深度学习笔记之LSTM轻量级变体——门控循环单元[GRU]
引言
上一节介绍了从反向传播过程的角度认识 LSTM \text{LSTM} LSTM如何抑制梯度消失的问题。本节以 LSTM \text{LSTM} LSTM的问题为引,介绍它的一种轻量级变体——门控循环单元。
回顾: LSTM \text{LSTM} LSTM的前馈计算过程
关于 LSTM \text{LSTM} LSTM的结构展开图与前馈计算过程表示如下:

对应一个单元 ( Cell ) (\text{Cell}) (Cell)的前馈计算过程:
{ f ( t ) = σ [ W H ⇒ F ⋅ h ( t − 1 ) + W X ⇒ F ⋅ x ( t ) + b F ] i ( t ) = σ [ W H ⇒ I ⋅ h ( t − 1 ) + W X ⇒ I ⋅ x ( t ) + b I ] C ~ ( t ) = Tanh [ W H ⇒ C ~ ⋅ h ( t − 1 ) + W X ⇒ C ~ ⋅ x ( t ) + b C ~ ] C ( t ) = f ( t ) ∗ C ( t − 1 ) + i t ∗ C ~ ( t ) o ( t ) = σ [ W H ⇒ O ⋅ h ( t − 1 ) + W X ⇒ O ⋅ x ( t ) + b O ] h ( t ) = o ( t ) ∗ Tanh ( C ( t ) ) \begin{cases} \begin{aligned} & f^{(t)} = \sigma \left[\mathcal W_{\mathcal H \Rightarrow \mathcal F} \cdot h^{(t-1)} + \mathcal W_{\mathcal X \Rightarrow \mathcal F} \cdot x^{(t)} + b_{\mathcal F}\right] \\ & i^{(t)} = \sigma \left[\mathcal W_{\mathcal H \Rightarrow \mathcal I} \cdot h^{(t-1)} + \mathcal W_{\mathcal X \Rightarrow \mathcal I} \cdot x^{(t)} + b_{\mathcal I}\right] \\ & \widetilde{\mathcal C}^{(t)} = \text{Tanh} \left[\mathcal W_{\mathcal H \Rightarrow \widetilde{\mathcal C}} \cdot h^{(t-1)} + \mathcal W_{\mathcal X \Rightarrow \widetilde{\mathcal C}} \cdot x^{(t)} + b_{\widetilde{\mathcal C}}\right] \\ & \mathcal C^{(t)} = f^{(t)} * \mathcal C^{(t-1)} + i_t * \widetilde{\mathcal C}^{(t)} \\ & o^{(t)} = \sigma \left[\mathcal W_{\mathcal H \Rightarrow \mathcal O} \cdot h^{(t-1)} + \mathcal W_{\mathcal X \Rightarrow \mathcal O} \cdot x^{(t)} + b_{\mathcal O}\right] \\ & h^{(t)} = o^{(t)} * \text{Tanh}(\mathcal C^{(t)}) \end{aligned} \end{cases} ⎩ ⎨ ⎧f(t)=σ[WH⇒F⋅h(t−1)+WX⇒F⋅x(t)+bF]i(t)=σ[WH⇒I⋅h(t−1)+WX⇒I⋅x(t)+bI]C (t)=Tanh[WH⇒C ⋅h(t−1)+WX⇒C ⋅x(t)+bC ]C(t)=f(t)∗C(t−1)+it∗C (t)o(t)=σ[WH⇒O⋅h(t−1)+WX⇒O⋅x(t)+bO]h(t)=o(t)∗Tanh(C(t))
对应的权重参数有:
θ = { W H ⇒ ⋅ : W H ⇒ F , W H ⇒ I , W H ⇒ C ~ , W H ⇒ O W X ⇒ ⋅ : W X ⇒ F , W X ⇒ I , W X ⇒ C ~ , W X ⇒ O b : b F , b I , b O , b C ~ \theta = \begin{cases} \mathcal W_{\mathcal H \Rightarrow \cdot} :\mathcal W_{\mathcal H \Rightarrow \mathcal F},\mathcal W_{\mathcal H \Rightarrow \mathcal I},\mathcal W_{\mathcal H \Rightarrow \widetilde{\mathcal C}},\mathcal W_{\mathcal H \Rightarrow \mathcal O} \\ \mathcal W_{\mathcal X \Rightarrow \cdot }:\mathcal W_{\mathcal X \Rightarrow \mathcal F},\mathcal W_{\mathcal X \Rightarrow \mathcal I},\mathcal W_{\mathcal X \Rightarrow \widetilde{\mathcal C}},\mathcal W_{\mathcal X \Rightarrow \mathcal O} \\ b:b_{\mathcal F},b_{\mathcal I},b_{\mathcal O},b_{\widetilde{\mathcal C}} \end{cases} θ=⎩ ⎨ ⎧WH⇒⋅:WH⇒F,WH⇒I,WH⇒C ,WH⇒OWX⇒⋅:WX⇒F,WX⇒I,WX⇒C ,WX⇒Ob:bF,bI,bO,bC
该结构相比于循环神经网络 ( Recurrent Neural Network,RNN ) (\text{Recurrent Neural Network,RNN}) (Recurrent Neural Network,RNN)在反向传播过程中,每一个时刻的前项传递过程,对应的参数均会有指数级别的梯度传播路径,并且反向传播过程中各门控结构的输出直接参与反向传播的计算。这种方式有效抑制了梯度消失问题——从梯度累加数量与门控结构的调节角度都可以使各时刻有梯度进行反向传播。
LSTM \text{LSTM} LSTM的问题
虽然 LSTM \text{LSTM} LSTM能够抑制梯度消失问题,但需要以增加时间复杂度和空间复杂度作为代价:
- 梯度越向初始时刻方向传播,关于各参数梯度的累加项越多(指数级别增长),它的梯度计算过程越困难;
- 相比于循环神经网络的权重参数, LSTM \text{LSTM} LSTM需要消耗更多的内存空间存储并更新参数信息。
这里与LSTM \text{LSTM} LSTM的部分相对应,仅描述‘序列信息传递过程’。
θ r = { W H ⇒ H , W X ⇒ H , b H } \theta_r = \{\mathcal W_{\mathcal H \Rightarrow \mathcal H},\mathcal W_{\mathcal X \Rightarrow \mathcal H},b_{\mathcal H}\} θr={WH⇒H,WX⇒H,bH}
并且包含更多类型参数的模型也会更加复杂。从而可能导致过拟合( Overfitting \text{Overfitting} Overfitting)的现象发生。基于此,我们观察门控循环单元 ( Gated Recurrent Unit,GRU ) (\text{Gated Recurrent Unit,GRU}) (Gated Recurrent Unit,GRU)是如何优化该问题的。
GRU \text{GRU} GRU的前馈计算过程
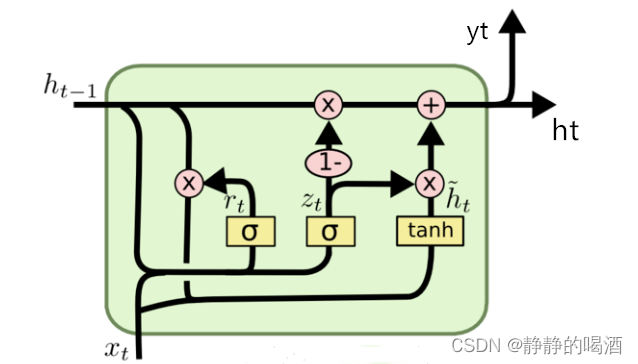
关于 GRU \text{GRU} GRU的前馈计算过程表示如下:
{ Z ( t ) = σ [ W H ⇒ Z ⋅ h ( t − 1 ) + W X ⇒ Z ⋅ x ( t ) + b Z ] r ( t ) = σ [ W H ⇒ r ⋅ h ( t − 1 ) + W X ⇒ r ⋅ x ( t ) + b r ] h ~ ( t ) = Tanh [ W H ⇒ H ~ ⋅ ( r ( t ) ∗ h ( t − 1 ) ) + W X ⇒ H ~ ⋅ x ( t ) + b H ~ ] h ( t ) = ( 1 − Z ( t ) ) ∗ h ( t − 1 ) + Z ( t ) ∗ h ~ ( t ) \begin{cases} \begin{aligned} & \mathcal Z^{(t)} = \sigma \left[\mathcal W_{\mathcal H \Rightarrow \mathcal Z} \cdot h^{(t-1)} + \mathcal W_{\mathcal X \Rightarrow \mathcal Z} \cdot x^{(t)} + b_{\mathcal Z}\right] \\ & r^{(t)} = \sigma \left[\mathcal W_{\mathcal H \Rightarrow r} \cdot h^{(t-1)} + \mathcal W_{\mathcal X \Rightarrow r} \cdot x^{(t)} + b_r\right] \\ & \widetilde{h}^{(t)} = \text{Tanh} \left[\mathcal W_{\mathcal H \Rightarrow \widetilde{\mathcal H}} \cdot (r^{(t)} * h^{(t-1)}) + \mathcal W_{\mathcal X \Rightarrow \widetilde{\mathcal H}} \cdot x^{(t)} + b_{\widetilde{\mathcal H}}\right] \\ & h^{(t)} = (1 - \mathcal Z^{(t)}) * h^{(t-1)} + \mathcal Z^{(t)} * \widetilde{h}^{(t)} \end{aligned} \end{cases} ⎩ ⎨ ⎧Z(t)=σ[WH⇒Z⋅h(t−1)+WX⇒Z⋅x(t)+bZ]r(t)=σ[WH⇒r⋅h(t−1)+WX⇒r⋅x(t)+br]h (t)=Tanh[WH⇒H ⋅(r(t)∗h(t−1))+WX⇒H ⋅x(t)+bH ]h(t)=(1−Z(t))∗h(t−1)+Z(t)∗h (t)
从结构图与公式角度观察 GRU \text{GRU} GRU和 LSTM \text{LSTM} LSTM之间的差别:
- 相比于 LSTM \text{LSTM} LSTM, GRU \text{GRU} GRU删除了细胞状态 ( Cell State ) (\text{Cell State}) (Cell State),和循环神经网络相同,只有一种序列信息 h ( t ) ( t = 1 , 2 , ⋯ , T ) h^{(t)}(t=1,2,\cdots,\mathcal T) h(t)(t=1,2,⋯,T)在各时刻之间传递;
- 相比于 LSTM \text{LSTM} LSTM, GRU \text{GRU} GRU少了一个门控结构,从而减少了一对权重矩阵 W H ⇒ ⋅ , W X ⇒ ⋅ \mathcal W_{\mathcal H \Rightarrow \cdot},\mathcal W_{\mathcal X \Rightarrow \cdot} WH⇒⋅,WX⇒⋅和偏置项 b . b_. b.;
其中 Z ( t ) \mathcal Z^{(t)} Z(t)被称作更新门 ( Update Gate ) (\text{Update Gate}) (Update Gate); r ( t ) r^{(t)} r(t)被称作重置门 ( Reset Gate ) (\text{Reset Gate}) (Reset Gate)。 LSTM \text{LSTM} LSTM和 GRU \text{GRU} GRU在逻辑上的核心区别有:
-
在 LSTM \text{LSTM} LSTM,各门控结构 f ( t ) , i ( t ) , o ( t ) f^{(t)},i^{(t)},o^{(t)} f(t),i(t),o(t)与细胞状态 C ~ ( t ) \widetilde{\mathcal C}^{(t)} C (t)之间的训练过程相互独立;仅在融合过程中对各神经元的输出分布进行运算:
上述4 4 4个隐变量中的输入均是h ( t − 1 ) , x ( t ) h^{(t-1)},x^{(t)} h(t−1),x(t);并且学习过程中,各神经元互不干扰。
C ( t ) = f ( t ) ∗ C ( t − 1 ) + i t ∗ C ~ ( t ) h ( t ) = o ( t ) ∗ Tanh ( C ( t ) ) \mathcal C^{(t)} = f^{(t)} * \mathcal C^{(t-1)} + i_t * \widetilde{\mathcal C}^{(t)} \\ h^{(t)}= o^{(t)} * \text{Tanh}(\mathcal C^{(t)}) C(t)=f(t)∗C(t−1)+it∗C (t)h(t)=o(t)∗Tanh(C(t)) -
在 GRU \text{GRU} GRU的细胞单元中,关于当前时刻的候选状态 h ~ ( t ) \widetilde{h}^{(t)} h (t)的训练过程中,其输入就已经被挑选过了:
h ~ ( t ) = Tanh [ W H ⇒ H ~ ⋅ ( r ( t ) ∗ h ( t − 1 ) ) + W X ⇒ H ~ ⋅ x ( t ) + b H ~ ] \widetilde{h}^{(t)} = \text{Tanh} \left[\mathcal W_{\mathcal H \Rightarrow \widetilde{\mathcal H}} \cdot (r^{(t)} * h^{(t-1)}) + \mathcal W_{\mathcal X \Rightarrow \widetilde{\mathcal H}} \cdot x^{(t)} + b_{\widetilde{\mathcal H}}\right] h (t)=Tanh[WH⇒H ⋅(r(t)∗h(t−1))+WX⇒H ⋅x(t)+bH ]
很明显, r ( t ) ∗ h ( t − 1 ) r^{(t)} * h^{(t-1)} r(t)∗h(t−1)相当于仅将未被遗忘的序列信息进行训练,而 ( 1 − r ( t ) ) ∗ h ( t − 1 ) (1 - r^{(t)}) * h^{(t-1)} (1−r(t))∗h(t−1)就已经被遗忘了。基于这种机制,使得候选状态 h ~ ( t ) \widetilde{h}^{(t)} h (t)的分布结果比 C ~ ( t ) \widetilde{\mathcal C}^{(t)} C (t)更有价值(指向性)。逻辑上就没有必要再使用类似输入门结构对其进行约束了。
一个是对‘输出分布’进行挑选,另一个是在输入分布时进行挑选。虽然使用了更精炼的输入分布,但该神经元的作用依然是求解当前时刻候选信息的后验概率分布 P ( h ~ ( t ) ∣ h ( t − 1 ) , x ( t ) ) \mathcal P(\widetilde{h}^{(t)} \mid h^{(t-1)},x^{(t)}) P(h (t)∣h(t−1),x(t))。因此,和 LSTM \text{LSTM} LSTM一样,最终输出 h ( t ) h^{(t)} h(t)依然要对 h ( t − 1 ) h^{(t-1)} h(t−1)与 h ~ ( t ) \widetilde{h}^{(t)} h (t)进行重新配比。但是这个配比相比之下简单很多。因为: h ( t − 1 ) h^{(t-1)} h(t−1)由各时刻的候选状态 h ~ ( t ) ( t = 1 , 2 , ⋯ ) \widetilde{h}^{(t)}(t=1,2,\cdots) h (t)(t=1,2,⋯)组成,而每个时刻求解候选状态 h ~ ( t ) \widetilde{h}^{(t)} h (t)的过程中,均已经将不必要的信息进行遗忘,因而不需要再对 h ( t − 1 ) h^{(t-1)} h(t−1)再执行遗忘:
h ( t ) = ( 1 − Z ( t ) ) ∗ h ( t − 1 ) + Z ( t ) ∗ h ~ ( t ) h^{(t)} = (1 - \mathcal Z^{(t)}) * h^{(t-1)} + \mathcal Z^{(t)} * \widetilde{h}^{(t)} h(t)=(1−Z(t))∗h(t−1)+Z(t)∗h (t)个人理解:
输入门 i ( t ) i^{(t)} i(t)是遗忘门 f ( t ) f^{(t)} f(t)的对称操作。
在 LSTM \text{LSTM} LSTM中,对于过去时刻的序列信息 C ( t − 1 ) \mathcal C^{(t-1)} C(t−1)和候选信息 C ~ ( t ) \widetilde{\mathcal C}^{(t)} C (t):
{ C ( t − 1 ) = f ( t − 1 ) ∗ C ( t − 2 ) + i ( t − 1 ) ∗ C ~ ( t − 1 ) C ~ ( t ) = Tanh [ W h ( t − 1 ) ⇒ C ~ ( t ) ⋅ h ( t − 1 ) + W x ( t ) ⇒ C ~ ( t ) ⋅ x ( t ) + b C ~ ] \begin{cases} \mathcal C^{(t-1)} = f^{(t-1)} * \mathcal C^{(t-2)} + i^{(t-1)} * \widetilde{\mathcal C}^{(t-1)} \\ \widetilde{\mathcal C}^{(t)} = \text{Tanh} \left[\mathcal W_{h^{(t-1)} \Rightarrow\widetilde{\mathcal C}^{(t)}} \cdot h^{(t-1)} + \mathcal W_{x^{(t)} \Rightarrow \widetilde{\mathcal C}^{(t)}} \cdot x^{(t)} + b_{\widetilde{\mathcal C}}\right] \end{cases} {C(t−1)=f(t−1)∗C(t−2)+i(t−1)∗C (t−1)C (t)=Tanh[Wh(t−1)⇒C (t)⋅h(t−1)+Wx(t)⇒C (t)⋅x(t)+bC ]
它们的输入均是 h ( τ ) , x ( τ ) ( τ ∈ { 1 , 2 , ⋯ T } ) h^{(\tau)},x^{(\tau)}(\tau \in \{1,2,\cdots \mathcal T\}) h(τ),x(τ)(τ∈{1,2,⋯T}),因而在计算对应后验概率分布的过程中,它们到底使用哪些信息作为条件,我们是不可探究的;
其中x ( τ ) x^{(\tau)} x(τ)是输入特征,不作考虑;但h ( τ ) h^{(\tau)} h(τ)作为序列信息,在表示C ( t − 1 ) . C ~ ( t ) \mathcal C^{(t-1)}.\widetilde{\mathcal C}^{(t)} C(t−1).C (t)后验的各神经元之间无交集,各自使用哪些‘过去信息’进行学习,未知,都有可能;
但 GRU \text{GRU} GRU中, h ( t − 1 ) , h ~ ( t ) h^{(t-1)},\widetilde{h}^{(t)} h(t−1),h (t)的输入均是被挑选(未被遗忘)的优质信息,导致它们的后验分布相比于之前的不可探究,更有指向性。因此,遗忘门和输入门这一对相辅相成的门控结构都被省略掉了。
而 Z ( t ) \mathcal Z^{(t)} Z(t)不是输入门,它仅仅是在 Sigmoid \text{Sigmoid} Sigmoid激活函数的值域 ( 0 , 1 ) (0,1) (0,1)下,权衡 h ( t − 1 ) h^{(t-1)} h(t−1)与 h ~ ( t ) \widetilde{h}^{(t)} h (t)之间比例关系的一个比率系数而已。其中 Z ( t ) \mathcal Z^{(t)} Z(t)仅表示学习出的一个比例系数;而 1 − Z ( t ) 1- \mathcal Z^{(t)} 1−Z(t)是基于 Sigmoid \text{Sigmoid} Sigmoid激活函数的值域描述的 Z ( t ) \mathcal Z^{(t)} Z(t)之外剩下的比例结果。将 h ( t − 1 ) h^{(t-1)} h(t−1)与 h ~ ( t ) \widetilde{h}^{(t)} h (t)之间的比例进行调整,并将最终的和作为输出。
GRU \text{GRU} GRU的优势
首先, GRU \text{GRU} GRU的参数更少,从而有效降低过拟合的风险;并且在反向传播的过程中,随着反向传播深度的加深,对应需要反向传播路径相比于 LSTM \text{LSTM} LSTM大量减少。从而减小了时间、空间复杂度的负担。


![[GUET-CTF2019]number_game[数独]](https://img-blog.csdnimg.cn/32229e01c27d4f5f90c7b4a8453436ba.png)