双指针//哈希表 解决链表有环等问题
- 19. 删除链表的倒数第N个结点
- 遍历两次,先求得链表长度,再删除
- 双指针,只遍历一次
- 141. 环形链表
- 哈希表
- 快慢双指针
- 142. 环形链表Ⅱ
- 哈希表
- 双指针
- 面试题02.07. 链表相交
- 哈希表
- 双指针
- 思路Ⅰ
- 思路Ⅱ
19. 删除链表的倒数第N个结点
题目链接:19. 删除链表的倒数第N个结点
题目内容:
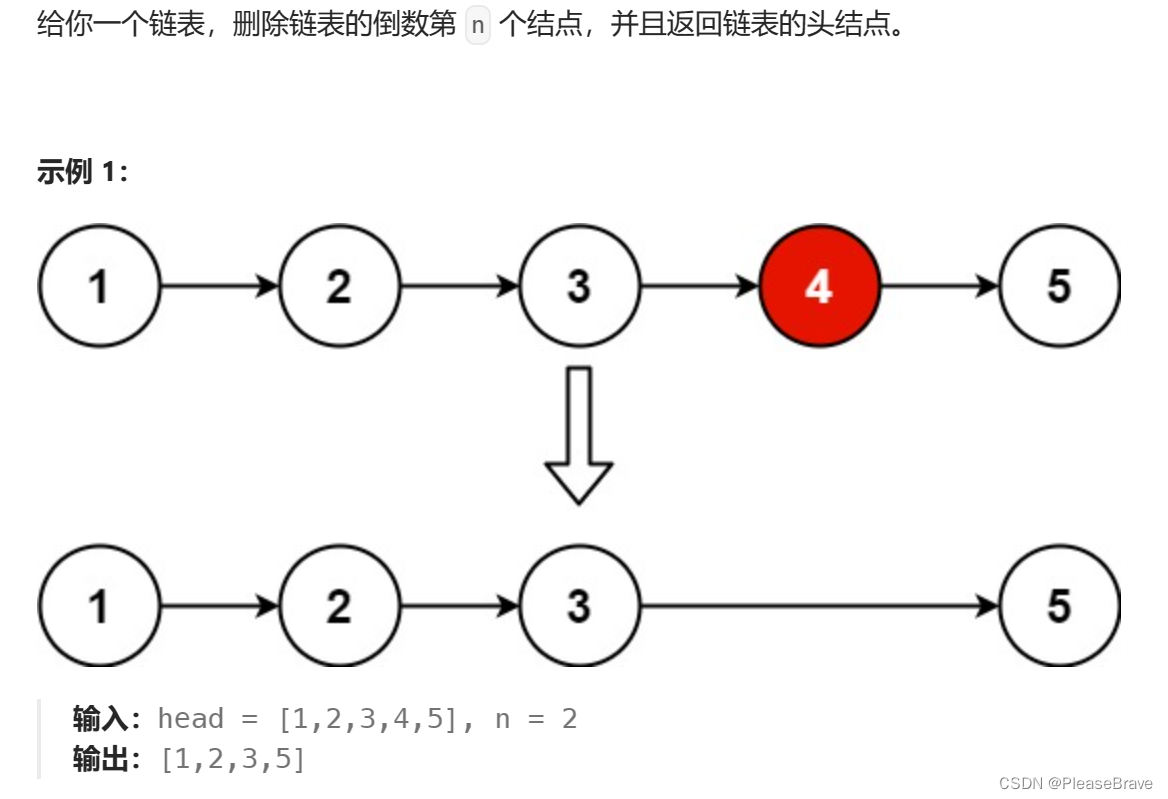
如果把链表换成数组等数据结构,可以直接根据下标,从数组末端开始,找到倒数第N个元素。但是!链表的缺点就在于,查找元素的时候需要O(N)的时间复杂度。由于其结点都是通过前驱结点的next指针连接的(单向链表中),因此只能一个方向遍历链表结点,不能直接从后往前找到倒数第N个。
遍历两次,先求得链表长度,再删除
从前往后如何找到倒数第N个结点呢?假设链表长度为Size,那么倒数第N个结点,实际上就是正数第Size+1-N个结点。【比如Size=5,N=2,倒数第2个结点是正数第4个结点,Size-1+N=4】。由此可以想到最直接的办法:遍历两次链表,第一遍求得Size,第二遍定位到要删除的结点,并删除。 实际上删除结点,需要将待删除结点的前驱结点和后驱结点连接起来,因此找到前驱结点就行。 从head开始,找到第Size-N个结点,即为待删除结点的前驱节点。
代码实现(C++):
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {int Size = 0;//构建一个虚拟头节点,不需要单独讨论删除头节点的情况ListNode *dummyhead = new ListNode(0, head);ListNode *currNode = dummyhead->next;//统计链表长度【除虚拟头节点外的结点数】while(currNode){Size++;currNode = currNode->next;}currNode = dummyhead;//定位到要删除结点的前驱结点 第Size-N个结点for(int i = 0; i < Size - n; i++){currNode = currNode->next;}//要删除的结点是currNode->nextListNode *tmp = currNode->next;//将待删除结点tmp的前驱结点和后驱结点连接起来currNode->next = tmp->next;delete tmp;return dummyhead->next;}
};
双指针,只遍历一次
解决这道题目的重点是,直到倒数第N个结点,实际上就是整数的第Size+1-N个结点。问题在于是否需要求得Size呢? 如果不求Size怎么能够找到第Size+1-N个结点呢?
使用双指针,一个slow,一个fast。先让fast向前定位到第n个结点;之后slow从第一个结点开始,fast从第n个结点开始,slow和fast都每次向前移动一个结点,直到fast->next == null【即移动到链表最后一个结点,相当于定位到了第Size个结点,fast从第n个结点走到第Size个结点,走了Size-n步;slow从第1个结点,就走到了Size-n+1个结点】,slow对应的结点就是要删除的结点。
在实际代码中,增加一个虚拟头结点,这样删除头结点的情况就不需要单独处理。slow从虚拟头结点开始,移动Size-n次,相当于移动到了被删除结点的前面一个结点【如果是一定要移动到被删除结点,那么终止条件改成fast==null即可,这样相当于fast从第n个结点移动到Size+1的位置,走了Size+1-n次,slow刚好走到Size+1-n结点的位置】。下图讨论了没有虚拟头节点和有虚拟头节点;slow最终指向待删除结点和待删除结点前面一个结点的情况:

以下代码(C++)实现的是上图的第二种情况,即有附加头节点,slow指向的待删除结点的前驱节点:
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {ListNode *dummyhead = new ListNode(0, head); //新建虚拟头节点ListNode *slow = dummyhead, *fast = dummyhead;//fast先指向第n个结点while(n){fast = fast->next;n--;}//fast指向最后一个结点结束while(fast->next){fast = fast->next;slow = slow->next;}//fast指针没用了,用来保存待删除的结点fast = slow->next;//建立新的连接slow->next = fast->next;delete fast; //删除结点return dummyhead->next;}
};
141. 环形链表
题目链接:环形链表
题目内容:
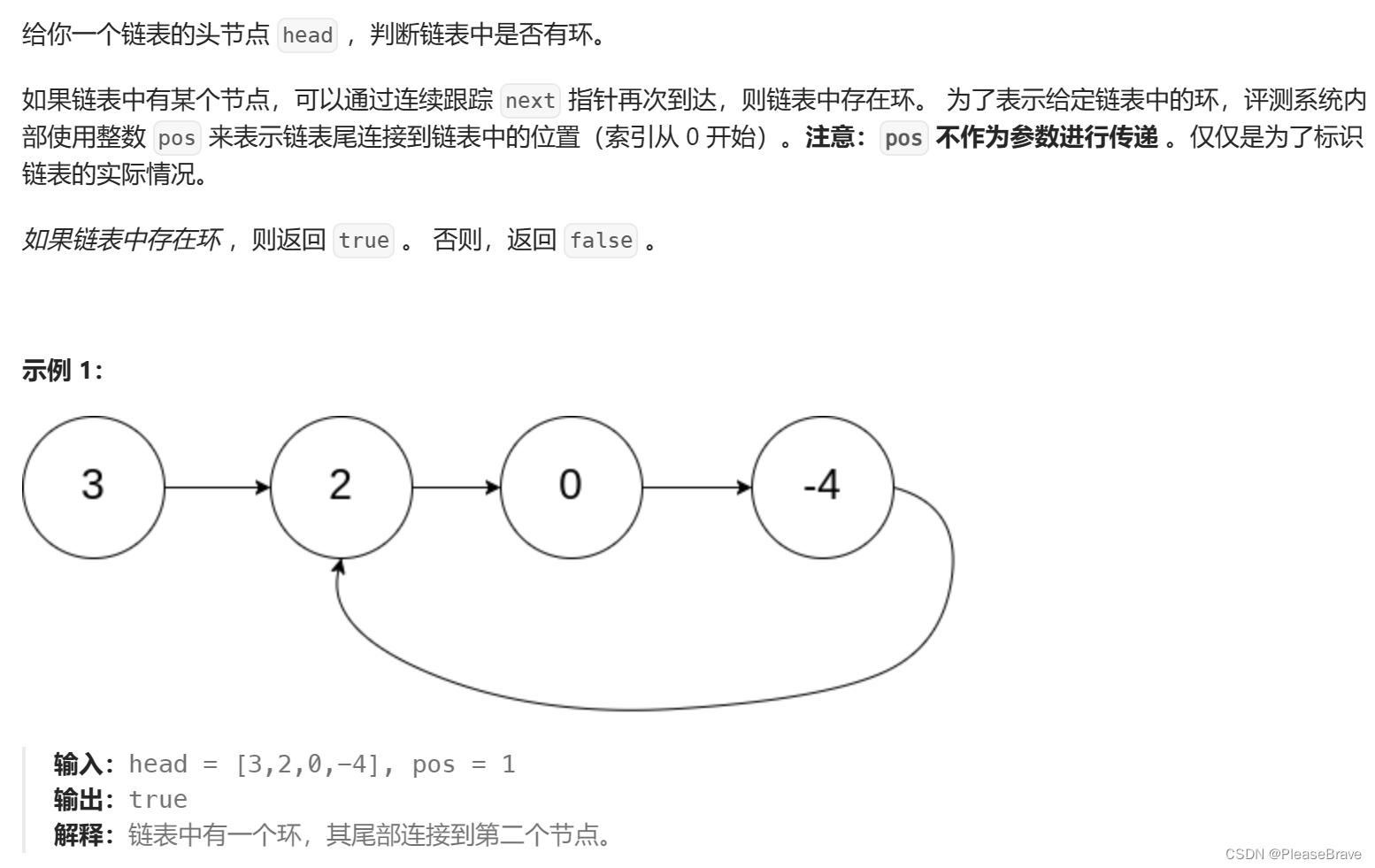
根据题意,实际上就是判断链表中是否存在环。
哈希表
遍历链表,并将各个结点地址存入一个unordered_set中,如果某个地址在set中出现过,即可认为有环。
class Solution {
public:bool hasCycle(ListNode *head) {if(head == nullptr || head->next == nullptr)return false;unordered_set <ListNode *> visited; //用来存访问过的结点地址ListNode *currNode = head; //从head结点开始遍历while(currNode){if(visited.count(currNode)) //如果当前结点地址已经访问过了,即有环return true; visited.insert(currNode); //否则添加到set中currNode = currNode->next;//结点后移}return false;}
};
快慢双指针
经典的Floyd判圈算法。一个slow指针,一个fast指针。slow从头节点开始每次向前移动一个结点,fast从头节点开始每次向前移动两个结点:
- 如果没有环,fast因为移动更快,而先遍历完链表;如果fast==null || fast->next == null即可认为没有环;
- 如果有环,那么fast只是比slow更先进入环内绕圈,待slow也进入环内,fast每次在圈内走两步,slow走一步,fast和slow之间的距离就减少一步,最后fast最追上slow,即出现fast == slow,即可判断有环。
代码如下(C++):
class Solution {
public:bool hasCycle(ListNode *head) {if(head == nullptr) return false; ListNode *slow = head, *fast = head;while(fast != nullptr && fast->next !=nullptr ){slow = slow->next;fast = fast->next->next; if(slow == fast) //fast追上了slow,有环return true;}//退出循环是因为fast先遍历完链表,无环return false;}
};142. 环形链表Ⅱ
题目链接:142. 环形链表Ⅱ
题目内容:

理解题意:实际上就是在判断链表是否有环的基础上,找出进入环的第一个结点:
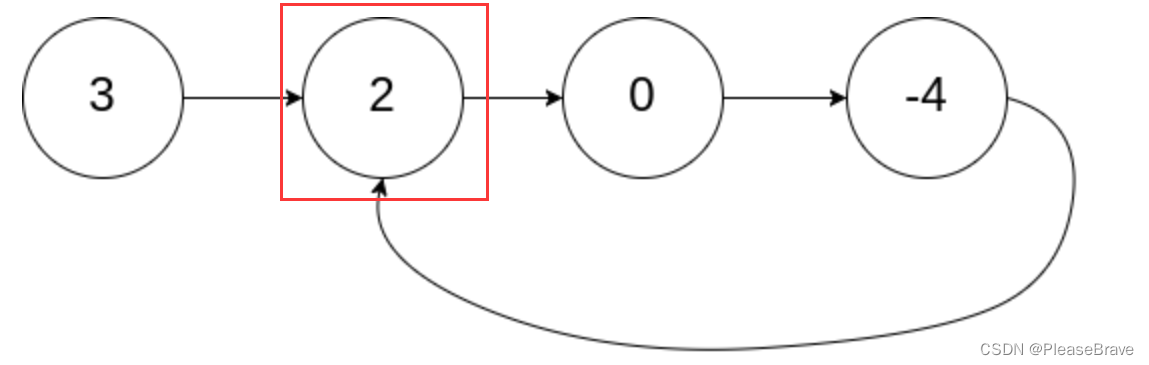
哈希表
同样使用哈希表,和141题的判断是否有环一样,用set存各个结点的地址,如果出现了重复的地址,且第一次重复的就是环的入口:
class Solution {
public:ListNode *detectCycle(ListNode *head) {if(head == nullptr || head->next == nullptr)return nullptr;unordered_set <ListNode *> visited;ListNode *currNode = head;while(currNode){if(visited.count(currNode))return currNode; //第一次重复的地址,就是环的入口visited.insert(currNode);currNode = currNode->next;}return nullptr;}
};
双指针
这里涉及到一些数学推理了……依旧是slow、fast两个指针,从头节点开始请看下图:

这里的x、y、z表示某一段链表中的节点数,都是左开右闭的,即起始结点不包括,终止结点包括【这个很重要的】。x:从头节点开始,到环的起始结点的结点数量;y:slow结点进入环以后,即从入环节点开始,移动y个节点,slow和fast相遇;z:从slow和fast相遇节点开始,slow(或fast)要移动z个节点,到达入环节点。
接下来分析x、y、z之间的数学关系,slow和fast相遇时:
- fast先进入环,开始绕圈【假设绕了n圈才和slow相遇,n≥1】,所以fast已经遍历的节点数:x+(y+z)*n+y;
- slow后进入环,入环后第一圈移动y个节点就和fast相遇了,slow遍历的节点数:x+y;【这里肯定是第一圈没走完就能和fast相遇的,因为slow入环的时候fast在环中一个位置,slow在入环节点处,假设fast距离入环节点m个节点的话,也就是和slow相差m个节点的距离,之后每一次移动,fast向slow靠近一个节点,那么移动m次就相遇,即题目中的y。m肯定是小于环的节点数的。】
因为fast每次向前移动两个,slow每次移动一个,所以:2*(x+y) = x+n*(y+z)+y;等式处理一下就得到了x = (n-1)*(y+z) +z,如果n=1,x=z,即index1指针从head开始,index2指针从slow与fast相遇的节点开始,两个分别向前移动,移动相同次数,index1和index2会相遇,相遇处即为入环处;如果n>1,就是index2在环内绕了(n-1)圈后和index1在入环处相遇。总之就是index1和index2会相遇,相遇处就是入环处。代码如下(C++):
class Solution {
public:ListNode *detectCycle(ListNode *head) {if(head == nullptr || head->next == nullptr)return nullptr;ListNode *slow = head, *fast = head;//fast和slow都从头节点开始do{if(fast && fast->next){slow = slow->next;fast = fast->next->next;}elsereturn nullptr; //如果fast先遍历完链表,即没有环}while(slow != fast); //跳出循环即为有环slow = head; //slow从head开始,fast从相遇点开始//二者每次向前移动一个节点,相遇处即为入环处while(slow != fast){slow = slow->next;fast = fast->next;}return slow; }
};
面试题02.07. 链表相交
题目链接:面试题02.07. 链表相交
题目内容:
理解题意:判断两个链表有没有相交的部分。
哈希表
如果两个链表相交,那么从相交节点开始,之后的节点都是公共的,是相同的地址。所以还是可以用哈希表解决,先遍历其中一个链表,然后将其每个节点的地址存入set中;之后遍历第二个链表,并判断每个节点地址是否在set中,如果在,那么直接返回,这个地址就是相交起始节点。如果遍历完第二个链表都没有公共的节点地址,那么就是不相交的。代码如下(C++):
class Solution {
public:ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {unordered_set <ListNode *> visited;ListNode *currNode = headA;while(currNode){ //遍历第一个链表并将各个节点的地址存在set中visited.insert(currNode);currNode = currNode->next;} currNode = headB;while(currNode){//遍历第二个链表并判断每个节点地址是否出现在set中if(visited.count(currNode))return currNode; //找到相交起始点currNode = currNode->next;}return nullptr;}
};
双指针
按道理,遍历两个链表的同时,对比是否有相同的节点地址,就能直到是否有交叉部分。但是问题在意,两个链表长度不一样,如果都从头开始遍历的话,即便两个链表是相交的,但是由于对比的节点没有对齐,而结果不正确。 所以解决办法是怎么把两个链表对齐。
思路Ⅰ
两个链表相交,从相交点开始到末尾节点的,都是重合的。在相交节点之前,链表A有几个节点、链表B有几个节点都不重要,也不确定。所以就是把两个链表按尾节点对齐。先遍历链表A和B统计两个链表的节点数【假设为Size_A和Size_B】,节点数大的链表先移动max(Siez_A,Size_B) - min(Size_A,Size_B)个节点,与节点数小的链表的头节点对齐【也相当于是为按尾节点对齐】,之后逐个对比两个链表的结点的地址。

代码如下(C++):
class Solution {
public:ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {//统计两个链表中的节点数int len_A = 0, len_B = 0;ListNode *currNodeA = headA, *currNodeB = headB;while(currNodeA){ //统计链表Alen_A++;currNodeA = currNodeA->next;}while(currNodeB){//统计链表Blen_B++;currNodeB = currNodeB->next;}//从新从头开始遍历两个链表currNodeA = headA;currNodeB = headB;while(len_A > len_B){ //如果Len_A更大进入这个循环currNodeA = currNodeA->next;len_A--;}while(len_B > len_A){//如果len_B更大进入这个循环currNodeB = currNodeB->next;len_B--;}//两个链表已经对齐了,开始逐个结点对比while(currNodeA && currNodeB){if(currNodeA == currNodeB)return currNodeA;currNodeA = currNodeA->next;currNodeB = currNodeB->next;}return nullptr;}
};
思路Ⅱ
虽然两个链表长度不一样,不能对齐,那么把链表A和链表B拼起来呢?即一个指针currNodeA先遍历链表A,遍历完链表A后从头开始遍历链表B;另一个指针currNodeB先遍历链表B,遍历完链表B后从头开始遍历链表A。 那么currNodeA和currNodeB都遍历两个链表,如果链表A和链表B有相交部分,currNodeA和currNodeB就会相等且不为null;如果没有相交的部分,currNodeA和currNodeB最后就遍历完链表,均为null。
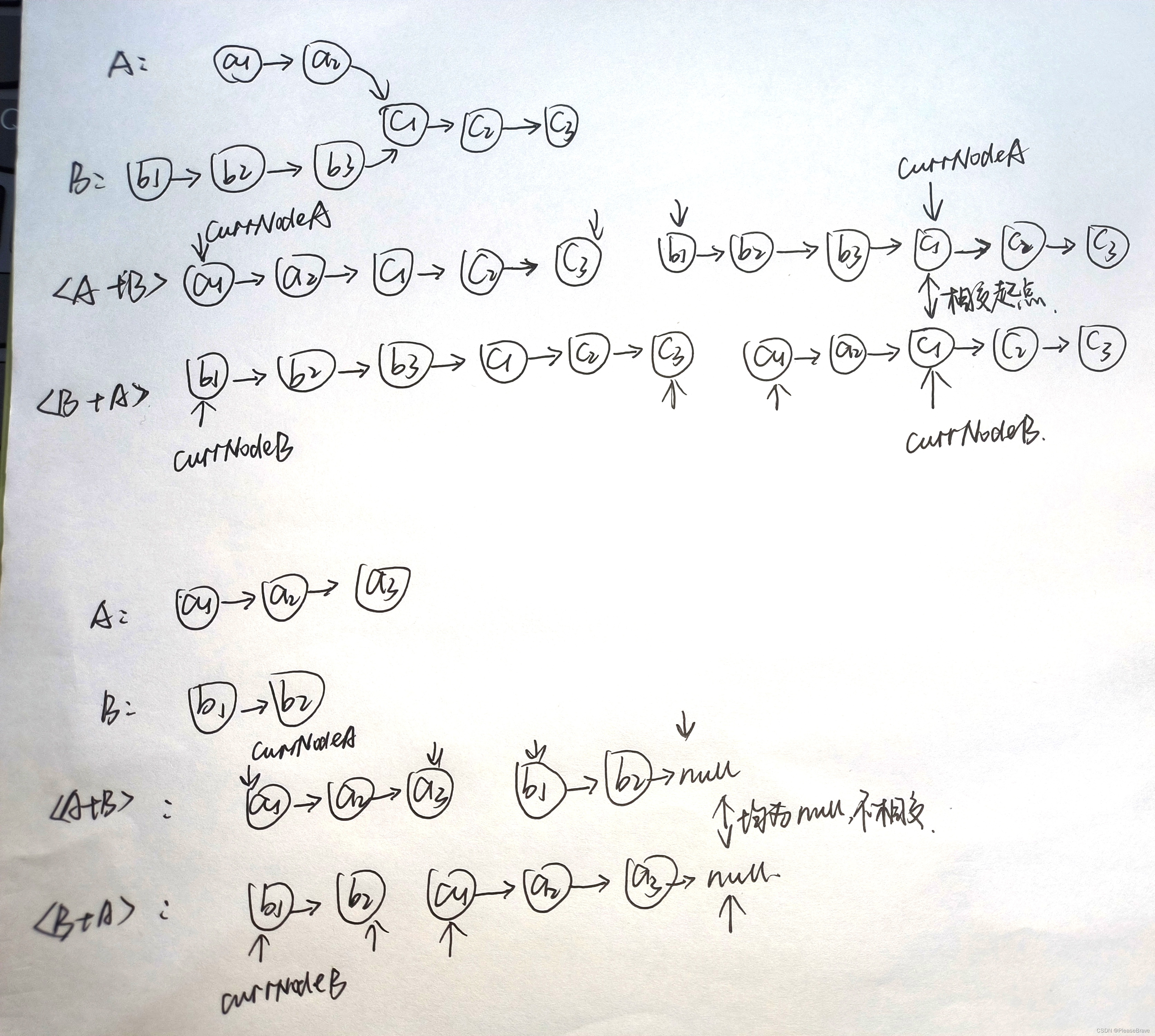
代码实现如下(C++):
class Solution {
public:ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {ListNode *currNodeA = headA, *currNodeB = headB;while(currNodeA != currNodeB){if(currNodeA)currNodeA = currNodeA->next;else currNodeA = headB;if(currNodeB)currNodeB = currNodeB->next;elsecurrNodeB = headA;}return currNodeA;}
};
![Java IO流(五)Netty实战[TCP|Http|心跳检测|Websocket]](https://img-blog.csdnimg.cn/3785951d86a845319206115b3fecc033.png)



