任何事情都是由量变到质变的过程,学习Python也不例外。只有把一个语言中的常用函数了如指掌了,才能在处理问题的过程中得心应手,快速地找到最优方案。本文和你一起来探索Python中的toad.quality函数,让你以最短的时间明白这个函数的原理。也可以利用碎片化的时间巩固这个函数,让你在处理工作过程中更高效。
文章目录
- 一、安装toad包
- 二、quality函数定义
- 三、quality函数实例
- 1 导入库并加载数据
- 2 实例
- 例1:默认参数调用quality函数
- 例2:iv_only参数设置为True
- 四、对比十等分计算iv值
一、安装toad包
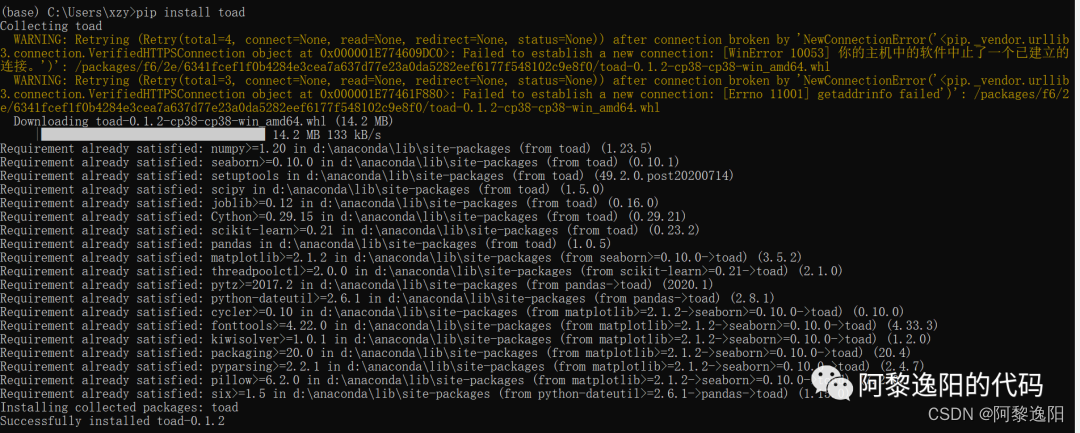
quality是toad库下的函数,调用需先要安装toad包。打开cmd,安装语句如下:
pip install toad
若安装成功,会显示结果如下:
二、quality函数定义
quality函数的功能是计算数据框中变量的iv、gini、entropy、unique四个指标。其中iv的定义可参考风控建模中的IV和WOE一文,gini和entropy的定义可自行百度。这三个指标的作用都是衡量变量对某个事件发生的区分能力。unique计算变量的取值个数。
其基本调用语法如下:
import toadtoad.quality(dataframe, target='target', cpu_cores=0, iv_only=False)
dataframe:数据集。
target:目标列或因变量列。
cpu_cores:将使用的最大 CPU 内核数,“0”表示将使用所有 CPU,“-1”表示将使用除一个之外的所有 CPU。
iv_only:布尔值,是否只展示iv列,默认是false。
三、quality函数实例
1 导入库并加载数据
背景:现需分析7252个客户的多头、关联风险、法院执行、风险名单和逾期信息,用于构建客户的贷前评分卡A卡。在进行评分卡搭建之前需要对客户的信息进行筛选,挑选出和客户逾期信息相关性高的变量。
首先读取数据,具体代码如下:
#[1]读取数据
import os
import toad
import numpy as np
import pandas as pdos.chdir(r'F:\公众号\70.数据分析报告')
date = pd.read_csv('testtdmodel1.csv', encoding='gbk')
date.head(3)
os.chdir:设置数据存放的文件路径。
pd.read_csv:读取数据。
得到结果:
2 实例
例1:默认参数调用quality函数
我们先来看下只输入数据框和因变量,其余参数采用默认值,会是什么效果,代码如下:
to_drop = ['input_time', '申请状态', '历史最高逾期天数.x'] # 去掉ID列和month列
quality_result = toad.quality(date.drop(to_drop,axis=1),'y')
quality_result
得到结果:
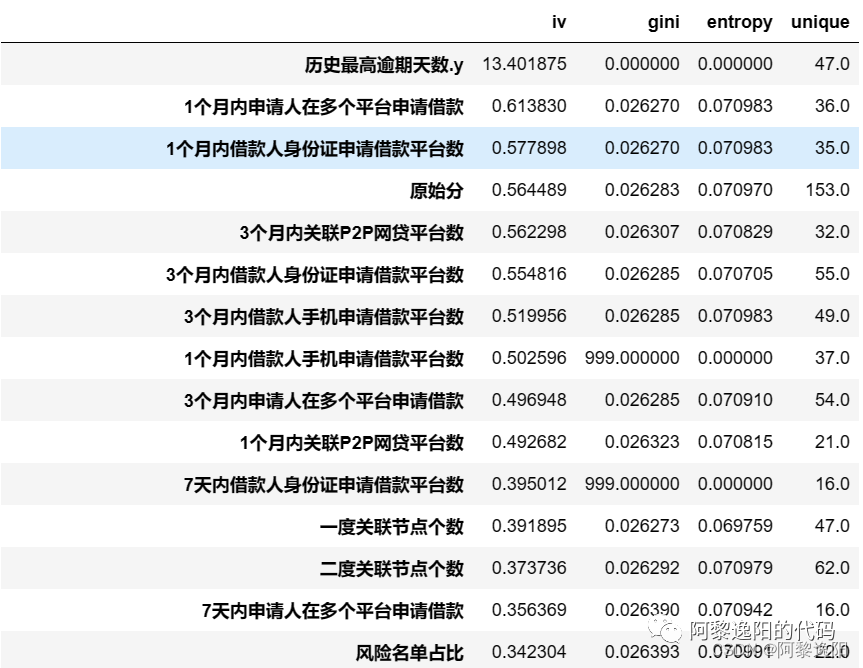
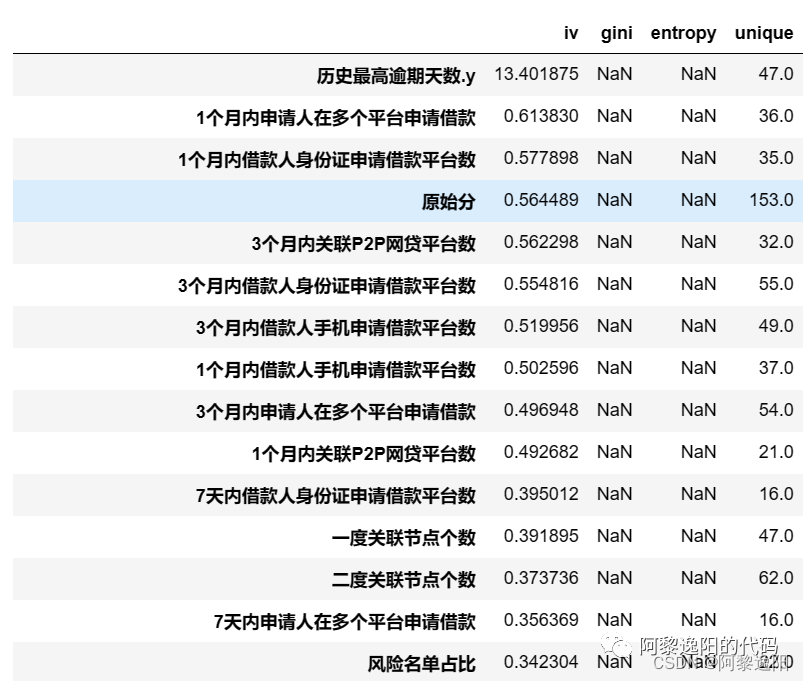
从结果知,计算出了对应变量的iv、gini、entropy、unique四个指标的值,并且按iv进行了降序排列。如果熟悉建模的同学应该清楚,这个函数可以用在变量挑选。
例2:iv_only参数设置为True
接着来看下iv_only设置成True的结果,代码如下:
to_drop = ['input_time', '申请状态', '历史最高逾期天数.x'] # 去掉ID列和month列
toad.quality(date.drop(to_drop,axis=1),'y',iv_only=True)
得到结果:
对比例1可以发现,iv_only设置成True时,iv、gini、entropy三个指标只计算了iv值。如果数据量很大,特征比较多,但想节省计算时间,这种设置比较适合。
四、对比十等分计算iv值
为了对比用toad.quality函数计算iv和十等分计算iv的区别。先定义10等分切割计算iv的函数,具体代码如下:
#等频切割变量函数
def bin_frequency(x,y,n=10): # x为待分箱的变量,y为target变量.n为分箱数量total = y.count() #1 计算总样本数bad = y.sum() #2 计算坏样本数good = total-bad #3 计算好样本数if x.value_counts().shape[0]==2: #4 如果该变量值是0和1则只分两组d1 = pd.DataFrame({'x':x,'y':y,'bucket':pd.cut(x,2)})else:d1 = pd.DataFrame({'x':x,'y':y,'bucket':pd.qcut(x,n,duplicates='drop')}) #5 用pd.cut实现等频分箱d2 = d1.groupby('bucket',as_index=True) #6 按照分箱结果进行分组聚合d3 = pd.DataFrame(d2.x.min(),columns=['min_bin'])d3['min_bin'] = d2.x.min() #7 箱体的左边界d3['max_bin'] = d2.x.max() #8 箱体的右边界d3['bad'] = d2.y.sum() #9 每个箱体中坏样本的数量d3['total'] = d2.y.count() #10 每个箱体的总样本数d3['bad_rate'] = d3['bad']/d3['total'] #11 每个箱体中坏样本所占总样本数的比例d3['badattr'] = d3['bad']/bad #12 每个箱体中坏样本所占坏样本总数的比例d3['goodattr'] = (d3['total'] - d3['bad'])/good #13 每个箱体中好样本所占好样本总数的比例d3['WOEi'] = np.log(d3['badattr']/d3['goodattr']) #14 计算每个箱体的woe值IV = ((d3['badattr']-d3['goodattr'])*d3['WOEi']).sum() #15 计算变量的iv值d3['IVi'] = (d3['badattr']-d3['goodattr'])*d3['WOEi'] #16 计算IVd4 = (d3.sort_values(by='min_bin')).reset_index(drop=True) #17 对箱体从大到小进行排序cut = []cut.append(float('-inf'))for i in d4.min_bin:cut.append(i)cut.append(float('inf'))WOEi = list(d4['WOEi'].round(3))return IV,cut,WOEi,d4
调用函数计算单个变量的iv值,具体代码如下:
IV,cut,WOEi,d4 = bin_frequency(date['1个月内申请人在多个平台申请借款'], date['y'], 10)
print(IV)
d4
得到结果:
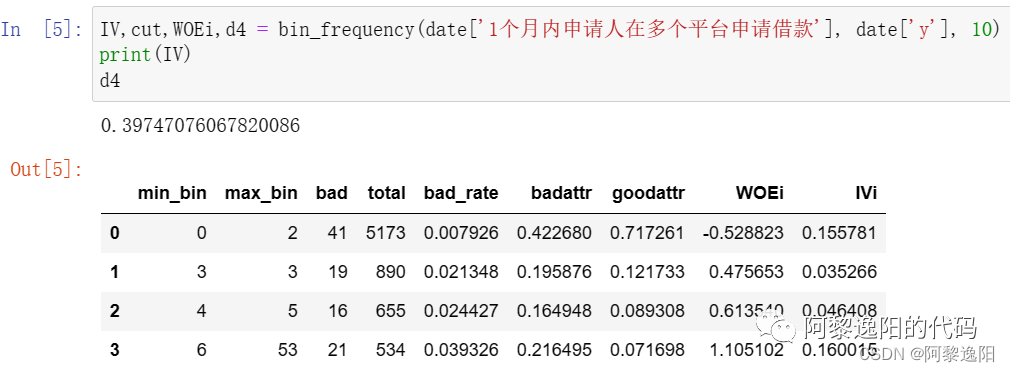
可以发现10等分计算变量【1个月内申请人在多个平台申请借款】的iv时值为0.397。而在例1中用toad.quality函数计算得到的结果是0.613,明显toad.quality计算的值高于10等分计算的值。说明不同的切割方式,对变量的iv值有较大的影响。
那是所有的变量都是如此吗?
我们用批量的方式,把数据框中的变量10等分iv值计算出来,然后和toad.quality方式计算的iv进行对比。先循环计算10等分iv值,具体代码如下:
columns = list(quality_result.index)
dt = date
dt = dt.fillna(-999999)
dt = dt.replace('NaN', -999999)
pd.set_option("display.max_rows", 1000)
pd.set_option("display.max_columns", 1000)
pd.set_option('display.max_columns',None)
IV_table = [0]
IV_name = ['xx']
for i in columns: try:IV,cut,WOEi,d4 = bin_frequency(dt[i], dt['y'], 10)IV_table.append(IV)IV_name.append(i)print('变量【', i, '】的', 'IV=', IV, end='\n')display(d4)except:print(i)pass#print('=======================================' ,end='\n')
IV_name_table = pd.DataFrame({'IV_name':IV_name, 'iv_value':IV_table})IV_name_table
得到结果:

把两个结果拼到一起对比,代码如下:
IV_name_table = IV_name_table.loc[1:, :] #去除第一行无用值
quality_result['IV_name'] = quality_result.index #加变量名列
pd.merge(IV_name_table, quality_result, on=['IV_name'], how='left') #合并数据
得到结果:
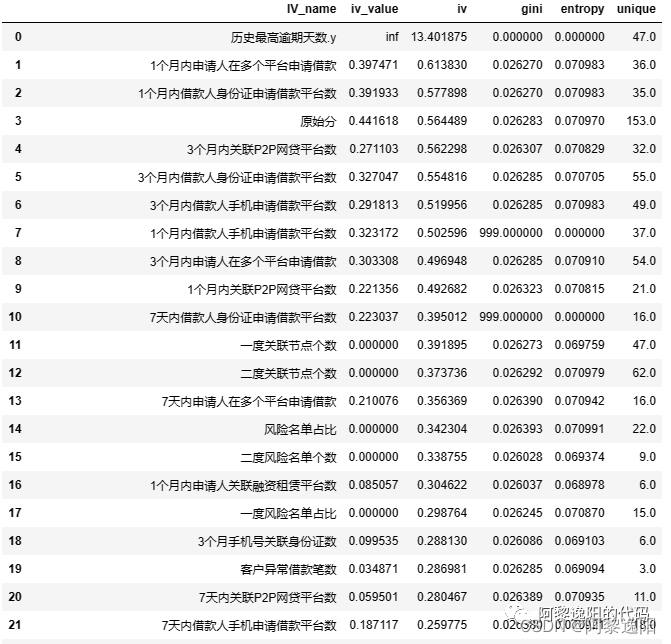
其中,iv_value列是十等分计算得到的iv值,iv列是toad.quality函数计算得到的iv值。可以发现,两者计算有些变量的差距还是挺大的,但大体趋势一致。在使用时可以根据具体场景选择两种方法中的一种进行计算,也可两者都计算,求并集挑选变量。
至此,Python中的quality函数已讲解完毕,如想了解更多Python中的函数,可以翻看公众号中“学习Python”模块相关文章。
【限时免费进群】群内提供学习Python、玩转Python、风控建模、人工智能、数据分析相关招聘内推信息、优秀文章、学习视频,也可交流学习工作中遇到的相关问题。需要的朋友添加微信号19967879837,加时备注想进的群,比如风控建模。
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
Python人脸识别—我的眼里只有你
Python画好看的星空图(唯美的背景)
用Python中的py2neo库操作neo4j,搭建关联图谱
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)