Stability AI于7月26号开源了SDXL1.0文生图模型,要知道距离SDXL0.9开源发布也不过一个月,只能说AI发展日新月异。
根据官网介绍,SDXL1.0经过迭代更新,已经是目前世界上最好的图像生成模型
官网根据Discord上的几代实验模型和外部测试,再配合用户的偏好数据,所谓的偏好数据 就是用户更加喜欢哪个模型生成的图像,用数据说话,得出用户最喜欢的模型是SDXL1.0
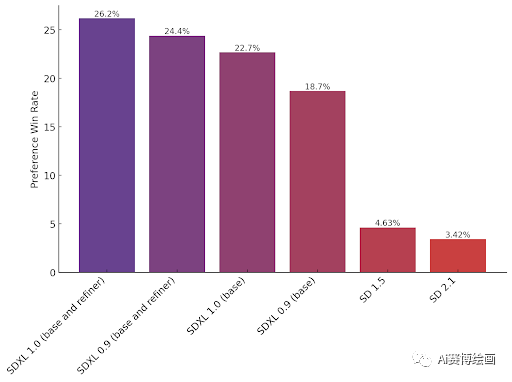
上图中X轴是模型名称,Y轴是用户偏好比例,可以看出SDXL1.0的用户偏好比例为26.2%,上个月发布的SDXL0.9为24.4%,而目前市面上使用最多的基模SD1.5有4.63%,被用户抛弃的SD2.1只有3.42%,这里应该是指纯粹使用SD基础模型,不包含二创模型。
此外官网也对SDXL1.0进行了详细的介绍,SDXL1.0可以生成几乎任何艺术风格的高质量图片,并没有对模型进行固化式训练,从而确保了风格的绝对自由(同时也说明 二次创作模型有更多的发挥空间,能创作出更多的二次模型)
并且SDXL1.0对颜色,对比度和阴影进行了精心调校,这也使得图片的分辨率得到了提升,基础出图支持1024*1024分辨率,分辨率高了,同时图片质量也上去了。

同时官网也对提示词编写进行了介绍,在使用SD1.5时,用户可能需要添加各种正向提示词如(masterpiece, best quality)画质限定词来获得高质量的图片,在SDXL1.0上只需要简单的提示词 就可以获得高质量图片

并且有了专属词的概念,例如红场(The Red Square) 和红场(red square),这两个词语对于图片的生成不再是一样的
官网也对SDXL的技术架构进行了简单的描述
SDXL1.0 也是历代开放模型参数最多的模型之一,SDXL采用了创新的架构,由35亿参数的基础模型和66亿参数细化器组成,
完整模型由用于潜在扩散的专家混合管道组成:第一步,基础模型生成(有噪声的)潜在模型,然后使用专门用于最终去噪步骤的细化模型对其进行进一步处理。请注意,基本模型也可以用作独立模块
这种两阶段架构可实现图像生成的稳健性,而不会影响速度或需要过多的计算资源。
SDXL 1.0 应在具有 8GB VRAM 或现成云实例的消费类 GPU 上有效工作。
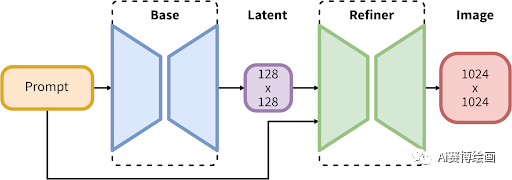
以上是官网的解释,大概意思是SDXL1.0出图稳定性和SDXL的扩展性都进行了大幅度提高,并且使用过程不会占用过多资源(这里可能大部分人都不懂什么意思,反正这次的SDXL1.0用的技术很新也很D就对了,一斤大米干五斤的活)
但是资源占用还是相对而言的,1050TI显卡SD1.5能跑,但是SDXL1.0就无法出图,并且8G显存上进行运行也是比较讲究运气,对硬件要求还是有了较大的提升,毕竟不可能又要马儿跑又不让马儿吃草吧
同时官网也说明了根据SDXL1.0进行炼丹会更加容易,制作自定义模型和自定义lora也会更加友好,但是目前SDXL1.0不支持controlNet,但是会有专属的controlNet给SDXL1.0使用,并且已经在测试当中了,不久后就会推出。(文件夹已经建好了 没错这里特指老滚6)

总结一下:经过个人实践,的确SDXL1.0出图质量会比SD1.5好不少,但是硬件要求也高了不少,只能说干多少活吃多少饭还是成正比的。但是由于没有controlNet和比较高质量的lora支持,目前也只能干一些比较简单的活,但是后面该有的都会有的。
可能大多数人都没有使用过最基础的SD1.5模型,基本都是使用基于SD1.5的二创模型(甚至还有基于SD1.0的),理解不了SDXL1.0的重要性
为了便于大家理解,我们使用SDXL1.0和SD1.5进行生成对比


目前我们大多数使用的模型都是基于V1-5-pruned-emaonly 这个模型二创出来的,那么如果把当前使用的模型的底模切换到质量这么高的SDXL1.0上面,二创出来的模型或者lora也会继承SDXL的高质量出图,而且使用起来也会更加简单,抽卡概率大大提升(当然是基于炼丹技术成熟的情况下)
虽然sdxl1.0的出图质量有了革命性的增长,但是也还未能达Midjourney的程度(很多文章说是会威胁到MJ啦,但是我觉得还是有点差距),不过这个差距也在慢慢缩短,相信不久之后,会有更多基于SDXL1.0的高质量模型和lora,大家还是拭目以待吧。
资料来源:
https://stability.ai/blog/stable-diffusion-sdxl-1-announcement