WARP
GPU的线程从thread grid 到thread block,一个thread block在CUDA Core上执行时,会分成warp执行,warp的颗粒度是32个线程。比如一个thread block可能有1024个线程,分成32个warp执行。

上图的CTA(cooperative thread arrays)即为thread block。
Warp内的32个线程是以lock-step的方式锁步执行,也就是在没有遇到分支指令的情况下,如果执行,那么执行的都是相同的指令。通过这种方式32个线程可以共享pc,源寄存器ID和目标寄存器ID。
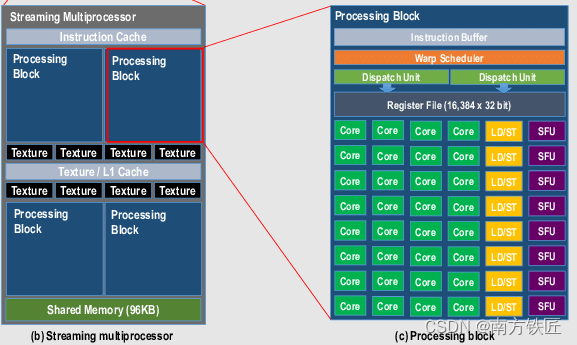
虽然warp是以32的颗粒度,但是具体在GPU内部执行时,也可能是以16的颗粒度,分两次执行,比如早期的fermi架构。
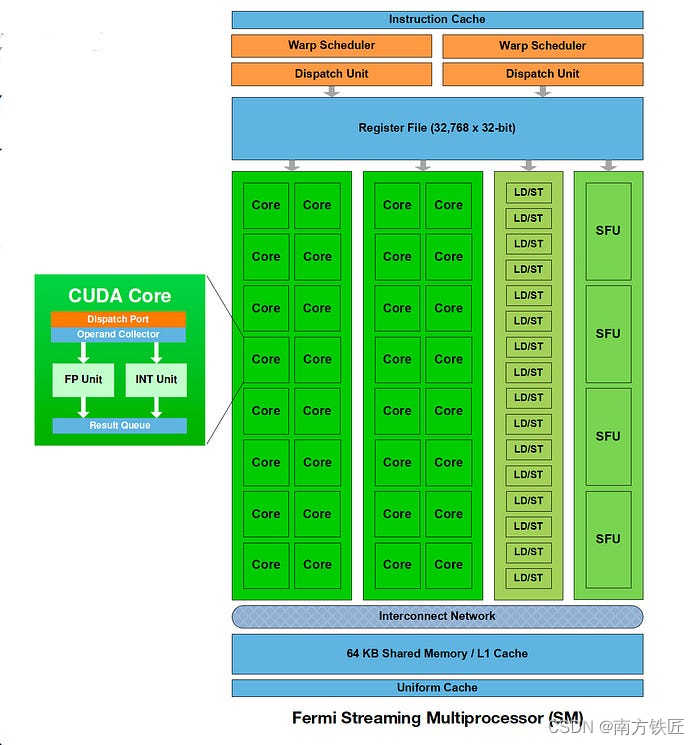
如上图所示,两个warp scheduler,每个warp每次只能在16个CUDA core上执行。
后续的Pascal GPU架构 CUDA core增加到了32个,每个周期都能执行一个warp。
寄存器
GPU的寄存器数量是影响划分CUDA thread block的数量的原因之一。

虽然内部执行是按照warp执行的,按照调度顺序和ready进行调度。但是寄存器的分配是静态的按照thread number分配的,而不是warp。在warp执行时,32个线程,每个线程读取源寄存器,写入目标寄存器。假设每个寄存器4B,那么每次32个线程读取128B。
因而128B也就是GPU L1 Cache Cacheline的大小。不同于CPU,每一级的cache都要维护MOSEI的一致性,对于GPU的thread来说,私有memory不需要共享,因此对于local memory可以write back。而全局共享memory则可以write evict。
CPU的寄存器,在编译器编译时,会根据寄存器的live time进行优化,而且在CPU内部执行时,进行重命名,在有限的寄存器数量上尽量的解决依赖问题。GPU只在编译时优化,尽量减少对memory的使用,在内部执行时,如果针对每个warp都增加一个寄存器重命名单元,设计复杂。因此GPU每个线程需要的寄存器就是它编译时需要的寄存器上限(寄存器上限也可以通过编译器控制)。这就导致了实际GPU内部执行时对寄存器使用数量的波动。如下图所示,因此也有很多文章研究如何优化寄存器的使用。

在编译时,nvcc可以通过指定--maxrregcount指定寄存器的数量,但是过多的寄存器会因为固定的寄存器资源而导致thread数量变少,过少的寄存器也会导致需要频繁的访问memory,因此也需要折衷。

WARP Divergence
之前讨论warp时说如果32个线程,没有遇到分支,那么每个线程都执行同一条指令,但是如果存在分支呢?
GPU没有CPU的分支预测,使用active mask和predicate register来构建token stack来处理遇到分支时的问题。
GPGPU-sim按照下图模拟的token stack,其中的
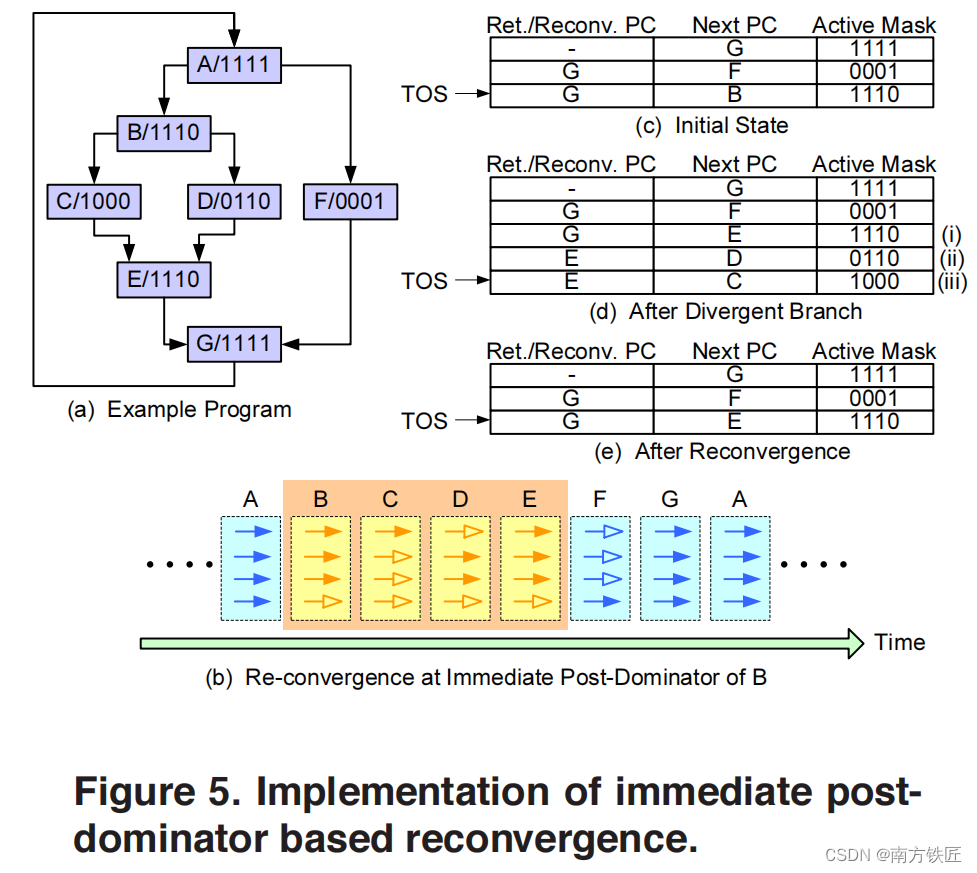
另一种可能的token stack则是按照如下的方式构建,结合了指令,predicate register和token stack。

上图中的(b)即为编译出的汇编指令,SSY 0xF0即为push stack,if else分支指令结束重聚的指令地址为0xF0。每个warp会有当前的active pc寄存器和active mask寄存器。我们假设一个warp内有8个thread,在SSY 0xF0指令执行时,会将active mask 压栈,压栈的内容包括Fig1 中的entry type SSY,active mask和re-convergence pc,也就是0xF0(从SSY 0xF0指令可以获得).
在分支指令@PO BRA 0xB8执行时,会将DIV(divergence),active mask(0xF0,这个并非pc,而是active mask,当前warp的每个thread的predicate register拼接而成,8bit 每个bit表示一个thread是否满足if条件) 和 0xB8(if语句块内的第一条指令的地址)压栈。
然后gpu会默认执行else分支(因为if需要跳转,else直接顺序执行),执行else分支时,需要对active mask取反,只执行不满足if条件的那些thread。
Else分支的最后一条汇编指令末尾会增加.S flag用于标志pop stack,此时pop指令会将active mask出栈,更新到active mask寄存器和active pc中,然后执行if 分支,直到执行完毕if内的最后一条指令,对应地址0xE8,此时再次出栈。
将当前active pc更新为0xF0,active mask更新为0xFF,此时if else分支执行完毕,回到重聚点,所有线程继续lock-step锁步执行。
这里只假设一个if else,但是实际上可能存在if else的嵌套,因此第一步SSY 0xF0,可以理解成上下文切换时的先保存当前的active mask。
上述的方案与GPGPU-sim中的架构类似,除了在指令中显式的增加了压栈出栈。
1. https://www.bu.edu/pasi/files/2011/07/Lecture2.pdf
- 2.Dynamic Warp Formation and Scheduling for Effificient GPU Control Flow
3. RegMutex: Inter-Warp GPU Register Time-Sharing
4. Analyzing Graphics Processor Unit (GPU) Instruction Set Architectures