在PyTorch中,Dataset和DataLoader是用于处理数据的两个重要类。Dataset类是一个抽象类,用于表示数据集。它的主要作用是将数据加载到内存中,并提供一种统一的方式来访问数据。为了使用Dataset类,你需要继承它并实现两个方法:__len__和__getitem__。__len__方法返回数据集的大小,__getitem__方法根据给定的索引返回数据集中的一个样本。下面是一个简单的自定义Dataset类的例子:```python from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self, data):self.data = datadef __len__(self):return len(self.data)def __getitem__(self, index):return self.data[index] ```DataLoader类是用于加载数据的迭代器。它可以将Dataset类的实例作为输入,并提供一种方便的方式来迭代数据。DataLoader类还提供了一些有用的功能,如数据的批处理、数据的随机打乱和多线程数据加载等。下面是一个简单的使用DataLoader的例子:```python from torch.utils.data import DataLoaderdataset = MyDataset(data) dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)for batch in dataloader:# 在这里进行训练或推理操作pass ```在上面的例子中,我们首先创建了一个MyDataset的实例,并将其传递给DataLoader类。我们还指定了批处理大小为32,打乱数据集并使用4个线程加载数据。然后,我们可以使用for循环迭代DataLoader对象,每次迭代都会返回一个批次的数据。这是Dataset和DataLoader的基本用法。你可以根据自己的需求对它们进行更多的定制和扩展。
8.12学习笔记
news/2024/11/16 21:48:03/
相关文章

湘大 XTU OJ:1406 String Game、1098 素数个数 题解(非常详细)
1406 String Game
一、链接
1406 String Game
二、题目
题目描述
Alice和Bob正在玩一个基于字符串的游戏,一开始,Alice和Bob分别拥有一个等长的字符串S1和S2,且这两个字符串只包含小写字母。 在每个回合中,Alice和Bob必须分…

【C语言练习】——找出单身狗、详解atoi函数
目录 一.找出单身狗版本1版本2 二.atoi函数介绍atoi函数atoi函数的模拟实现 一.找出单身狗
版本1 题目: 一个数组中只有一个数字是出现一次,其他所有数字都出现了两次 找出这一个只出现一次的数字 一个数组比如是1、2、3、4、5、1、2、3、4 只有5出现一…
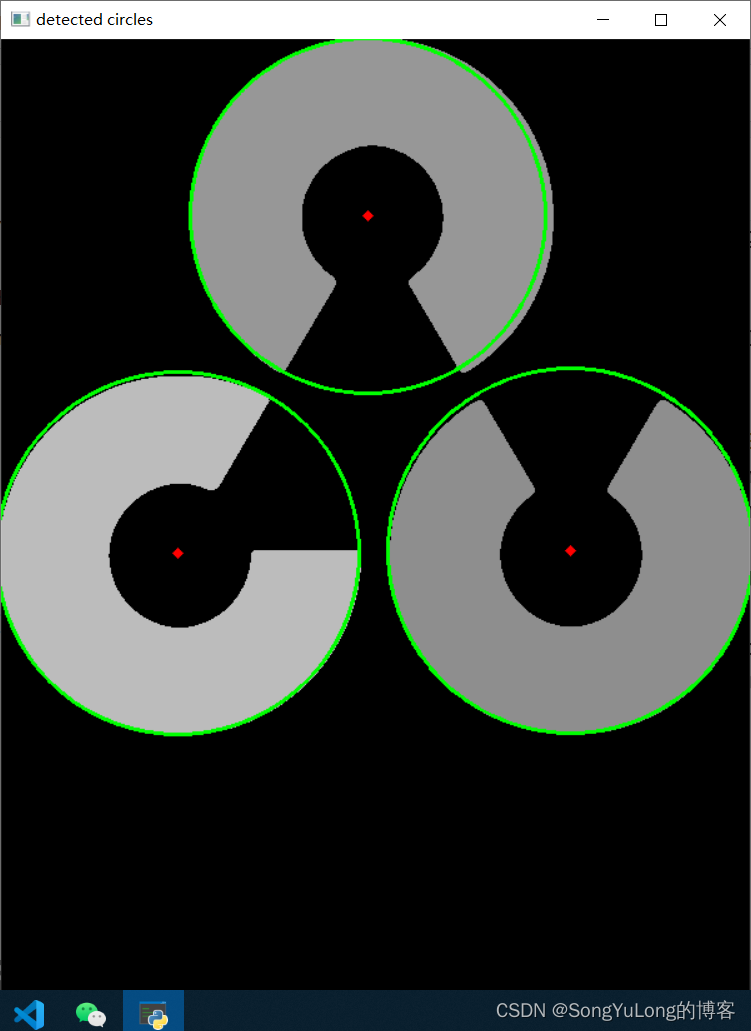
Python-OpenCV中的图像处理-霍夫变换
Python-OpenCV中的图像处理-霍夫变换 霍夫变换霍夫直线变换霍夫圆环变换 霍夫变换
霍夫(Hough)变换在检测各种形状的技术中非常流行,如果要检测的形状可以用数学表达式描述,就可以是使用霍夫变换检测它。即使要检测的形状存在一点破坏或者扭曲也是可以使…
阿里云账号注册入口_账户注册详细流程(图文)
阿里云账号怎么注册?阿里云账号支持手机号注册、阿里云APP注册、支付宝和钉钉多种注册方式,账号注册后需要通过实名认证才可以购买或使用云产品,阿里云百科来详细说下不同途径注册阿里云账号图文流程:
目录
阿里云账号注册流程 …
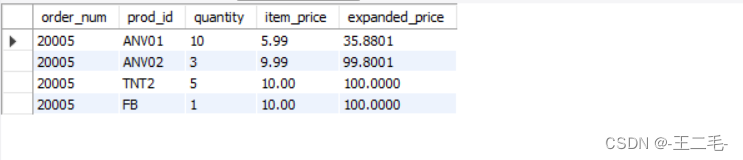
MySql012——检索数据:创建计算字段(拼接字段、使用别名、执行算术计算)
准备工作1:在study库中创建表vendors,并插入数据 说明:vendors表包含供应商名和位置信息。 use study;CREATE TABLE vendors
(vend_id int NOT NULL AUTO_INCREMENT,vend_name char(50) NOT NULL ,vend_address char(50) NULL ,…
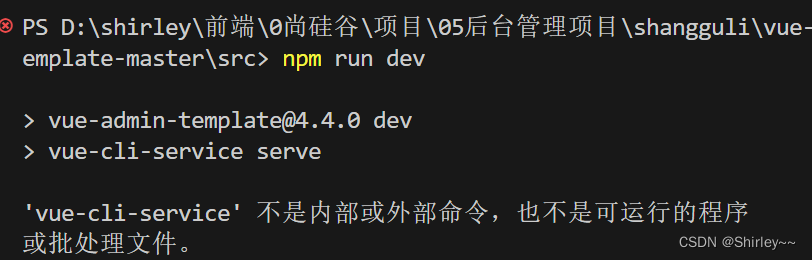
vue报错‘vue-cli-service‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件。
运行我的后台管理项目的时候报错:‘vue-cli-service’ 不是内部或外部命令,也不是可运行的程序或批处理文件。 查看自己package.json中是否有vue 或者vue-cli-service 查看自己项目目录下有没有node_module文件夹,如果有删除,然后…
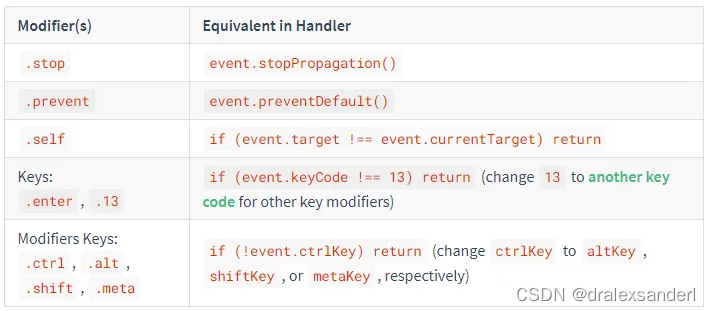
vue中有趣的几个功能
vue中有趣的几个功能
老实说,我们大多数人都不太喜欢阅读文档,但是当使用像 Vue 这样不断发展的现代前端框架时,每个新版本都会发生很多变化,我们可能会错过一些后来推出的新的、闪亮的功能。让我们来看看那些有趣但不那么受欢迎…

删除块参照 删除块定义
删除块参照
void CDwgDatabaseUtil::DeleteBlockReference(CString strBlockName)
{// 锁定文档acDocManager->lockDocument(acDocManager->curDocument());AcDbObjectId objRecId;if (