Stable Diffusion主要用于从文本生成图像,是人工智能技术在内容创作行业中不断发展的应用。要在本地计算机上运行Stable Diffusion,您需要一个强大的 GPU 来满足其繁重的要求。强大的 GPU 可以让您更快地生成图像,而具有大量 VRAM 的更强大的 GPU 可以让您更快地创建更高分辨率的图像。那么,最适合Stable Diffusion的消费类 GPU 是什么?让我们看看NVIDIA和AMD的部分GPU上的Stable Diffusion性能来寻找答案。
关于Stable Diffusion
什么是Stable Diffusion?
Stable Diffusion是一种机器学习模型。由于它能够根据文本提示生成图像,因此它越来越多地用于内容创建。Stable Diffusion 的独特之处在于它缺乏商业开发的软件,而是依赖于各种开源应用程序。此外,与其他类似的文本到图像模型不同,它通常在本地系统上本地使用,而不是使用在线 Web 服务。
Stable Diffusion 可以在具有至少 8GB VRAM 的中档 GPU 上运行。然而,它极大地受益于具有更多 VRAM 的强大现代 GPU。
Stable Diffusion的组成框架
您可以直接使用Stability AI和Runway开发的Stable Diffusion版本。然而,大多数人使用第三方创建的基于网络的版本。最常用的Stable Diffusion是:
- Automatic 1111:这主要用于 NVIDIA GPU,尽管 AMD 和 Apple Silicon 也有分支。它允许您使用xformers,它可以显着提高 NVIDIA GPU 的性能。
- SHARK:SHARK 是Automatic 1111 的替代方案。它本身支持 NVIDIA 和 AMD GPU。然而,AMD GPU 的性能往往较高,而 NVIDIA GPU 的性能往往较低。
- 自定义:有些人使用他们需要的功能创建自己的应用程序,因为Stable Diffusion是公开的,任何人都可以直接使用。
每个实现在功能和可用性方面都有独特的优点和缺点。从性能和基准测试的角度来看,推荐使用Automatic 1111和SHARK。根据您要测试的GPU,建议同时使用Automatic 1111和SHARK。使用 Automatic 1111 测试 NVIDIA GPU,使用 SHARK 测试 AMD GPU。
注意:Stable Diffusion 会不断更新,因此您使用的不同版本可能会导致性能变化。
什么影响Stable Diffusion的性能?
首先,Stable Diffusion设置和模型
最常调整的设置(例如提示、否定提示、cfg 比例和种子)不会对性能产生显着影响。生成狗或山地景观的图像需要相同的时间。即使选择的模型也往往只会导致生成时间的微小差异。看下面的图像,尽管有不同的提示和 cfg 比例,但它们的生成时间几乎完全相同。

其他设置(例如步长、分辨率和采样方法)将影响Stable Diffusion的性能。
- 步骤:调整步骤会影响生成图像所需的时间,但不会改变每秒迭代的处理速度。尽管许多用户选择 20 到 50 步,但将步数增加到 200 左右往往会在每次运行中产生更一致的结果。
- 分辨率:图像分辨率不仅对性能影响最大,还会影响生成图像所需的 VRAM 量。出于基准测试目的,您可以使用 512×512 分辨率来确保与各种 GPU 型号的兼容性。
- 采样方法(Euler、DPM等)。它会显着影响生成时间,某些选项所需的时间大约是其他选项的两倍。“Euler”和“Euler a”使用最广泛,并且往往提供最佳性能。其他方法(例如 DPM2)往往需要大约两倍的时间。出于 GPU 基准测试的目的,建议坚持使用 Euler 的变体以保持一致性。
其次是硬件
- GPU :GPU 对速度和图像质量影响最大。更强大的 GPU 具有更高的内存带宽和更多的 VRAM,可以更快地生成稳定的扩散图像,尤其是在更高分辨率的情况下。GPU 上的 VRAM 数量决定了可以生成的最高分辨率图像。建议至少 8GB,更高分辨率需要 12GB 或更多。
- CPU :虽然 GPU 处理大部分繁重的工作,但快速的 CPU 仍可以在较小程度上提高性能。具有更高时钟速度和更多内核的 CPU 可以提供较小的提升。
- RAM :系统内存有助于向 GPU 提供数据,因此至少拥有 16GB RAM 可以确保最佳性能。更多 RAM(高达 32GB 或 64GB)可以进一步提高速度。
实现Stable Diffusion的最佳 GPU
要了解最适合Stable Diffusion的消费类 GPU,我们将检查这些 GPU 在其两个最流行的实现(其最新公开版本)上的Stable Diffusion性能。
许多Stable Diffusion实现通过计算“每秒迭代次数”或“ it/s ”来显示它们的工作速度。因此,为了检查Stable Diffusion性能,该指标是常用且很好的衡量标准。每秒迭代次数是通过将迭代次数除以生成图像所需的秒数来计算的。例如,如果生成具有 200 次迭代的图像需要 15 秒,则每秒的迭代次数约为13.3(即 200 次迭代除以 15 秒)。
首先,让我们看一下 Puget Systems 在 4000 系列 GPU 以及最近三代 NVIDIA 和 AMD RX 7900 XTX 和 RX 6900 XT的顶级 GPU 上测试的基准测试结果。
Automatic 1111性能
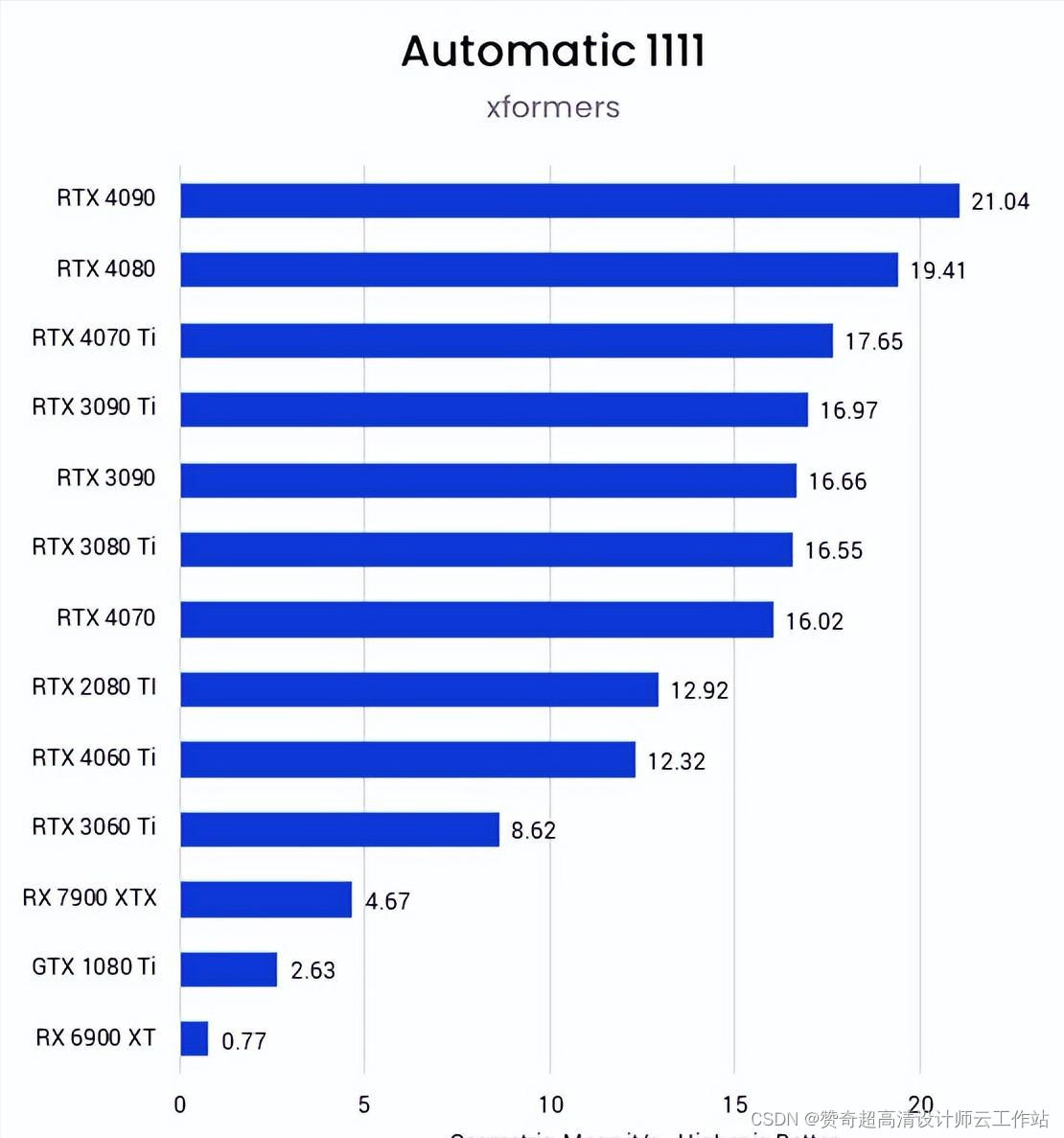
Automatic 1111是Stable Diffusion最常用的表现形式,通常可以在 NVIDIA GPU 上提供最佳性能。
NVIDIA 在这方面的表现明显优于 AMD。在 NVIDIA 的 GPU 列表中,RTX 4090 是获胜者,在Automatic 1111上提供了最高的性能结果。 甚至 RTX 3060 Ti 的速度也是 Radeon GPU 的两倍。只有 GTX 1080 Ti 比 RX 7900 XTX 差。
较新的 4000 系列 GPU 在图像生成速度方面具有明显的优势,同时性能与价格呈线性增长。RTX 4070 Ti 比之前的 RTX 3090 Ti 快约 5%,RTX 4060 Ti 比 3060 Ti 快近 43%,这表明了这一点。如果您仍然拥有 2000 或 1000 系列 GPU,即使是中档 4000 系列 GPU 也能提供显着的性能提升。
Shark性能测试

尽管 SHARK 不如Automatic 1111 常用,但许多 AMD 用户更喜欢它。看看上面的基准测试结果,原因就很清楚了。
RX 7900 XTX 的性能在 SHARK 的帮助下翻了四倍,每秒的迭代次数与运行 1111 的 RTX 4090 类似。同样,RX 6900 XT 的性能提升幅度甚至更大,达到了 1100%,但这仅使其与低端产品具有竞争力。已测试 NVIDIA GPU。
使用 SHARK 时,NVIDIA GPU 的性能比自动1111差约 30% ,尽管相对性能保持相同。
重要提示:正确使用Stable Diffusion非常重要,因为它会极大地影响性能。它可以从减少 30% 到大幅增加 1100%!上述GTX 1080 Ti的结果证明了这一点。在 Puget Systems 的本次测试中,它无法运行 SHARK。
总结
最突出的是各种Stable Diffusion实现之间性能的巨大差异。NVIDIA GPU 在Automatic 1111上提供最高性能,而 AMD GPU 在 SHARK 上工作效果最佳。顶级 GPU 各自的实现具有相似的性能。
如果您尚未决定使用特定的实现,NVIDIA 和 AMD 的高端 GPU 都提供了出色的性能。GeForce RTX 4090 和Radeon RX 7900 XTX 在Stable Diffusion的首选实现中均提供约 21 it/s 的速度。
值得注意的是,Stable Diffusion是一个不断发展的模型,具有一组工具。今天的运作方式与几个月前或未来的运作方式截然不同。 它的性能将在未来几个月和几年内发生变化。因此,本文中的性能结果可能会随着时间的推移而发生变化。作为明智的读者,我们希望您理解这些基准测试结果仅供参考。
如果您有兴趣在 RTX 4090 等顶级 GPU 上测试当前使用的Stable Diffusion实现的性能,请查看我们下面的服务。
赞奇云工作站- Stable Diffusion的云服务平台
Stable Diffusion 主要是为单 GPU 使用而设计的;然而,通过一些额外的软件和配置,它可以利用多个 GPU。通过将工作分散到多个 GPU 上,可以提高整体迭代速度。虽然大多数Stable Diffusion实现默认设计为在单个 GPU 上运行,但一种常用的实现(Automatic1111)可以选择以最少的附加配置启用多 GPU 支持。
运行Stable Diffusion算力越强,出图越快。显存越大,所设置图片的分辨率越高,所以一般的配置电脑还是带不动stable diffusion的,所以还是推荐选择赞奇云工作站,相比传统电脑无需一次性投入大量金钱,还可以随开随用,按需使用,高效助力设计。
上赞奇云工作站不需要复杂的安装和部署,就能随时随地享受到行业领先配置的机器,高画质稳定输出作品,减少本地配置时间和成本投入,完全不同担心电脑卡顿、运行不动等问题。