目录
- 一、 Filebeat+ELK 部署
- Filebeat 节点上操作
- 二、Filter
- grok 正则捕获插件
- 内置正则表达式调用
- 自定义表达式调用
- mutate 数据修改插件
- multiline 多行合并插件
- date 时间处理插件
一、 Filebeat+ELK 部署
Node1节点(2C/4G):node1/192.168.154.10 Elasticsearch
Node2节点(2C/4G):node2/192.168.154.11 Elasticsearch
Apache节点:apache/192.168.154.12 Logstash Kibana Apache
Filebeat节点:filebeat/192.168.154.13 Filebeat
先在Filebeat节点添加网页文件

浏览器访问http://192.168.154.13/test.html获取日志

Filebeat 节点上操作
1.安装 Filebeat
#上传软件包 filebeat-6.7.2-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.7.2-linux-x86_64.tar.gz
mv filebeat-6.7.2-linux-x86_64/ /usr/local/filebeat
2.设置 filebeat 的主配置文件
cd /usr/local/filebeatvim filebeat.yml
filebeat.inputs:
- type: log #指定 log 类型,从日志文件中读取消息enabled: truepaths:- /var/log/httpd/access_log #指定监控的日志文件tags: ["filebeat"] #设置索引标签fields: #可以使用 fields 配置选项设置一些参数字段添加到 output 中service_name: httpdlog_type: accessfrom: 192.168.154.13 #要收集日志的来源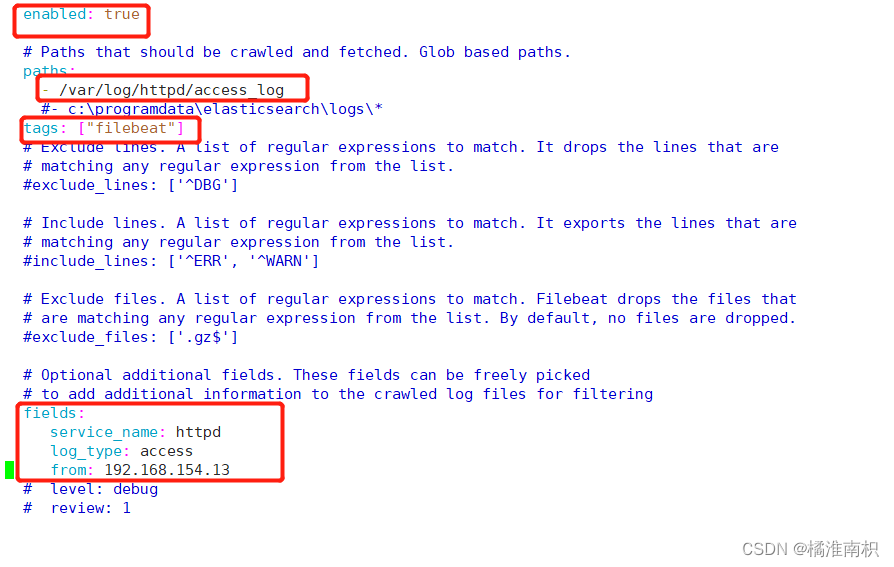
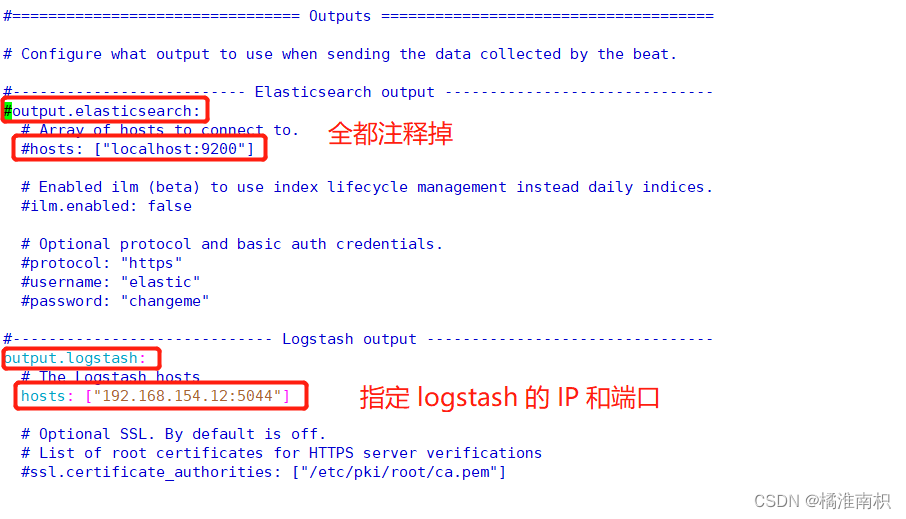
--------------Elasticsearch output-------------------
(全部注释掉)
----------------Logstash output---------------------
output.logstash:hosts: ["192.168.154.12:5044"] #指定 logstash 的 IP 和端口
#启动 filebeat
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
#-e:输出到标准输出,禁用syslog/文件输出
#-c:指定配置文件
#nohup:在系统后台不挂断地运行命令,退出终端不会影响程序的运行
4.在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.dvim filebeat.conf
input {beats {port => "5044"}
}
filebeat发送给logstash的日志内容会放到message字段里面,logstash使用grok插件正则匹配message字段内容进行字段分割
Kibana自带grok的正则匹配的工具:http://:5601/app/kibana#/dev_tools/grokdebugger
#%{IPV6}|%{IPV4} 为 logstash 自带的 IP 常量
filter {grok {match => ["message", "(?<remote_addr>%{IPV6}|%{IPV4})[\s\-]+\[(?<logTime>.*)\]\s+\"(?<method>\S+)\s+(?<url_path>.+)\"\s+(?<rev_code>\d+) \d+ \"(?<req_addr>.+)\" \"(?<content>.*)\""]}
}
output {elasticsearch {hosts => ["192.168.154.10:9200","192.168.154.11:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}
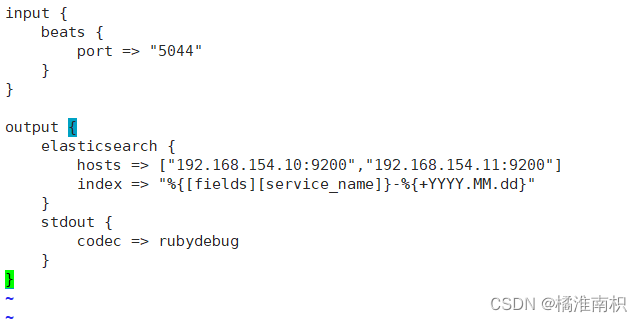
#启动 logstash
logstash -f filebeat.conf
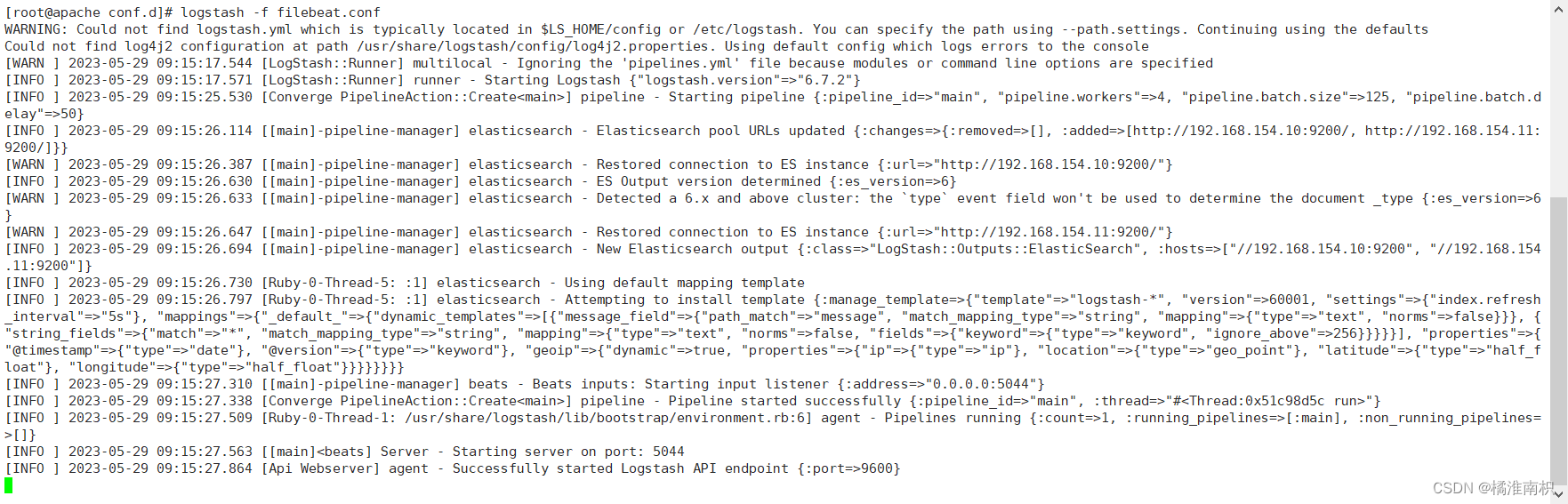
5.浏览器访问 http://192.168.154.10:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“httpd-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。

二、Filter
表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
- grok 对若干个大文本字段进行再分割成一些小字段 (?<字段名>正则表达式) 字段名: 正则表达式匹配到的内容
- date 对数据中的时间格式进行统一和格式化
- mutate 对一些无用的字段进行剔除,或增加字段
- mutiline 对多行数据进行统一编排,多行合并或拆分
grok 正则捕获插件
grok 使用文本片段切分的方式来切分日志事件
内置正则表达式调用
%{SYNTAX:SEMANTIC}
SYNTAX代表匹配值的类型,例如,0.11可以NUMBER类型所匹配,10.222.22.25可以使用IP匹配
SEMANTIC表示存储该值的一个变量声明,它会存储在elasticsearch当中方便kibana做字段搜索和统计,你可以将一个IP定义为客户端IP地址client_ip_adress,
如%{IP:client_ip_address},所匹配到的值就会存储到client_ip_address这个字段里边,类似数据库的列名,也可以把event log
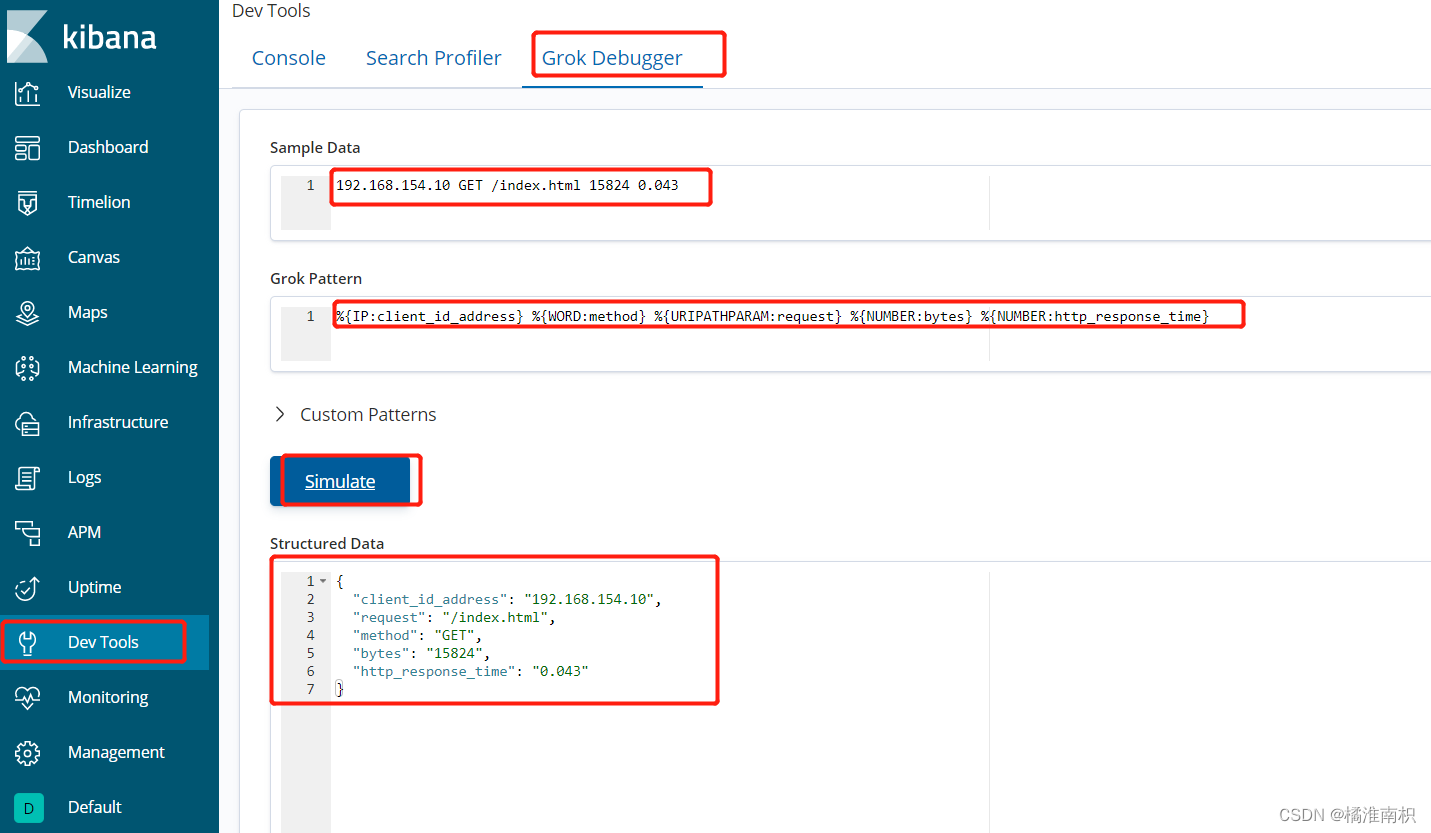
中的数字当成数字类型存储在一个指定的变量当中,比如响应时间http_response_time,假设event log record 如下:
messages: 192.168.154.10 GET /index.html 15824 0.043
可以使用如下grok pattern来匹配这种记录
%{IP:client_id_address} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:http_response_time}
自定义表达式调用
语法: (?<field_name>pattern)
举例:捕获10或11和长度的十六进制数的queue_id可以使用表达式(?<queue_id>[0-9A-F]{10,11})
messages: 192.168.154.10 GET /index.html 15824 0.043
(?<remote_addr>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) (?<http_method>[A-Z]+) (?<request_uri>/.*) (?<response_bytes>[0-9]+) (?<response_time>[[0-9]\.]+)

对日志来进行字段分割

使用Dev Tools调试
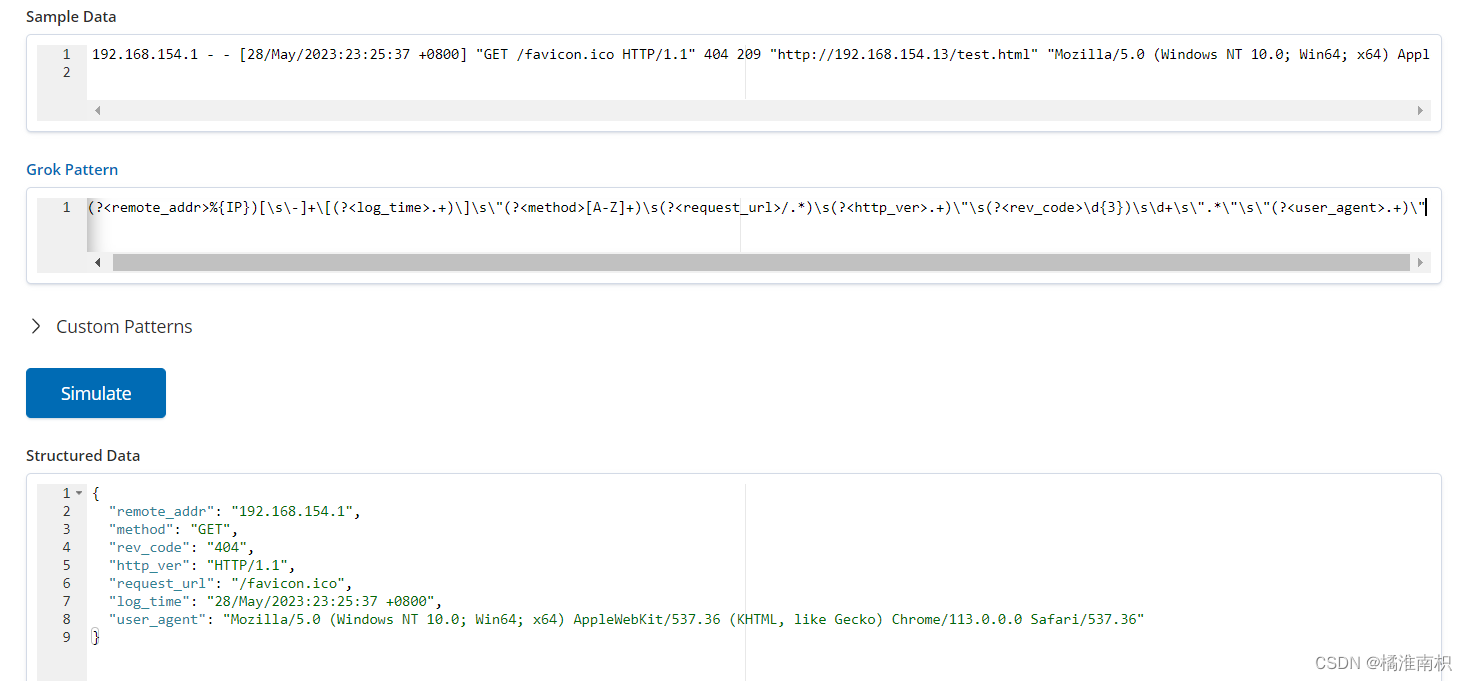
192.168.154.1 - - [28/May/2023:23:25:37 +0800] "GET /favicon.ico HTTP/1.1" 404 209 "http://192.168.154.13/test.html" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"(?<remote_addr>%{IP})[\s\-]+\[(?<log_time>.+)\]\s\"(?<method>[A-Z]+)\s(?<request_url>/.*)\s(?<http_ver>.+)\"\s(?<rev_code>\d{3})\s\d+\s\".*\"\s\"(?<user_agent>.+)\"
cd /etc/logstash/conf.dvim filebeat.conf
input {beats {port => "5044"}
}
filter {grok {match => ["message", "(?<remote_addr>%{IP})[\s\-]+\[(?<log_time>.+)\]\s\"(?<method>[A-Z]+)\s(?<request_url>/.*)\s(?<http_ver>.+)\"\s(?<rev_code>\d{3})\s\d+\s\".*\"\s\"(?<user_agent>.+)\""]}
}output {elasticsearch {hosts => ["192.168.154.10:9200","192.168.154.11:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}logstash -f filebeat.conf


mutate 数据修改插件
它提供了丰富的基础类型数据处理能力。可以重命名,删除,替换和修改事件中的字段。
Mutate 过滤器常用的配置选项

示例:将字段old_field重命名为new_field
filter {mutate {#写法1,使用中括号括起来rename => ["old_field" => "new_field"]#写法2,使用大括号括起来rename => { "old_field" => "new_field" }}
}
添加字段
filter {mutate {add_field => {"f1" => "field1""f2" => "field2"}}
}
将字段删除
filter {mutate {remove_field => ["messages","@version","tags"]}
}
将fileName1字段数据类型转换成string类型,filedName2字段数据类型转换成float类型
filter {mutate {#写法1,使用中括号括起来convert => ["filedName1","string"]#写法2,使用大括号括起来convert => { "filedName2","float" }}
}
将filedName字段中所有 “/” 字符替换为"_"
filter {mutate {gsub => ["filedName","/","_"]}
}
multiline 多行合并插件
java错误日志一般都是一条日志很多行的,会把堆栈信息打印出来,当经过 logstash 解析后,每一行都会当做一条记录放到 ES,那这种情况肯定是需要处理的。这里就需要使用 multiline 插件,对属于同一条日志的记录进行拼接。
安装 multiline 插件
在线安装插件
cd /usr/share/logstash
bin/logstash-plugin install logstash-filter-multiline离线安装插件
先在有网的机器上在线安装插件,然后打包,拷贝到服务器,执行安装命令
bin/logstash-plugin preepare-offline-pack --overwrite --output logstash-filter-multiline.zip logstash-filter-multilinebin/logstash-plugin install file:///usr/share/logstash/logstash-filter-multiline.zip检查下插件是否安装成功,可以执行一下命令查看插件列表
bin/logstash-plugin list
使用 multiline 插件
第一步:每一条日志的第一行开头都是一个时间,可以用时间的正则表达式匹配到第一行
第二步:然后将后面每一行的日志与第一行合并。
第三步:当遇到某一行的开头是可以匹配正则表达式的时间的,就停止第一条日志的合并,开始合并第二条日志。
第四步:重复第二步和第三步。
filter {multiline {pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}" negate => truewhat => "previous"}
}
- pattern:用来匹配文本的表达式,也可以是grok表达式
- what:如果pattern匹配成功的话,那么匹配行是归属于上一个事件,还是归属于下一个事件。previous:归属于上一个事件,向上合并。
- negate:是否对pattern的结果取反。false:不取反,是默认值。true:取反。将多行事件扫描过程中的行匹配逻辑取反(如果pattern匹配失败,则认为当前行是多行事件的组成部分)
date 时间处理插件
用于分析字段中的日期,然后使用该日期或时间戳作为事件的logstash时间戳。
在Logstash产生了一个Event对象的时候,会给该Event设置一个时间,字段为"@timestamp",同时,我们的日志内容一般也会有时间,但是这两个时间是不一样的,因为日志内容的时间是该日志打印出来的时间,而"@timestamp"字段的时间是input插件接收到了一条数据并创建Event的时间,所有一般来说的话"@timestamp"的时间要比日志内容的时间晚一点,因为Logstash监控数据变化,数据输入,创建Event导致的时间延迟。这两个时间都可以使用,具体要根据自己的需求来定。
filter {date {match => ["access_time","dd/MMM/YYYY:HH:mm:ss Z","UNIX","yyyy-MM-dd HH:mm:ss","dd-MMM-yyyy HH:mm:ss"]target => "@timestamp"timezone => "Asia/Shanghai"}
}
- match:用于配置具体的匹配内容规则,前半部分内容表示匹配实际日志当中的时间戳的名称,后半部分则用于匹配实际日志当中的时间戳格式,这个地方是整条配置的核心内容,如果此处规则匹配是无效的,则生成后的日志时问戳将会被input插件读取的时间替代。如果时间格式匹配失败,会生成一个tags字段,字段值为 _dateparsefailure,需要重新检查上边的match配置解析是否正确。
- target: 将匹配的时间戳存储到给定的目标字段中。如果未提供,则默认更新事件的@timestamp字段。
- timezone: 当需要配置的date里面没有时区信息,而且不是UTC时间,需要设置timezone参数。