print("单棵决策树在测试集上的性能:%.3f"%dtc.score(x_test,y_test))
#定义一个AdaBoost分类器对象,使用决策树分类器作为基分类器
abc2 = AdaBoostClassifier(DecisionTreeClassifier(),algorithm="SAMME",n_estimators=50,learning_rate=0.1)
abc2.fit(x_train,y_train)
print("\nAdaBoot(决策树)在训练集上的性能:%.3f"%abc2.score(x_train,y_train))
print("AdaBoot(决策树)在测试集上的性能:%.3f"%abc2.score(x_test,y_test))#输出二分类指标
y_predict =abcl.predict(x_test)
from sklearn import metrics
print('\n测试集混淆矩阵:\n',metrics.confusion_matrix(y_test,y_predict))
print('测试集准确率:%.3f'%(metrics.accuracy_score(y_test,y_predict)))
print('测试集精度:%.3f'%(metrics.precision_score(y_test,y_predict)))
print('测试集召回率:%.3f'%(metrics.recall_score(y_test,y_predict)))
print('测试集F1值:%.3f'%(metrics.f1_score(y_test,y_predict)))
print('测试集Fbeta值(beta=0.1):%.3f'%(metrics.fbeta_score(y_test,y_predict,beta=0.1)))
print('测试集Fbeta值(beta=10):%.3f'%(metrics.fbeta_score(y_test,y_predict,beta=10)))
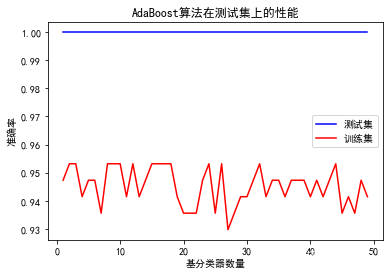
print('测试集分类报告:\n',metrics.classification_report(y_test,y_predict,target_names=['class_0','class_I']))#观察弱分类器数量在测试集上分类准确度
abc_train_scores=[]
abc_test_scores=[]
for i in range(1,50):abc = AdaBoostClassifier(DecisionTreeClassifier(),n_estimators=i)abc.fit(x_train,y_train)abc_train_scores.append(abc.score(x_train,y_train))abc_test_scores.append(abc.score(x_test,y_test))
import matplotlib.pyplot as plt
#解决图形中的中文显示乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
#解决图形中的坐标轴负号显示问题
plt.matplotlib.rcParams['axes.unicode_minus']=False
plt.figure()
plt.title("AdaBoost算法在测试集上的性能")
plt.xlabel("基分类器数量")
plt.ylabel("准确率")
plt.plot(range(1,50),abc_train_scores,color='b',label='测试集')
plt.plot(range(1,50),abc_test_scores,color='r',label='训练集')
plt.legend()
plt.show()运行结果:
单个sVC在训练集上的性能:0.965 单个sVC在测试集上的性能:0.959 nAdaBoot(SVC)在训练集上的性能:0.945 AdaBoot(SVC)在测试集上的性能:0.959 单棵决策树在训练集上的性能:1.000 单棵决策树在测试集上的性能:0.936AdaBoot(决策树)在训练集上的性能:1.000 AdaBoot(决策树)在测试集上的性能:0.947测试集混淆矩阵:[[66 5][ 2 98]] 测试集准确率:0.959 测试集精度:0.951 测试集召回率:0.980 测试集F1值:0.966 测试集Fbeta值(beta=0.1):0.952 测试集Fbeta值(beta=10):0.980 测试集分类报告:precision recall f1-score supportclass_0 0.97 0.93 0.95 71class_I 0.95 0.98 0.97 100accuracy 0.96 171macro avg 0.96 0.95 0.96 171 weighted avg 0.96 0.96 0.96 171
总结
以上就是今天的内容~
最后欢迎大家点赞👍,收藏⭐,转发🚀,
如有问题、建议,请您在评论区留言💬哦。