😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!💪💪💪

文章目录
- 📗前言
- 📙哈希表
- ✨哈希表定义及思路
- 🎃模拟散列表
- 🎄字符串前缀哈希
- 🎋哈希表工程实现
- 📘后记
📗前言
大家好,我是白晨,这一段时间🕊了,主要是🐏了,再加上我与生俱来的拖延症,我不是有意托更的😖,果咩纳塞。

本次为大家带来的是哈希表在算法中的应用与实践,主要讲解哈希表的思路以及在算法题中的应用,本篇文章由于是面向算法党的,对于工程实现部分讲解较为粗糙,以后会在STL中详细讲解工程实现。
当然,本篇文章会给出哈希表的两种快速实现,希望大家能将这两个模板理解记忆,方便面试中或者算法竞赛中快速实现。
📙哈希表
✨哈希表定义及思路
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,哈希表的增删查改操作都是O(1)。 这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
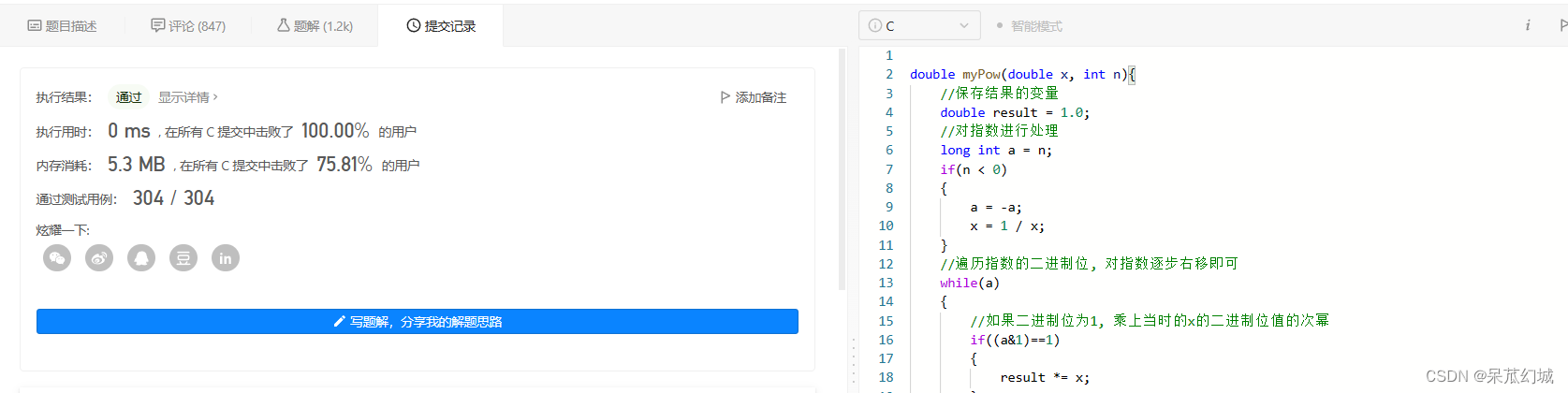
我们先用一个例子来演示哈希表的用途,假设我们有 10^5 个 范围为 0~10^9 的数,这时随机给出一个范围为 0~10^9 的数,求这个数是否在前面给出的10^5 个数中。
我们的第一反应肯定是前面10^5个数存储到数组中,然后逐个遍历查询,或者将前面的数排序,然后二分查找,这样的做法时间复杂度为O(N)或者O(NlogN),效率比较低,对于查询次数不多的数据或许可以顶一顶,遇到需要频繁查询的数据就很难受了。
所以,就产生了哈希表这样的数据结构,根据所给数的值,将其映射到对应的一个位置,以后,查询只需要通过**所给值(以后称为关键字)**进行映射,找到位置,就能判断是否存在这个值,时间复杂度为O(1)。从关键字求映射值的这个函数就称为 哈希函数。
具体例子为:

哈希表定义我们了解完以后,我们一起来看看哈希表的实现,哈希表的实现分为两种:
- 开散列(拉链法)

- 闭散列(开放寻址法)

这两种实现的区别在于发生哈希冲突(关键值根据哈希函数得到的映射位置相同)以后处理的方式不同,拉链法是将冲突的元素全部在一个位置上串起来,像一个拉链一样;而开放寻址法是通过再哈希,确定一个没有值使用新的位置,保证一个位置只存放一个值。
🎃模拟散列表

🍬原题链接:模拟散列表
🪅算法思想:
按照哈希表的思想进行实现,主要看下文代码实现。
🪆代码实现:
- 拉链法(开散列法)
// 拉链法
#include <iostream>
#include <cstring>using namespace std;const int N = 100003; // 超过10w的最小质数int h[N]; // 哈希表,对应位置存储单链表下标
int e[N], ne[N], idx; // 单链表,模拟每个哈希结点下挂的拉链
// 这里要注意上面的模拟单链表不是一般意义上的单链表,而是用数组模拟了多个单链表,用ne[k] = -1表示 NULL
// ne[k] = -1时,表示k结点没有后驱结点了,也就是一个单链表结束void insert(int x)
{int k = (x % N + N) % N; // 保证模出来的数一定为正数// 单链表头插e[idx] = x;ne[idx] = h[k];h[k] = idx++;
}bool find(int x)
{int k = (x % N + N) % N;for (int i = h[k]; i != -1; i = ne[i])if (e[i] == x)return true;return false;
}int main()
{int m;scanf("%d", &m);memset(h, 0xff, sizeof h);while (m--){char op[2];int x;scanf("%s%d", op, &x);if (op[0] == 'I') insert(x);else{if (find(x)) puts("Yes");else puts("No");}}return 0;
}
- 开放寻址法(闭散列法)
// 开放寻址法
#include <iostream>
#include <cstring>using namespace std;const int N = 200003, null = 0x3f3f3f3f; // null表示这个位置为空int h[N]; // 开散列法时间复杂度主要取决于冲突次数,所以将数组大小开成要求大小的2~3倍// 查找成功返回下标,失败返回该数应该被插入的下标
int find(int x)
{int k = (x % N + N) % N;// 不考虑数组被占满的情况while (h[k] != null && h[k] != x){k++;if (k == N) k = 0;}return k;
}void insert(int x)
{int k = find(x);if (h[k] == null) h[k] = x;
}int main()
{memset(h, 0x3f, sizeof(h));int m;scanf("%d", &m);while (m--){char op[2];int x;scanf("%s%d", op, &x);if (op[0] == 'I') insert(x);else{int k = find(x);if (h[k] != null) puts("Yes");else puts("No");}}return 0;
}
🎄字符串前缀哈希

🍬原题链接:字符串哈希
🪅算法思想:
先要注意,这个前缀哈希与md5那种字符串哈希不是一个东西,字符串前缀哈希是针对一个字符串的哈希,将字符串的字母视为 131 或者 13331 进制的数。如abcd,就是a∗1313+b∗1312+c∗1311+d∗1310a * 131^3 + b * 131^2 + c * 131^1 + d * 131^0a∗1313+b∗1312+c∗1311+d∗1310。
这样将一个字符串从左到右的哈希值都存到一个数组h[]中,h[0]=0,h[1]=a∗1310,h[2]=a∗1311+b∗1310,h[3]=a∗1312+b∗1311+c∗1310h[0] = 0,h[1] = a * 131^0,h[2] = a * 131^1 + b * 131^0,h[3] = a * 131^2 + b * 131^1 + c * 131^0h[0]=0,h[1]=a∗1310,h[2]=a∗1311+b∗1310,h[3]=a∗1312+b∗1311+c∗1310,依次类推就是字符串前缀哈希数组
- 那么这个哈希有什么用呢?
如果要求一个字符串和另一个字符串是否相等,一般做法就是逐个比较字符,时间复杂度为O(N),如果使用两个字符串的哈希值比较,那么时间复杂度就能降低为O(1),这个方法在很大程度上可以代替KMP算法。
但是这样有一个问题,字符串长度如果很大到达10w位左右,那么哈希值就是 13110w131^{10w}13110w 的大小,非常夸张,这样的值如何保存呢? 我们这里选择只保留 2^64 大小的值,相当于一个unsigned long long 的大小,但是这样保存的话就无法保证哈希值的唯一性,如果发生哈希冲突就无法比较两个字符串是否真的相等。
所以,这样的做法并不能保证完全正确,所以我们必须尽量避免冲突,做法就是 将字符串的字母视为 131 或者 13331 进制的数,而不是其他进制的数,有数学证明这个进制产生的冲突是最少的。
即使这种方法有瑕疵,但是并不能掩盖其优秀的能力,如 求一个字符串中 l1~r1 和 l2~r2 这两段子串是否相等 l1~r1 和 l2~r2 这两段子串的哈希值可以从字符串前缀哈希数组中求得:h[l∼r]=h[r]−h[l−1]∗131(r−l+1)h[l \sim r] = h[r] - h[l - 1] * 131^{(r - l + 1)}h[l∼r]=h[r]−h[l−1]∗131(r−l+1) 比较两段哈希值,相等即可认为字符串相等。
🪆代码实现:
#include <iostream>using namespace std;typedef unsigned long long ULL;const int N = 100010, P = 131;char s[N];
ULL h[N]; // 字符串前缀哈希
ULL p[N]; // P进制的N次方ULL getHash(int l, int r)
{return h[r] - h[l - 1] * p[r - l + 1];
}int main()
{int n, m;scanf("%d%d%s", &n, &m, s + 1);// 初始化哈希值,大于2^64的值会自动溢出,相当于直接模2^64p[0] = 1;for (int i = 1; i <= n; ++i){h[i] = h[i - 1] * P + s[i]; //递推p[i] = p[i - 1] * P;}while (m--){int l1, r1, l2, r2;scanf("%d%d%d%d", &l1, &r1, &l2, &r2);if (getHash(l1, r1) == getHash(l2, r2)) puts("Yes");else puts("No");}return 0;
}
🎋哈希表工程实现
工程实现多使用开散列(拉链法),这里我用图解一下开散列的框架思路:
- 开散列结点实现:

- 开散列实现:

- 哈希函数实现:
template<class K>
struct Hash
{size_t operator()(const K& key){return key;}
};// BKDR法
template<>
struct Hash<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto& ch : key){hash *= 31;hash += ch;}return hash;}
};
- 开散列代码实现:
namespace LinkHash
{// 哈希结点template<class K, class V>struct HashData{pair<K, V> _data;HashData<K, V>* _next = nullptr;HashData(const pair<K, V>& data):_data(data),_next(nullptr){}};template<class K, class V, class HashFunc = Hash<K>>class HashTable{typedef HashData<K, V> Node;public:Node* Find(const K& key){if (_table.size() == 0)return nullptr;HashFunc hf;size_t index = hf(key) % _table.size();Node* cur = _table[index];while (cur){if (cur->_data.first == key)return cur;cur = cur->_next;}return nullptr;}bool Insert(const pair<K, V>& data){if (Find(data.first))return false;HashFunc hf;// 负载因子超过1就增容if (_table.size() == 0 || _n / _table.size() >= 1){size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;HashTable<K, V, HashFunc> newHT;newHT._table.resize(newSize);for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t index = hf(cur->_data.first) % newSize;// 头插cur->_next = newHT._table[index];newHT._table[index] = cur;cur = next;}}_table.swap(newHT._table);}size_t index = hf(data.first) % _table.size();if (_table[index] == nullptr){_table[index] = new Node(data);}else{Node* cur = _table[index];Node* tar = new Node(data);tar->_next = cur;_table[index] = tar;}++_n;return true;}bool Erase(const K& key){if (_table.size() == 0)return false;HashFunc hf;size_t index = hf(key) % _table.size();Node* prev = nullptr;Node* cur = _table[index];while (cur){if (cur->_data.first == key){if (prev == nullptr){_table[index] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}else{prev = cur;cur = cur->_next;}}return false;}private:vector<Node*> _table;size_t _n;};
}
- 闭散列实现:
闭散列使用情况较少,所以不进行讲解,代码提供给大家作为参考。
namespace CloseHash
{enum Status{EMPTY,EXIST,DELETE};template<class K, class V>struct HashData{pair<K, V> _data;Status _status = EMPTY;};template<class K, class V, class HashFunc = Hash<K>>class HashTable{typedef HashData<K, V> Node;public:Node* Find(const K& key){if (_table.size() == 0)return nullptr;HashFunc hf;size_t start = hf(key) % _table.size();size_t i = 0;size_t index = start;while (_table[index]._status != EMPTY){if (_table[index]._status == EXIST && _table[index]._data.first == key){return &_table[index];}++i;if (i % 2 == 1){index += i / 2 + 1;}else{index -= i / 2;}index %= _table.size();}return nullptr;}bool Insert(const pair<K, V>& data){if (Find(data.first))return false;HashFunc hf;if (_table.size() == 0 || _n * 10 / _table.size() >= 7){// 扩容// 现代写法:通过开一个新表调用Insert插入结点,再交换内部数据。size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;HashTable<K, V, HashFunc> newHashTable;newHashTable._table.resize(newSize);for (auto& e : _table){if (e._status == EXIST){newHashTable.Insert(e._data);}}_table.swap(newHashTable._table);}size_t start = hf(data.first) % _table.size();size_t i = 0;size_t index = start;while (_table[index]._status == EXIST){// 线性探测/*++i;index += i;index %= _table.size();*/// 二次探测++i;if (i % 2 == 1){index += i / 2 + 1;}else{index -= i / 2;}index %= _table.size();}_table[index]._data = data;_table[index]._status = EXIST;++_n;return true;}bool Erase(const K& key){Node* ret = Find(key);if (ret == nullptr)return false;ret->_status = DELETE;_n--;return true;}private:vector<Node> _table;size_t _n = 0; // 有效数据个数};void TestHashTable(){int a[] = { 1, -1, 11, 51,5,-5,15,15};HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(25, 25));cout << ht.Find(5) << endl;ht.Erase(5);cout << ht.Find(5) << endl;}
}
📘后记
哈希的思想不止用在哈希表中,在许多算法中也使用了哈希的思想,希望大家能在本篇中初步了解哈希思想的应用,未来在学习STL等知识点时可以更加得心应手。
如果解析有不对之处还请指正,我会尽快修改,多谢大家的包容。
如果大家喜欢这个系列,还请大家多多支持啦😋!
如果这篇文章有帮到你,还请给我一个大拇指 👍和小星星 ⭐️支持一下白晨吧!喜欢白晨【算法】系列的话,不如关注👀白晨,以便看到最新更新哟!!!
我是不太能熬夜的白晨,我们下篇文章见。