前言:
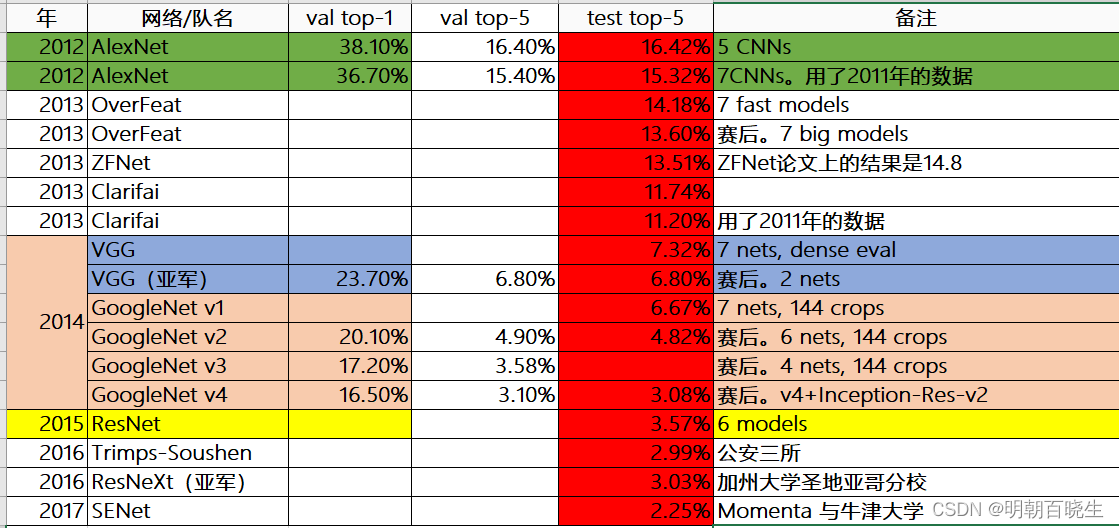
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)是近年来机器视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。
ImageNet数据集是ILSVRC竞赛使用的是数据集,由斯坦福大学李飞飞教授主导,包含了超过1400万张全尺寸的有标记图片。ILSVRC比赛会每年从ImageNet数据集中抽出部分样本,以2012年为例,比赛的训练集包含1281167张图片,验证集包含50000张图片,测试集为100000张图片。
ImageNet的分类发展历史
我们通过test top-5 可以看到错误率在逐步的降低。
AlexNet- VGG- GoogleNet-ResNet
目录:
1 LeNet-5
2 AlexNet
一 LeNet-5
1.1 简介

LeNet-5是一个经典的深度卷积神经网络,由Yann LeCun在1998年提出,旨在解决手写数字识别问题,被认为是卷积神经网络的开创性工作之一。该网络是第一个被广泛应用于数字图像识别的神经网络之一,也是深度学习领域的里程碑之一。本文首先介绍了卷积神经网络的基本原理,然后介绍了LeNet-5的基本结构和训练过程,并给出了LeNet-5的pytorch代码实现,最后说明了LeNet-5对深度学习的贡献。
Yoshua Bengio, Yann Lecun, Geoffrey Hinton
1.2 应用:
该网络在手写数字识别上精度可以达到99.2%,在邮政编码识别
以及支票识别上面,占据了美国50%以上的市场份额。
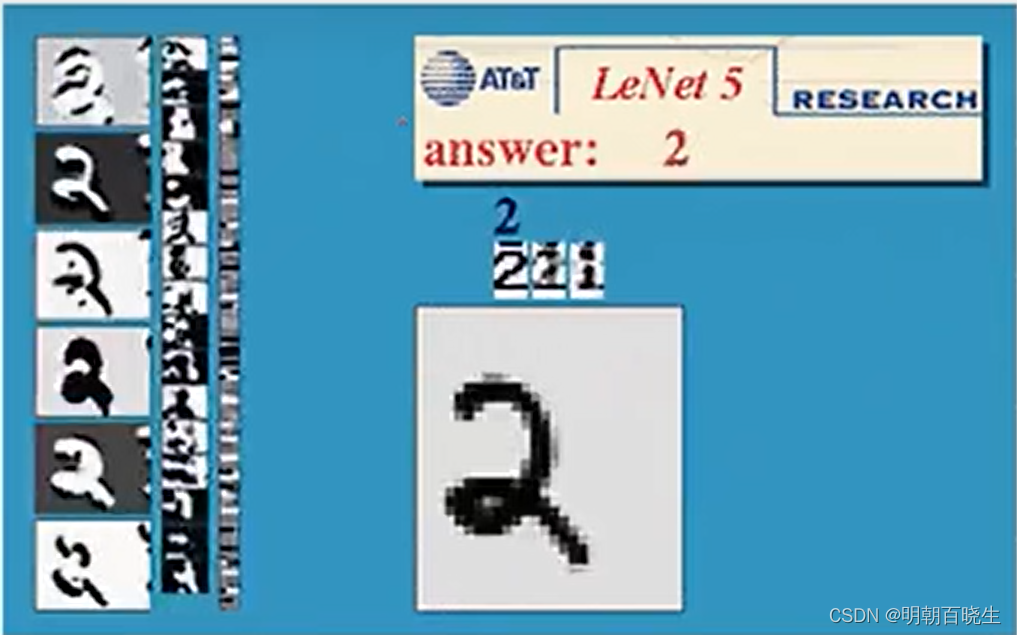
1.3 网络结构
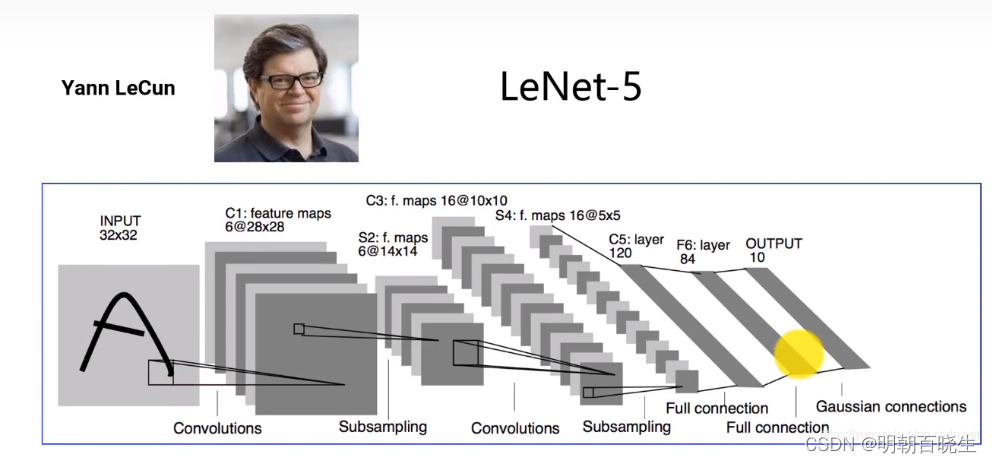
LeNet-5的基本结构包括7层网络结构(不含输入层),其中包括2个卷积层、2个降采样层(池化层)、2个全连接层和输出层。
| 层 | 参数 |
| L1-输入层 | 输入层接收大小为 32×32 的手写数字图像,其中包括灰度值(0-255) |
| L2-卷积层C1 | 卷积层C1包括6个卷积核,每个卷积核的大小为 5×5 ,步长为1,填充为0。 因此,每个卷积核会产生一个大小为 28×28 的特征图(输出通道数为6 |
| L3-采样层S2 | 采样层S2采用最大池化(max-pooling)操作,每个窗口的大小为 2×2 ,步长为2。因此,每个池化操作会从4个相邻的特征图中选择最大值,产生一个大小为 14×14 的特征图(输出通道数为6)。这样可以减少特征图的大小,提高计算效率,并且对于轻微的位置变化可以保持一定的不变性。 |
| L4-卷积层C3 | 卷积层C3包括16个卷积核,每个卷积核的大小为 5×5 ,步长为1,填充为0。因此,每个卷积核会产生一个大小为 10×10 的特征图(输出通道数为16)。 |
| L5-采样层S4 | 采样层S4采用最大池化操作,每个窗口的大小为 2×2 ,步长为2。因此,每个池化操作会从4个相邻的特征图中选择最大值,产生一个大小为 5×5 的特征图(输出通道数为16) |
| L6-全连接层C5 | C5将每个大小为 5×5 的特征图拉成一个长度为400的向量,并通过一个带有120个神经元的全连接层进行连接。120是由LeNet-5的设计者根据实验得到的最佳值。 |
| L7-全连接层F6 | 全连接层F6将120个神经元连接到84个神经元。 |
| L8-输出层 | 输出层由10个神经元组成,每个神经元对应0-9中的一个数字,并输出最终的分类结果。在训练过程中,使用交叉熵损失函数计算输出层的误差,并通过反向传播算法更新卷积核和全连接层的权重参数。 |
# -*- coding: utf-8 -*-
"""
Created on Thu May 25 16:15:33 2023@author: chengxf2
"""import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
from torchvision import transforms
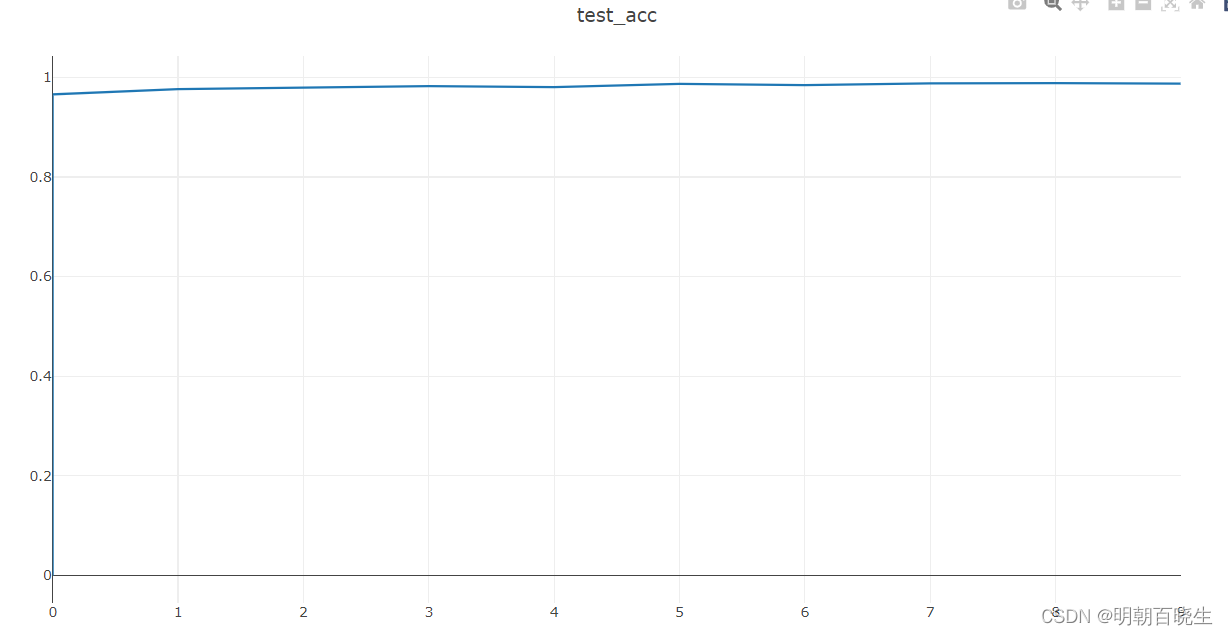
from visdom import Visdomclass LeNet5(nn.Module):def __init__(self):super(LeNet5,self).__init__()#灰度图,只有一个通道self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5,stride=1) self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)#feature map [16,6,5,5]self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)#全连接层self.fc1 = nn.Linear(in_features=16 * 4 * 4, out_features=120)self.fc2 = nn.Linear(in_features=120, out_features=84)self.fc3 = nn.Linear(in_features=84, out_features=10)def forward(self, x):conv_1 = self.conv1(x)pool_1 = self.pool1(torch.relu(conv_1))conv_2 = self.conv2(pool_1)pool_2 = self.pool2(torch.relu(conv_2))x = pool_2.view(-1, 16 * 4 * 4)x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)return xdef run():# 加载MNIST数据集train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())# 定义数据加载器train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)# 定义模型、损失函数和优化器model = LeNet5()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters())vis = Visdom()vis.line([0],[0],win ='test_acc',opts = dict(title='test_acc'))# 训练模型for epoch in range(10):for i, (images, labels) in enumerate(train_loader):optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()if (i+1) % 200 == 0:print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, 10, i+1, len(train_loader), loss.item()))# 测试模型model.eval()#表明当前计算不需要反向传播,使用之后,强制后边的内容不进行计算图的构建with torch.no_grad():correct = 0total = 0for images, labels in test_loader:outputs = model(images) #[64, 10]#该函数返回由最大值以及最大值处的索引组成元组(max,max_indices)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()acc = correct / totalvis.line([acc],[epoch+1], win='test_acc',update='append')print('Test Accuracy: [{}/{}]={:.2f}%'.format(correct,total,100 * correct / total))if __name__ == "__main__":run()
假如输入图像大小为m*n,过滤器(filter)为f*f,padding为p,步长(stride)为s,则输出大小为:如果商不是整数,向下取整,即floor函数。参考:
二 AlexNet
2.1 简介
AlexNet经典网络由Alex Krizhevsky、Hinton等人在2012年提出,发表在NIPS,论文名为《ImageNet Classification with Deep Convolutional Neural Networks》
2.2 创新点
2012年前图像处理主流是SVM,AlexNet 创新点如下
| 创新点 |
| 1 激活函数使用ReLU替代Tanh或Sigmoid加快训练速度,解决网络较深时梯度弥散问题 |
| 2 .训练时使用Dropout随机忽略一部分神经元,以避免过拟合 |
| 3使用重叠最大池化(Overlapping Max Pooling),避免平均池化时的模糊化效果;并且让步长比池化核的尺寸小,提升特征丰富性。filter的步长stride小于filter的width或height。一般,kernel(filter)的宽和高是相同的,深度(depth)是和通道数相同的 |
| 4使用LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其它反馈较小的神经元,增强了模型泛化能力。LRN只对数据相邻区域做归一化处理,不改变数据的大小和维度 |
| 5 .数据扩充(Data Augmentation):训练时随机地从256*256的原始数据中截取227*227大小的区域,水平翻转;光照变换。增加了数据量,大大减少过拟合,提升泛化能力。 |
| 6多GPU并行运算。 第一次使用了两张GTX580,把卷积核放在两张gpu上 AlexNet输入是一种属于1000种不同类别的一张BGR图像,大小为227*227,输出是一个向量,大小为1000。输出向量的第i个元素值被解释为输入图像属于第i类的概率。因此,输出向量的所有元素的总和为1。 |
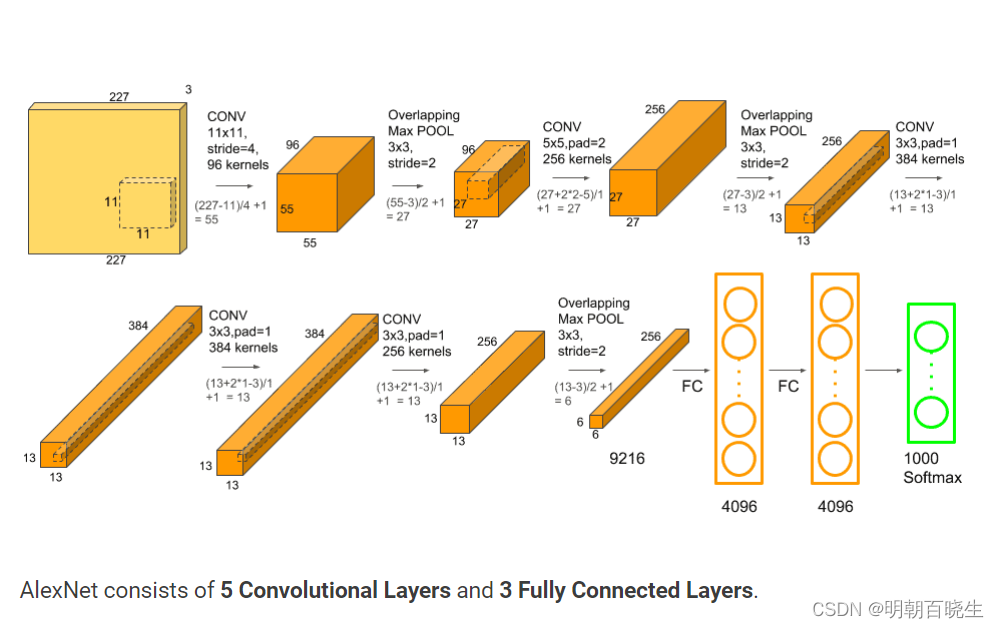
2.3 网络结构
AlexNet架构:5个卷积层(Convolution、ReLU、LRN、Pooling)+3个全连接层(InnerProduct、ReLU、Dropout),predict时对各层进行说明
| 层 | 介绍 | 训练参数 |
| 输入层 | 图像大小227*227*3。 | |
| convolution_1+ReLU+LRN | 使用96个11*11的filter,stride为4,padding为0,输出为55*55*96,96个feature maps | (11*11*3*96)+96=34944 |
| 最大池化层_1 | filter为3*3,stride为2,padding为0,输出为27*27*96,96个feature maps。 | |
| convolution_2+ReLU+LRN | 使用256个5*5的filter,stride为1,padding为2,输出为27*27*256,256个feature maps | (5*5*96*256)+256=614656。 |
| 最大池化层_2 | filter为3*3,stride为2,padding为0,输出为13*13*256,256个feature maps。 | |
| convolution_3+ReLU | 使用384个3*3的filter,stride为1,padding为1,输出为13*13*384,384个feature maps | (3*3*256*384)+384=88512 |
| convolution_4+ReLU | 使用384个3*3的filter,stride为1,padding为1,输出为13*13*384,384个feature maps | (3*3*384*384)+384=1327488 |
| convolution_5+ReLU | 使用256个3*3的filter,stride为1,padding为1,输出为13*13*256,256个feature maps | (3*3*384*256)+256=884992 |
| 最大池化层_3 | filter为3*3,stride为2,padding为0,输出为6*6*256,256个feature maps。 | |
| 全连接层1+ReLU+Dropout | 有4096个神经元 | (6*6*256)*4096=37748736 |
| 全连接层2+ReLU+Dropout | 有4096个神经元 | 4096*4096=16777216 |
| 全连接层3 | 有1000个神经元 | 4096*1000=4096000 |
| 输出层(Softmax) | 输出识别结果 1000个分类可能 |
参考:
经典网络AlexNet介绍_fengbingchun的博客-CSDN博客
https://www.cnblogs.com/TimVerion/p/11378949.html
卷积神经网络经典回顾之LeNet-5 - 知乎
课时69 经典卷积网络 LeNet5,AlexNet, VGG, GoogLeNet-1_哔哩哔哩_bilibili