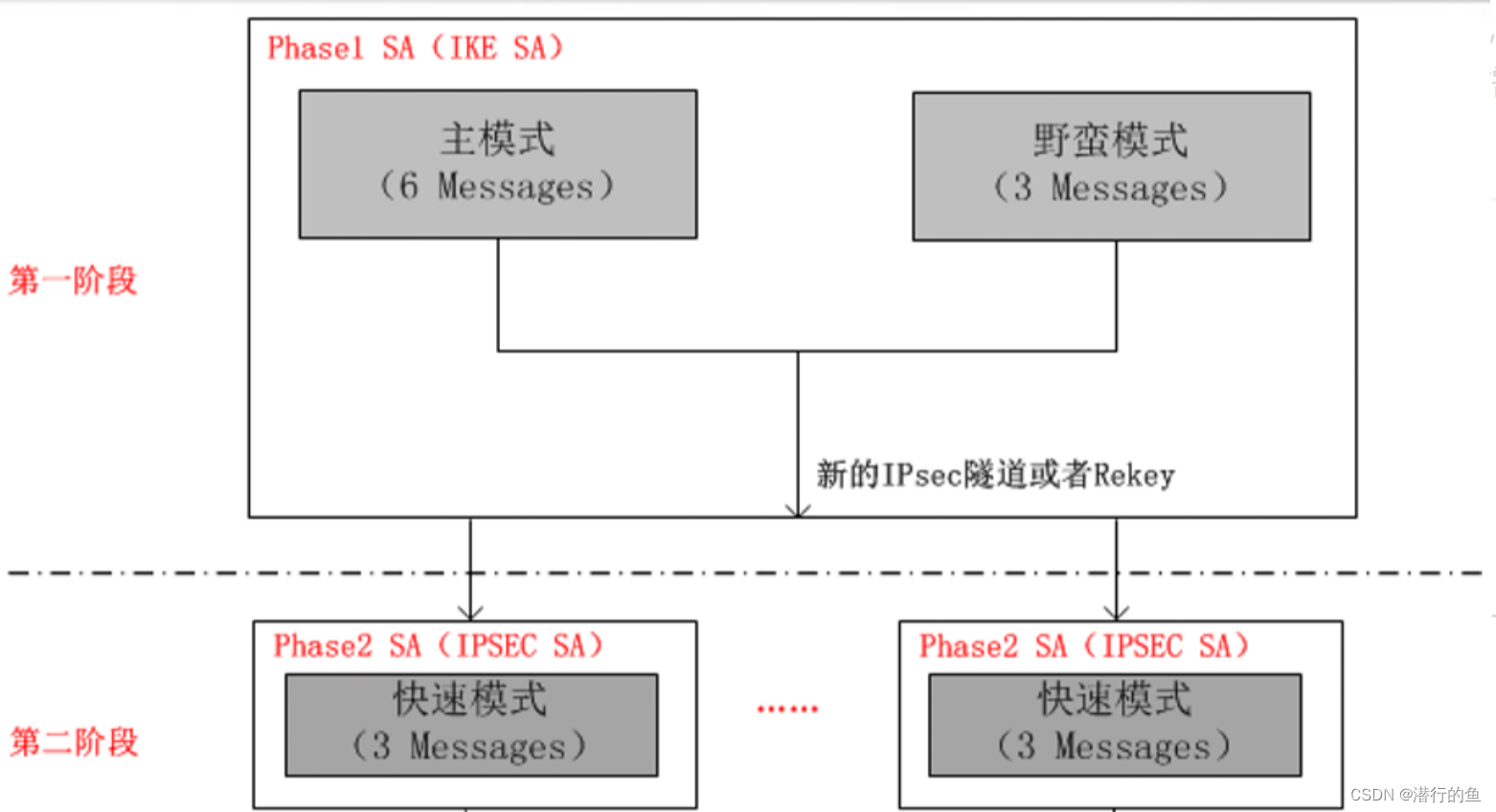
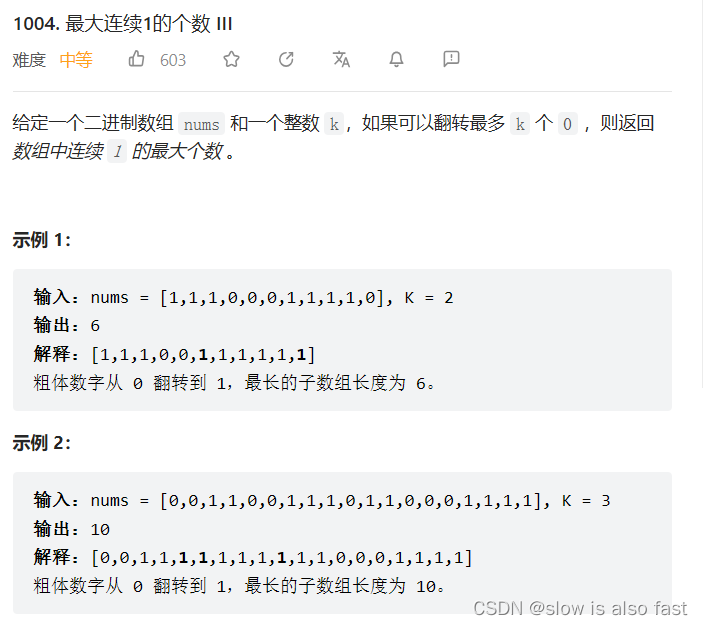
文章目录
- 一、分割|语义相关(6篇)
- 1.1 Point2Mask: Point-supervised Panoptic Segmentation via Optimal Transport
- 1.2 Weakly Supervised 3D Instance Segmentation without Instance-level Annotations
- 1.3 LiDAR-Camera Panoptic Segmentation via Geometry-Consistent and Semantic-Aware Alignment
- 1.4 ReIDTrack: Multi-Object Track and Segmentation Without Motion
- 1.5 Focus on Content not Noise: Improving Image Generation for Nuclei Segmentation by Suppressing Steganography in CycleGAN
- 1.6 NuInsSeg: A Fully Annotated Dataset for Nuclei Instance Segmentation in H&E-Stained Histological Images
一、分割|语义相关(6篇)
1.1 Point2Mask: Point-supervised Panoptic Segmentation via Optimal Transport
Point2掩码:基于最优传输的点监督全景分割
https://arxiv.org/abs/2308.01779

弱监督图像分割最近引起了越来越多的研究关注,旨在避免昂贵的像素级标记。 在本文中,我们提出了一种有效的方法,即 Point2Mask,仅使用每个目标的单个随机点注释进行训练即可实现高质量的全景预测。 具体来说,我们将全景伪掩模生成公式化为最佳传输(OT)问题,其中每个真实(gt)点标签和像素样本分别定义为标签供应商和消费者。 运输成本是通过引入的面向任务的地图来计算的,该地图侧重于各种事物和物品目标之间的类别和实例差异。 此外,提出了一种基于质心的方案来为每个gt点供应商设置准确的单元数量。 因此,伪掩码生成转化为以全局最小运输成本寻找最佳运输计划,这可以通过 Sinkhorn-Knopp 迭代来解决。 Pascal VOC 和 COCO 上的实验结果证明了我们提出的 Point2Mask 方法在点监督全景分割方面的良好性能。
1.2 Weakly Supervised 3D Instance Segmentation without Instance-level Annotations
无实例级标注的弱监督3D实例分割
https://arxiv.org/abs/2308.01721

随着深度学习的出现,3D语义场景理解任务取得了巨大成功,但往往需要大量手动标注的训练数据。 为了减轻标注成本,我们提出了第一个弱监督的 3D 实例分割方法,该方法只需要分类语义标签作为监督,而不需要实例级标签。 所需的语义注释可以是密集的,也可以是极其稀疏的(例如总点的 0.02%)。 即使没有任何与实例相关的基本事实,我们也设计了一种将点云分解为原始片段的方法,并找到用于学习实例质心的最有信心的样本。 此外,我们使用伪实例构建了一个重构的数据集,该数据集用于学习我们定义的多级形状感知对象信号。 采用非对称对象推理算法,以不同的策略处理核心点和边界点,生成高质量的伪实例标签来指导迭代训练。 实验表明,我们的方法可以达到与最近的完全监督方法相当的结果。 通过从分类语义标签生成伪实例标签,我们设计的方法还可以帮助现有的方法以降低注释成本来学习 3D 实例分割。
1.3 LiDAR-Camera Panoptic Segmentation via Geometry-Consistent and Semantic-Aware Alignment
基于几何一致和语义感知的激光雷达摄像机全景图像分割
https://arxiv.org/abs/2308.01686

3D 全景分割是一项具有挑战性的感知任务,需要语义分割和实例分割。 在此任务中,我们注意到图像可以提供丰富的纹理、颜色和辨别信息,这可以补充 LiDAR 数据以显着提高性能,但它们的融合仍然是一个具有挑战性的问题。 为此,我们提出了 LCPS,第一个激光雷达相机全景分割网络。 在我们的方法中,我们分三个阶段进行激光雷达-相机融合:1)异步补偿像素对齐(ACPA)模块,用于校准传感器之间异步问题引起的坐标未对准; 2)语义感知区域对齐(SARA)模块,将一对一的点像素映射扩展到一对多的语义关系; 3)点到体素特征传播(PVP)模块,集成了整个点云的几何和语义融合信息。 我们的融合策略比 NuScenes 数据集上仅使用 LiDAR 的基线提高了约 6.9% 的 PQ 性能。 广泛的定量和定性实验进一步证明了我们新颖框架的有效性。
1.4 ReIDTrack: Multi-Object Track and Segmentation Without Motion
ReIDTrack:无运动的多目标跟踪与分割
https://arxiv.org/abs/2308.01622

近年来,主流的多目标跟踪(MOT)和分割(MOTS)方法主要遵循检测跟踪范式。 基于 Transformer 的端到端(E2E)解决方案为 MOT 和 MOTS 带来了一些想法,但它们无法在主要的 MOT 和 MOTS 基准测试中实现新的最先进(SOTA)性能。 检测和关联是检测跟踪范式的两个主要模块。 关联技术主要依赖于运动和外观信息的组合。 随着深度学习最近的发展,检测和外观模型的性能迅速提高。 这些趋势让我们考虑是否可以仅基于高性能检测和外观模型来实现SOTA。 我们的论文主要基于 CBNetV2 来探索这个方向,以 Swin-B 作为检测模型,MoCo-v2 作为自监督外观模型。 运动信息和 IoU 映射在关联过程中被删除。 我们的方法在 CVPR2023 WAD 研讨会的 MOTS 赛道上获得第一名,并在 MOT 赛道上获得第二名。 我们希望我们简单有效的方法能为 MOT 和 MOTS 研究界提供一些见解。 源代码将在此git仓库下发布。
1.5 Focus on Content not Noise: Improving Image Generation for Nuclei Segmentation by Suppressing Steganography in CycleGAN
关注内容而不是噪声:通过抑制CycleGan中的隐写来改进核分割的图像生成
https://arxiv.org/abs/2308.01769

在显微镜图像中注释细胞核以训练神经网络是一项艰巨的任务,需要专业知识,并且会受到评估者之间和评估者内部差异的影响,尤其是在荧光显微镜中。 CycleGAN 等生成网络可以反转该过程并为给定掩模生成合成显微镜图像,从而构建合成数据集。 然而,过去的工作报告了掩模和生成图像之间的内容不一致,部分原因是 CycleGAN 通过隐藏高频图像重建的快捷方式信息来最小化其损失,而不是编码所需的图像内容并学习目标任务。 在这项工作中,我们建议通过采用基于 DCT 的低通滤波,从生成的图像中删除隐藏的快捷方式信息(称为隐写术)。 我们表明,这增加了生成的图像和循环掩模之间的一致性,并评估下游核分割任务的合成数据集。 与普通的 CycleGAN 相比,我们的 F1 分数提高了 5.4 个百分点。 将先进的正则化技术集成到 CycleGAN 架构中可能有助于缓解与隐写术相关的问题,并为细胞核分割生成更准确的合成数据集。
1.6 NuInsSeg: A Fully Annotated Dataset for Nuclei Instance Segmentation in H&E-Stained Histological Images
NuInsSeg:一种用于H&E染色组织图像核实例分割的全标注数据集
https://arxiv.org/abs/2308.01760

在计算病理学中,自动细胞核实例分割在整个切片图像分析中起着至关重要的作用。 虽然针对此任务提出了许多计算机化方法,但与经典机器学习和图像处理技术相比,有监督深度学习 (DL) 方法已显示出卓越的分割性能。 然而,这些模型需要完全注释的数据集进行训练,而获取这些数据集具有挑战性,尤其是在医学领域。 在这项工作中,我们发布了苏木精和曙红 (H&E) 染色组织学图像中最大的完全手动注释的细胞核数据集之一,称为 NuInsSeg。 该数据集包含 665 个图像块,其中包含来自 31 个人类和小鼠器官的 30,000 多个手动分割的细胞核。 此外,我们第一次为整个数据集提供了额外的模糊区域掩模。 这些模糊区域代表了图像中即使对于人类专家也无法进行精确且确定的手动注释的部分。