2023年的深度学习入门指南(25) - 通义千问7b
最近发生的两件事情都比较有意思,一个是连续开源了7b和13b模型的百川,对其53b闭源了;另一个是闭源项目通义千问开源了自己的7b模型。
下面我们就来研究下通义千问7b.
使用通义千问7b
首先安装依赖库:
pip install transformers==4.31.0 accelerate tiktoken einops transformers_stream_generator bitsandbytes
通义千问7b的开源做得还是不错的,不光在自家的魔搭平台上可以用,而且也开放在了huggingface上,所以我们可以直接用huggingface的API来调用。
我们按照官方的三轮对话的例子:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfigtokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参# 第一轮对话 1st dialogue turn
response, history = model.chat(tokenizer, "你好", history=None)
print(response)# 第二轮对话 2nd dialogue turn
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)# 第三轮对话 3rd dialogue turn
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
运行结果如下:
你好!很高兴为你服务。
---
好的,这是一个关于一个年轻人奋斗创业最终取得成功的故事:这是一个关于一个年轻人叫做杰克的故事。杰克是一个非常有抱负的年轻人,他一直梦想着自己能够成为一名成功的企业家。他从小就对商业和创业有着浓厚的兴趣,而且非常勤奋,总是努力学习和探索新的知识和技能。在大学里,杰克学习了商业管理和创业课程,并且积极参加各种商业竞赛和实习项目。他通过自己的努力和聪明才智,赢得了很多奖项和机会,得到了很多宝贵的经验和知识。毕业后,杰克决定开始自己的创业之路。他开始在市场上寻找机会,发现了一个非常有潜力的行业,并且决定在这个行业里创业。他面临着很多挑战和困难,但是他非常坚韧和有决心,不断努力和探索新的方法和思路,不断地学习和进步。杰克和他的团队经历了许多困难和失败,但是他们一直保持着乐观和积极的态度,并且不断地学习和改进自己的方法和策略。最终,他们终于成功地推出了一款非常受欢迎的产品,并且在市场上获得了巨大的成功。杰克的成功不仅仅是因为他的聪明才智和勤奋努力,更重要的是因为他具有坚定的信念和不屈不挠的精神。他不断地学习和进步,不断地尝试新的方法和思路,不断地克服困难和挑战,最终取得了成功。他的故事告诉我们,只要我们具有勇气和决心,就可以在创业的道路上取得成功。
---
这个故事的标题可以是:《杰克的创业之路》。
不知道千问7b所说的杰克,是不是姓马?:)
gradio
千问7b的Web demo用的是Gradio来实现的。与Streamlit类似,Gradio也是包含了简单的Web封装,加上前端的封装。
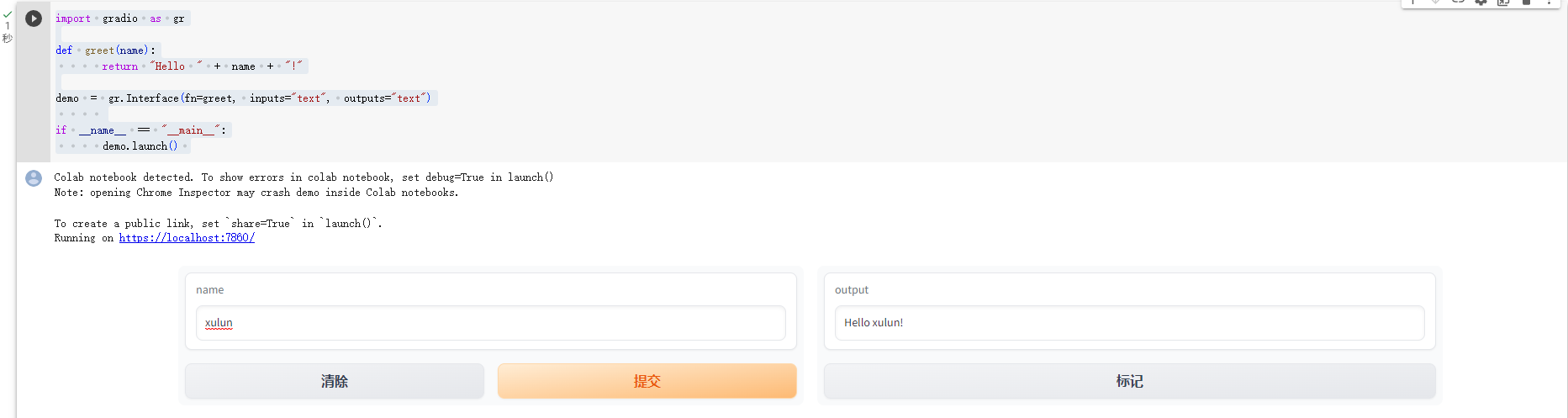
我们先看一个最简单的例子:
import gradio as grdef greet(name):return "Hello " + name + "!"demo = gr.Interface(fn=greet, inputs="text", outputs="text")if __name__ == "__main__":demo.launch()
Gradio对Jupyter Notebook的支持相当好,我们可以直接在Jupyter Notebook中运行,既可以启动后端,也能展示前端。
Gradio通过Markdown方法来书写markdown文本,当然也支持html标签:
gr.Markdown("""<p align="center"><img src="https://modelscope.cn/api/v1/models/qwen/Qwen-7B-Chat/repo?Revision=master&FilePath=assets/logo.jpeg&View=true" style="height: 80px"/><p>""")gr.Markdown("""<center><font size=8>Qwen-7B-Chat Bot</center>""")gr.Markdown("""<center><font size=3>This WebUI is based on Qwen-7B-Chat, developed by Alibaba Cloud. (本WebUI基于Qwen-7B-Chat打造,实现聊天机器人功能。)</center>""")gr.Markdown("""<center><font size=4>Qwen-7B <a href="https://modelscope.cn/models/qwen/Qwen-7B/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-7B">🤗</a>  | Qwen-7B-Chat <a href="https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary">🤖 <a>| <a href="https://huggingface.co/Qwen/Qwen-7B-Chat">🤗</a>  |  <a href="https://github.com/QwenLM/Qwen-7B">Github</a></center>""")
我们来看下效果:
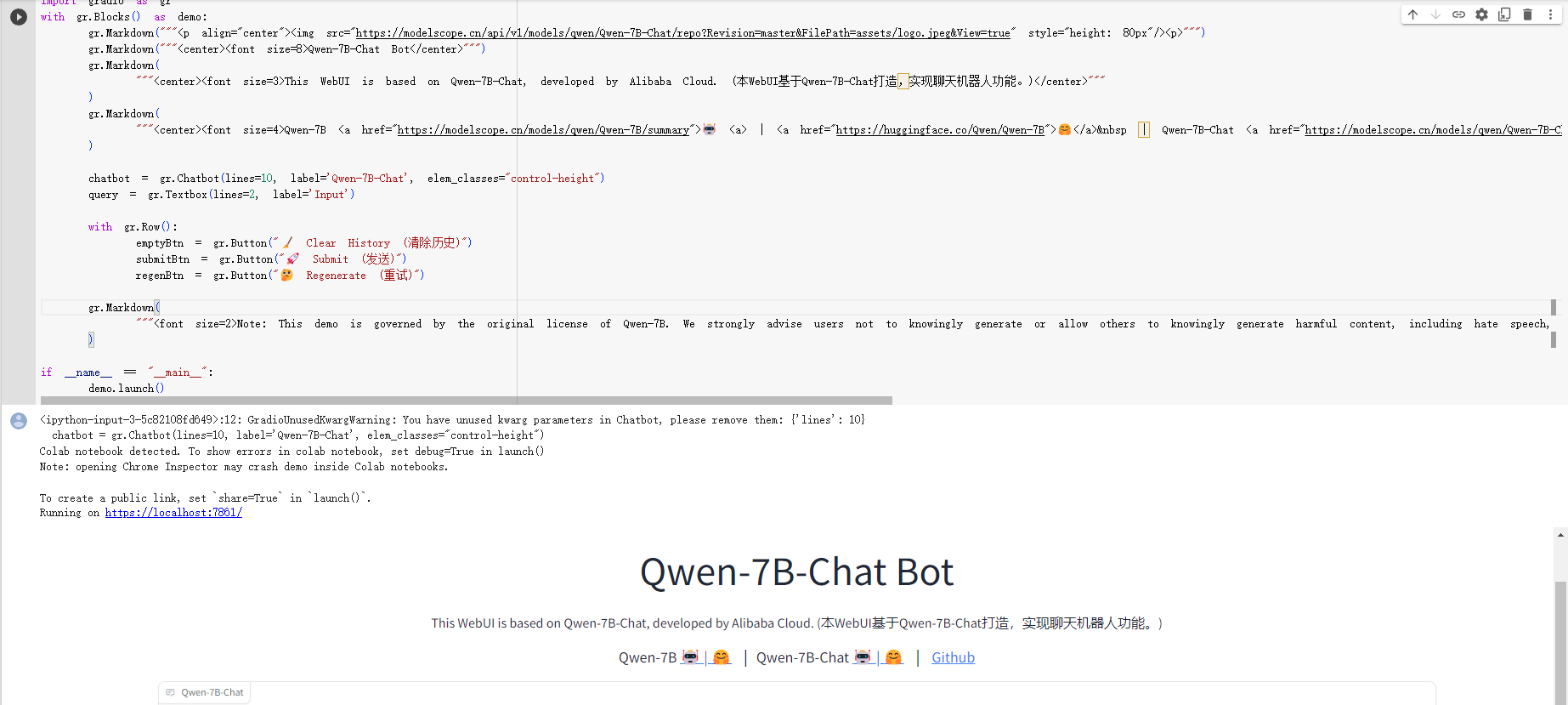
Gradio支持TextBox用于输入,Button用于点击事件,而且支持ChatBot这样的复杂控件。还可以用Row来横向布局:
chatbot = gr.Chatbot(lines=10, label='Qwen-7B-Chat', elem_classes="control-height")query = gr.Textbox(lines=2, label='Input')with gr.Row():emptyBtn = gr.Button("🧹 Clear History (清除历史)")submitBtn = gr.Button("🚀 Submit (发送)")regenBtn = gr.Button("🤔️ Regenerate (重试)")
效果如下:
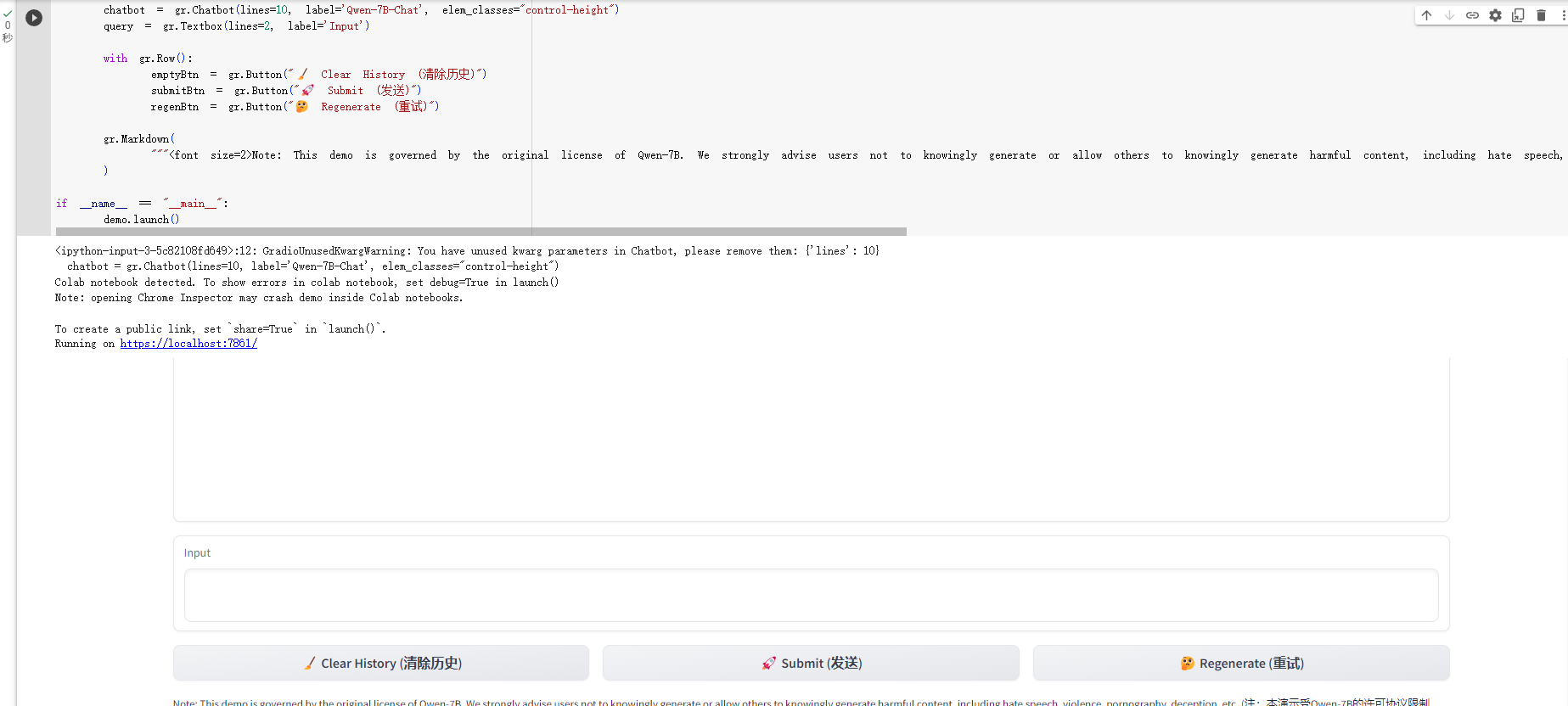
完整代码如下,大家可以自己运行一下:
import gradio as gr
with gr.Blocks() as demo:gr.Markdown("""<p align="center"><img src="https://modelscope.cn/api/v1/models/qwen/Qwen-7B-Chat/repo?Revision=master&FilePath=assets/logo.jpeg&View=true" style="height: 80px"/><p>""")gr.Markdown("""<center><font size=8>Qwen-7B-Chat Bot</center>""")gr.Markdown("""<center><font size=3>This WebUI is based on Qwen-7B-Chat, developed by Alibaba Cloud. (本WebUI基于Qwen-7B-Chat打造,实现聊天机器人功能。)</center>""")gr.Markdown("""<center><font size=4>Qwen-7B <a href="https://modelscope.cn/models/qwen/Qwen-7B/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-7B">🤗</a>  | Qwen-7B-Chat <a href="https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary">🤖 <a>| <a href="https://huggingface.co/Qwen/Qwen-7B-Chat">🤗</a>  |  <a href="https://github.com/QwenLM/Qwen-7B">Github</a></center>""")chatbot = gr.Chatbot(lines=10, label='Qwen-7B-Chat', elem_classes="control-height")query = gr.Textbox(lines=2, label='Input')with gr.Row():emptyBtn = gr.Button("🧹 Clear History (清除历史)")submitBtn = gr.Button("🚀 Submit (发送)")regenBtn = gr.Button("🤔️ Regenerate (重试)")gr.Markdown("""<font size=2>Note: This demo is governed by the original license of Qwen-7B. We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, including hate speech, violence, pornography, deception, etc. (注:本演示受Qwen-7B的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。)""")if __name__ == "__main__":demo.launch()
再给三个Button配上响应函数,就可以响应功能了:
submitBtn.click(predict, [query, chatbot], [chatbot], show_progress=True)submitBtn.click(reset_user_input, [], [query])emptyBtn.click(reset_state, outputs=[chatbot], show_progress=True)regenBtn.click(regenerate, [chatbot], [chatbot], show_progress=True)
其中reset_state只更新下内部状态就好:
def reset_state():task_history.clear()return []
reset_user_input需要通过update函数来刷新下状态,写过React的同学应该很熟悉,这其实是个异步操作哈:
def reset_user_input():return gr.update(value="")
然后是需要处理下流状态的predict函数:
def predict(query, chatbot):print("User: " + parse_text(query))chatbot.append((parse_text(query), ""))fullResponse = ""for response in model.chat_stream(tokenizer, query, history=task_history):chatbot[-1] = (parse_text(query), parse_text(response))yield chatbotfullResponse = parse_text(response)task_history.append((query, fullResponse))print("Qwen-7B-Chat: " + parse_text(fullResponse))
注意yield的用法,chatbot就是我们用gr.ChatBot生成的对话框控件。
regenerate仍然要注意下yield:
def regenerate(chatbot):if not task_history:yield chatbotreturnitem = task_history.pop(-1)chatbot.pop(-1)yield from predict(item[0], chatbot)
代码超参数
下面我们来看下Qwen-7B-Chat的代码。
首先是支持了哪些配置项和超参数:
from transformers import PretrainedConfigclass QWenConfig(PretrainedConfig):model_type = "qwen"keys_to_ignore_at_inference = ["past_key_values"]attribute_map = {"hidden_size": "n_embd","num_attention_heads": "n_head","max_position_embeddings": "n_positions","num_hidden_layers": "n_layer",}def __init__(self,vocab_size=151851,n_embd=4096,n_layer=32,n_head=32,n_inner=None,embd_pdrop=0.0,attn_pdrop=0.0,layer_norm_epsilon=1e-5,initializer_range=0.02,scale_attn_weights=True,use_cache=True,eos_token_id=151643,apply_residual_connection_post_layernorm=False,bf16=False,fp16=False,fp32=False,kv_channels=128,rotary_pct=1.0,rotary_emb_base=10000,use_dynamic_ntk=False,use_logn_attn=False,use_flash_attn=True,ffn_hidden_size=22016,no_bias=True,tie_word_embeddings=False,**kwargs,):self.eos_token_id = eos_token_idsuper().__init__(eos_token_id=eos_token_id, tie_word_embeddings=tie_word_embeddings, **kwargs)self.vocab_size = vocab_sizeself.n_embd = n_embdself.n_layer = n_layerself.n_head = n_headself.n_inner = n_innerself.embd_pdrop = embd_pdropself.attn_pdrop = attn_pdropself.layer_norm_epsilon = layer_norm_epsilonself.initializer_range = initializer_rangeself.scale_attn_weights = scale_attn_weightsself.use_cache = use_cacheself.apply_residual_connection_post_layernorm = (apply_residual_connection_post_layernorm)self.bf16 = bf16self.fp16 = fp16self.fp32 = fp32self.kv_channels = kv_channelsself.rotary_pct = rotary_pctself.rotary_emb_base = rotary_emb_baseself.use_dynamic_ntk = use_dynamic_ntkself.use_logn_attn = use_logn_attnself.use_flash_attn = use_flash_attnself.ffn_hidden_size = ffn_hidden_sizeself.no_bias = no_biasself.tie_word_embeddings = tie_word_embeddings
我们来解释下这些参数:
- vocab_size:词汇表大小,即模型可以处理的不同单词的数量,默认为 151851
- n_embd: 嵌入层的维度,即每个单词或位置的向量表示的长度,默认为 4096
- n_layer: 编码器层的数量,即模型中重复堆叠的自注意力层和前馈层的数量,默认为 32
- n_head=32: 注意力头的数量,即每个编码器层中分割后的多头自注意力机制的数量,默认为 32
- n_inner: 前馈层的内部维度,即每个编码器层中全连接层的隐藏单元数,默认为 None,表示与嵌入层维度相同
- embd_pdrop: 嵌入层的丢弃概率,即在嵌入层后应用丢弃正则化时随机置零单元的概率,默认为 0.0,表示不使用丢弃正则化
- attn_pdrop: 注意力层的丢弃概率,即在注意力层后应用丢弃正则化时随机置零单元的概率,默认为 0.0,表示不使用丢弃正则化
- layer_norm_epsilon: 层归一化的 epsilon 值,即在计算层归一化时加到分母上的小量,防止除以零,默认为 1e-5
- initializer_range: 初始化范围,即在初始化模型参数时使用的均匀分布的上下界,默认为 0.02
- scale_attn_weights: 是否缩放注意力权重,即在计算多头自注意力机制时是否除以注意力头数的平方根,默认为 True
- use_cache: 是否使用缓存,即在解码时是否保存前面计算过的隐藏状态和注意力键值对,默认为 True
- eos_token_id:结束符号的 ID,即表示序列结束的特殊单词对应的整数编号,默认为 151643
- apply_residual_connection_post_layernorm:是否在层归一化后应用残差连接,即在每个编码器层中是否先进行层归一化再加上输入,默认为 False
- bf16:是否使用 bf16 格式,即是否使用 16 位浮点数来存储模型参数和计算梯度,默认为 False
- fp16:是否使用 fp16 格式,即是否使用 16 位浮点数来存储模型参数和计算梯度,默认为 False
- fp32:是否使用 fp32 格式,即是否使用 32 位浮点数来存储模型参数和计算梯度,默认为 False
- kv_channels: 键值通道数,即在计算注意力键值对时使用的线性变换的输出维度,默认为 128
- rotary_pct: 旋转百分比,即在嵌入层中使用旋转位置编码的比例,默认为 1.0,表示全部使用旋转位置编码
- rotary_emb_base: 旋转嵌入基数,即在计算旋转位置编码时使用的基数,默认为 10000
- use_dynamic_ntk:是否使用动态 NTK,即是否在计算注意力权重时使用动态神经切线核方法,默认为 False
- use_logn_attn: 是否使用对数注意力,即是否在计算注意力权重时使用对数函数来加速和压缩,默认为 False
- use_flash_attn: 是否使用闪存注意力,即是否在计算注意力权重时使用闪存变换来降低复杂度,默认为 True
- ffn_hidden_size: 前馈层的隐藏大小,即每个编码器层中全连接层的输出维度,默认为 22016
- no_bias: 是否不使用偏置,即在模型中的所有线性变换中是否不添加偏置向量,默认为 True
- tie_word_embeddings: 是否绑定词嵌入,即在模型中是否共享输入和输出的词嵌入矩阵,默认为 False
- kwargs: 其他参数,用于接收额外的配置信息或覆盖上面的默认值
Flash Attention
千问7b建议使用flash attention来进行加速。
Flash Attention 是一种新型的注意力算法,它可以快速和内存高效地计算精确的注意力权重,而不需要近似或压缩。它的主要思想是利用 GPU 的层次化内存结构,通过分块和重用的方法,减少从高带宽内存(HBM)到片上静态随机存储器(SRAM)的读写次数,从而提高计算速度和节省内存空间。Flash Attention 还可以扩展到块稀疏注意力,进一步降低计算复杂度和内存消耗。
Flash Attention 的主要优势有:
- 它可以实现与标准注意力相同的模型质量和精度,而不牺牲任何信息或引入任何噪声。
- 它可以在不同的序列长度、批量大小、模型大小和硬件配置下,都能达到显著的加速和内存节省效果。
- 它可以与其他优化技术如混合精度训练、激活检查点等兼容,进一步提升性能。
- 它可以支持更长的上下文长度,从而提高模型在长文本任务上的表现。
具体原理我们后面会分析到其论文和代码。
代码在:https://github.com/Dao-AILab/flash-attention。论文在:https://arxiv.org/abs/2205.14135
这里我们先看在千问7b中如何使用flash attention。
首先要把Flash attention的库加载进来:
def _import_flash_attn():global apply_rotary_emb_func, rms_norm, flash_attn_unpadded_functry:from flash_attn.layers.rotary import apply_rotary_emb_func as __apply_rotary_emb_funcapply_rotary_emb_func = __apply_rotary_emb_funcexcept ImportError:logger.warn("Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency ""https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary")try:from flash_attn.ops.rms_norm import rms_norm as __rms_normrms_norm = __rms_normexcept ImportError:logger.warn("Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency ""https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm")try:import flash_attnif not hasattr(flash_attn, '__version__'):from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_funcelse:if int(flash_attn.__version__.split(".")[0]) >= 2:from flash_attn.flash_attn_interface import flash_attn_varlen_func as __flash_attn_unpadded_funcelse:from flash_attn.flash_attn_interface import flash_attn_unpadded_func as __flash_attn_unpadded_funcflash_attn_unpadded_func = __flash_attn_unpadded_funcexcept ImportError:logger.warn("Warning: import flash_attn fail, please install FlashAttention to get higher efficiency ""https://github.com/Dao-AILab/flash-attention")
然后我们实现一个使用Flash Attention的自注意力模块:
class FlashSelfAttention(torch.nn.Module):def __init__(self,causal=False,softmax_scale=None,attention_dropout=0.0,):super().__init__()assert flash_attn_unpadded_func is not None, ("Please install FlashAttention first, " "e.g., with pip install flash-attn")assert (rearrange is not None), "Please install einops first, e.g., with pip install einops"self.causal = causalself.softmax_scale = softmax_scaleself.dropout_p = attention_dropoutdef forward(self, q, k, v):assert all((i.dtype in [torch.float16, torch.bfloat16] for i in (q, k, v)))assert all((i.is_cuda for i in (q, k, v)))batch_size, seqlen_q = q.shape[0], q.shape[1]seqlen_k = k.shape[1]q, k, v = [rearrange(x, "b s ... -> (b s) ...") for x in [q, k, v]]cu_seqlens_q = torch.arange(0,(batch_size + 1) * seqlen_q,step=seqlen_q,dtype=torch.int32,device=q.device,)if self.training:assert seqlen_k == seqlen_qis_causal = self.causalcu_seqlens_k = cu_seqlens_qelse:is_causal = seqlen_q == seqlen_kcu_seqlens_k = torch.arange(0,(batch_size + 1) * seqlen_k,step=seqlen_k,dtype=torch.int32,device=q.device,)self.dropout_p = 0output = flash_attn_unpadded_func(q,k,v,cu_seqlens_q,cu_seqlens_k,seqlen_q,seqlen_k,self.dropout_p,softmax_scale=self.softmax_scale,causal=is_causal,)output = rearrange(output, "(b s) ... -> b s ...", b=batch_size)return output
其主要步骤如下:
- 首先,检查q, k, v的数据类型是否为torch.float16或torch.bfloat16,以及是否在CUDA设备上运行。
- 然后,使用einops库的rearrange函数,将q, k, v的形状从"b s …“变为”(b s) …",其中b是批次大小,s是序列长度。
- 接着,根据q和k的序列长度,生成两个整数张量cu_seqlens_q和cu_seqlens_k,它们表示每个批次中每个序列的起始位置。
- 再然后,根据是否处于训练模式和是否使用因果掩码,设置cu_seqlens_k和is_causal的值,以及注意力的dropout概率。
- 核心的Flash Attention来了,调用flash_attn_unpadded_func函数,它是FlashAttention库提供的一个核心函数,它可以快速计算未填充的自注意力矩阵,并返回输出张量。
- 最后,将输出张量的形状从"(b s) …“变回"b s …”,并返回。
RMSNorm层
通义千问的RMSNorm跟之前讲的基本一样,这里就不多解释了:
class RMSNorm(torch.nn.Module):def __init__(self, dim: int, eps: float = 1e-6):super().__init__()self.eps = epsself.weight = nn.Parameter(torch.ones(dim))def _norm(self, x):return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)def forward(self, x):if rms_norm is not None and x.is_cuda:return rms_norm(x, self.weight, self.eps)else:output = self._norm(x.float()).type_as(x)return output * self.weight位置编码
千问7b的位置编码是标准的Rotary Position Embedding。来自论文《RoFormer: Enhanced Transformer with Rotary Position Embedding》。
class RotaryEmbedding(torch.nn.Module):def __init__(self, dim, base=10000):super().__init__()self.dim = dimself.base = baseself.inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))if importlib.util.find_spec("einops") is None:raise RuntimeError("einops is required for Rotary Embedding")self._rotary_pos_emb_cache = Noneself._seq_len_cached = 0self._ntk_alpha_cached = 1.0def update_rotary_pos_emb_cache(self, max_seq_len, offset=0, ntk_alpha=1.0):seqlen = max_seq_len + offsetif seqlen > self._seq_len_cached or ntk_alpha != self._ntk_alpha_cached:base = self.base * ntk_alpha ** (self.dim / (self.dim - 2))self.inv_freq = 1.0 / (base** (torch.arange(0, self.dim, 2, device=self.inv_freq.device).float()/ self.dim))self._seq_len_cached = max(2 * seqlen, 16)self._ntk_alpha_cached = ntk_alphaseq = torch.arange(self._seq_len_cached, device=self.inv_freq.device)freqs = torch.outer(seq.type_as(self.inv_freq), self.inv_freq)emb = torch.cat((freqs, freqs), dim=-1)from einops import rearrangeself._rotary_pos_emb_cache = rearrange(emb, "n d -> 1 n 1 d")def forward(self, max_seq_len, offset=0, ntk_alpha=1.0):self.update_rotary_pos_emb_cache(max_seq_len, offset, ntk_alpha)return self._rotary_pos_emb_cache[:, offset : offset + max_seq_len]
千问7b的_rotate_half使用了einops库来加速:
def _rotate_half(x):from einops import rearrangex = rearrange(x, "... (j d) -> ... j d", j=2)x1, x2 = x.unbind(dim=-2)return torch.cat((-x2, x1), dim=-1)
最后是apply_rotary_pos_emb的实现,使用了apply_rotary_emb_func来进行加速。
def apply_rotary_pos_emb(t, freqs):if apply_rotary_emb_func is not None and t.is_cuda:t_ = t.float()freqs = freqs.squeeze(0).squeeze(1)cos = freqs[:, : freqs.shape[-1] // 2].cos()sin = freqs[:, : freqs.shape[-1] // 2].sin()output = apply_rotary_emb_func(t_, cos, sin).type_as(t)return outputelse:rot_dim = freqs.shape[-1]t_, t_pass_ = t[..., :rot_dim], t[..., rot_dim:]t_ = t_.float()t_pass_ = t_pass_.float()t_ = (t_ * freqs.cos()) + (_rotate_half(t_) * freqs.sin())return torch.cat((t_, t_pass_), dim=-1).type_as(t)
千问7b的注意力结构
首先还是一堆变量定义:
class QWenAttention(nn.Module):def __init__(self, config, layer_number=None):super().__init__()max_positions = config.max_position_embeddingsself.register_buffer("bias",torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view(1, 1, max_positions, max_positions),persistent=False,)self.register_buffer("masked_bias", torch.tensor(-1e4), persistent=False)self.layer_number = max(1, layer_number)self.params_dtype = config.params_dtypeself.seq_length = config.seq_lengthself.hidden_size = config.hidden_sizeself.split_size = config.hidden_sizeself.num_heads = config.num_attention_headsself.head_dim = self.hidden_size // self.num_headsself.use_flash_attn = config.use_flash_attnself.scale_attn_weights = Trueself.layer_idx = Noneself.projection_size = config.kv_channels * config.num_attention_headsassert self.projection_size % config.num_attention_heads == 0self.hidden_size_per_attention_head = (self.projection_size // config.num_attention_heads)self.c_attn = nn.Linear(config.hidden_size, 3 * self.projection_size)self.c_proj = nn.Linear(config.hidden_size, self.projection_size, bias=not config.no_bias)self.is_fp32 = not (config.bf16 or config.fp16)if (self.use_flash_attnand flash_attn_unpadded_func is not Noneand not self.is_fp32):self.core_attention_flash = FlashSelfAttention(causal=True, attention_dropout=config.attn_pdrop)self.bf16 = config.bf16if config.rotary_pct == 1.0:self.rotary_ndims = Noneelse:assert config.rotary_pct < 1self.rotary_ndims = int(self.hidden_size_per_attention_head * config.rotary_pct)dim = (self.rotary_ndimsif self.rotary_ndims is not Noneelse self.hidden_size_per_attention_head)self.rotary_emb = RotaryEmbedding(dim, base=config.rotary_emb_base)self.use_dynamic_ntk = config.use_dynamic_ntkself.use_logn_attn = config.use_logn_attnlogn_list = [math.log(i, self.seq_length) if i > self.seq_length else 1for i in range(1, 32768)]self.logn_tensor = torch.tensor(logn_list)[None, :, None, None]self._ntk_cached = 1.0self.attn_dropout = nn.Dropout(config.attn_pdrop)
大致介绍一下这些变量,具体的含义我们在后面代码可以讲到:
- max_positions 定义了模型可以处理的最大位置数,它来自配置对象
- bias 是一个下三角矩阵,大小为 (max_positions, max_positions),用于实现自注意力的屏蔽。它被注册为一个不需要持久化的缓冲区
- masked_bias 是一个具有大负值(-1e4)的张量,用于在注意力得分中屏蔽某些位置
- layer_number 是当前层的层数,至少为1
- params_dtype 是模型参数的数据类型
- seq_length 是输入序列的长度
- hidden_size、split_size、num_heads、head_dim 分别为隐藏层大小,分割大小,注意力头数和每个注意力头的维度
- use_flash_attn 是一个布尔标志,表示是否使用 Flash Attention
- scale_attn_weights 是一个布尔标志,表示是否对注意力权重进行缩放
- projection_size 定义了投影的大小,它等于 kv_channels 和 num_attention_heads 的乘积
- c_attn 和 c_proj 是两个线性层,用于计算注意力得分
- core_attention_flash 是一个 FlashSelfAttention 对象,只有在使用 Flash Attention 并且数据类型不是 fp32 时才会创建
- bf16 是一个布尔标志,表示是否使用 bf16 数据类型
- rotary_emb 是一个 RotaryEmbedding 对象,用于实现旋转位置编码
- use_dynamic_ntk 是一个布尔标志,表示是否使用动态 NTK
- use_logn_attn 是一个布尔标志,表示是否使用 logn 注意力
- logn_tensor 是一个张量,包含了一些预计算的 logn 值
- attn_dropout 是一个 Dropout 层,用于在注意力计算中添加随机性
下面我们来看注意力的计算:
def _attn(self, query, key, value, attention_mask=None, head_mask=None):attn_weights = torch.matmul(query, key.transpose(-1, -2))if self.scale_attn_weights:attn_weights = attn_weights / torch.full([],value.size(-1) ** 0.5,dtype=attn_weights.dtype,device=attn_weights.device,)query_length, key_length = query.size(-2), key.size(-2)causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length]mask_value = torch.finfo(attn_weights.dtype).minmask_value = torch.full([], mask_value, dtype=attn_weights.dtype).to(attn_weights.device)attn_weights = torch.where(causal_mask, attn_weights.to(attn_weights.dtype), mask_value)attn_weights = nn.functional.softmax(attn_weights, dim=-1)attn_weights = attn_weights.type(value.dtype)attn_weights = self.attn_dropout(attn_weights)if head_mask is not None:attn_weights = attn_weights * head_maskattn_output = torch.matmul(attn_weights, value)attn_output = attn_output.transpose(1, 2)return attn_output, attn_weights
其主要步骤如下:
- 使用 torch.matmul 计算查询(query)和键(key)的点积,得到注意力权重 attn_weights。
- 如果 self.scale_attn_weights 为 True,则将注意力权重除以值(value)的最后一个维度的平方根,这是一种常见的缩放操作,用于控制注意力权重的大小。
- 创建一个因果屏蔽 causal_mask,该屏蔽用于确保在自注意力计算中,任何位置只能注意到其之前的位置。其中 mask_value 是一个非常小的数,用于在注意力得分中屏蔽某些位置。
- 使用 torch.where 应用因果屏蔽。如果 causal_mask 中的某一位置为 True,那么在对应的 attn_weights 位置保持原值,否则用 mask_value 替换。
- 对注意力权重应用 softmax 函数,使得所有权重之和为1,这样可以将它们解释为概率。
- 使用 attn_dropout 对注意力权重应用 dropout 操作,以增加模型的泛化能力。
- 如果提供了 head_mask,则将其应用到注意力权重上,这可以用于屏蔽某些注意力头。
- 使用注意力权重和值(value)计算注意力输出 attn_output,并将其张量的第1维和第2维进行转置,以满足后续操作的需要。
为了提高计算精度,还有另一个Attention的计算函数:
def _upcast_and_reordered_attn(self, query, key, value, attention_mask=None, head_mask=None):bsz, num_heads, q_seq_len, dk = query.size()_, _, k_seq_len, _ = key.size()attn_weights = torch.empty(bsz * num_heads,q_seq_len,k_seq_len,dtype=torch.float32,device=query.device,)scale_factor = 1.0if self.scale_attn_weights:scale_factor /= float(value.size(-1)) ** 0.5with autocast(enabled=False):q, k = query.reshape(-1, q_seq_len, dk), key.transpose(-1, -2).reshape(-1, dk, k_seq_len)attn_weights = torch.baddbmm(attn_weights, q.float(), k.float(), beta=0, alpha=scale_factor)attn_weights = attn_weights.reshape(bsz, num_heads, q_seq_len, k_seq_len)query_length, key_length = query.size(-2), key.size(-2)causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length]mask_value = torch.finfo(attn_weights.dtype).minmask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)attn_weights = torch.where(causal_mask, attn_weights, mask_value)if attention_mask is not None:attn_weights = attn_weights + attention_maskattn_weights = nn.functional.softmax(attn_weights, dim=-1)if attn_weights.dtype != torch.float32:raise RuntimeError("Error with upcasting, attn_weights does not have dtype torch.float32")attn_weights = attn_weights.type(value.dtype)attn_weights = self.attn_dropout(attn_weights)if head_mask is not None:attn_weights = attn_weights * head_maskattn_output = torch.matmul(attn_weights, value)return attn_output, attn_weights
_upcast_and_reordered_attn注意力权重计算使用float32精度。将query和key reshape成2D矩阵,然后使用torch.baddbmm进行高效的矩阵乘法。计算得到的attn_weights再reshape回原始的4D形状。同样应用因果遮掩矩阵和attention mask。
在softmax之前校验attn_weights是否是float32,如果不是会报错。softmax后再将attn_weights转回value的dtype。
最后得到attention输出和权重矩阵。
还有对头的拆分和组装的两个辅助函数:
def _split_heads(self, tensor, num_heads, attn_head_size):new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)tensor = tensor.view(new_shape)return tensordef _merge_heads(self, tensor, num_heads, attn_head_size):tensor = tensor.contiguous()new_shape = tensor.size()[:-2] + (num_heads * attn_head_size,)return tensor.view(new_shape)
_split_heads 函数的作用是将输入张量的最后一个维度分割成两个维度,其中一个是注意力头的数量(num_heads),另一个是每个注意力头的大小(attn_head_size)。函数首先创建了新的形状 new_shape,然后使用 view 函数将输入张量变形为这个新的形状。
_merge_heads 函数的作用是将 _split_heads 函数处理后的张量回归到原始的维度。首先,它会调用 contiguous 函数确保张量在内存中是连续的,这是因为在某些情况下,view 函数需要输入张量在内存中是连续的。然后,它创建了新的形状 new_shape,并使用 view 函数将输入张量变形为这个新的形状。
最后是前向计算。主要分为十步:
- 输入参数:hidden_states是输入的隐藏状态,layer_past是上一层的输出,attention_mask和head_mask分别是注意力掩码和头掩码,encoder_hidden_states和encoder_attention_mask是在编码器-解码器架构中使用的,output_attentions决定是否输出注意力权重,use_cache决定是否使用缓存。
- 计算 query、key 和 value:通过self.c_attn(hidden_states)计算混合层,然后将其拆分为查询、键和值。拆分后的大小是self.split_size。
- 分割多头注意力:使用_split_heads()函数对 query、key 和 value 进行拆分,将最后一个维度拆分为self.num_heads和self.head_dim。
- 处理旋转位置嵌入:根据kv_seq_len和ntk_alpha计算旋转位置嵌入。然后,对 query 和 key 应用旋转位置嵌入。
- 处理 past layer:如果layer_past存在,将其与当前的 key 和 value 连接起来。
- 处理缓存:如果use_cache为 True,则将当前的 key 和 value 存储到present中。
- 应用对数注意力:如果use_logn_attn为 True,并且当前不处于训练模式,那么将对 query 应用对数注意力。
- 应用 Flash Attention 或常规注意力:如果use_flash_attn为 True,并且满足一些其他条件,那么使用 Flash Attention 对 query、key 和 value 进行处理。否则,使用常规的注意力机制,并且将 query、key 和 value 的维度重新排列以符合_attn()函数的要求。
- 计算注意力输出并进行投影:使用self.c_proj()将注意力输出进行投影。
- 生成输出:如果output_attentions为 True,那么在输出中加入注意力权重。
def forward(self,hidden_states: Optional[Tuple[torch.FloatTensor]],layer_past: Optional[Tuple[torch.Tensor]] = None,attention_mask: Optional[torch.FloatTensor] = None,head_mask: Optional[torch.FloatTensor] = None,encoder_hidden_states: Optional[torch.Tensor] = None,encoder_attention_mask: Optional[torch.FloatTensor] = None,output_attentions: Optional[bool] = False,use_cache: Optional[bool] = False,):mixed_x_layer = self.c_attn(hidden_states)query, key, value = mixed_x_layer.split(self.split_size, dim=2)query = self._split_heads(query, self.num_heads, self.head_dim)key = self._split_heads(key, self.num_heads, self.head_dim)value = self._split_heads(value, self.num_heads, self.head_dim)kv_seq_len = hidden_states.size()[1]if layer_past:# layer past[0] shape: bs * seq_len * head_num * dimkv_seq_len += layer_past[0].shape[1]if (self.use_dynamic_ntkand kv_seq_len == hidden_states.size()[1]and not self.training):context_value = math.log(kv_seq_len / self.seq_length, 2) + 1ntk_alpha = 2 ** math.ceil(context_value) - 1ntk_alpha = max(ntk_alpha, 1)self._ntk_cached = ntk_alphaelse:ntk_alpha = self._ntk_cachedrotary_pos_emb = self.rotary_emb(kv_seq_len, ntk_alpha=ntk_alpha).to(hidden_states.device)if rotary_pos_emb is not None:if isinstance(rotary_pos_emb, tuple):rotary_pos_emb = rotary_pos_embelse:rotary_pos_emb = (rotary_pos_emb,) * 2if rotary_pos_emb is not None:q_pos_emb, k_pos_emb = rotary_pos_emb# Slice the pos emb for current inferencecur_len = query.shape[1]q_pos_emb = q_pos_emb[:, -cur_len:, :, :]k_pos_emb = k_pos_emb[:, -cur_len:, :, :]query = apply_rotary_pos_emb(query, q_pos_emb)key = apply_rotary_pos_emb(key, k_pos_emb)if layer_past is not None:past_key, past_value = layer_past[0], layer_past[1]key = torch.cat((past_key, key), dim=1)value = torch.cat((past_value, value), dim=1)if use_cache:present = (key, value)else:present = Noneif self.use_logn_attn and not self.training:if self.logn_tensor.device != query.device or self.logn_tensor.dtype != query.dtype:self.logn_tensor = self.logn_tensor.to(query.device).type_as(query)seq_start = key.size(1) - query.size(1)seq_end = key.size(1)logn_tensor = self.logn_tensor[:, seq_start:seq_end, :, :]query = query * logn_tensor.expand_as(query)if (self.use_flash_attnand flash_attn_unpadded_func is not Noneand not self.is_fp32and query.is_cuda):q, k, v = query, key, valuecontext_layer = self.core_attention_flash(q, k, v)context_layer = rearrange(context_layer, "b s h d -> b s (h d)").contiguous()else:query = query.permute(0, 2, 1, 3)key = key.permute(0, 2, 1, 3)value = value.permute(0, 2, 1, 3)attn_output, attn_weight = self._attn(query, key, value, attention_mask, head_mask)context_layer = self._merge_heads(attn_output, self.num_heads, self.head_dim)attn_output = self.c_proj(context_layer)outputs = (attn_output, present)if output_attentions:if (self.use_flash_attnand flash_attn_unpadded_func is not Noneand not self.is_fp32):raise ValueError("Cannot output attentions while using flash-attn")else:outputs += (attn_weight,)return outputs
小结
千问7b的代码比较长,实现的接口也较多,下一节我们继续介绍将自注意力模块和组装成模型的代码。
![[C++ 网络协议] 套接字和地址族、数据序列](https://img-blog.csdnimg.cn/d3bb90e97a35433fa86f1306f057cb87.png)