领域驱动设计(Domain Driven Design,简称DDD)盛行之后,这种基于贫血模型的传统的开发模式就更加被人诟病。而基于充血模型的DDD开发模式越来越被人提倡。所以,我打算用两节课的时间,结合一个虚拟钱包系统的开发案例,带你彻底弄清楚这两种开发模式。
先搞清楚下面几个问题:
- 什么是贫血模型?什么是充血模型?
- 为什么说基于贫血模型的传统开发模式违反OOP?
- 基于贫血模型的传统开发模式既然违反OOP,那又为什么如此流行?
- 什么情况下我们应该考虑使用基于充血模型的DDD开发模式?
好了,让我们带着这些问题,正式开始今天的学习吧!
什么是基于贫血模型的传统开发模式?
MVC三层架构中的M表示Model,V表示View,C表示Controller。它将整个项目分为三层:数据层、逻辑层和展示层。MVC三层开发架构是一个比较笼统的分层方式,落实到具体的开发层面,很多项目也并不会100%遵从MVC固定的分层方式,而是会根据具体的项目需求,做适当的调整。
刚刚我们回顾了MVC三层开发架构。现在,我们再来看一下,什么是贫血模型?
实际上,你可能一直都在用贫血模型做开发,只是自己不知道而已。不夸张地讲,据我了解,目前几乎所有的业务后端系统,都是基于贫血模型的。我举一个简单的例子来给你解释一下。
// Controller+VO(View Object) //
public class UserController {private UserService userService; //通过构造函数或者IOC框架注入,一般是IOC注入public UserVo getUserById(Long userId) {UserBo userBo = userService.getUserById(userId);UserVo userVo = [...convert userBo to userVo...];return userVo;}
}public class UserVo {//省略其他属性、get/set/construct方法private Long id;private String name;private String cellphone;
}// Service+BO(Business Object) //
public class UserService {private UserRepository userRepository; //通过构造函数或者IOC框架注入public UserBo getUserById(Long userId) {UserEntity userEntity = userRepository.getUserById(userId);UserBo userBo = [...convert userEntity to userBo...];return userBo;}
}public class UserBo {//省略其他属性、get/set/construct方法private Long id;private String name;private String cellphone;
}// Repository+Entity //
public class UserRepository {public UserEntity getUserById(Long userId) { //... }
}public class UserEntity {//省略其他属性、get/set/construct方法private Long id;private String name;private String cellphone;
}从代码中,我们可以发现,UserBo是一个纯粹的数据结构,只包含数据,不包含任何业务逻辑。业务逻辑集中在UserService中。我们通过UserService来操作UserBo。换句话说,Service层的数据和业务逻辑,被分割为BO和Service两个类中。像UserBo这样,只包含数据,不包含业务逻辑的类,就叫作贫血模型(Anemic Domain Model)。同理,UserEntity、UserVo都是基于贫血模型设计的。这种贫血模型将数据与操作分离,破坏了面向对象的封装特性,是一种典型的面向过程的编程风格。
什么是基于充血模型的DDD开发模式?
首先,我们先来看一下,什么是充血模型?
在贫血模型中,数据和业务逻辑被分割到不同的类中。充血模型(Rich Domain Model)正好相反,数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的面向对象编程风格。(将repository和entity定义在一起。)
接下来,我们再来看一下,什么是领域驱动设计?
领域驱动设计,即DDD,主要是用来指导如何解耦业务系统,划分业务模块,定义业务领域模型及其交互。领域驱动设计这个概念并不新颖,早在2004年就被提出了,到现在已经有十几年的历史了。不过,它被大众熟知,还是基于另一个概念的兴起,那就是微服务。
我们知道,除了监控、调用链追踪、API网关等服务治理系统的开发之外,微服务还有另外一个更加重要的工作,那就是针对公司的业务,合理地做微服务拆分。而领域驱动设计恰好就是用来指导划分服务的。所以,微服务加速了领域驱动设计的盛行。
实际上,基于充血模型的DDD开发模式实现的代码,也是按照MVC三层架构分层的。Controller层还是负责暴露接口,Repository层还是负责数据存取,Service层负责核心业务逻辑。它跟基于贫血模型的传统开发模式的区别主要在Service层。
在基于贫血模型的传统开发模式中,Service层包含Service类和BO类两部分,BO是贫血模型,只包含数据,不包含具体的业务逻辑。业务逻辑集中在Service类中。在基于充血模型的DDD开发模式中,Service层包含Service类和Domain类两部分。Domain就相当于贫血模型中的BO。不过,Domain与BO的区别在于它是基于充血模型开发的,既包含数据,也包含业务逻辑。而Service类变得非常单薄。总结一下的话就是,基于贫血模型的传统的开发模式,重Service轻BO;基于充血模型的DDD开发模式,轻Service重Domain。
为什么基于贫血模型的传统开发模式如此受欢迎?
- 第一点原因是,大部分情况下,我们开发的系统业务可能都比较简单,简单到就是基于SQL的CRUD操作,所以,我们根本不需要动脑子精心设计充血模型,贫血模型就足以应付这种简单业务的开发工作。除此之外,因为业务比较简单,即便我们使用充血模型,那模型本身包含的业务逻辑也并不会很多,设计出来的领域模型也会比较单薄,跟贫血模型差不多,没有太大意义。
- 第二点原因是,充血模型的设计要比贫血模型更加有难度。因为充血模型是一种面向对象的编程风格。我们从一开始就要设计好针对数据要暴露哪些操作,定义哪些业务逻辑。而不是像贫血模型那样,我们只需要定义数据,之后有什么功能开发需求,我们就在Service层定义什么操作,不需要事先做太多设计。
- 第三点原因是,思维已固化,转型有成本。基于贫血模型的传统开发模式经历了这么多年,已经深得人心、习以为常。你随便问一个旁边的大龄同事,基本上他过往参与的所有Web项目应该都是基于这个开发模式的,而且也没有出过啥大问题。如果转向用充血模型、领域驱动设计,那势必有一定的学习成本、转型成本。很多人在没有遇到开发痛点的情况下,是不愿意做这件事情的。
第三点简直是直击要害啊!
什么项目应该考虑使用基于充血模型的DDD开发模式?
既然基于贫血模型的开发模式已经成为了一种约定俗成的开发习惯,那什么样的项目应该考虑使用基于充血模型的DDD开发模式呢?
基于充血模型的DDD开发模式,更适合业务复杂的系统开发。比如,包含各种利息计算模型、还款模型等复杂业务的金融系统。
那么你可能会好奇?为什么仅仅对service层进行改变,就可以发生巨大的变化呢?
实际上,除了我们能看到的代码层面的区别之外(一个业务逻辑放到Service层,一个放到领域模型中),还有一个非常重要的区别,那就是两种不同的开发模式会导致不同的开发流程。基于充血模型的DDD开发模式的开发流程,在应对复杂业务系统的开发的时候更加有优势。为什么这么说呢?我们先来回忆一下,我们平时基于贫血模型的传统的开发模式,都是怎么实现一个功能需求的。
不夸张地讲,我们平时的开发,大部分都是SQL驱动(SQL-Driven)的开发模式。我们接到一个后端接口的开发需求的时候,就去看接口需要的数据对应到数据库中,需要哪张表或者哪几张表,然后思考如何编写SQL语句来获取数据。之后就是定义Entity、BO、VO,然后模板式地往对应的Repository、Service、Controller类中添加代码。非常有水平!!!
缺点:
- 业务逻辑包裹在一个大的SQL语句中,而Service层可以做的事情很少。
- SQL都是针对特定的业务功能编写的,复用性差。
- 当我要开发另一个业务功能的时候,只能重新写个满足新需求的SQL语句,这就可能导致各种长得差不多、区别很小的SQL语句满天飞。
这些缺点会使得再开发复杂业务时候会让代码越来越乱,最终导致无法维护。
如果我们在项目中,应用基于充血模型的DDD的开发模式,那对应的开发流程就完全不一样了。在这种开发模式下,我们需要事先理清楚所有的业务,定义领域模型所包含的属性和方法。领域模型相当于可复用的业务中间层。新功能需求的开发,都基于之前定义好的这些领域模型来完成。
我们知道,越复杂的系统,对代码的复用性、易维护性要求就越高,我们就越应该花更多的时间和精力在前期设计上。而基于充血模型的DDD开发模式,正好需要我们前期做大量的业务调研、领域模型设计,所以它更加适合这种复杂系统的开发。难度更加复杂,但是后期维护更加方便。
那么说了这么多到底如何开始一个DDD充血模型呢?
那么根据一个虚拟钱包系统为例开发一个DDD充血模型Demo。
钱包业务介绍:
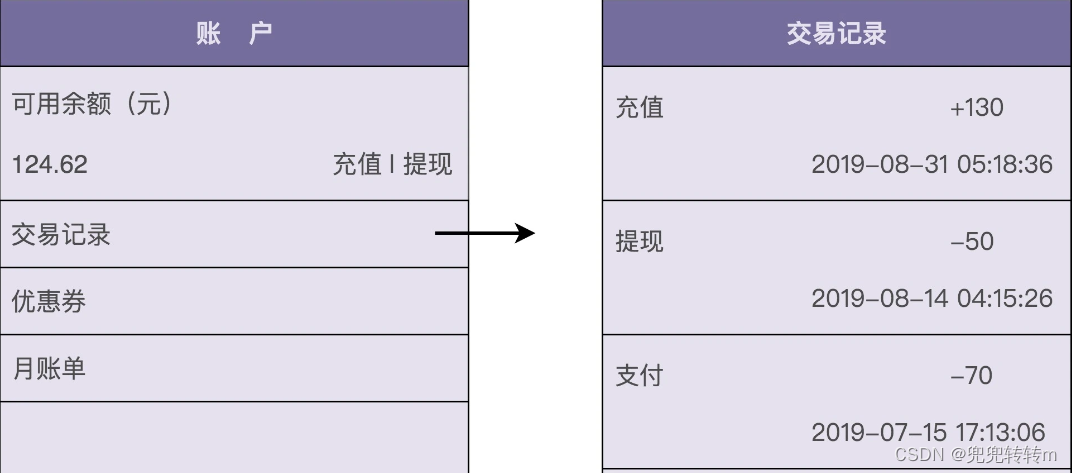
很多具有支付、购买功能的应用(比如淘宝、滴滴出行、极客时间等)都支持钱包的功能。应用为每个用户开设一个系统内的虚拟钱包账户,支持用户充值、提现、支付、冻结、透支、转赠、查询账户余额、查询交易流水等操作。下图是一张典型的钱包功能界面,你可以直观地感受一下。
1. 充值
用户通过三方支付渠道,把自己银行卡账户内的钱,充值到虚拟钱包账号中,整个过程可以分为三部分,第一个操作,从用户的银行卡账户转账到应用的公共银行卡账户;第二个操作是将用户的充值金额加到虚拟钱包余额上;第三个操作是记录刚刚这笔交易流水。
2. 支付
用户用钱包内的余额,支付购买应用内的商品。实际上,支付的过程就是一个转账的过程,从用户的虚拟钱包账户划钱到商家的虚拟钱包账户上。除此之外,我们也需要记录这笔支付的交易流水信息。
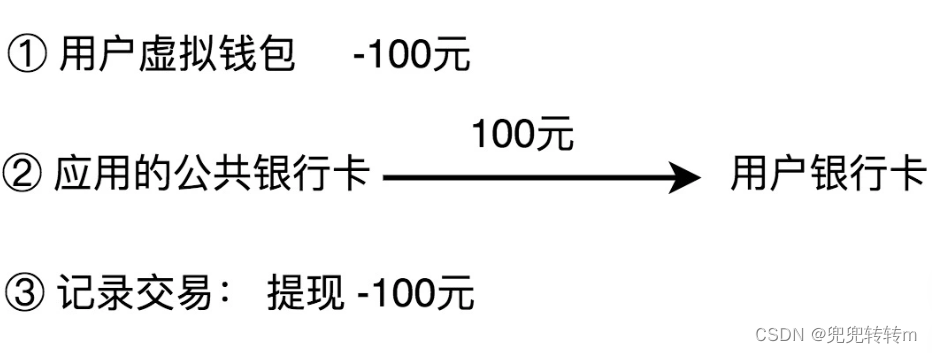
3. 体现
除了充值、支付之外,用户还可以将虚拟钱包中的余额,提现到自己的银行卡中。这个过程实际上就是扣减用户虚拟钱包中的余额,并且触发真正的银行转账操作,从应用的公共银行账户转钱到用户的银行账户。同样,我们也需要记录这笔提现的交易流水信息。
4.查询余额
查询余额功能比较简单,我们看一下虚拟钱包中的余额数字即可。
5.查询交易流水
查询交易流水也比较简单。我们只支持三种类型的交易流水:充值、支付、提现。在用户充值、支付、提现的时候,我们会记录相应的交易信息。在需要查询的时候,我们只需要将之前记录的交易流水,按照时间、类型等条件过滤之后,显示出来即可。
钱包系统的设计思路
根据刚刚讲的业务实现流程和数据流转图,我们可以把整个钱包系统的业务划分为两部分,其中一部分单纯跟应用内的虚拟钱包账户打交道,另一部分单纯跟银行账户打交道。我们基于这样一个业务划分,给系统解耦,将整个钱包系统拆分为两个子系统:虚拟钱包系统和三方支付系统。
这样可以避免每次第三方支付的转账,仅仅在体现过程中才会产生第三方转账。

为了能在有限的篇幅内,将今天的内容讲透彻,我们接来下只聚焦于虚拟钱包系统的设计与实现。对于三方支付系统以及整个钱包系统的设计与实现,我们不做讲解。你可以自己思考下。我会在最后加入我自己的思考。
对于虚拟钱包,可以要针对以下等五个功能进行设计。
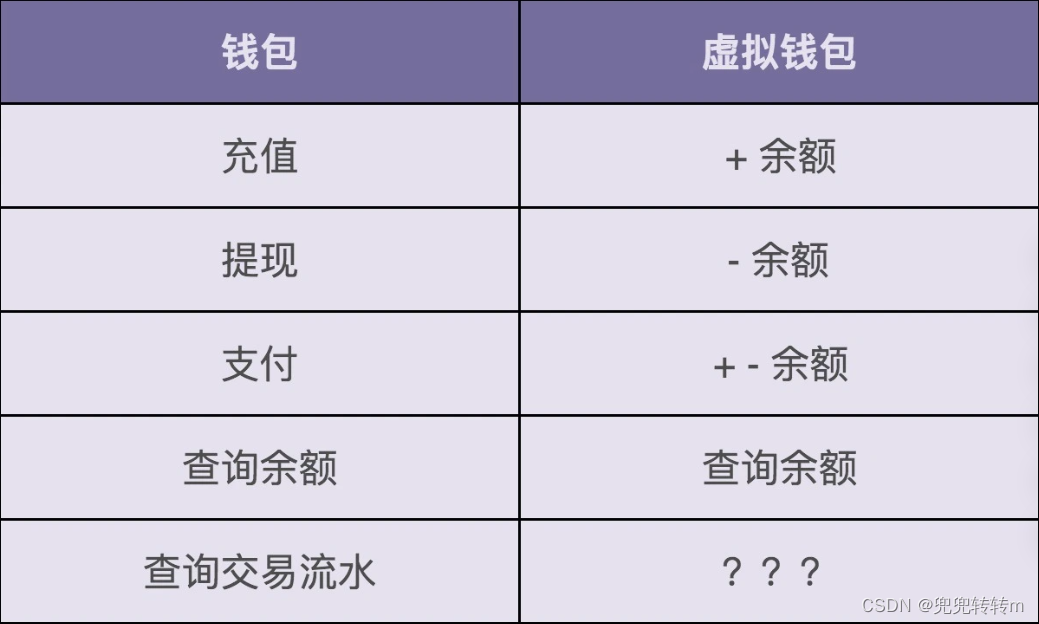
从图中我们可以看出,虚拟钱包系统要支持的操作非常简单,就是余额的加加减减。其中,充值、提现、查询余额三个功能,只涉及一个账户余额的加减操作,而支付功能涉及两个账户的余额加减操作:一个账户减余额,另一个账户加余额。
现在,我们再来看一下图中问号的那部分,也就是交易流水该如何记录和查询?我们先来看一下,交易流水都需要包含哪些信息。我觉得下面这几个信息是必须包含的。
| 入账钱包账号 |
| 出账钱包账号 |
| 支出金额 |
| 剩余金额 |
| 支出时间 |
从图中我们可以发现,交易流水的数据格式包含两个钱包账号,一个是入账钱包账号,一个是出账钱包账号。为什么要有两个账号信息呢?这主要是为了兼容支付这种涉及两个账户的交易类型。不过,对于充值、提现这两种交易类型来说,我们只需要记录一个钱包账户信息就够了。
那么根据上述的设计思路,贫血模型的传统开发模式是如何实现的呢?
基于贫血模型的传统开发模式
首先:Controller+VO 负责暴露接口,具体的伪代码实现如下:主要还是调用Service层的方法。
public class VirtualWalletController {// 通过构造函数或者IOC框架注入private VirtualWalletService virtualWalletService;public BigDecimal getBalance(Long walletId) { ... } //查询余额public void debit(Long walletId, BigDecimal amount) { ... } //出账public void credit(Long walletId, BigDecimal amount) { ... } //入账public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) { ...} //转账//省略查询transaction的接口
}Service和BO负责核心业务逻辑,Repository和Entity负责数据存取。Repository这一层的代码实现比较简单,不是我们讲解的重点,所以我也省略掉了。Service层的代码如下所示。注意,这里我省略了一些不重要的校验代码,比如,对amount是否小于0、钱包是否存在的校验等等。
public class VirtualWalletBo {//省略getter/setter/constructor方法private Long id;private Long createTime;private BigDecimal balance;
}public Enum TransactionType {DEBIT,CREDIT,TRANSFER;
}public class VirtualWalletService {// 通过构造函数或者IOC框架注入private VirtualWalletRepository walletRepo;private VirtualWalletTransactionRepository transactionRepo;public VirtualWalletBo getVirtualWallet(Long walletId) {VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);VirtualWalletBo walletBo = convert(walletEntity);return walletBo;}public BigDecimal getBalance(Long walletId) {return walletRepo.getBalance(walletId);}// 在事务操作时候,注意事务是否会失效。@Transactionalpublic void debit(Long walletId, BigDecimal amount) {VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);BigDecimal balance = walletEntity.getBalance();if (balance.compareTo(amount) < 0) {throw new NoSufficientBalanceException(...);}VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();transactionEntity.setAmount(amount);transactionEntity.setCreateTime(System.currentTimeMillis());transactionEntity.setType(TransactionType.DEBIT);transactionEntity.setFromWalletId(walletId);transactionRepo.saveTransaction(transactionEntity);walletRepo.updateBalance(walletId, balance.subtract(amount));}@Transactionalpublic void credit(Long walletId, BigDecimal amount) {VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();transactionEntity.setAmount(amount);transactionEntity.setCreateTime(System.currentTimeMillis());transactionEntity.setType(TransactionType.CREDIT);transactionEntity.setFromWalletId(walletId);transactionRepo.saveTransaction(transactionEntity);VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);BigDecimal balance = walletEntity.getBalance();walletRepo.updateBalance(walletId, balance.add(amount));}@Transactionalpublic void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();transactionEntity.setAmount(amount);transactionEntity.setCreateTime(System.currentTimeMillis());transactionEntity.setType(TransactionType.TRANSFER);transactionEntity.setFromWalletId(fromWalletId);transactionEntity.setToWalletId(toWalletId);transactionRepo.saveTransaction(transactionEntity);debit(fromWalletId, amount);credit(toWalletId, amount);}
}基于充血模型的DDD开发模式
刚刚讲了如何利用基于贫血模型的传统开发模式来实现虚拟钱包系统,现在,我们再来看一下,如何利用基于充血模型的DDD开发模式来实现这个系统?
在前面我们讲到,基于充血模型的DDD开发模式,跟基于贫血模型的传统开发模式的主要区别就在Service层,Controller层和Repository层的代码基本上相同。所以,我们重点看一下,Service层按照基于充血模型的DDD开发模式该如何来实现。
在这种开发模式下,我们把虚拟钱包VirtualWallet类设计成一个充血的Domain领域模型,并且将原来在Service类中的部分业务逻辑移动到VirtualWallet类中,让Service类的实现依赖VirtualWallet类。具体的代码实现如下所示:
public class VirtualWallet { // Domain领域模型(充血模型)private Long id;private Long createTime = System.currentTimeMillis();;private BigDecimal balance = BigDecimal.ZERO;public VirtualWallet(Long preAllocatedId) {this.id = preAllocatedId;}public BigDecimal balance() {return this.balance;}public void debit(BigDecimal amount) {if (this.balance.compareTo(amount) < 0) {throw new InsufficientBalanceException(...);}this.balance = this.balance.subtract(amount);}public void credit(BigDecimal amount) {if (amount.compareTo(BigDecimal.ZERO) < 0) {throw new InvalidAmountException(...);}this.balance = this.balance.add(amount);}
}public class VirtualWalletService {// 通过构造函数或者IOC框架注入private VirtualWalletRepository walletRepo;private VirtualWalletTransactionRepository transactionRepo;public VirtualWallet getVirtualWallet(Long walletId) {VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);VirtualWallet wallet = convert(walletEntity);return wallet;}public BigDecimal getBalance(Long walletId) {return walletRepo.getBalance(walletId);}@Transactionalpublic void debit(Long walletId, BigDecimal amount) {VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);VirtualWallet wallet = convert(walletEntity);wallet.debit(amount);VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();transactionEntity.setAmount(amount);transactionEntity.setCreateTime(System.currentTimeMillis());transactionEntity.setType(TransactionType.DEBIT);transactionEntity.setFromWalletId(walletId);transactionRepo.saveTransaction(transactionEntity);walletRepo.updateBalance(walletId, wallet.balance());}@Transactionalpublic void credit(Long walletId, BigDecimal amount) {VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);VirtualWallet wallet = convert(walletEntity);wallet.credit(amount);VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();transactionEntity.setAmount(amount);transactionEntity.setCreateTime(System.currentTimeMillis());transactionEntity.setType(TransactionType.CREDIT);transactionEntity.setFromWalletId(walletId);transactionRepo.saveTransaction(transactionEntity);walletRepo.updateBalance(walletId, wallet.balance());}@Transactionalpublic void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {//...跟基于贫血模型的传统开发模式的代码一样...}
}
看了上面的代码,你可能会说,领域模型VirtualWallet类很单薄,包含的业务逻辑很简单。相对于原来的贫血模型的设计思路,这种充血模型的设计思路,貌似并没有太大优势。你说得没错!这也是大部分业务系统都使用基于贫血模型开发的原因。不过,如果虚拟钱包系统需要支持更复杂的业务逻辑,那充血模型的优势就显现出来了。比如,我们要支持透支一定额度和冻结部分余额的功能。这个时候,我们重新来看一下VirtualWallet类的实现代码。
VirtualWallet中的balance方法是不是没有用到啊。
领域模型VirtualWallet类添加了简单的冻结和透支逻辑之后,功能看起来就丰富了很多,代码也没那么单薄了。如果功能继续演进,我们可以增加更加细化的冻结策略、透支策略、支持钱包账号(VirtualWallet id字段)自动生成的逻辑(不是通过构造函数经外部传入ID,而是通过分布式ID生成算法来自动生成ID)等等。VirtualWallet类的业务逻辑会变得越来越复杂,也就很值得设计成充血模型了。
这样也从侧面说明了设计成充血模型后,不会进行SQL驱动编程,可以重复利用BO也就是VirtualWallet。而不是根据一个SQL写一个BO了。
那么第三方银行转账如何设计呢?
第三方银行转账,提现的时间我们假设是2小时以内完成转账。可以引入消息队列进行异步处理。