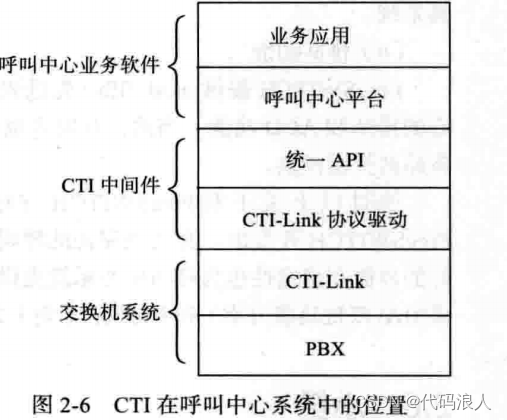
ASRT语音识别系统的部署以及模型的使用(运用篇)
前言
ASRT是一个中文语音识别系统,由AI柠檬博主开源在GitHub上。
GitHub地址:ASRT_SpeechRecognition
国内Gitee镜像地址:ASRT_SpeechRecognition
文档地址:ASRT语音识别工具文档
本文主要是记录一下我在参考文章:教你如何使用ASRT训练中文语音识别模型 并完成部署以及使用模型进行语音识别的操作步骤。
文章作者比较惜字如金,文中很多细节之处没有细讲,我在windows上进行部署的时候踩了比较多的坑,特此记录下。
本文适用对象:只想搭建一个语音识别服务端,来实现语音识别功能,而不需要训练出自定义的语音识别模型(如:训练出可识别某些方言的模型)。
如需训练自定义模型,可参考文章ASRT语音识别系统的部署以及模型训练
文章目录
- 前言
- @[toc]
- 先决条件:
- 下载ASRT Released包
- 运行环境搭建
- 操作系统安装CUDA、cuDNN
- 安装步骤
- 查看CUDA版本:
- 查看cuDNN版本:
- 安装Anaconda
- 安装步骤
- 查看conda版本信息:
- 项目部署
- conda创建python虚拟环境
- 操作步骤
- 查看虚拟环境基本信息
- 为ASRT项目安装依赖包
- 安装依赖包:
- 踩坑记录:
- 使用ASRT模型
- 本机进行语音识别
- 将ASRT部署成服务
- 设置ASRT服务开机自启动
- 常见问题去哪里找?
文章目录
- 前言
- @[toc]
- 先决条件:
- 下载ASRT Released包
- 运行环境搭建
- 操作系统安装CUDA、cuDNN
- 安装步骤
- 查看CUDA版本:
- 查看cuDNN版本:
- 安装Anaconda
- 安装步骤
- 查看conda版本信息:
- 项目部署
- conda创建python虚拟环境
- 操作步骤
- 查看虚拟环境基本信息
- 为ASRT项目安装依赖包
- 安装依赖包:
- 踩坑记录:
- 使用ASRT模型
- 本机进行语音识别
- 将ASRT部署成服务
- 设置ASRT服务开机自启动
- 常见问题去哪里找?
先决条件:
众所周知,跑神经网络,要用到英伟达的显卡。
本人硬件参数: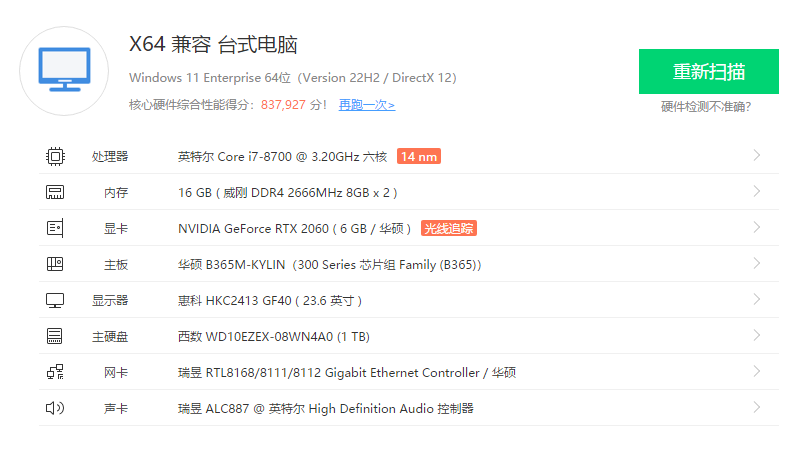
以下是官方配置建议,我的显卡可能不达标,但如果存粹使用训练好的模型来进行语音识别的话,并不需要这么高的设备。

下载ASRT Released包
前往Github下载最新Released包(ASRT v1.3.0)。
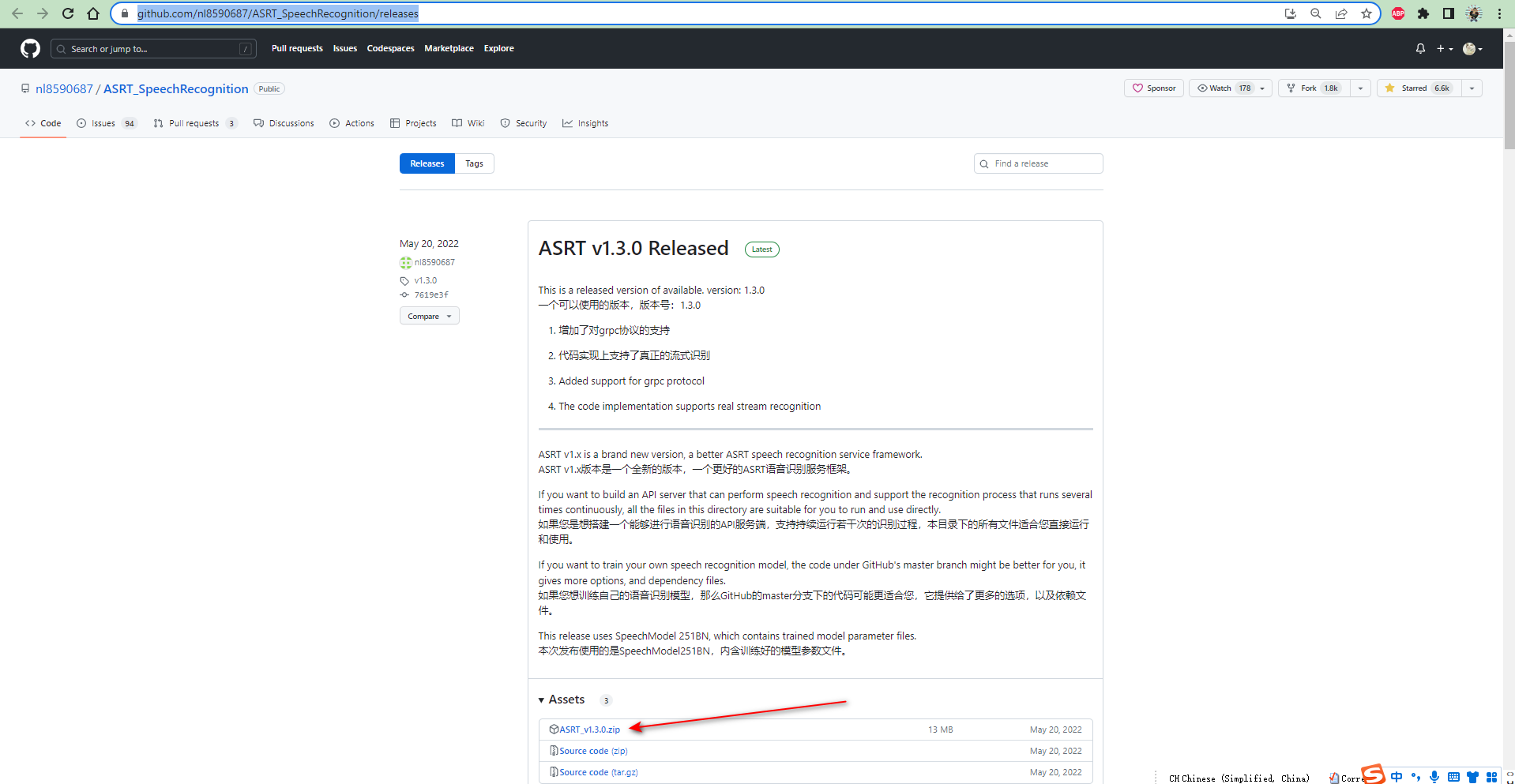
下载完成后,需要进行解压。之后,如果GitHub仓库上如果代码有更新,重复上述步骤即可。
我的解压路径:
cd C:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_SpeechRecognition
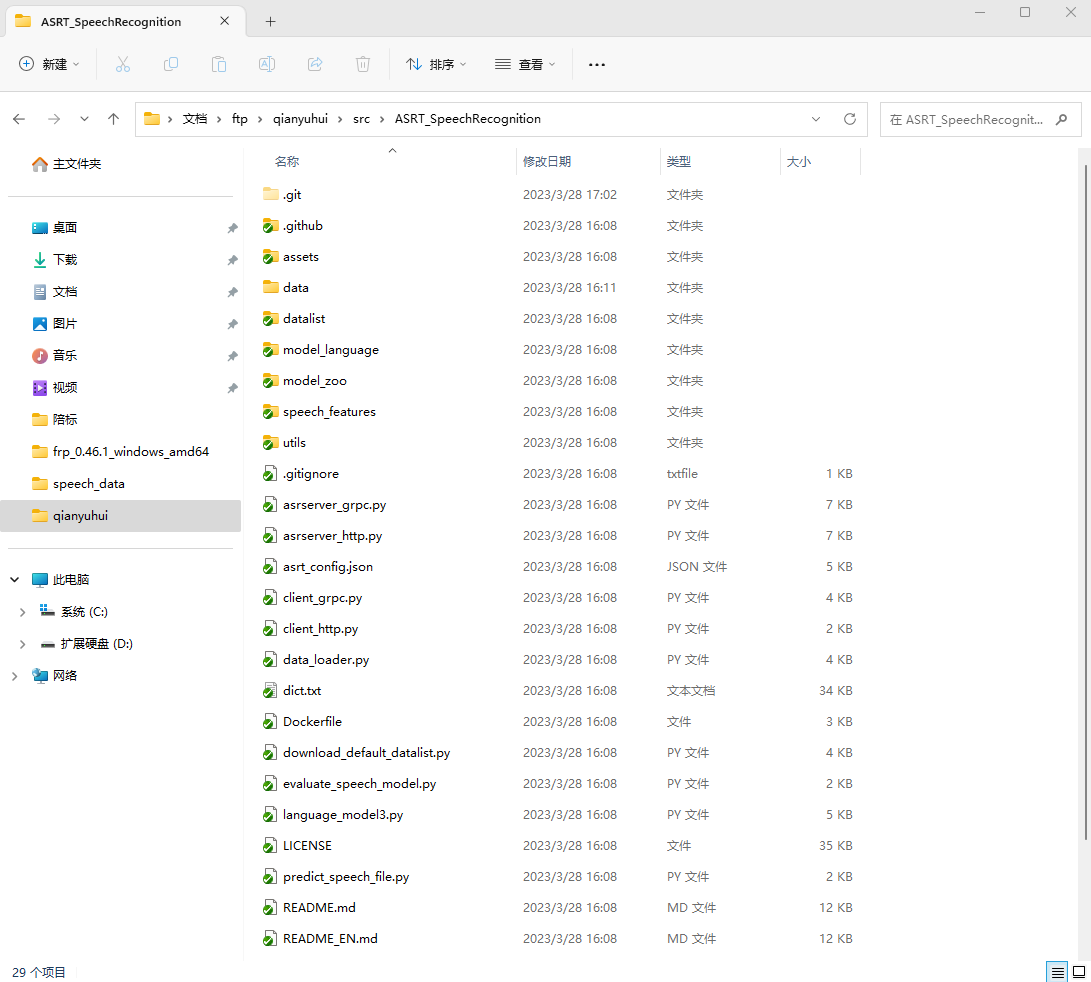
运行环境搭建
操作系统安装CUDA、cuDNN
训练模型请安装好Nvidia GPU驱动和CUDA、cuDNN。
安装步骤
安装过程略过。参考文章:Windows 安装 CUDA/cuDNN
查看CUDA版本:
nvcc -V

查看cuDNN版本:
进入 cuda 的安装路径, C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include,找到 cudnn_version.h 选中,以记事本方式打开。

这里,我的是8.8.1
安装Anaconda
安装步骤
安装步骤略过,参考文章:anaconda的安装和使用
查看conda版本信息:
Anaconda PowerShell控制台中输入以下命令:
conda info
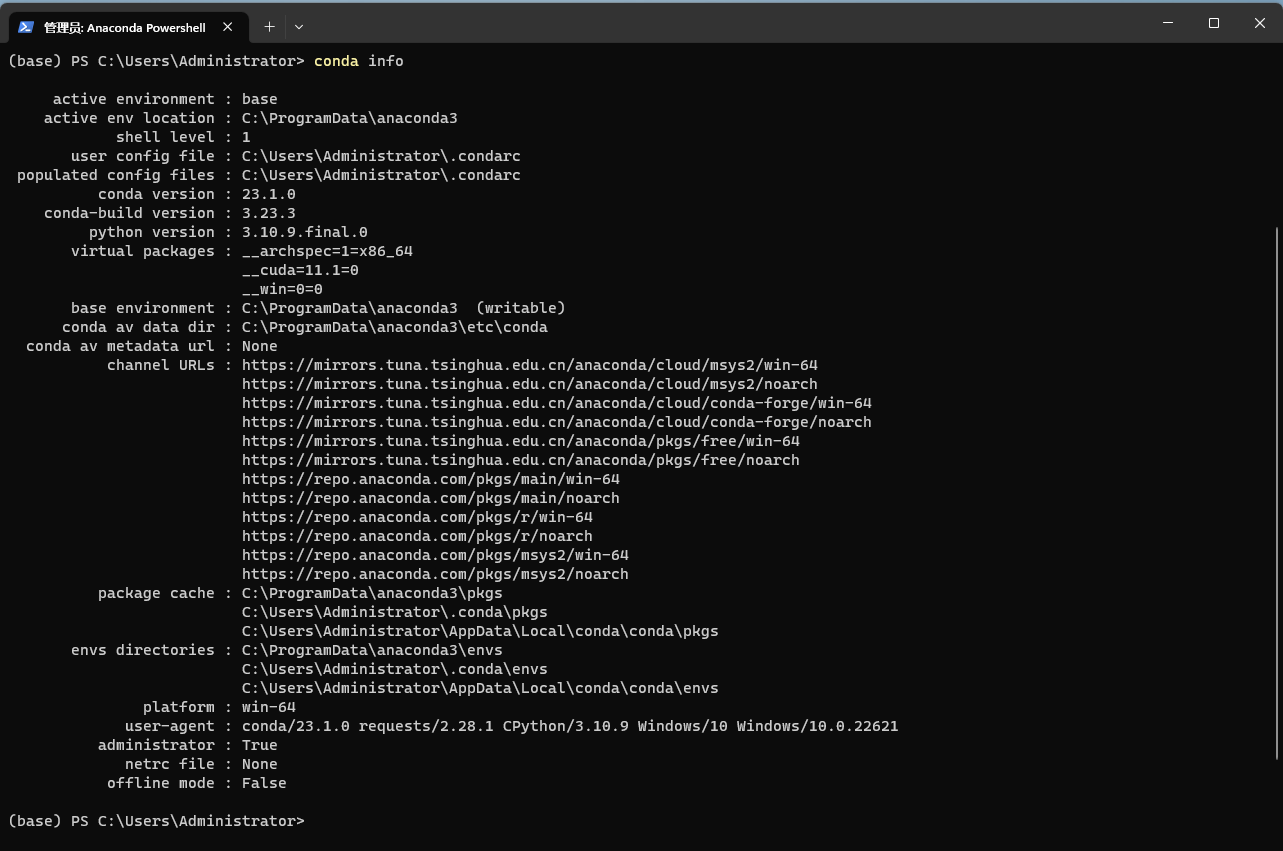
我的conda版本是23.1.0
项目部署
conda创建python虚拟环境
首先请确保Anaconda 创建python3.10的虚拟环境。
操作步骤
我给asrt单独创建了一个名为:asrt_env的虚拟环境:
Anaconda PowerShell控制台中输入以下命令:
conda create -n asrt_env python=3.10
查看虚拟环境基本信息
Anaconda PowerShell控制台中输入以下命令:
conda env list conda activate asrt_env conda info
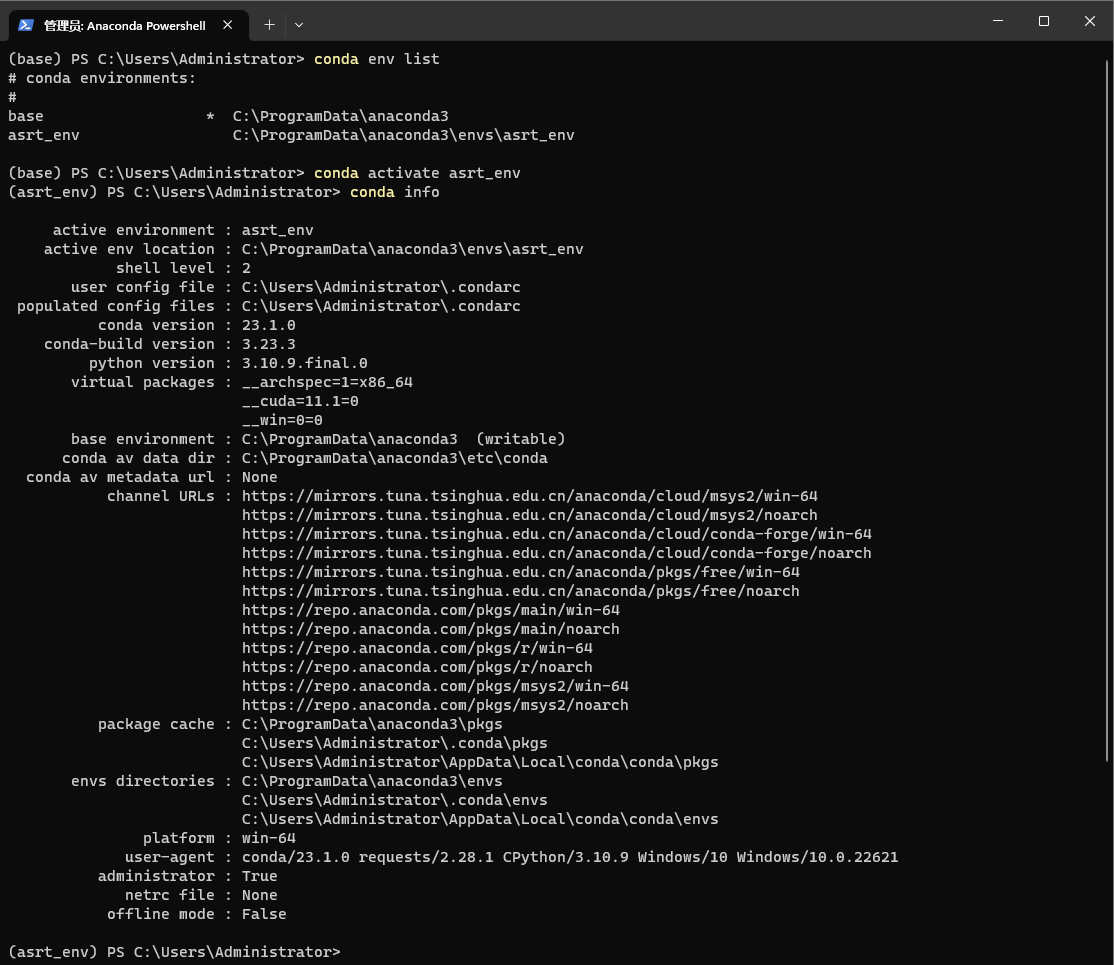
为ASRT项目安装依赖包
安装依赖包:
Anaconda PowerShell控制台中,我们激活asrt_env虚拟环境,并cd到ASRT项目下,通过
requirements.txt为其安装依赖包:
conda env list
conda activate asrt_env
cd c:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_SpeechRecognition\
pip install -r requirements.txt
这是一个漫长的安装过程,甚至经常因为网速慢导致下载失败。
踩坑记录:
我在安装tensorflow-gpu时失败了好几次,因为我conda使用的是清华源,下载tensorflow-gpu及其缓慢:
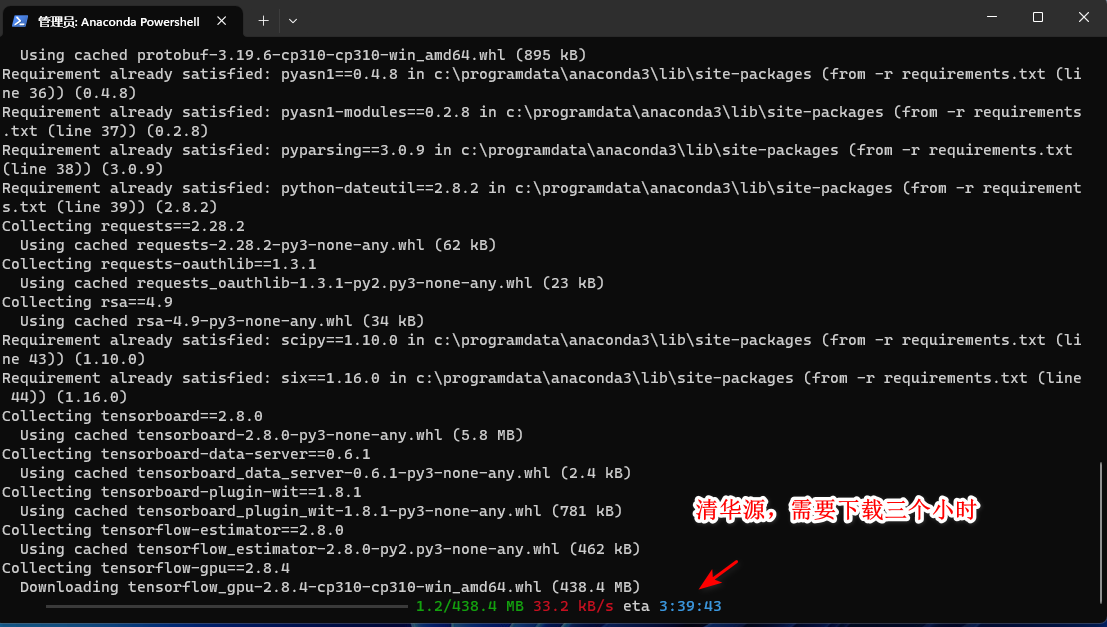
后来网上找到了提速的办法:
关掉原本的控制台,重新通过asrt_env进入ASRT项目目录,
单独先使用中科大的镜像将tensorflow-gpu安装好:
conda env list
conda activate asrt_env
pip --default-timeout=1000000 install -U -i https://pypi.mirrors.ustc.edu.cn/simple/ --upgrade tensorflow-gpu==2.8.4
然后重新安装requirements.txt内的包:
conda env list
conda activate asrt_env
cd C:\\Users\\Administrator\\Documents\\ftp\\qianyuhui\\src\\ASRT_SpeechRecognition
pip install -r requirements.txt
使用ASRT模型
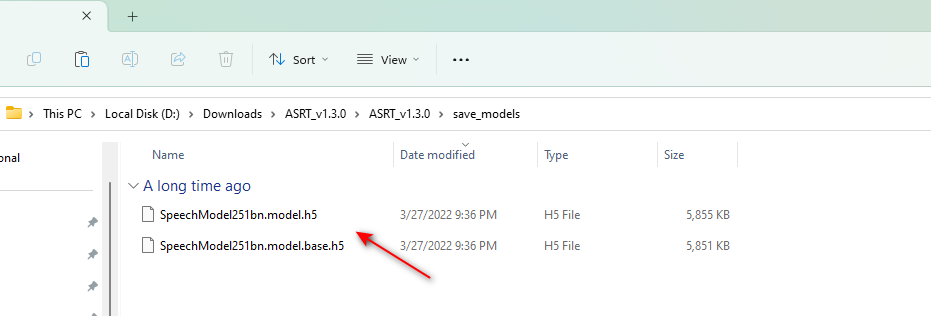
ASRT Released包中的save_models文件夹下已经有一份训练好的模型文件了
本机进行语音识别
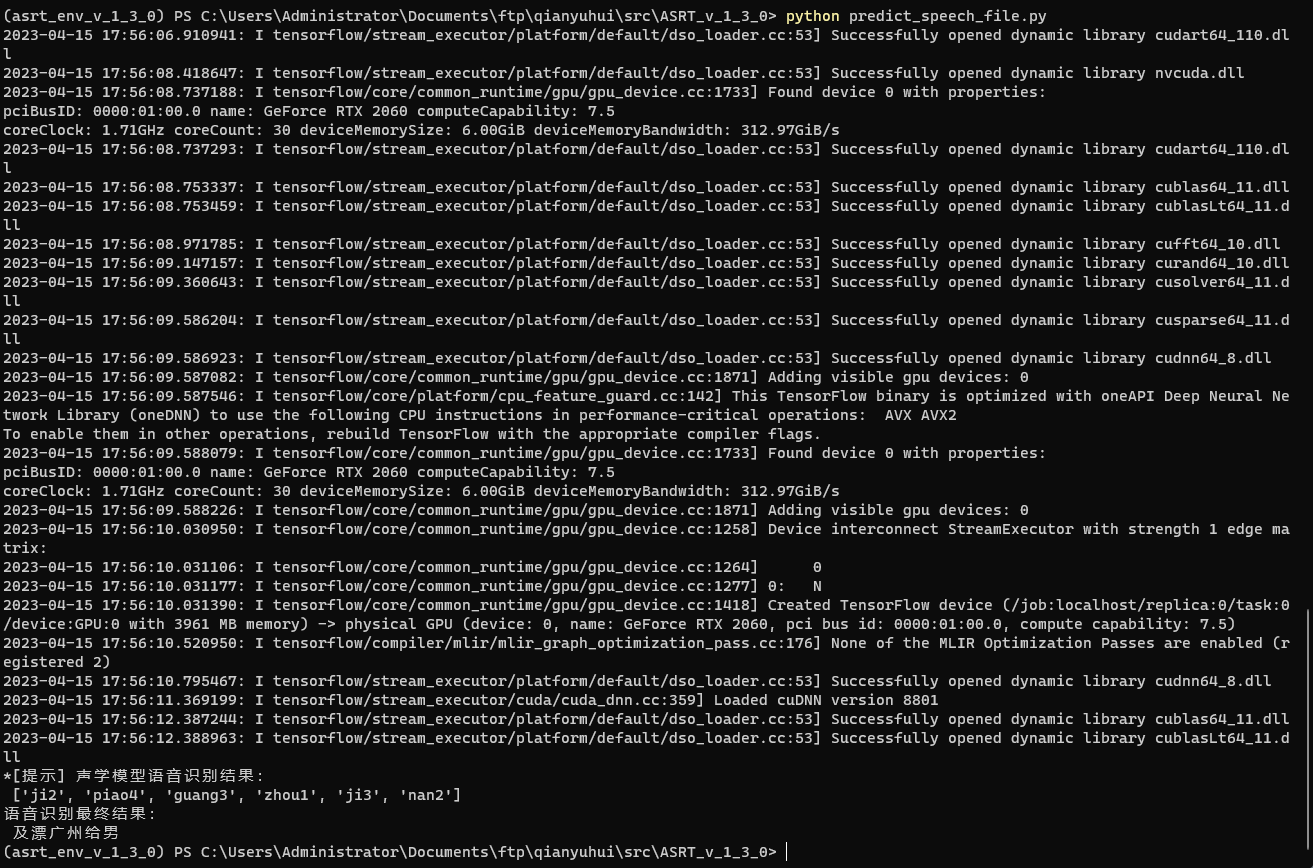
语音识别使用predict_speech_file.py文件:
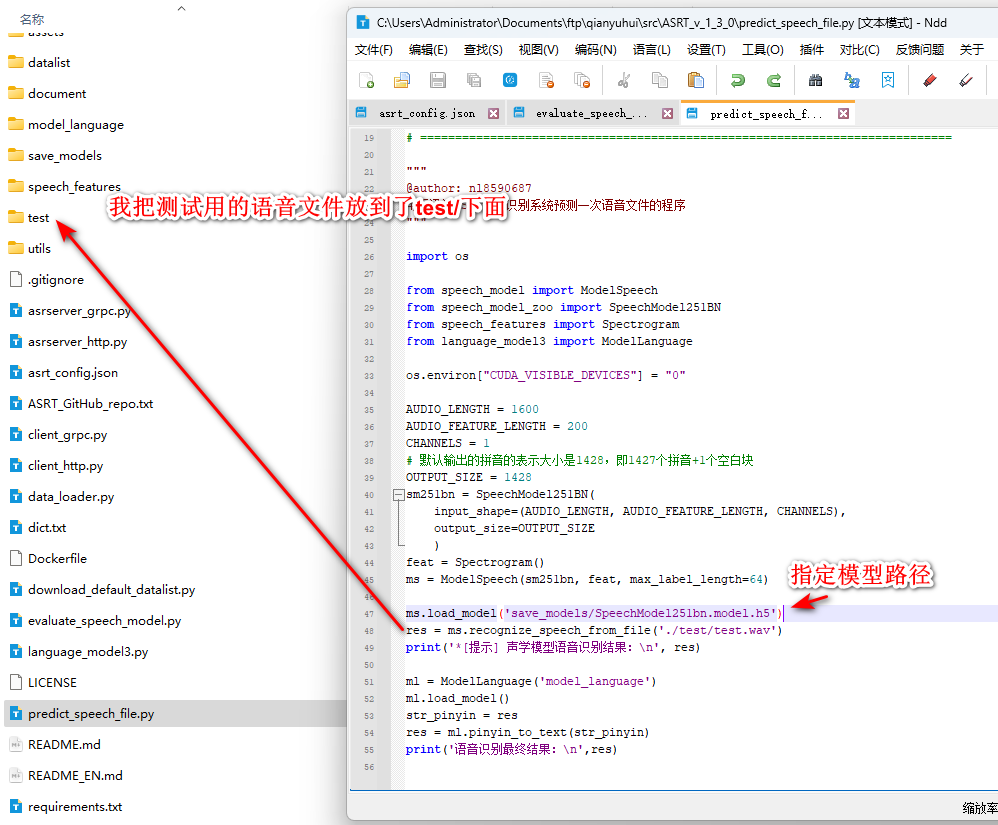
第47行代码:load_model()方法中,需要指定模型参数文件(.h)路径。
第48行代码:recognize_speech_from_file()函数里面,填写我们需要识别的录音文件的文件名路径。
完毕后,运行代码,查看识别结果。
conda env list
conda activate asrt_env
cd C:\\Users\\Administrator\\Documents\\ftp\\qianyuhui\\src\\ASRT_SpeechRecognition python predict_speech_file.py
将ASRT部署成服务
这部分参考文章:教你如何使用ASRT部署中文语音识别API服务器
打开asrserver_http.py文件,如图。
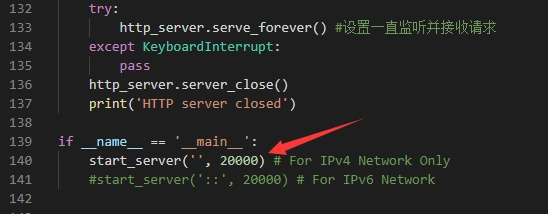
在文件末尾,有默认监听的端口配置,默认为20001端口。
输入以下命令启动服务:
python asrserver_http.py
设置ASRT服务开机自启动
常见问题去哪里找?
FAQ常见问题答疑