目录
- 2.1 安装部署
- 1、【单机部署】
- 2、【集群部署】
- 2.2 Kafka命令行操作
- 1、查看topic相关命令参数
- 2、查看当前kafka服务器中的所有Topic
- 3、创建 first topic
- 4、查看 first 主题的详情
- 5、修改分区数(注意:分区数只能增加,不能减少)
- 6、删除 topic
- 7、生产者发送消息
- 8、消费者消费消息
2.1 安装部署
1、【单机部署】
1、下载并上传到nginx服务器
官网:http://kafka.apache.org/downloads.html
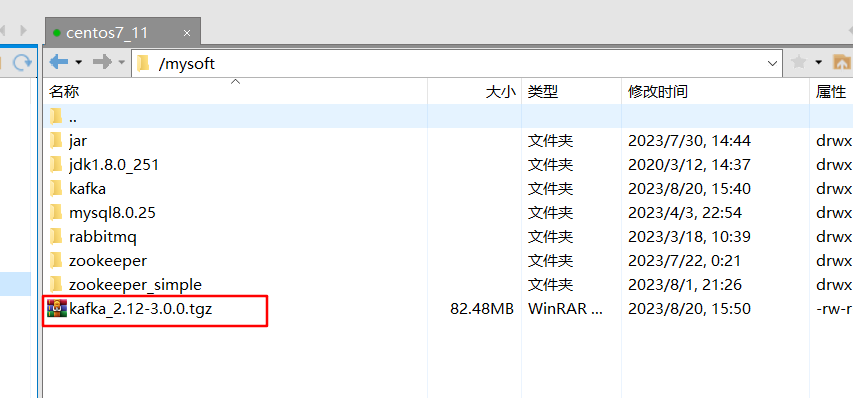
2、解压安装包
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
3、修改解压后的文件名称
mv kafka_2.12-3.0.0/ kafka
4、进入到/mysoft/kafka/config 目录,修改配置文件
vim server.properties
本地做的修改主要是:
broker.id=1
delete.topic.enable=true
log.dirs=/soft/kafka/logs
zookeeper.connect=192.168.239.11:2181/kafka
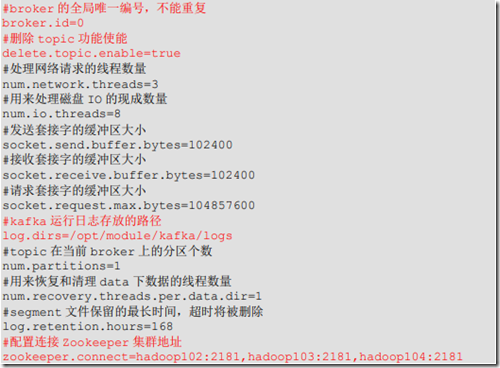
配置文件各个配置意义:
5、启动单节点
先启动zookeeper 节点

启动kafka
./kafka-server-start.sh -daemon ../config/server.properties
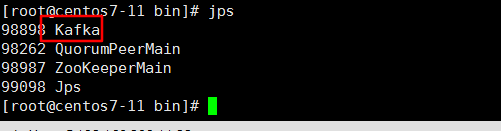
6、查看kafka有没有正常启动: jps
7、配置kafka的环境变量
1)在/etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
sudo vim /etc/profile.d/my_env.sh
增加如下内容
#KAFKA_HOME
export KAFKA_HOME=/mysoft/kafka
export PATH=$PATH:$KAFKA_HOME/bin
2)刷新一下环境变量。
source /etc/profile
2、【集群部署】
2.2 Kafka命令行操作
1、查看topic相关命令参数
bin/kafka-topics.sh
2、查看当前kafka服务器中的所有Topic
bin/kafka-topics.sh --bootstrap-server 192.168.239.11:9092 --list

3、创建 first topic
bin/kafka-topics.sh --bootstrap-server 192.168.239.11:9092 --create --partitions 1 --replication-factor 1 --topic first

4、查看 first 主题的详情
bin/kafka-topics.sh --bootstrap-server 192.168.239.11:9092 --describe --topic first
5、修改分区数(注意:分区数只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server 192.168.239.11:9092 --alter --topic first --partitions 3
6、删除 topic
bin/kafka-topics.sh --bootstrap-server 192.168.239.11:9092 --delete --topic first
7、生产者发送消息
bin/kafka-console-producer.sh --bootstrap-server 192.168.239.11:9092 --topic first
8、消费者消费消息
消费 first 主题中的数据
bin/kafka-console-consumer.sh --bootstrap-server 192.168.239.11:9092 --topic first
把主题中所有的数据都读取出来(包括历史数据)。
bin/kafka-console-consumer.sh --bootstrap-server 192.168.239.11:9092 --topic first --from-beginning