排序
1. 冒泡排序
>> 冒泡排序的思想
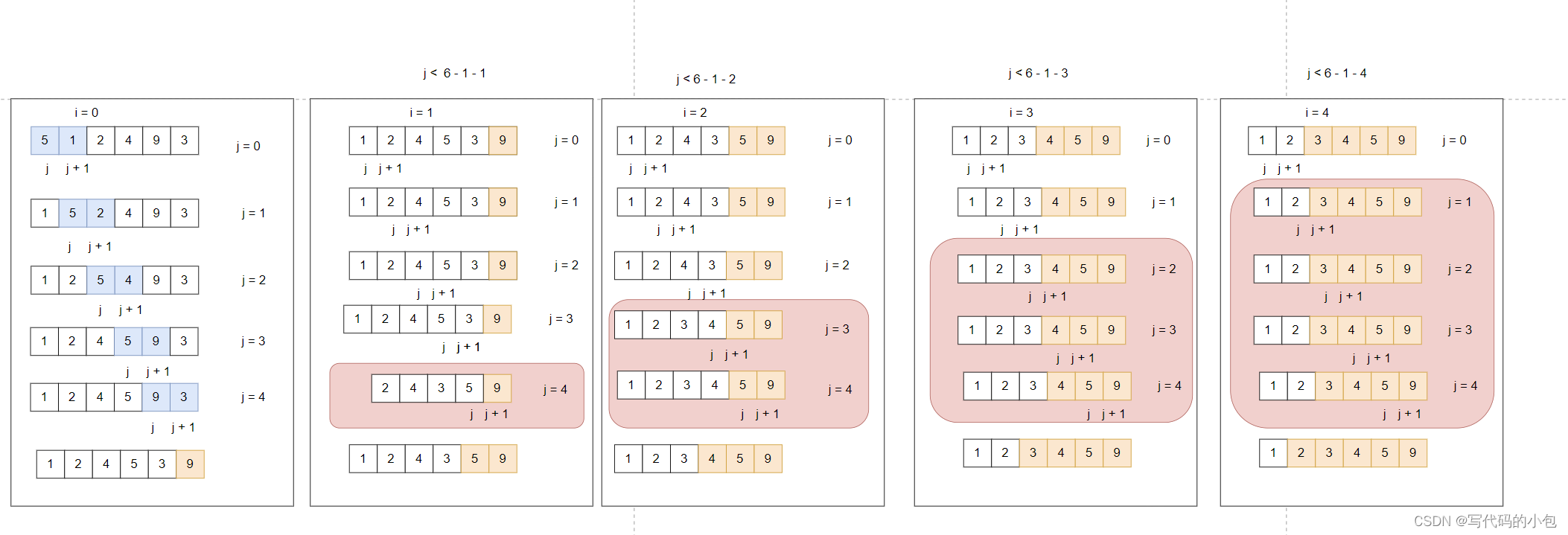
冒泡排序是一种简单的排序算法,其基本思想是通过多次遍历待排序序列,依次比较相邻的元素并交换位置,使得每次遍历后最大(或最小)的元素冒泡到序列的末尾。具体步骤如下:
- 从待排序序列的第一个元素开始,依次比较相邻的两个元素。
- 如果前一个元素大于后一个元素,则交换这两个元素的位置,使得较大的元素向后移动。
- 继续比较下一对相邻元素,重复上述操作,直到遍历到序列的倒数第二个元素。
- 重复执行上述操作,每次遍历使得最大的元素冒泡到序列的末尾。
- 重复以上步骤,直到所有元素都排序完成。
冒泡排序的时间复杂度为
O(n^2),其中n为待排序序列的长度。虽然冒泡排序的时间复杂度较高,在处理大规模数据时效率较低,但由于其简单直观的思想和实现方式,适用于小规模数据的排序任务。
>> 冒泡排序代码实现
public class BubbleSorting {public static void main(String[] args) {int[] arr = {46, 28, 69, 39, 4, 23, 76, 84, 78, 81, 18, 91, 27, 52};// 冒泡排序for (int i = 0; i < arr.length - 1; i ++) {for (int j = 0; j < arr.length - 1 - i; j ++) {if (arr[j] > arr[j + 1]) {arr[j] = arr[j] ^ arr[j +1];arr[j+1] = arr[j] ^ arr[j +1];arr[j] = arr[j] ^ arr[j +1];}}}System.out.println(Arrays.toString(arr));}
}
// 输出:[4, 18, 23, 27, 28, 39, 46, 52, 69, 76, 78, 81, 84, 91]
2. 选择排序
>> 选择排序的思想

选择排序的思想是通过不断地选择未排序序列中的最小(或最大)元素,并将其放到已排序序列的末尾,逐步构建有序序列。具体步骤如下:
- 首先,将待排序序列分为两部分:已排序序列和未排序序列。初始时,已排序序列为空,未排序序列包含待排序的所有元素。
- 在未排序序列中找到最小(或最大)的元素,记为最小值(或最大值)。
- 将最小值与未排序序列的第一个元素进行交换,将最小值放到已排序序列的末尾。
- 缩小未排序序列的范围,将已排序序列增加一个元素,重复步骤2和步骤3,直到未排序序列为空。
通过不断地选择未排序序列中的最小(或最大)元素,并将其放到已排序序列的末尾,最终可以得到一个有序序列。
选择排序的特点是简单直观,代码实现相对较简单,但效率较低。其时间复杂度为
O(n^2),其中n是待排序元素的数量。无论待排序序列的初始顺序如何,选择排序的比较次数和交换次数都是固定的,因此它的时间复杂度相对稳定。然而,由于每次都要进行交换操作,选择排序在大规模数据的排序过程中效率较低,一般不适用于大规模或需要高效排序的场景。
>> 选择排序代码实现
public class SelectSort2 {public static void main(String[] args) {int[] arr = {46, 28, 69, 39, 4, 23, 76, 84, 78, 81, 18, 91, 27, 52};// 选择排序for (int i = 0; i < arr.length-1; i++) {int min = i;for (int j = i + 1; j < arr.length; j++) {if (arr[min] > arr[j]) {min = j;}}int temp = arr[i];arr[i] = arr[min];arr[min] = temp;}System.out.println(Arrays.toString(arr));}
}
// 输出:[4, 18, 23, 27, 28, 39, 46, 52, 69, 76, 78, 81, 84, 91]
3. 插入排序
>> 插入排序的思想
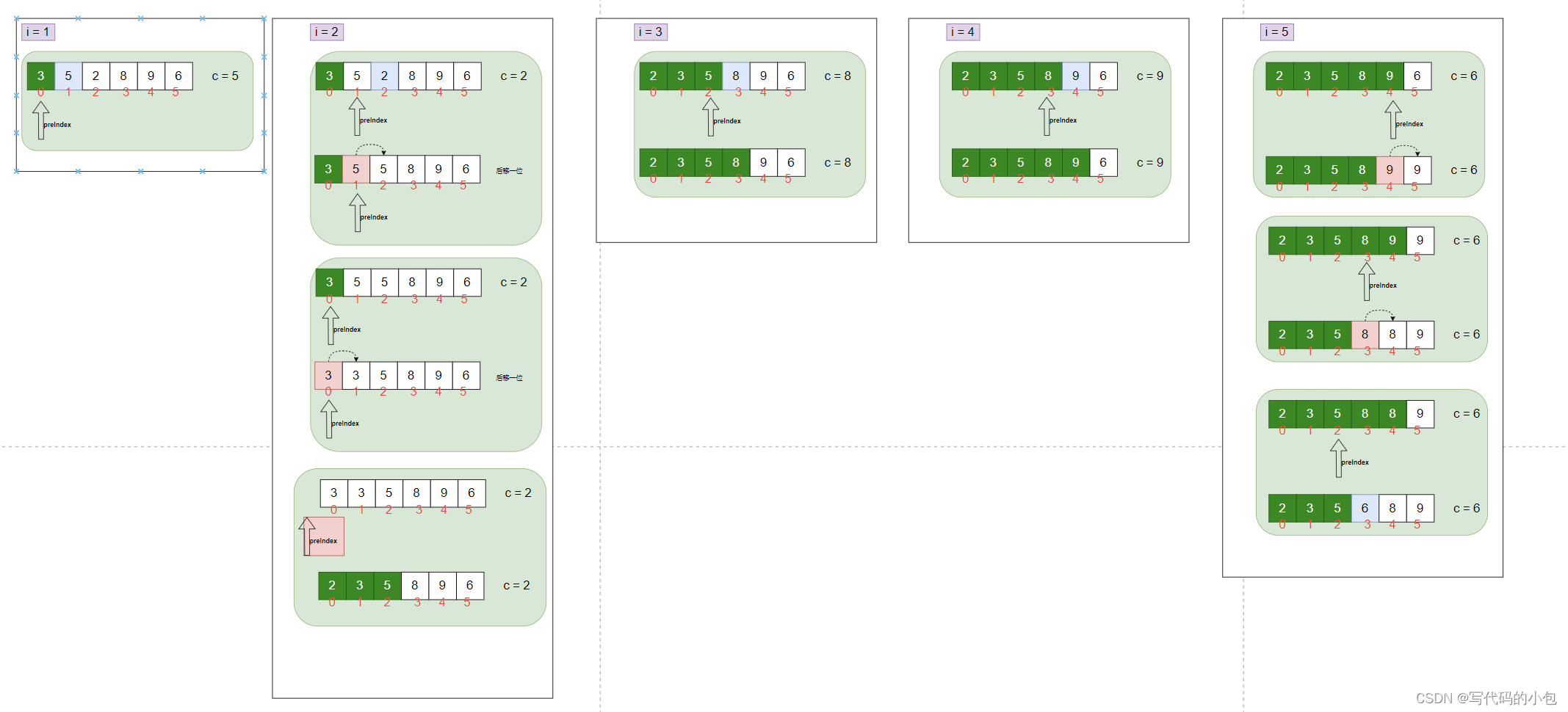
插入排序的思想是将待排序的元素逐个插入到已排序序列中的正确位置,从而逐步构建有序序列。具体步骤如下:
- 首先,将待排序序列分为两部分:已排序序列和未排序序列。初始时,已排序序列只包含第一个元素,未排序序列包含剩余的元素。
- 从未排序序列中取出第一个元素,将其视为当前元素。
- 将当前元素与已排序序列从右往左进行比较,找到合适的位置插入。
- 将当前元素插入到已排序序列中的正确位置,同时调整已排序序列的元素位置,使其仍然保持有序。
- 重复步骤2至步骤4,直到未排序序列中的所有元素都被插入到已排序序列中。
通过不断地将待排序序列中的元素插入到已排序序列的正确位置,最终可以得到一个有序序列。
插入排序的特点是相对于其他简单排序算法(如选择排序、冒泡排序),效率要高一些。其时间复杂度为O(n^2),其中n是待排序元素的数量。插入排序在对近乎有序的数据进行排序时,效果较好,而在对大规模乱序数据进行排序时,效率相对较低。尽管如此,插入排序的实现简单,对于小规模或部分有序的数据集合,仍然是一种有效的排序方法。
>> 插入排序代码实现
public class InsertSort {public static void main(String[] args) {int[] arr = {46, 28, 69, 39, 4, 23, 76, 84, 78, 81, 18, 91, 27, 52};for (int i = 1; i < arr.length; i++) {int index = i - 1;int num = arr[i];while (index >= 0 && num < arr[index]) {arr[index + 1] = arr[index];index --;}arr[index + 1] = num;}System.out.println(Arrays.toString(arr));}
}
4. 二分法查找
>> 二分法查找的思想
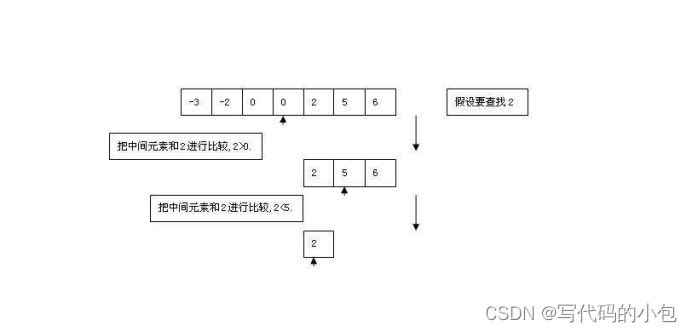
二分法查找是一种高效的查找算法,适用于已排序的数组。其基本思想是将待查找区间不断二分,通过比较目标值与中间元素的大小关系来确定下一步查找的范围。具体步骤如下:
- 确定查找区间的起始和结束位置,通常为整个数组的起始和结束位置。
- 计算查找区间的中间位置 mid,可以取 (start + end) / 2。
- 比较目标值与中间元素的大小关系:
- 如果目标值等于中间元素,那么就找到了目标值,返回索引。
- 如果目标值小于中间元素,说明目标值可能在左半部分,更新结束位置为 mid - 1。
- 如果目标值大于中间元素,说明目标值可能在右半部分,更新起始位置为 mid + 1。
- 重复步骤 2 和步骤 3,直到目标值找到或者查找区间为空(起始位置大于结束位置)为止。
二分法查找的时间复杂度为
O(log n),其中 n 是待查找区间内元素的个数。这使得它成为处理大规模数据的一种高效算法。
需要注意的是,二分法查找要求待查找的数组必须是有序的,否则查找结果将不可靠。另外,如果数组中存在重复元素,二分查找可能无法找到第一个或最后一个目标值的索引,需要进行额外的处理。
>> 二分法查找代码实现
public class BinarySearch {public static void main(String[] args) {int[] arr = {1,2,3,4,5,6};int key = 2;int index = binarySearch(arr, key);System.out.println(arr[index]);}// 二分法查找static int binarySearch(int[] arr, int key) {int left = 0, right = arr.length - 1;while (left <= right) {int mid = (left + right) >> 1;if (arr[mid] > key) {right = mid - 1;} else if (arr[mid] < key) {left = mid +1;} else {return mid;}}return -1;}
}