merge、join以及concat的方法的不同以及相同
相同之处:都用于合并数据。 不同之处:
merge主要是基于列的合并。join主要是基于索引(行标签)的合并。concat可以沿任意轴合并,更灵活。
import pandas as pddf1 = pd.DataFrame({'A': ['A0', 'A1'], 'B': ['B0', 'B1']})
df2 = pd.DataFrame({'A': ['A2', 'A3'], 'B': ['B2', 'B3']})
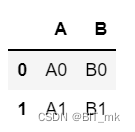

merge
result = pd.merge(df1, df2, on='A', how='outer')
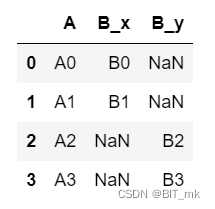
join
df1 = df1.set_index('A')
df2 = df2.set_index('A')
result = df1.join(df2, lsuffix='_df1', rsuffix='_df2')
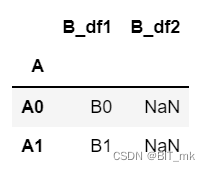
df1 = df1.set_index('A'):将df1的索引设置为"A"列,意味着后续的连接操作将基于这个列的值。df2 = df2.set_index('A'):同样地,将df2的索引设置为"A"列。result = df1.join(df2, lsuffix='_df1', rsuffix='_df2'):使用join方法将df1和df2连接在一起。参数lsuffix和rsuffix是必要的,因为两个DataFrame在设置索引后将具有相同的列名,这些后缀将添加到重叠列名中,以便区分来自哪个DataFrame。- 如果df2中A列中的值有与df1中A的值相同的则会连接在一起,否则将会补成nan
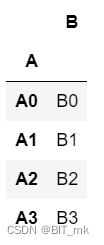
concat
result = pd.concat([df1, df2])
stack函数
stack的作用是重新塑造DataFrame,它将数据的列“堆叠”成行,生成一个MultiIndex Series,其中新的索引级别包括原始DataFrame的列名。这有助于将宽格式的数据转换为长格式,并常用于准备数据进行分析或可视化。
例如,如果原始DataFrame是:
A B
0 1 2
1 3 4
那么stack()的结果将是:
0 A 1B 2
1 A 3B 4
dtype: int64
agg函数
agg函数是Pandas库中的一个强大工具,用于聚合操作。它允许你同时对一个或多个列执行多种聚合操作。
使用agg函数,你可以一次执行例如求和、平均值、最小值和最大值等多种操作,并将结果组合成一个DataFrame。
以下是一个示例,说明如何使用agg函数:
import pandas as pd# 创建一个示例DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})# 对'A'列求和,对'B'列求最大值和最小值
result = df.agg({'A': 'sum','B': ['max', 'min']
})
结果是:
A B
max NaN 6.0
min NaN 4.0
sum 6.0 NaN
也可以对整个DataFrame调用agg并应用相同的聚合函数到每一列:
result = df.agg(['sum', 'mean']) A B
sum 6 15
mean 2.0 5.0
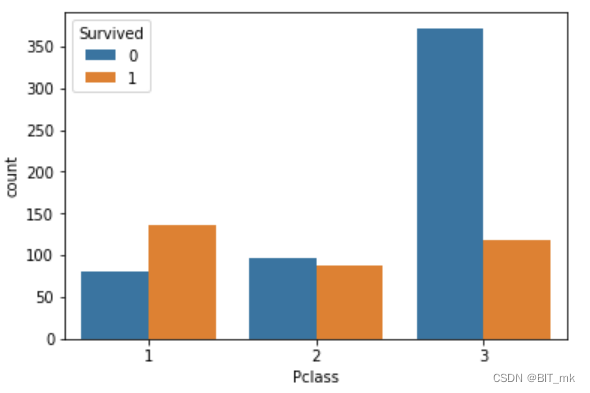
countplot--计算条形统计图
sns.countplot(x="Pclass", hue="Survived", data=text)-
x="Pclass":设置x轴上的变量为"Pclass"列。这意味着图形将显示该列中不同类别的计数。 -
hue="Survived":使用"Survived"列为图形着色,这样你就可以看到每个"Pclass"类别中"Survived"的不同值的计数。这可以帮助你理解"Pclass"和"Survived"之间的关系。 -
data=text:设置数据源为textDataFrame。这是你之前从CSV文件读取的数据。
FacetGrid
facet = sns.FacetGrid(text, hue="Survived",aspect=3)FacetGrid是一个用于创建一组图形的对象,这些图形可以根据一个或多个分类变量的不同级别展示数据。
-
facet = sns.FacetGrid():创建一个FacetGrid对象并将其赋值给变量facet。 -
text:第一个参数,指定要使用的DataFrame,这里是text。 -
hue="Survived":设置着色变量为"Survived"列。这意味着在网格内的每个小图中,不同的"Survived"值将使用不同的颜色表示。 -
aspect=3:设置每个小图的宽高比为3。这控制了每个小图的形状。
kdeplot--核密度估计图
facet.map(sns.kdeplot,'Age',shade= True)-
facet: 这是一个已经创建的FacetGrid对象,通常基于某个分类变量对数据进行分组。 -
.map(): 这是FacetGrid对象的方法,用于在网格的每个子集上绘制特定类型的图。 -
sns.kdeplot: 这是传递给map方法的绘图函数,用于在每个facet上绘制核密度估计图。 -
'Age': 这是传递给kdeplot的变量名,表示要绘制KDE图的DataFrame中的列名。 -
shade=True: 这是传递给kdeplot的一个参数,表示KDE图下方的区域将被填充或"阴影",使图形更容易阅读和解释。
facet.set
facet.set(xlim=(0, text['Age'].max()))这行代码设置了FacetGrid对象中每个子图的x轴范围。
-
facet: 这是一个已经创建的FacetGrid对象。 -
.set(): 这是FacetGrid对象的一个方法,用于设置网格属性。 -
xlim=(0, text['Age'].max()): 这是传递给set方法的一个参数,用于设置x轴的限制。0: x轴的起始值设置为0。text['Age'].max(): x轴的结束值设置为textDataFrame中'Age'列的最大值。
facet.add_legend()
facet.add_legend()facet.add_legend()是Seaborn库中FacetGrid对象的一个方法,用于在图的一个角落添加图例。
图例是一个包含一个或多个条目的区域,每个条目由一个标记(例如颜色块或线条)和一个标签组成。图例用于解释图中的符号和颜色代表的含义。
如果之前创建的FacetGrid对象facet基于某个分类变量进行着色(例如通过hue参数指定),那么调用facet.add_legend()将添加一个图例来解释这些颜色。
图例通常自动基于hue参数所代表的数据列的名称和唯一值生成。
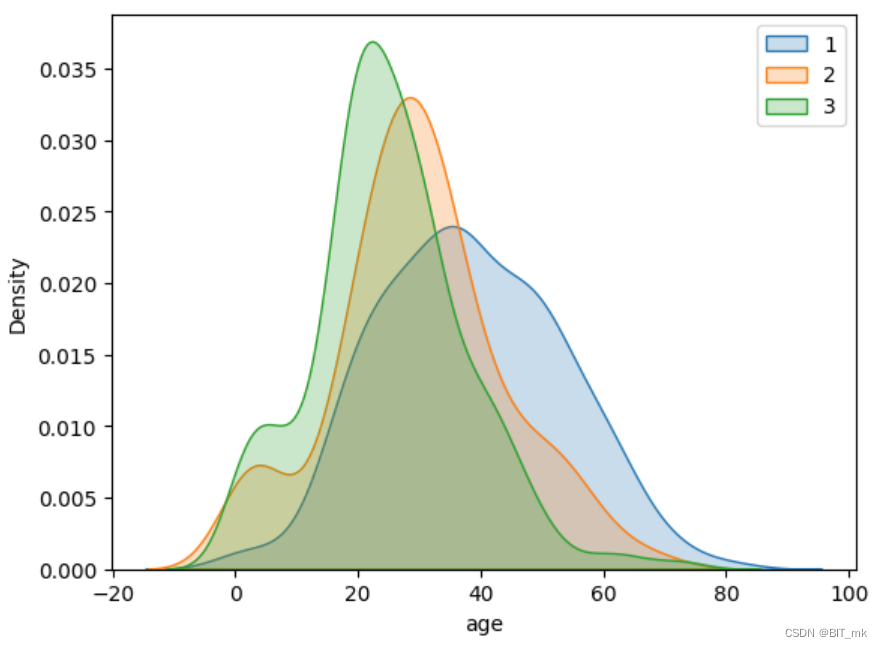
折线图表示年龄分布情况
text.Age[text.Pclass == 1].plot(kind='kde')
text.Age[text.Pclass == 2].plot(kind='kde')
text.Age[text.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")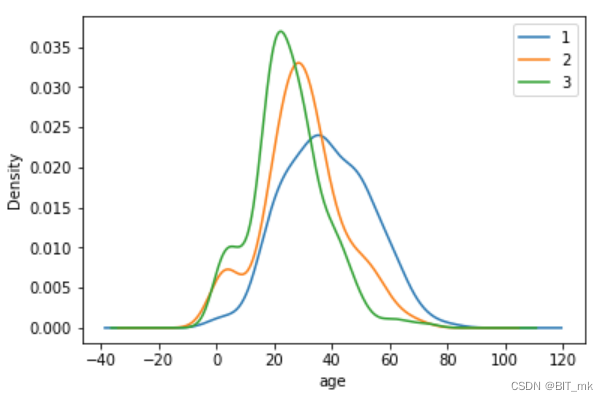
为什么所有的曲线都被添加到同一个图上:
-
没有新的图形或轴创建:如果你想在不同的图或轴上绘制,你通常会使用像
plt.figure()或plt.subplot()这样的函数来创建新的图或轴。在你的代码中,没有使用这些函数,所以所有的绘图都被添加到当前的图和轴上。 -
连续的绘图调用:当你连续调用
plot函数,matplotlib会在当前活动的轴上绘制。如果没有创建新的轴或图,那么连续的绘图调用将在同一个轴上绘制。 -
全局状态:matplotlib有一个全局状态机制,它跟踪当前的图、轴等。当你调用像
plt.plot()这样的函数时,它操作当前活动的图和轴。如果你不显式地改变活动的图或轴,连续的调用将在同一位置操作。
填充问题
具体地说,plot方法的kind='kde'选项并不直接接受shade参数。如果你想要控制阴影或填充KDE图下方的区域,你可以直接使用Seaborn的kdeplot函数,或者使用matplotlib的命令来手动填充。
import seaborn as sns
sns.kdeplot(text.Age[text.Pclass == 1], shade=True)
sns.kdeplot(text.Age[text.Pclass == 2], shade=True)
sns.kdeplot(text.Age[text.Pclass == 3], shade=True)
plt.xlabel("age")
plt.legend((1,2,3),loc="best")