chatglm-6b很强,很多同学都想自己试一试,但不是每个人都有GPU、高端显卡的环境,大多数同学都是一台普通的笔记本。
笔者这里分享一下在自己的8G内存,intel i3笔记本上安装部署chatglm-6b的实际经验。有很多网站都分享了一些经验,但不知道是不是环境的问题,笔者自己发现按照网上的文章,很多都走不通,也是自己综合各个文章,多次尝试,才勉强算是成功运行了!!!虽然运行特别慢,但也算是个小成果!废话不说了,走起:
第一大步: 首先下载,安装python依赖库这些呢,没什么特别的,事务性列举如下,就不多说了(在windows/linux下安装python什么的,就不多说了,笔者用的Python 3.10.6,版本不能太低):
(1)下载官方代码,安装Python依赖的库
下载地址:GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
然后找到文件requirements.txt并运行:
pip install -r requirements.txt
注意装完了,后不一定够用,反正缺啥装啥就完了,也不啰嗦了
(2)下载INT4量化后的预训练结果文件
注意,CPU上,反正笔者用的INT4,建议就用这个吧
INT4量化的预训练文件下载地址:THUDM/chatglm-6b-int4 at main
完了在上面github下载的chatglm-6b-main新建个目录model,把上面下载的一大堆文件,包括模型bin,py的一堆都拷贝进去
第二大步:这一步是最重要的了,大家可要注意了(最好需要先安装CPU版本的torch)
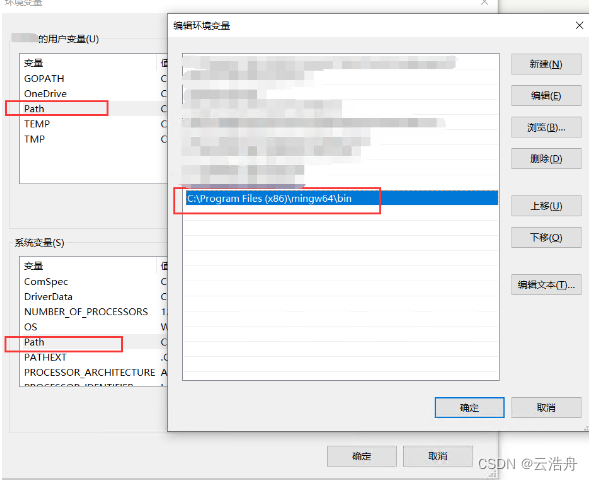
(1)需要安装GCC并配置环境变量
网上有很多材料,有的说安装TDM-GCC,有的又说安装mingw64,有的又说安装win64devkit,反正笔者自己的经验是:win64devkit(注意,可以多装几个,因为编译.so文件时,和运行时要求的,可能有时候要用不同的gcc,如果不行,就换一个,反正win64devkit编译下面的.so是没问题的)
(2)编译quantization_kernels.so与quantization_kernels_parallel.so
进行上面int4模型存放的目录,即chatglm-6b-main/model,运行如下命令:
gcc -fPIC -pthread -fopenmp -std=c99 quantization_kernels.c -shared -o quantization_kernels.sogcc -fPIC -pthread -fopenmp -std=c99 quantization_kernels_parallel.c -shared -o quantization_kernels_parallel.so
注:有可能只编译上面一个就够了,哈哈
(3)修改cli_demo.py(或者web_demo.py,看你想运行哪一个)
找到如下代码,改成如下样子:
tokenizer = AutoTokenizer.from_pretrained("自己的目录\\ChatGLM-6B-main\\model", trust_remote_code=True)
model = AutoModel.from_pretrained("自己的目录\\ChatGLM-6B-main\\model", trust_remote_code=True).float()
model = model.quantize(bits=4, kernel_file="自己的目录\\ChatGLM-6B-main\\model\\quantization_kernels.so")
model = model.eval()
其实主要就是GPU版本后面是.half().cuda(),而这里是float();另外加载quantization_kernels.so
(4)运行python cli_demo.py,应该就可以对话了
祝成功!