💓博主个人主页:不是笨小孩👀
⏩专栏分类:数据结构与算法👀 刷题专栏👀 C语言👀
🚚代码仓库:笨小孩的代码库👀
⏩社区:不是笨小孩👀
🌹欢迎大家三连关注,一起学习,一起进步!!💓

二叉树
- 二叉树的性质
- 二叉树的链式结构
- 二叉树的遍历
- 前序遍历
- 中序遍历
- 后序遍历
- 层序遍历
- 二叉树的销毁
- 二叉树的查找
二叉树的性质
1.若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1) 个结点.
2. 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是 2^h-1.
3. 对任何一棵二叉树, 如果度为0其叶结点个数为n0 , 度为2的分支结点个数为02 ,则有n0 =n2 +1
4. 若规定根节点的层数为1,具有n个结点的满二叉树的深度,h= . (ps: 是log以2为底,n+1为对数)
5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对于序号为i的结点有:
- 若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
- 若2i+1<n,左孩子序号:2i+1,2i+1>=n否则无左孩子
- 若2i+2<n,右孩子序号:2i+2,2i+2>=n否则无右孩子
二叉树的链式结构
一般来说,二叉树分为二叉链和三叉链,二叉链就是结构里面一个左孩子节点,一个右孩子节点,三叉链多了一个父亲节点,我们比较经常见的都是二叉链的,所以我们主要讲的也是二叉链。
结构:
typedef int BTDataType;typedef struct BinaryTreeNode
{BTDataType data;struct BinaryTreeNode* left;struct BinaryTreeNode* right;
}BTNode;我们在看任意一颗二叉树时,都可以将它分为三部分,根,左子树,右子树,左子树也可看成根,左子树,右子树,右子树也可看成根,左子树,右子树,因此二叉树定义是递归式的,我们后面的代码也是主要靠递归来实现的。
二叉树的遍历
二叉树遍历(Traversal)是按照某种特定的规则,依次对二叉树中的节点进行相应的操作,并且每个节点只操作一次。
二叉树的遍历分为,前序遍历、中序遍历、后序遍历、层序遍历,其中前中后序遍历是递归定义的,而层序遍历是非递归遍历的。
前序遍历
前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点的操作发生在遍历其左右子树之前。前序先访问根节点,再访问左子树,再访问右子树。
代码如下:
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root)
{if (root == NULL){return;}printf("%d ", root->data);BinaryTreePrevOrder(root->left);BinaryTreePrevOrder(root->right);
}
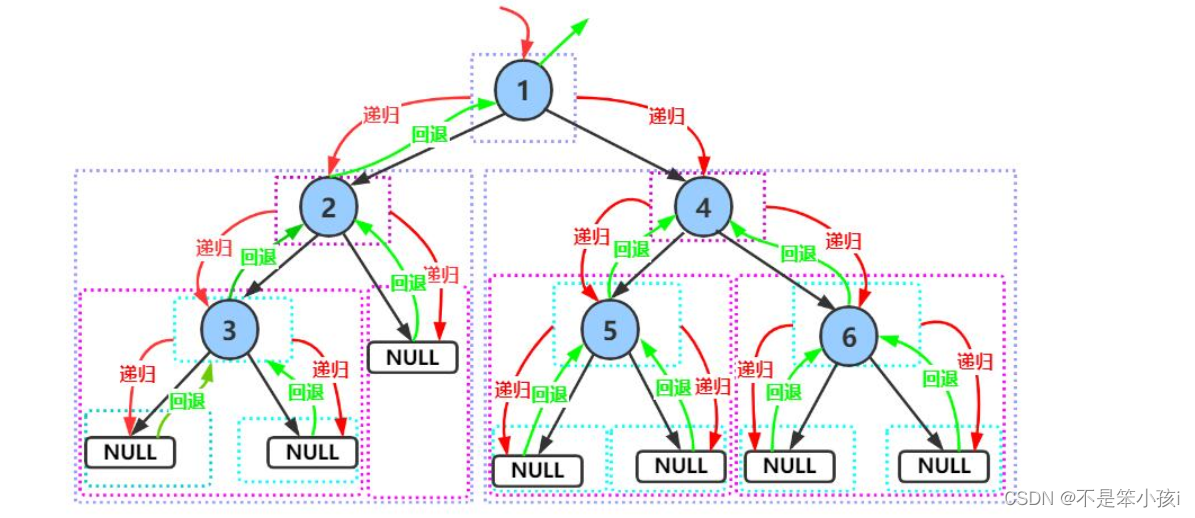
递归图:
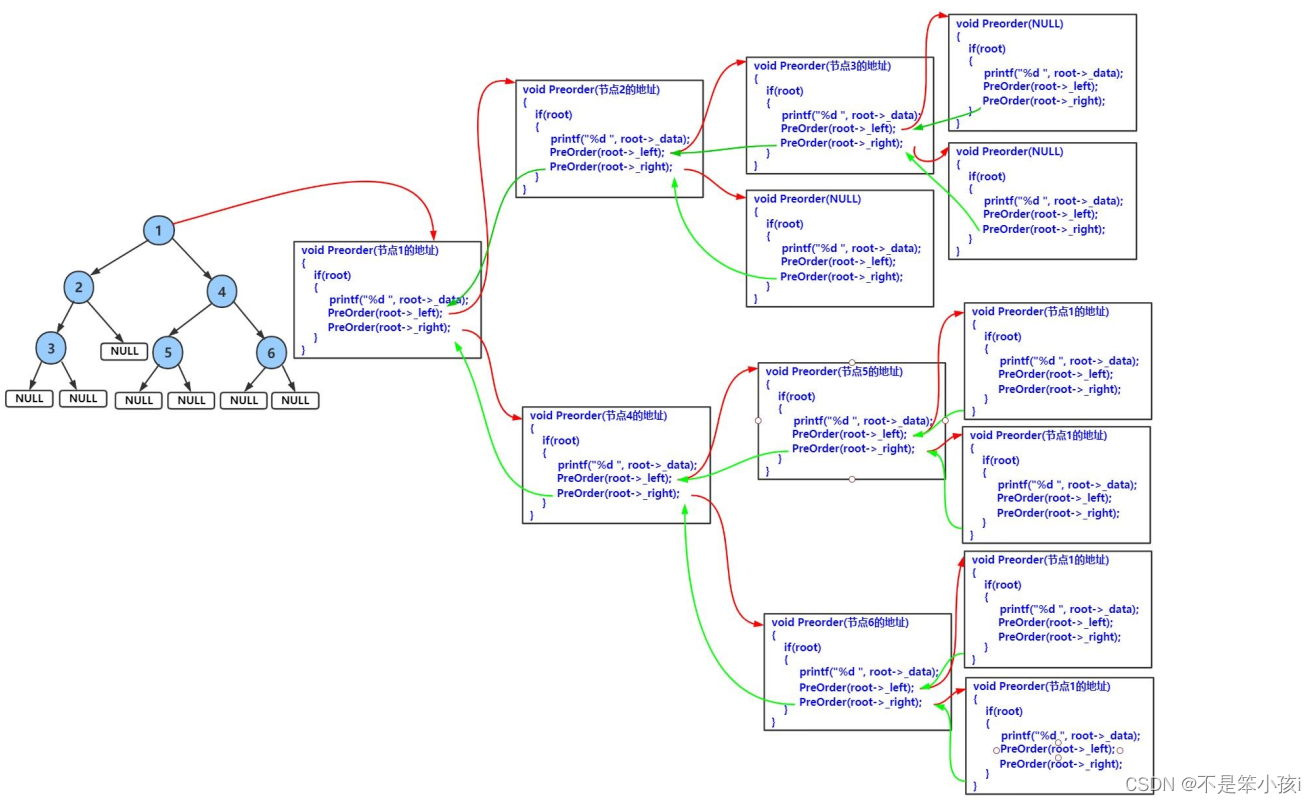
大家可以根据这个递归展开图好好理解一下,后面的二叉树基本操作都是需要用递归来实现的。
中序遍历
中序遍历(Inorder Traversal)——访问根结点的操作发生在遍历其左右子树之中(间)。
代码如下:
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root)
{if (root == NULL){return;}BinaryTreeInOrder(root->left);printf("%d ", root->data);BinaryTreeInOrder(root->right);}
后序遍历
后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。
代码如下:
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root)
{if (root == NULL){return;}BinaryTreePostOrder(root->left);BinaryTreePostOrder(root->right);printf("%d ", root->data);
}
这三种遍历本质上都是一样的,理解清楚一个,另外两个就很简单了。
层序遍历
层序遍历和其他三种都不一样,设二叉树的根节点所在层数为1,层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左右访问第2层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
那这个要怎么实现呢?
我们需要借助我们的队列,我们可以先把根节点入到队列里,然后开始出队列,只不过每次出的时候如果它的左孩子不为空就将左孩子入队列,右孩子不为空就将右孩子入队列,以此类推。我们就是利用了队列的先进先出,我们就可以轻松地完成层序遍历。
代码如下:
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root)
{Queue q;QueueInit(&q);if (root){QueuePush(&q,root);}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front->left){QueuePush(&q, front->left);}if (front->right){QueuePush(&q, front->right);}printf("%d ", front->data);}printf("\n");
}
二叉树的销毁
二叉树的销毁很简单,我们需要遍历一遍二叉树,但是我们用那种遍历呢,如果用前序,那么就会销毁根节点,就找不到它的左孩子和右孩子,明显是不合适的,最好的情况就是我们先去销毁它的左孩子,再去销毁他的右孩子,然后再销毁根节点,所以这里我们使用后序遍历是比较合适的。
代码如下:
// 二叉树销毁
void BinaryTreeDestory(BTNode* root)
{if (root == NULL){return;}BinaryTreeDestory(root->left);BinaryTreeDestory(root->right);free(root);
}
二叉树的查找
二叉树的查找的基本思路也是遍历一遍二叉树,但是我们需要返回这个节点,这就给我们的难度增加了很多,我们这里想的是先看根节点是不是,如果不是就去他的左子树找,如果找到了就返回,否则就去它的右子树找,找到就返回该节点,最后都找不到我们就返回NULL.
代码如下:
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (root == NULL){return NULL;}if (root->data == x){return root;}BTNode* left = BinaryTreeFind(root->left, x);if (left != NULL){return left;}BTNode* right = BinaryTreeFind(root->right, x);if (right != NULL){return right;}return NULL;
}
最后带大家看一下会给我们带来好运的树:

今天的分享就到这里,感谢大家的关注和支持!