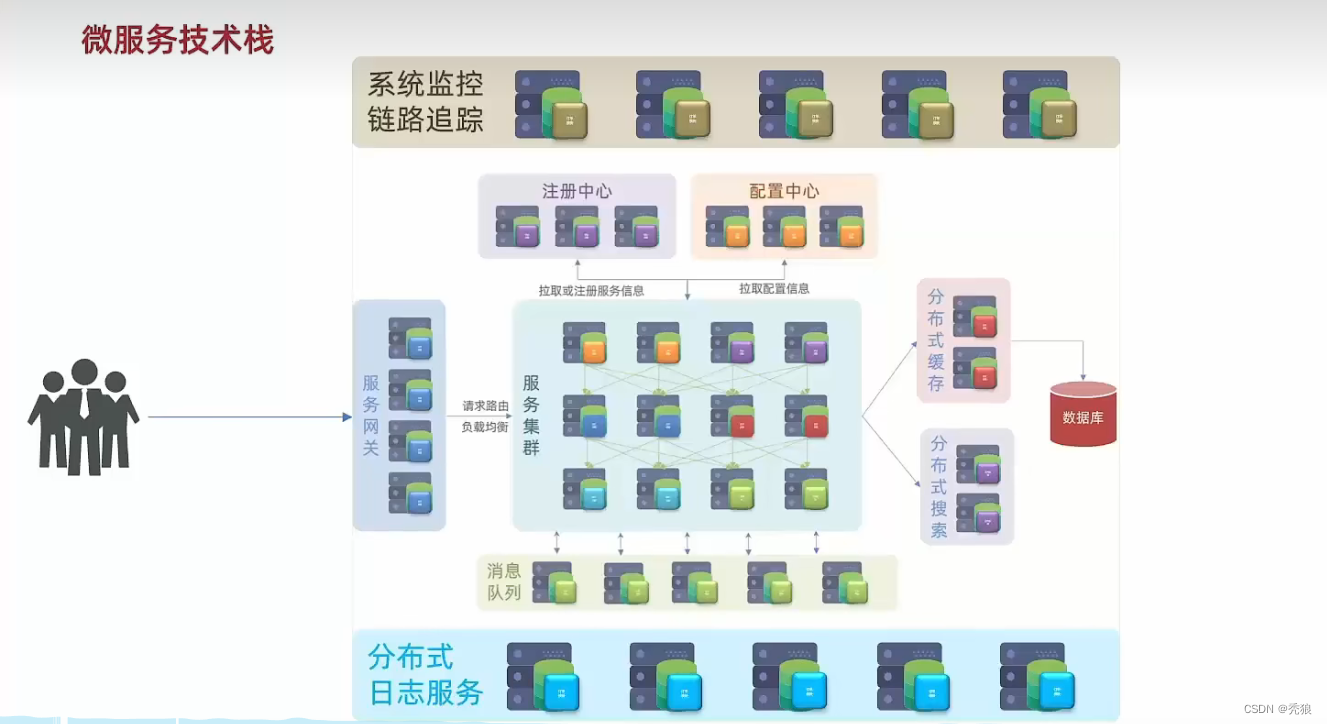
微服务简介
微服务是什么?
微服务是一种架构风格,将一个大型应用程序拆分为一组小型、自治的服务。每个服务都运行在自己独立的进程中,使用轻量级的通信机制(通常是HTTP或消息队列)进行相互之间的通信。这种方式使得每个服务可以独立开发、部署和扩展,同时也降低了整个应用程序的复杂性。微服务架构可以提高系统的可伸缩性、灵活性和可维护性,使得团队可以更快地开发和交付新的功能。
微服务项目结构图
单体的Java项目和分布式的Java项目的区别
单体项目
- 优点:发布简单,开发时无需考虑接口暴露问题。
- 缺点:项目耦合度会随着代码量的增大而提高,可读性底。
- 作用域:面向使用人群小的项目,开发成本底。(个人系统,个人博客,等等)
微服务项目
- 优点:大大降低耦合度,业务模块分布清楚,可读性高。
- 缺点:开发成本远远大于单体项目,需要考虑接口暴露问题。
- 作用域:面向使用人群大的项目。(电商项目,等等)
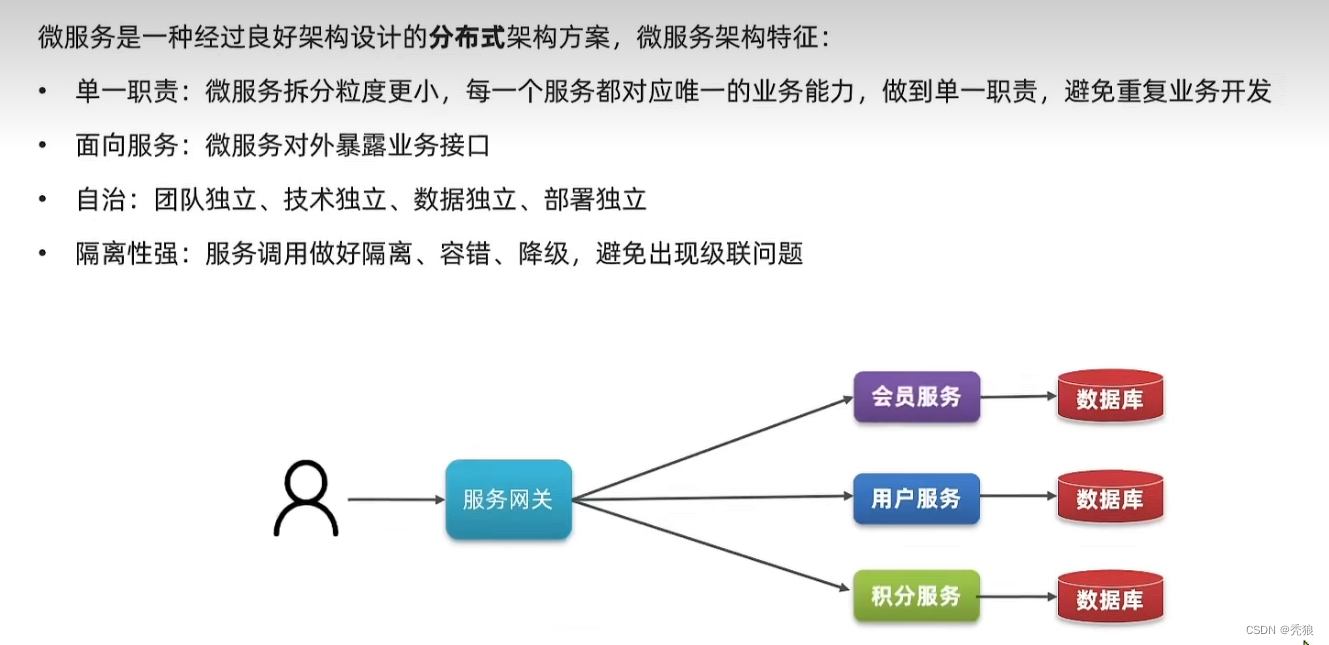
微服务结构
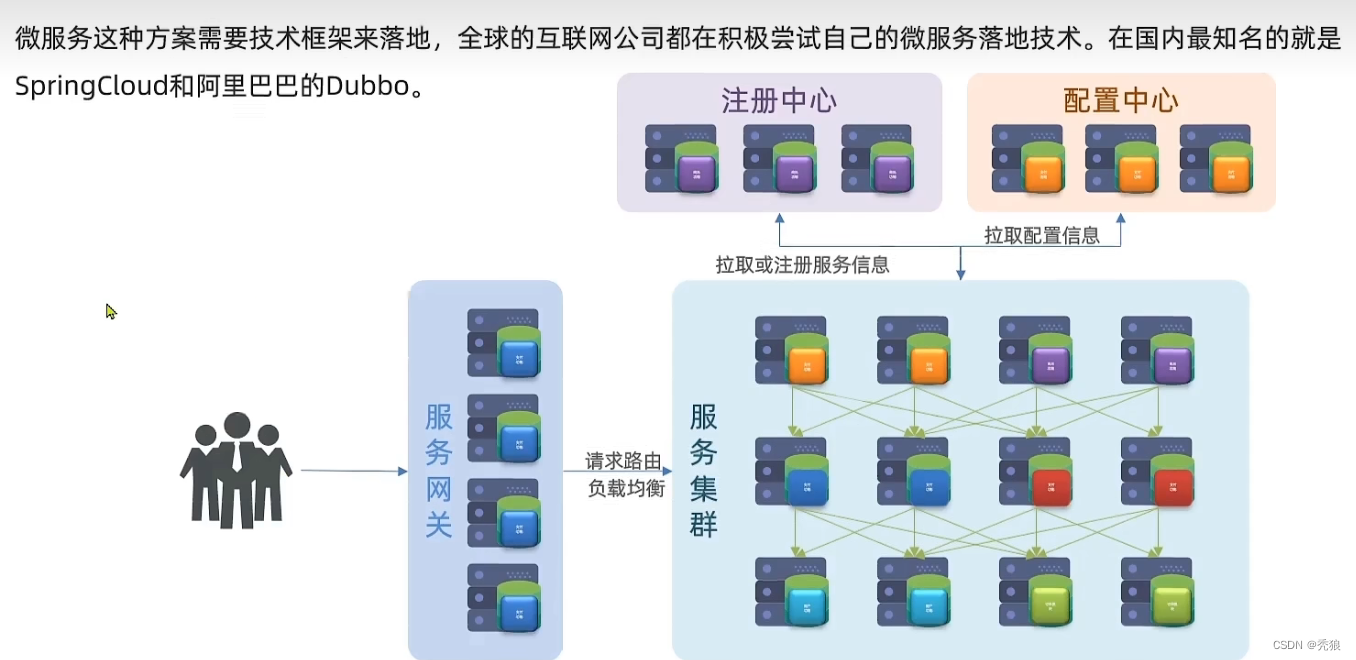
微服务对比

学习环境
jdk1.8,。
springboot版本为:2.3.9.RELEASE。
springcloud版本为:Hoxton.SR10。
eureka
eureka的作用:作为服务中心。
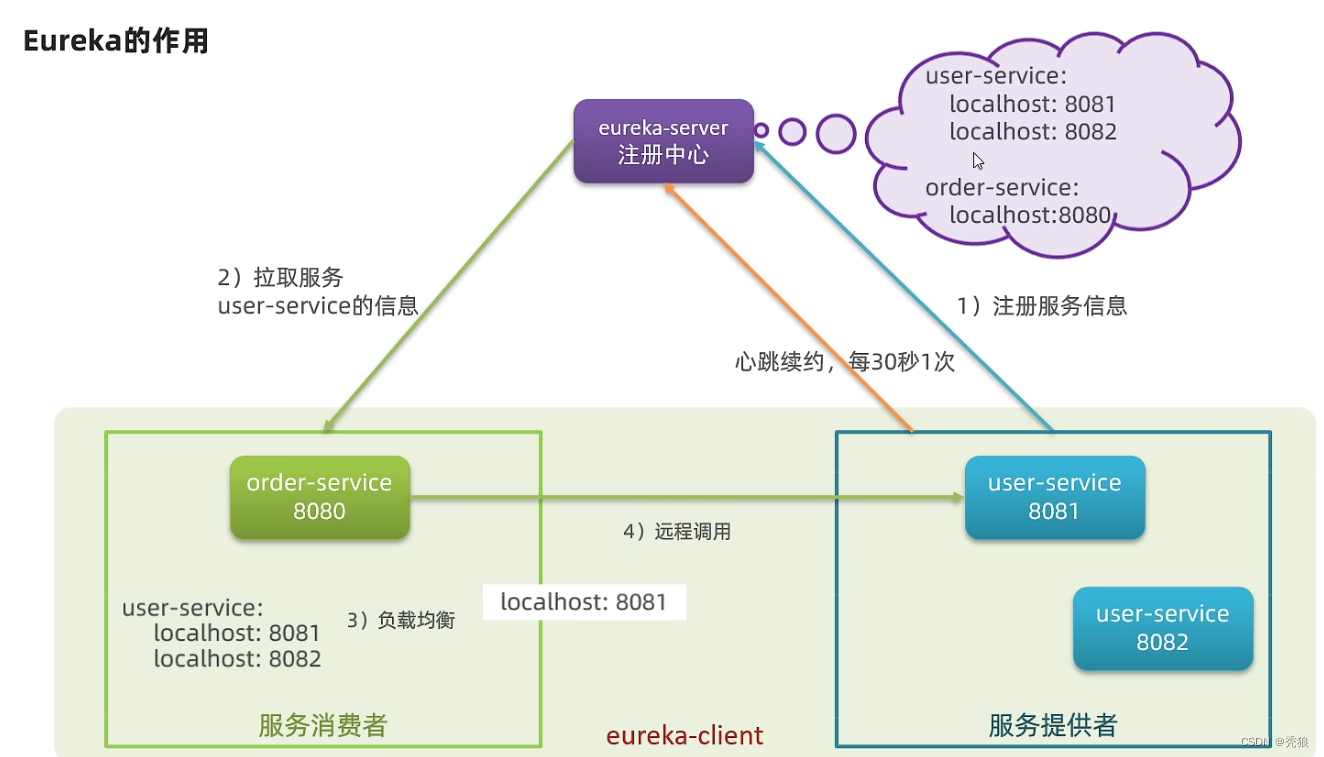
 eureka的使用
eureka的使用
1.创建eureka的注册中心
导入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>在application.yml中配置对应的注册信息
#在注册中心中的名字
spring:application:name: eurekaService
对应的服务端口
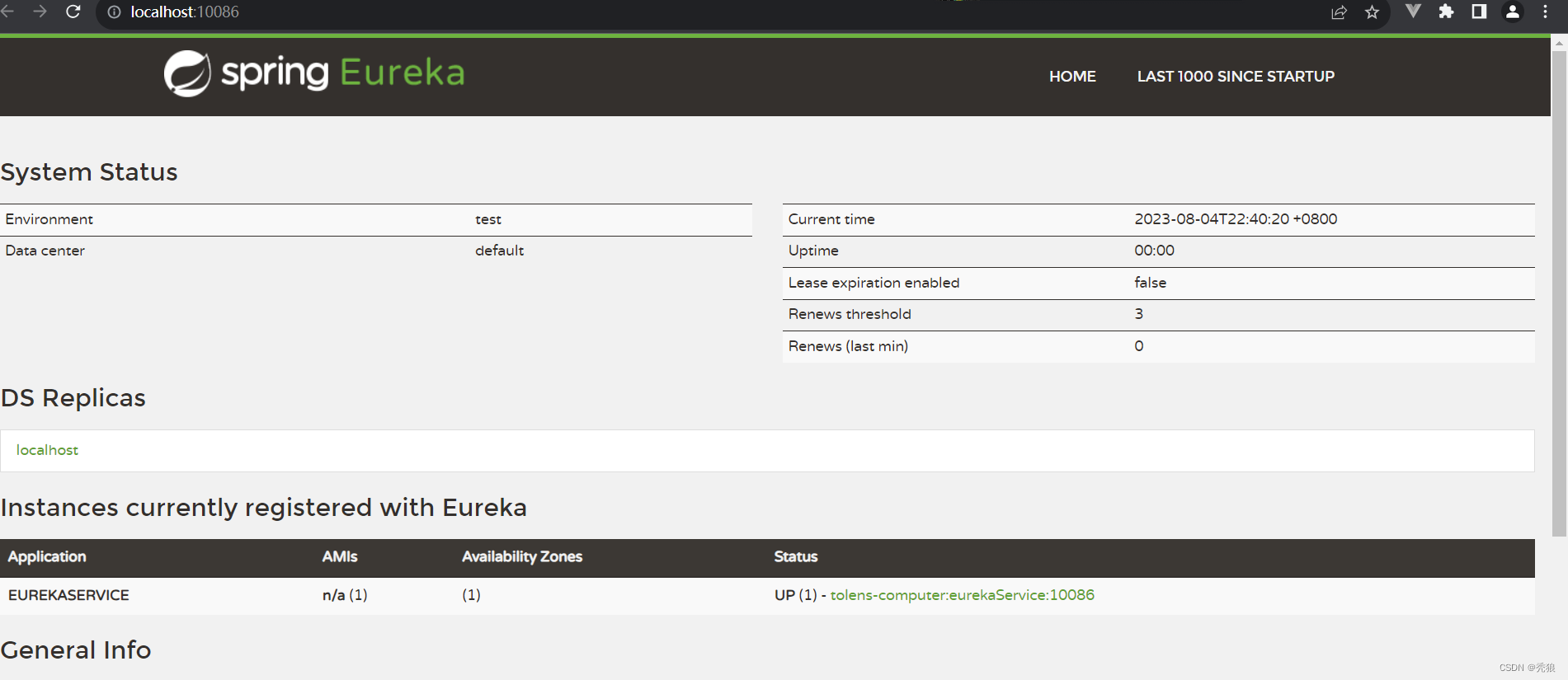
server:port: 10086因为eureka作为服务注册中心,所以也需要将自己注册到服务中心中
eureka:client:service-url:defaultZone: http://localhost:10086/eureka在启动类上添加注解驱动 @EnableEurekaServer
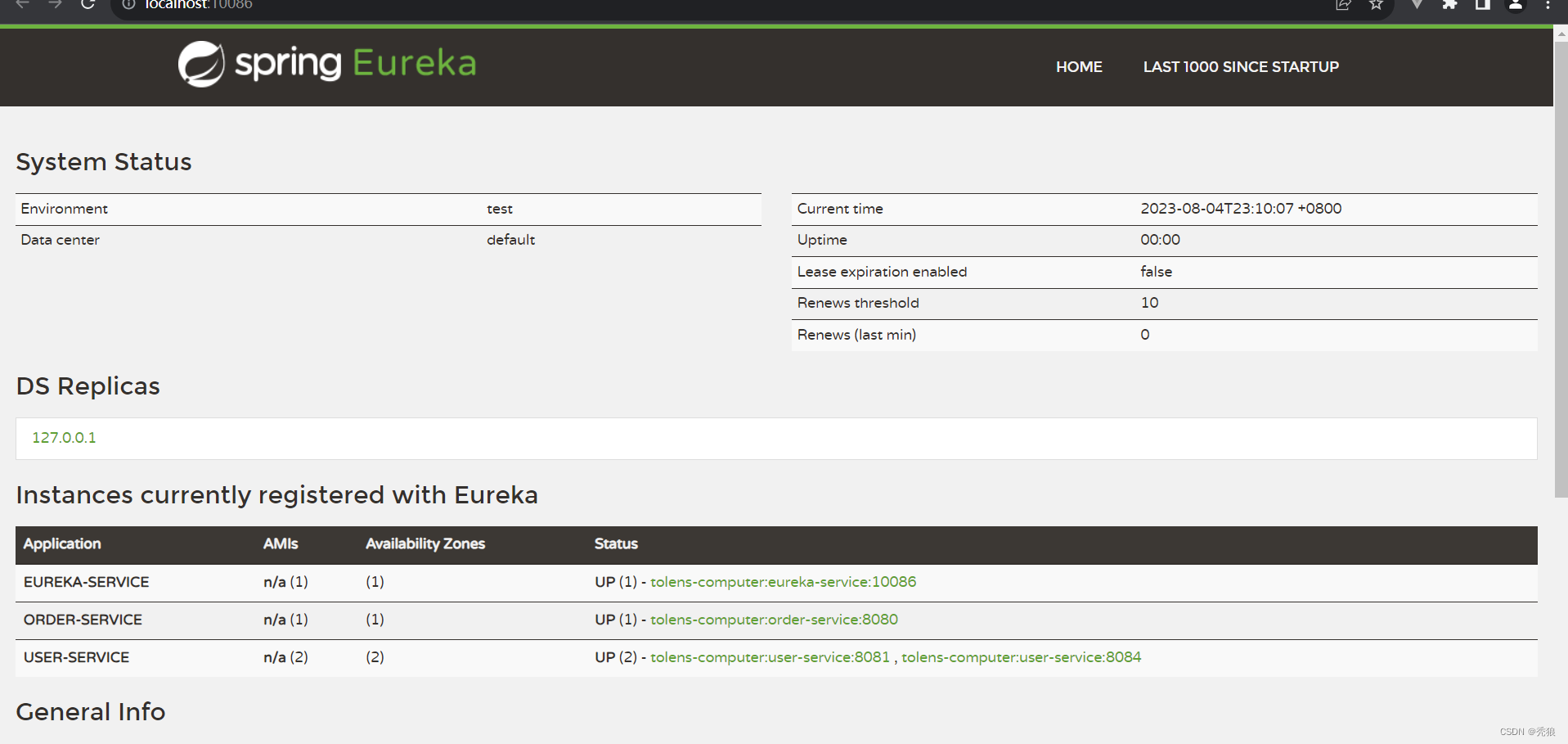
对应的效果图
 2.将服务端和消费端都注册到eureka中。
2.将服务端和消费端都注册到eureka中。
此时服务端和客户端需要添加的依赖为下
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
在application.yml编写注册信息
#要注册到的注册中心位置
eureka:client:service-url:defaultZone: http://localhost:10086/eurekaspring:application:name: ”对应名字“在restTemplate中将原本对应的地址位置修改为在eureka中的要调用的服务名字
注册中心效果图为下:
在未来我们的某个模块不一定只有一个,它可能是多个相同的模块,防止因为宕机的缘故导致服务无法使用。
这里我们就复制一个相同的服务
 在对用的restTemplate的配置类添加 @LoadBalanced
在对用的restTemplate的配置类添加 @LoadBalanced
进行测试,在调用两次接口后发现两个服务都被调用了一次,说明实现了负载均衡。

 Ribbon
Ribbon
Ribbon流程
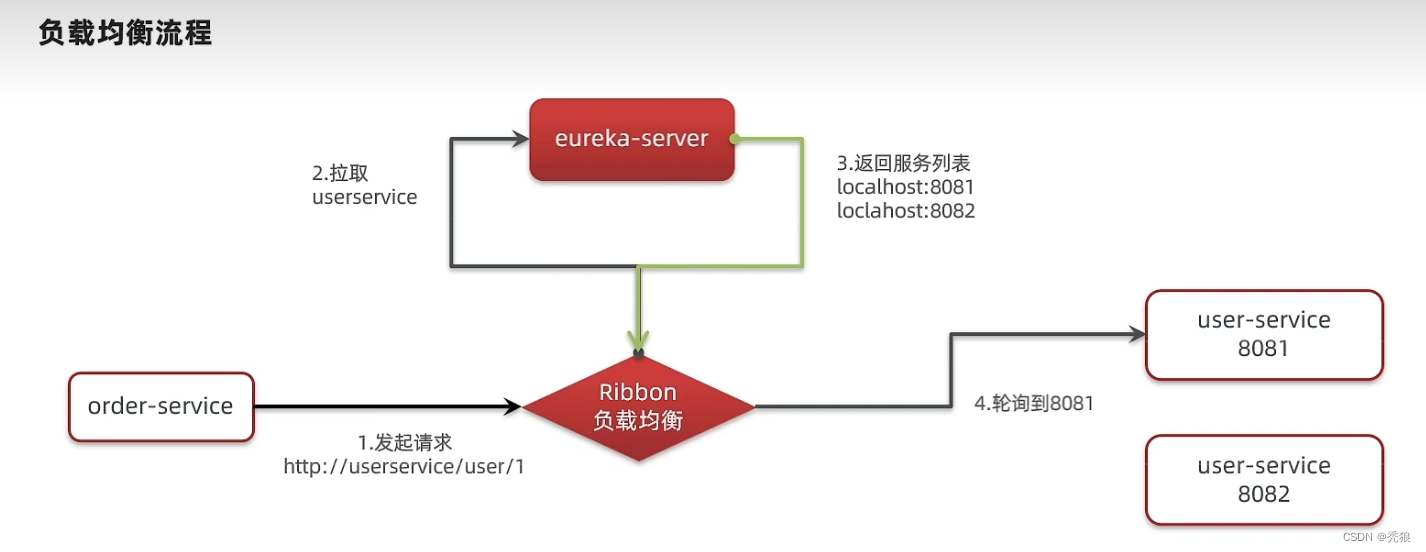
Ribbon负载均衡流程源码
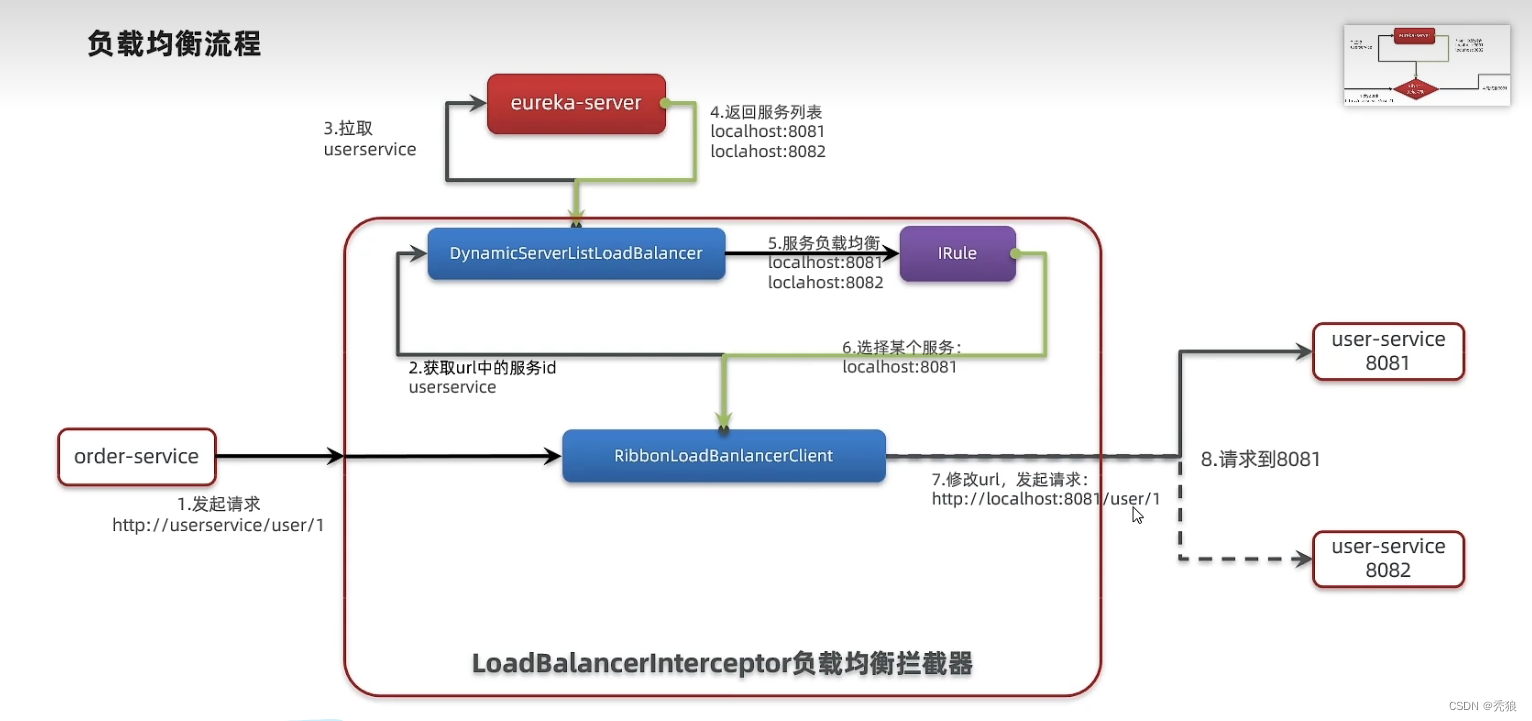
在LoadBalancerInterceptor类中会调用intercept方法,其会获取对应的host名字,通过这个host去注册中心中查找对应的服务地址。
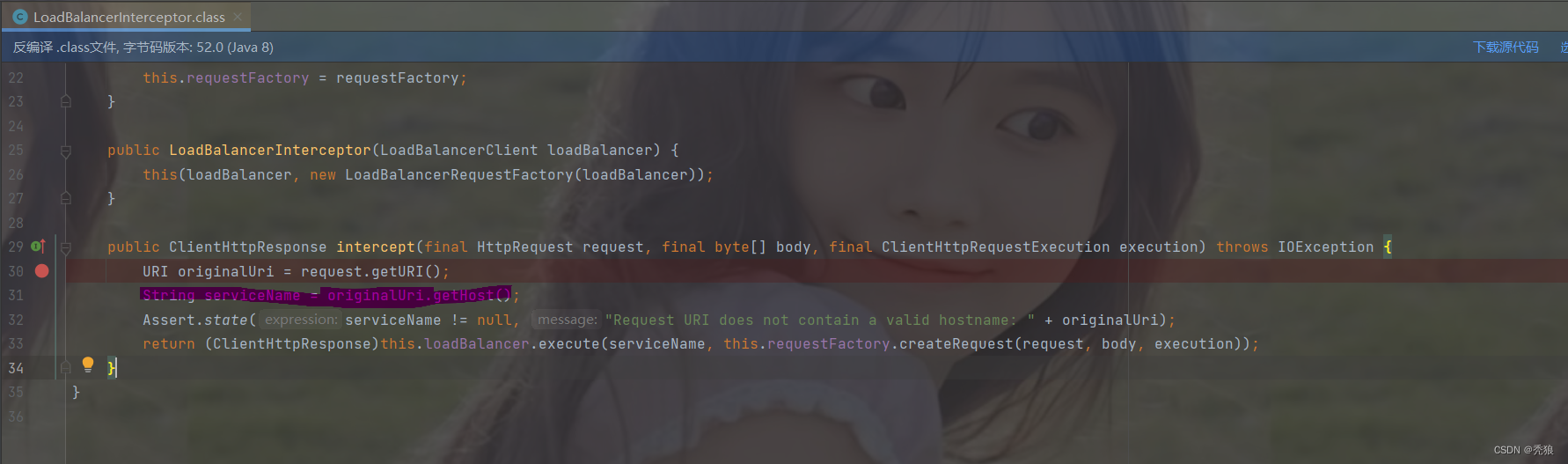
效果图为下:
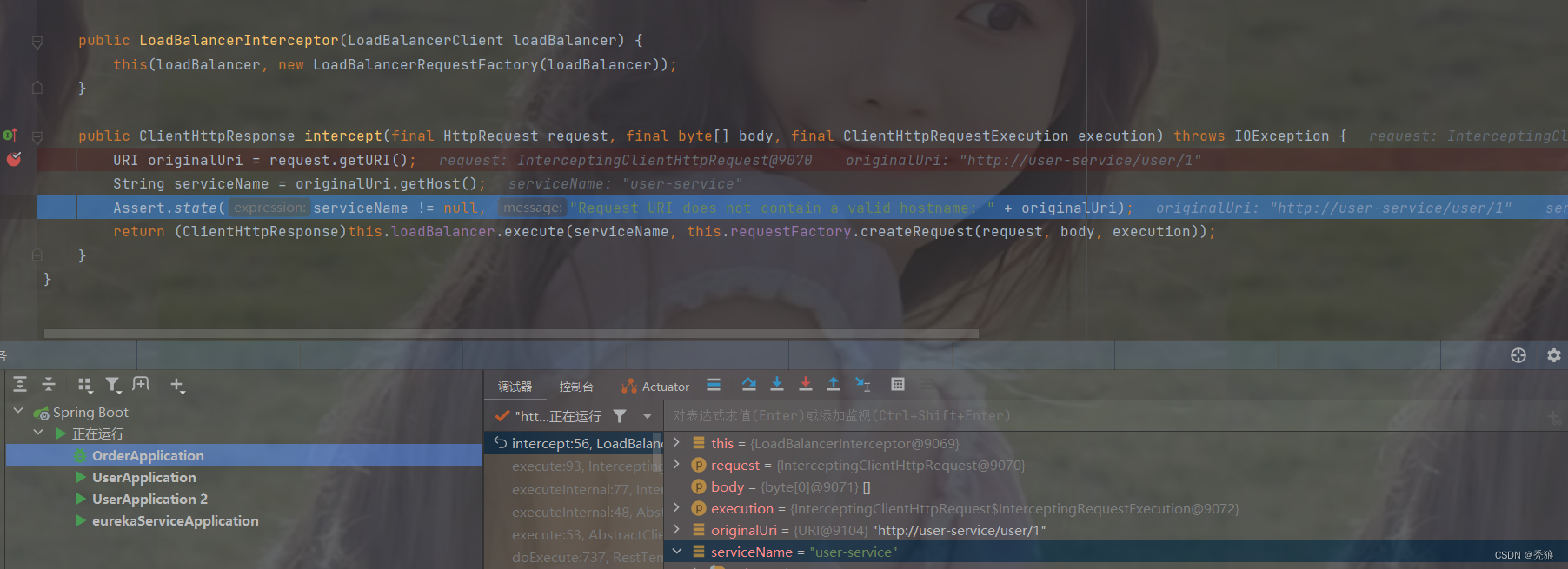 获得到的serverName=user-service。
获得到的serverName=user-service。
通过后序loadBalancer的execute方法,其会调用实现类下的execute方法,也就是RibbonLoadBalancerClient下的execute方法
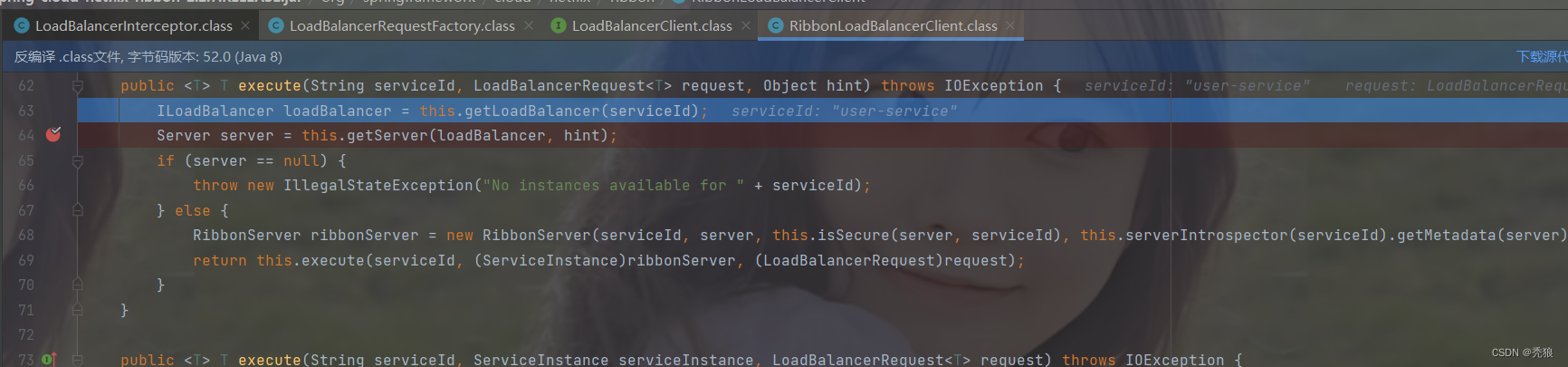
通过getServer方法去eureka中拉去对应的名字的服务,可以得到user-service的实例,这里就是两个user-service实例。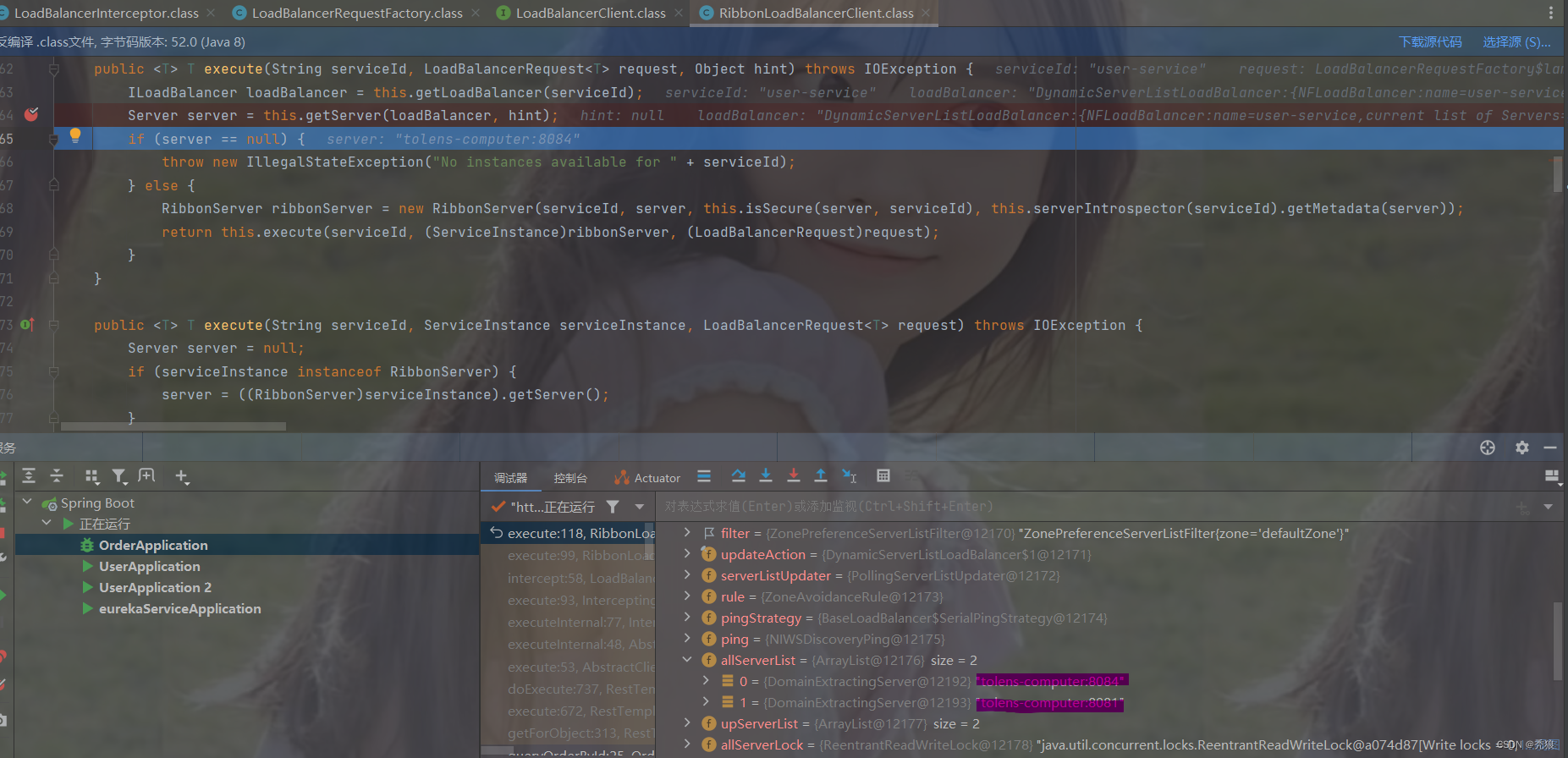
在getServer方法中最终会调用到rule.choose方法
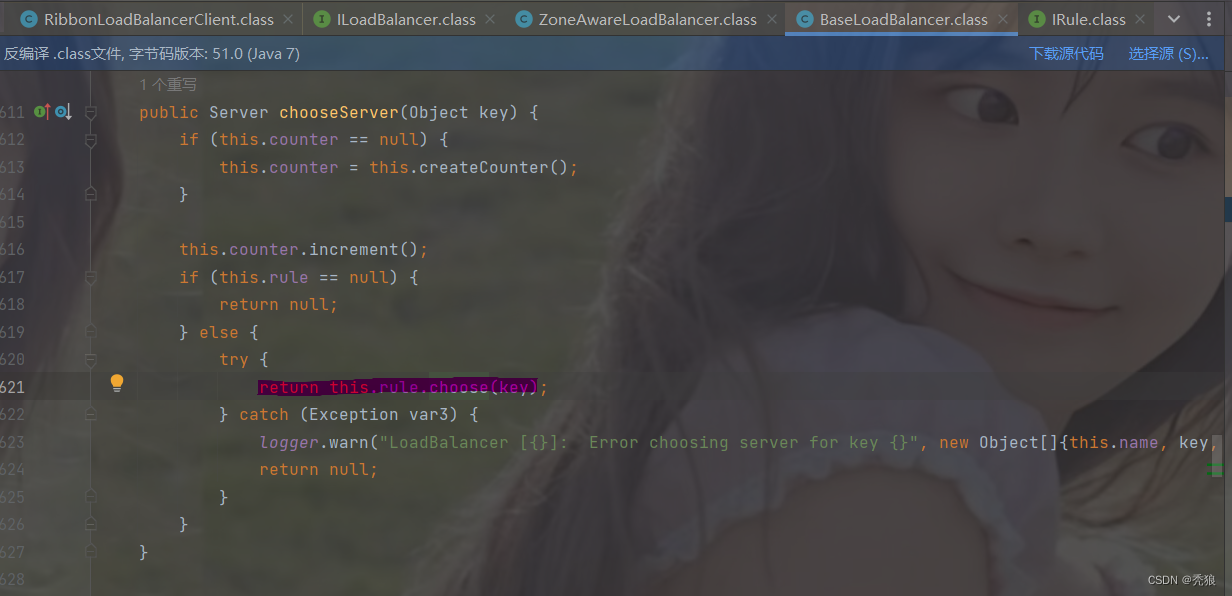
在该方法的作用就是选择对应的负载均衡的策略。
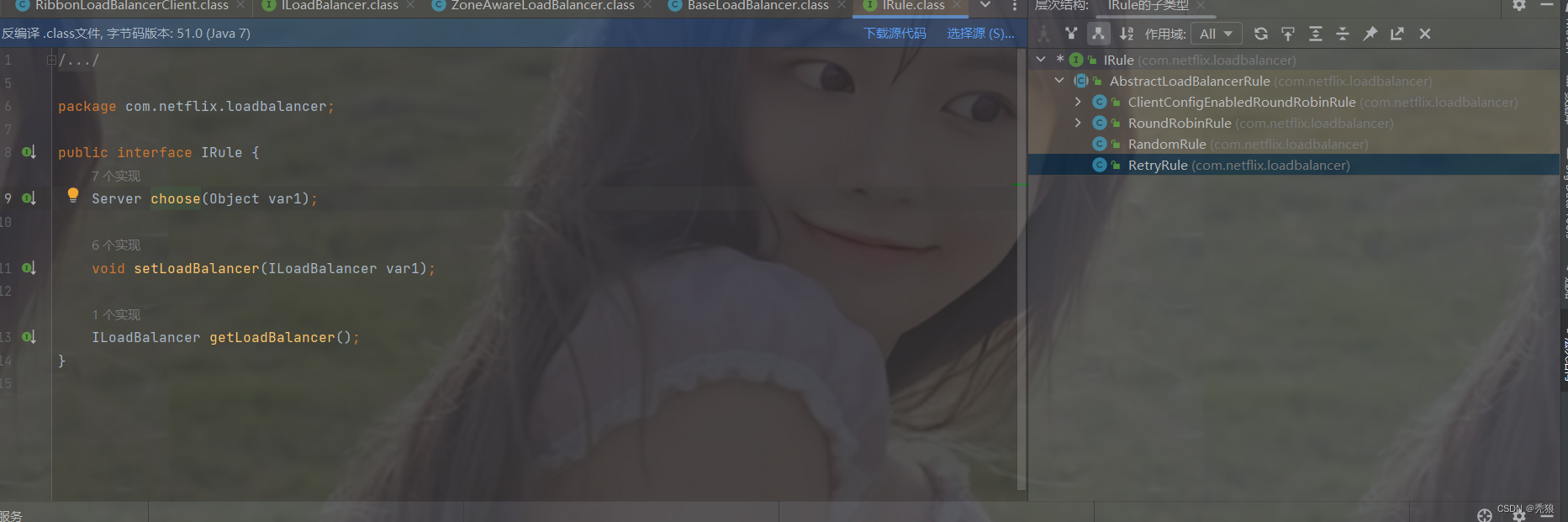
总共有四大种策略,默认使用轮番查询策略,也就是 RoundRobinRule。
最终只要通过添加@LoadBalanced就可以实现负载均衡。
负载均衡策略

设置策略的方法
1. 通过@Bean配置对应的策略,其作用域为全局。
@Bean//设置为随机策略public IRule getIRule() {return new RandomRule();}2.通过在application.yml中进行配置,此方法的优点就是作用域小,可以只作用在某个服务模块上。
#对应要设置策略的服务名
user-service:ribbon:NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule饥饿加载
在默认情况下,只有当消费端访问对用的服务端时,服务端才会进行加载,所以在第一次访问服务端的耗时会很长。
为了提高访问效率,我们可以在项目启动时提前加载好对应的服务端,这里就可以使用饥饿加载。
配置方法为下:
ribbon:eager-load:enabled: true#clients是个列表,所以可以设置多个clients: - user-service这样在消费端第一次访问对应的服务端时就会大大减少消耗的时间。
nacos
nacos安装
下载并解压对应的nacos文件后,通过cmd进入nacos的bin目录,执行以下指令进行启动。
startup.cmd -m standalone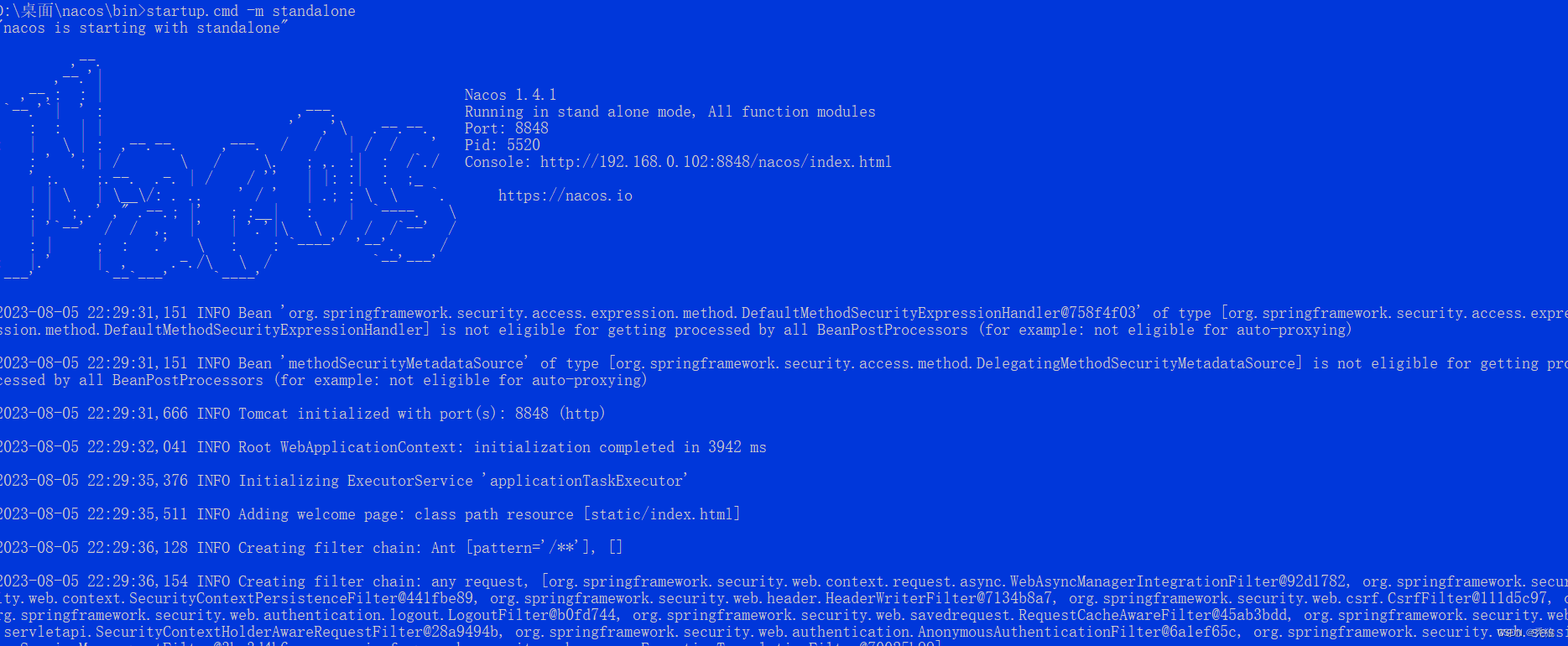
此时我们就可以访问localhost:8848/nacos,在该界面中的用户名和密码都是:nacos。
将对应的服务端和消费端的注册中心都改为nacos。
1.导入依赖
在父目录中导入的依赖为下:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>2.2.5.RELEASE</version><type>pom</type><scope>import</scope>
</dependency>在服务端和消费端导入的依赖为下:
<!-- nacos客户端依赖包 -->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>在服务端中的application.yml中配置为下:
spring:cloud:nacos:server-addr: localhost:8848启动微服务,效果图为下:
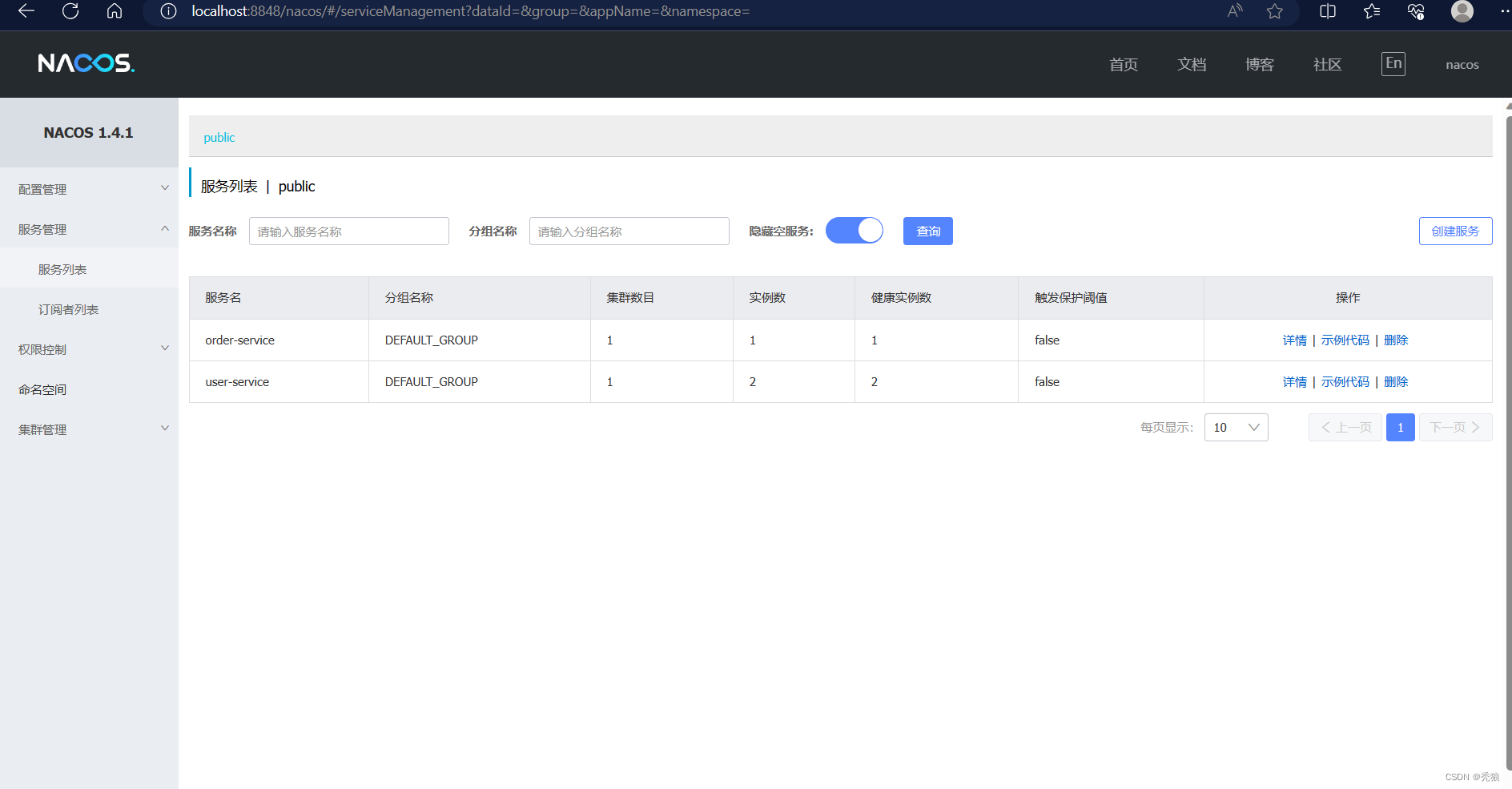
nacos服务分级存储模型
实现方法就是:将每个服务分布到不同的集群,这样就可以保证在某个集群失效时不会影响服务的使用。
例子:将所有的user-service设置到集群HZ,将order-service设置到集群BJ。
在application.yml的设置为下:
spring:cloud:nacos:discovery:#设置对应的集群名称cluster-name: BJ实现效果为下:
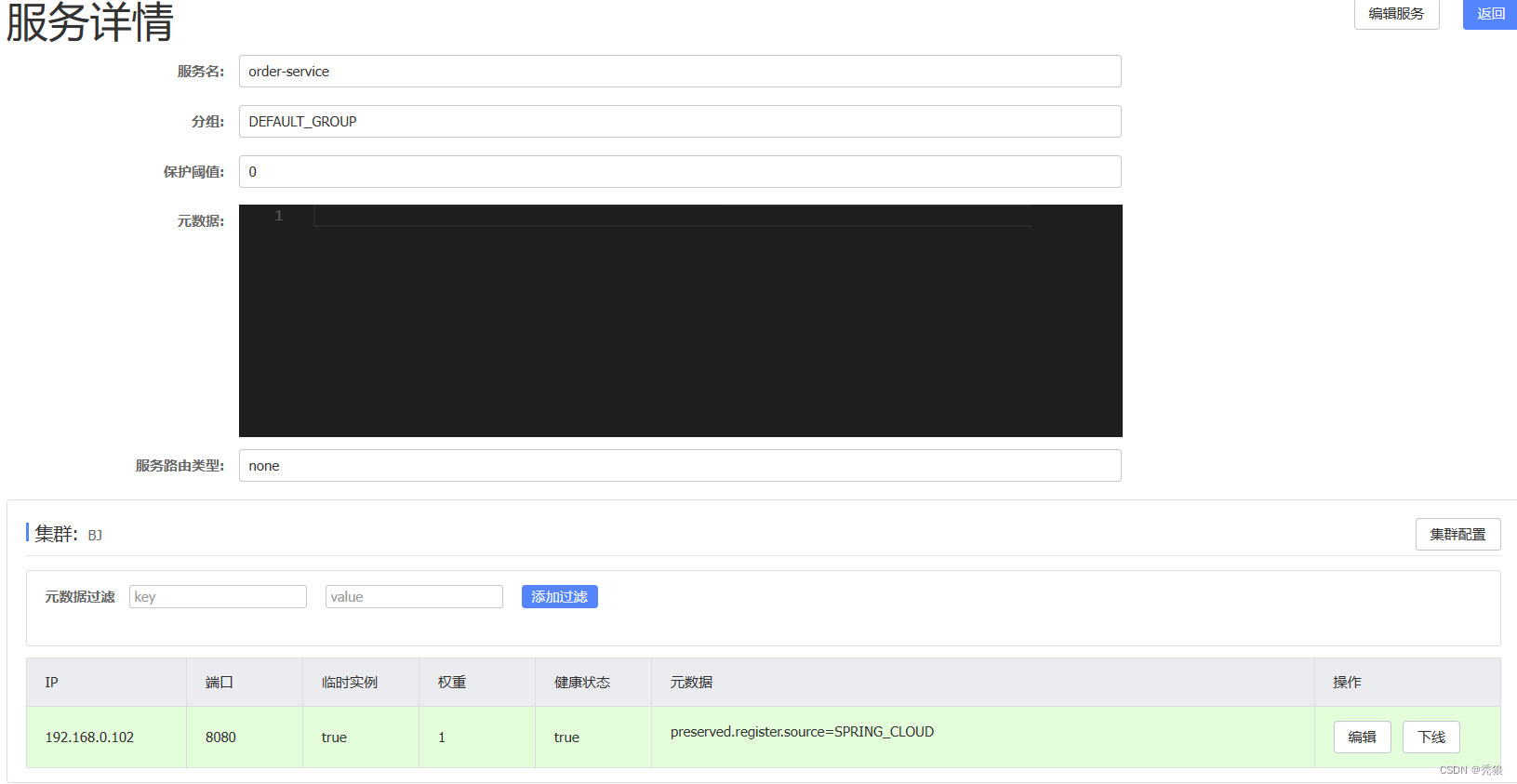
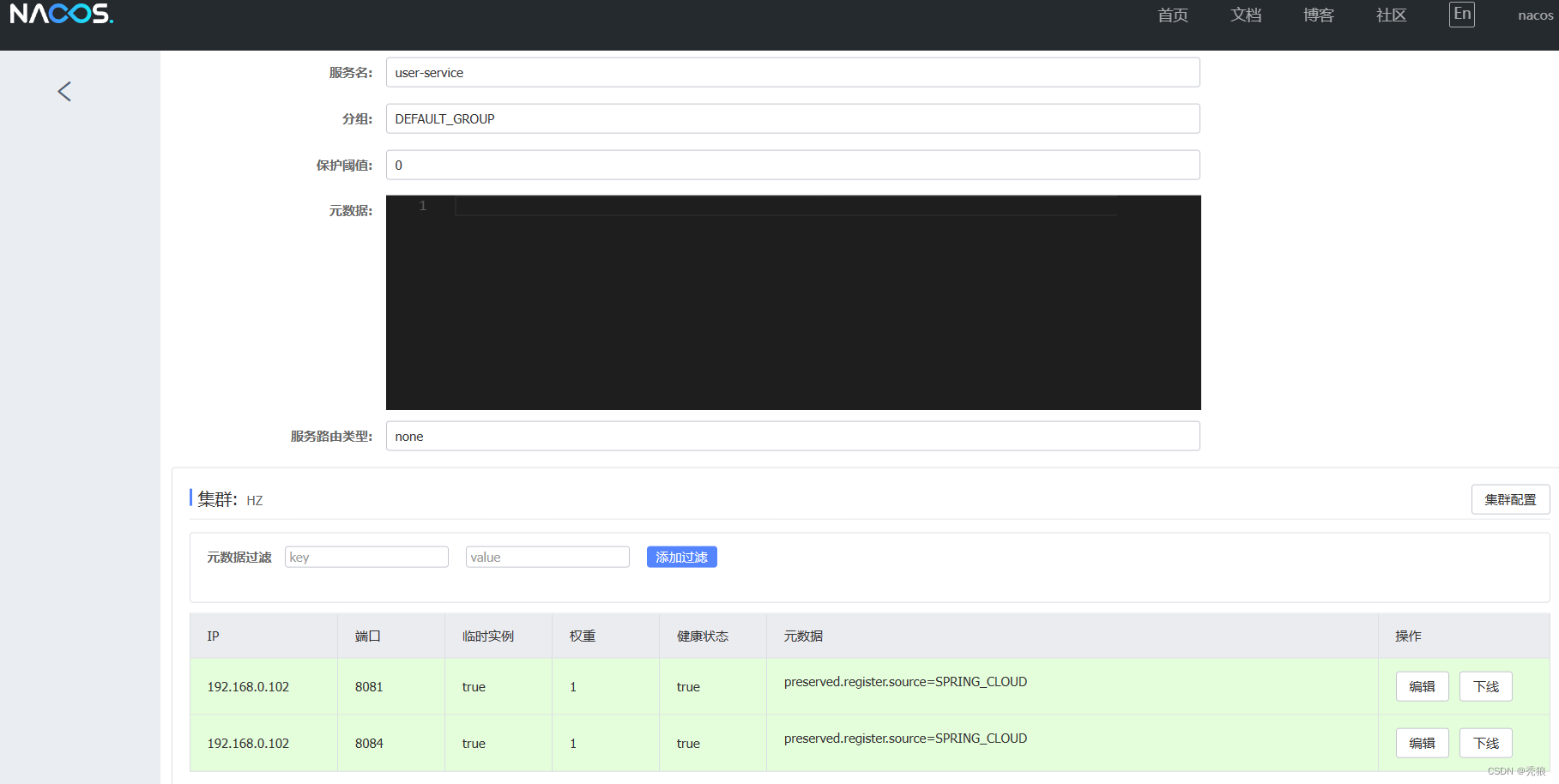
服务实例的权重设置
权重范围为:0~1,数字越大权重就越大。
在nacos中的是设置方式为下:
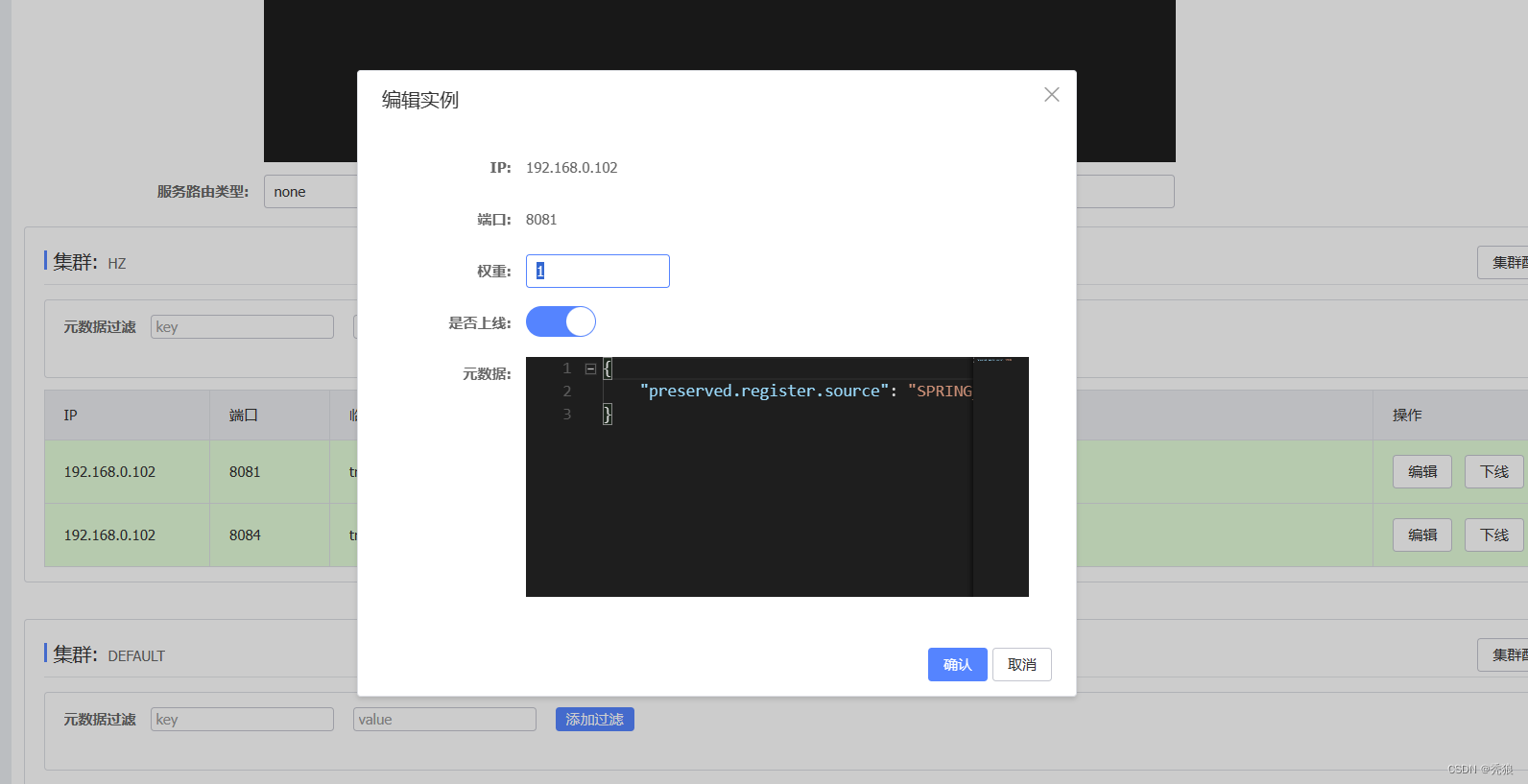
权重的使用的特殊情况。
当我们需要对某个模块进行升级时,我们不再需要重新发布项目,而是将当前服务的权重设置为0,这样用户访问是就不会调用当前的服务模块,用户对访问到项目功能的其他模块。
nacos设置负载均衡
在application.yml中配置以下信息:
#对应要设置策略的服务名
user-service:ribbon:#设置的哦负载均衡的策略NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule该策略为:存在多个拥有同样功能的集时,我们会先去访问,距离我们更近的集群,当该集群宕机时,才会访问其他相同功能的模块。
nacos环境隔离
 在nacos中新建一个环境的方式。
在nacos中新建一个环境的方式。
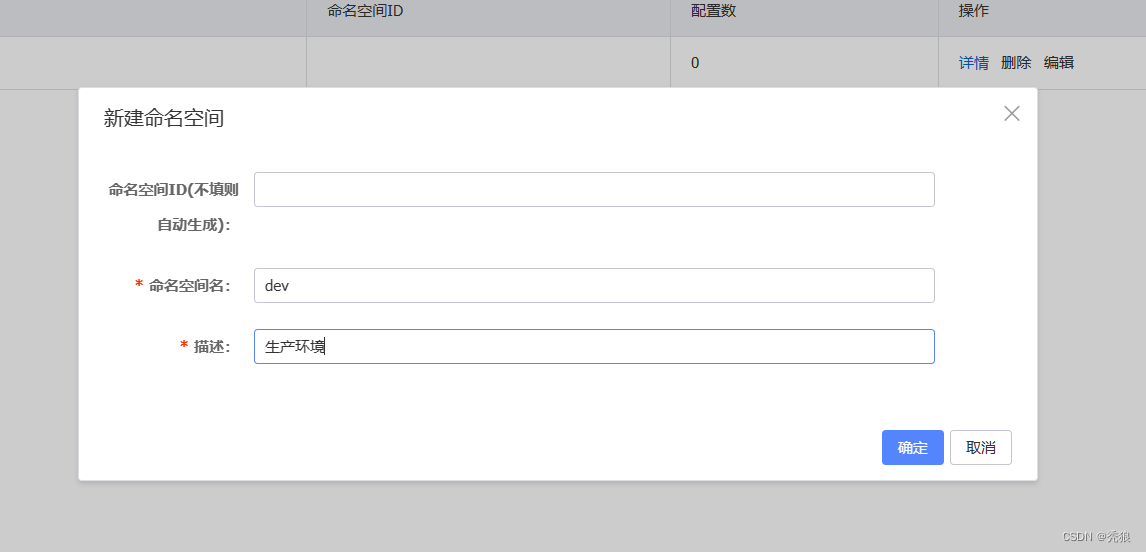
id不设置的话,就会通过UUID自动生成。
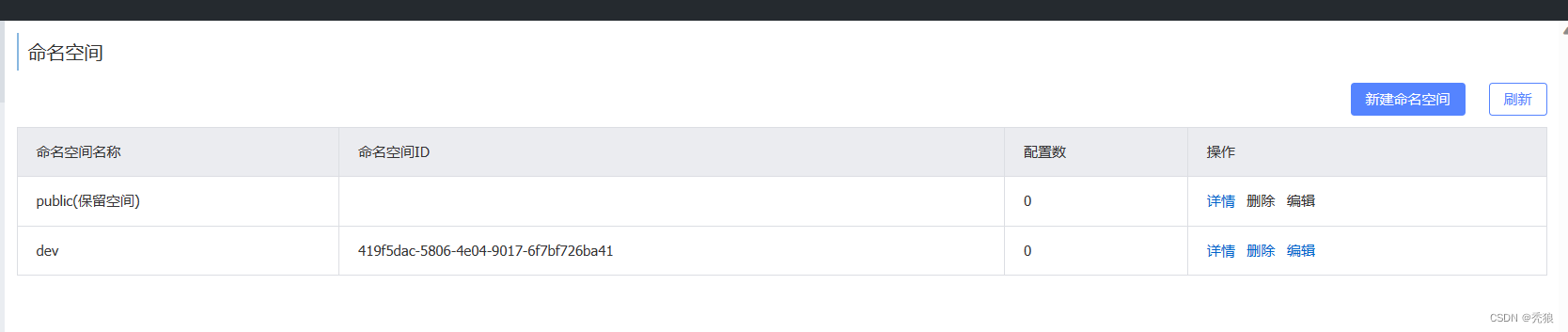
在代码application.tml中设置服务的环境空间。
spring:cloud:nacos:server-addr: localhost:8848discovery:cluster-name: BJnamespace: 419f5dac-5806-4e04-9017-6f7bf726ba41注意:不同环境间的服务模块是无法相互调用的,所以如果出现500异常可能就是跨环境的错误。
nacos和eureka的区别

nacos设置非临时实例的设置为下:
spring:cloud:nacos:discovery:#设置为非临时实例ephemeral:true