摘要
在这项工作中,我们解决了引用分割的挑战性任务。引用分割中的查询表达式通常通过描述目标对象与其他对象的关系来表示目标对象。因此,为了在图像中的所有实例中找到目标实例,模型必须对整个图像有一个整体的理解。为了实现这一点,我们将引用分割重新定义为直接关注问题:在图像中找到查询语言表达最受关注的区域。我们引入了转换器和多头注意来构建一个具有编码器-解码器注意机制架构的网络,该架构可以用语言表达“查询”给定的图像。此外,我们提出了一个查询生成模块,该模块产生多组具有不同关注权重的查询,这些查询代表了从不同方面对语言表达的不同理解。同时,为了从这些基于视觉线索的多样化理解中找到最佳方法,我们进一步提出了一个查询平衡模块,自适应地选择这些查询的输出特征,以更好地生成掩码。我们的方法是轻量级的,并且在RefCOCO, RefCOCO+和G-Ref三个参考分割数据集上实现了一致的新性能。

我们的方法检测一种语言表达的多种强调或理解方式,并为每种方式生成查询向量。我们使用每个向量来“查询”图像,并对每个查询生成响应。然后网络有选择地聚合这些响应,其中提供更好理解的查询被突出显示。
背景
挑战和贡献
1)参考分割图像中对象之间的关联比较复杂,查询表达式往往通过描述与其他对象之间的关系来表示目标对象,这需要对图像和语言表达有一个整体的理解。
sol:
1. 我们探索通过构建具有全局操作的网络来增强对多模态特征的整体理解,其中所有元素(例如,像素-像素,单词-单词,像素-单词)之间的直接交互建模。
常用的小核卷积在交互方面低效-用transformer解决。大多数带transformer的分割网络它们大多只利用注意力机制作为基于类fcn管道的辅助模块,这限制了它们对全局上下文建模的能力。
我们使用视觉引导注意力从语言特征中生成一组查询向量,并使用这些向量对给定图像进行“查询”,并从响应中生成分割掩码,如图1所示。这种基于注意力的框架使我们能够在计算的每个阶段实现多模态特征之间的全局操作,使网络更好地建模视觉和语言信息的全局上下文。
2)物体/图像的多样性以及语言的不受限制的表达,这带来了高度的随机性。
sol:
1. 我们提出了一个查询生成模块(Query Generation Module, QGM),该模块在视觉特征的帮助下,基于语言生成多个不同的查询向量。
在大多数先前的视觉变换工作中,对变换解码器的查询通常是一组固定的学习向量,每个学习向量用于预测一个对象。实验表明,每个查询向量都有自己的运行模式,并且专门针对某一类对象[1]。在这些具有固定查询的工作中,必须隐含一个假设,即输入图像中的对象按照一定的统计规则分布,这与参考分割的随机性不匹配。
2. 为了确保生成的查询向量是有效的,并找到更适合图像和语言的理解方式,我们进一步提出了查询平衡模块Query Balance Module自适应地选择这些查询的输出特征,以便更好地生成掩码。该模块是轻量级的,其参数大小大致相当于七个卷积层。
相关工作
Referring Segmentation 参考分割
参考分割的目的是在给定描述其属性的自然语言表达式的图像中找到目标对象。
这里只放本篇论文提及的20年后的
Bi-directional relationship inferring network for referring image segmentation,2020
Multi-task collaborative network for joint referring expression comprehension and segmentation, 2020
与之前建立在类fcn网络上的方法不同,我们用完全基于注意力的架构取代了预测和识别头,这有助于我们轻松地对图像中的长期依赖关系进行建模。
Attention and Transformer
Transformer模型是一种仅使用注意力机制的序列到序列深度网络架构
感觉介绍的都比较常识
方法
网络以图像![]() 和语言表达式
和语言表达式![]() 作为输入,其中H0和W0分别为输入图像的高度和宽度,T为语言表达式的长度。
作为输入,其中H0和W0分别为输入图像的高度和宽度,T为语言表达式的长度。
首先,将输入的图像和语言表达映射到特征空间中。
同时,将视觉特征发送到Transformer编码器,生成一组记忆特征。从QGM获得的查询向量query vectors用于“查询”内存特征,然后由查询平衡模块Query Balance Module选择解码器的结果响应。
最后,网络为目标对象输出一个maskMp。
模型
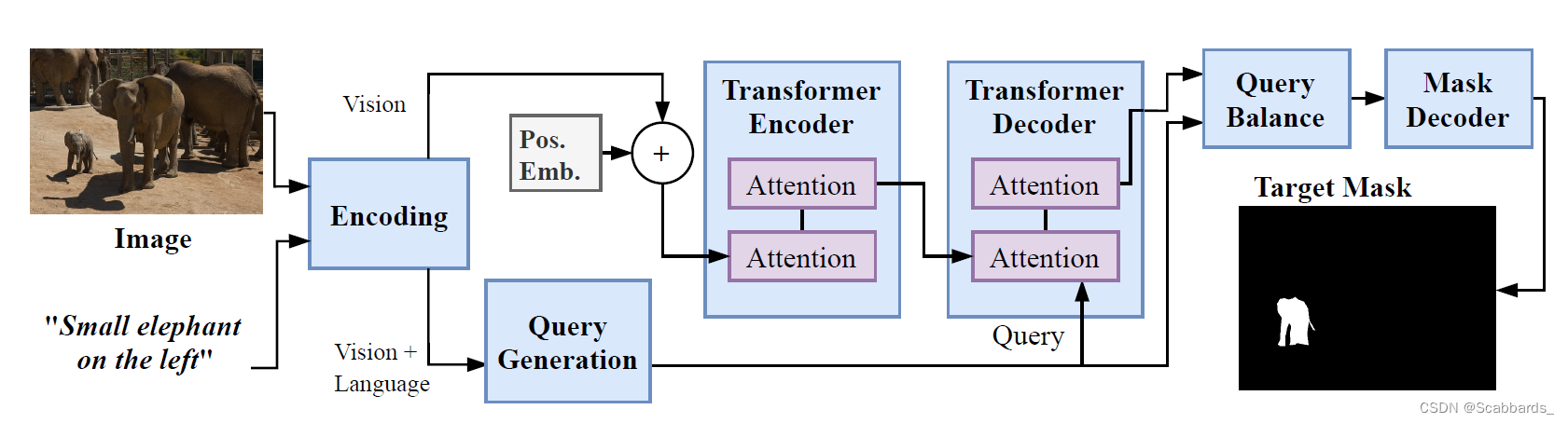
Encoding
由于Transformer架构只接受顺序输入,原始图像和语言输入必须在发送到变压器之前转换成特征空间。
视觉特征
我们使用CNN主干进行图像编码。我们将主干中最后三层的特征作为编码器的输入。通过调整三组特征映射的大小并将它们相加,我们得到原始视觉特征![]()
式中,H;W为特征的空间大小,C为特征通道数。
语言特征
我们首先使用查找表将每个词转换为词嵌入[31],然后使用RNN模块将词嵌入转换为与视觉特征相同的通道号,从而得到一组语言特征![]()
然后将Fvr和Ft作为视觉和语言特征发送到查询生成模块。同时,我们将Fvr的空间域平面化成一个序列,形成视觉特征![]() ,都会被送到transformer模块。
,都会被送到transformer模块。
Transformer Module.
我们使用一个完整但浅的变压器对输入特征应用注意力操作。
该网络有一个变压器编码器和一个解码器,每一个都有两层。每层有一个(编码器)或两个(解码器)多头注意模块和一个前馈(feed-forward)网络。
变压器编码器以视觉特征Fv作为输入,导出视觉信息 ![]() 的记忆特征。在发送到编码器之前,我们在Fv上添加了一个固定正弦空间位置嵌入(fixed sine spatial positional embedding)。
的记忆特征。在发送到编码器之前,我们在Fv上添加了一个固定正弦空间位置嵌入(fixed sine spatial positional embedding)。
在我们的实验中,我们将Fv与语言特征的最终状态相乘,以丰富视觉特征中的信息。然后Fm作为键和值与查询生成的Nq查询向量一起发送到变压器解码器模块。Decoder查询语言查询向量和视觉记忆特征,输出Nq响应进行掩码解码。
Mask Decoder Module
掩码解码器由三个堆叠的3*3卷积层组成,用于解码,然后是一个1 * 1卷积层,用于输出最终的分割掩码。上采样层可以选择性地在层之间插入,以控制输出大小。为了更清楚地展示变压器模块的有效性,在我们的实现中,掩码解码模块没有使用任何以前的CNN特征。我们利用输出掩码上的二值交叉熵损失来指导网络训练。
Query Generation Module 查询生成模块
许多属性隐藏在语言表达式中,例如像“大/小”,“左/右”。为了提取关键信息,解决参考分割中的高随机性问题,我们提出了查询生成模块,根据输入的图像和语言表达,借助图像信息在线自适应生成查询向量,如图所示。
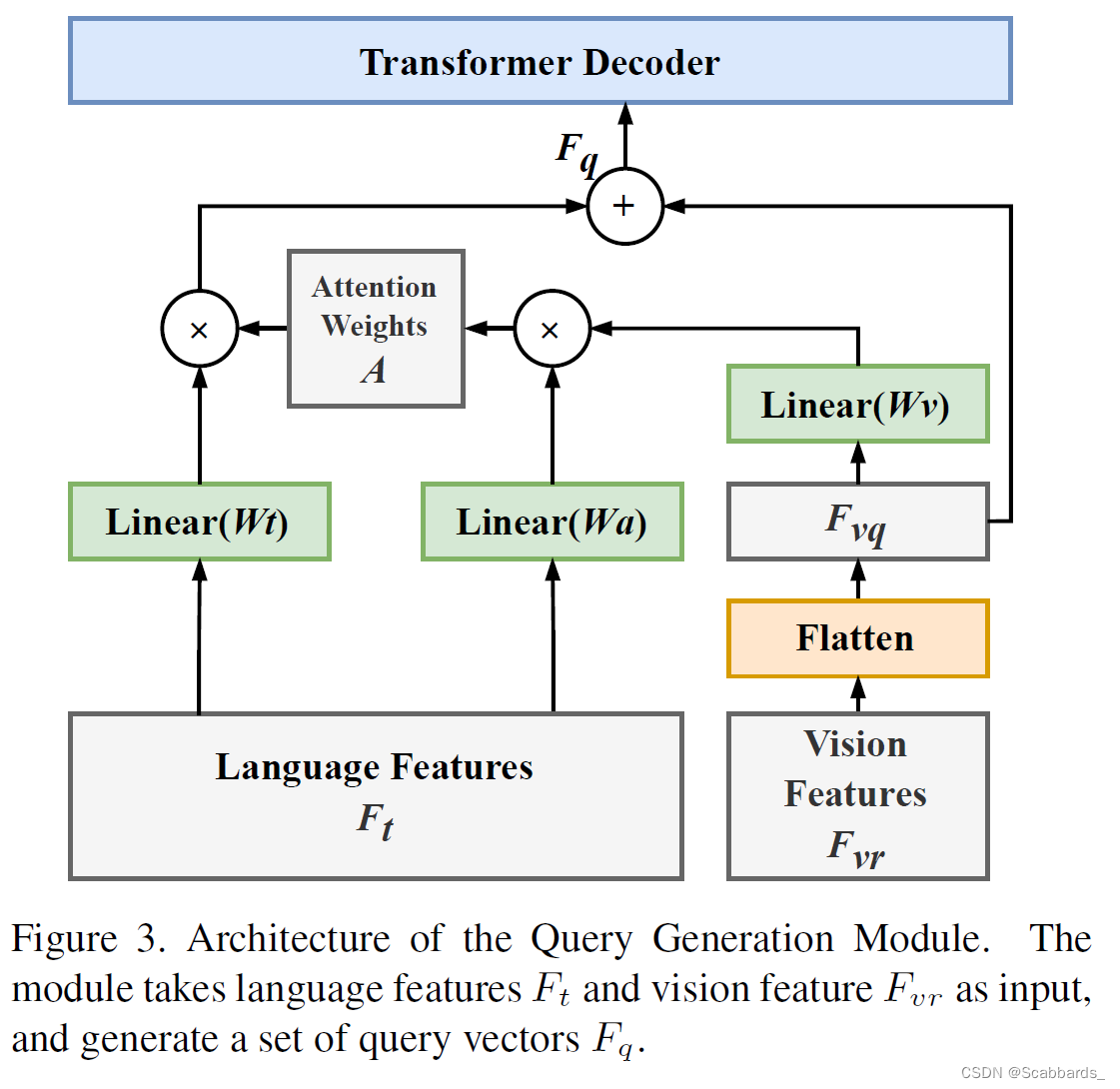
此外,为了让网络学习信息的不同方面并增强查询的鲁棒性,我们在只有一个目标实例的情况下生成多个查询。查询生成模块将语言特征fv2rnlc和原始视觉以fv2rhwc为输入。在Ft中,第i个向量是单词wi的特征向量,它是输入语言表达式中的第i个单词。
Ft中的Nl由零填充固定。该模块的目标是输出Nq个查询向量,每个查询向量是一个在视觉信息引导下具有不同关注权重的语言特征。
首先,准备视觉特征,如图所示:该模块将常规的2D视觉特征转换为一组序列特征。我们将视觉特征Fvr的特征通道维度大小通过三个卷积层减少到查询个数Nq,得到Nq特征映射。

它们中的每一个都将参与一个查询向量的生成。然后在空间域中对特征映射进行平坦化,形成大小为Nq (HW)的特征矩阵Fvq,即:

大多数作品都是通过语言自注意来获得权值的,它没有利用图像中的信息,只输出一组权值。但在实践中,同一句话可能会有不同的理解角度和重点,最合适、最有效的重点只有借助形象才能知道,如图所示

对于同样的输入句子“the large circle on the left”,单词“left”对于第一个图像来说信息量更大,而
“large”对于第二张图片更有用。在这种情况下,语言自我注意无法区分“大”和“左”的重要性,因此只能给这两个词较高的注意权重,使注意过程效率降低。
因此,在查询生成模块中,我们结合图像从多个方面理解语言表达,从语言中形成Nq查询。不同的查询强调不同的单词,然后通过查询平衡模块找到更合适的关注权重并增强。
为此,我们结合视觉特征Fvq得出语言特征Ft的注意权值。首先,我们对Fvq和Ft进行线性投影。然后,对于第n次查询,我们取第n个视觉特征向量fvqn2
R1 (HW);N = 1;2;:::;Nq和所有单词的语言特征。设第i个单词的特征表示为fti 2
R1C;I = 1;2;:::;第i个单词的第n个注意力权重是fvqn和fti投影的乘积:

得到标量 ani ,![]() 和
和![]()
![]() 是可学习的参数。Softmax函数作为规范化应用于每个查询的所有单词。
是可学习的参数。Softmax函数作为规范化应用于每个查询的所有单词。
对于第n次查询,从ani到![]() 形成所有单词的注意权值集
形成所有单词的注意权值集
它由一组不同单词的注意权值组成,不同的查询可以关注语言表达的不同部分。因此,Nq查询向量关注语言表达的不同侧重点或不同理解方式。
接下来,将得到的注意权值应用到语言特征上:
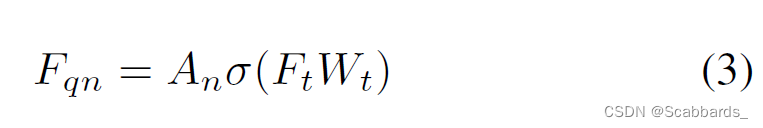
其中 ![]() 为可学习参数。每一个Fqn是一种由视觉信息引导的辅助语言特征向量,作为对变换解码器的查询向量。在数学上,每个查询都是语言表达式中不同单词的特征的投影加权和,因此它保留了作为语言特征的属性,可以用于查询图像。
为可学习参数。每一个Fqn是一种由视觉信息引导的辅助语言特征向量,作为对变换解码器的查询向量。在数学上,每个查询都是语言表达式中不同单词的特征的投影加权和,因此它保留了作为语言特征的属性,可以用于查询图像。
Query Balance Module
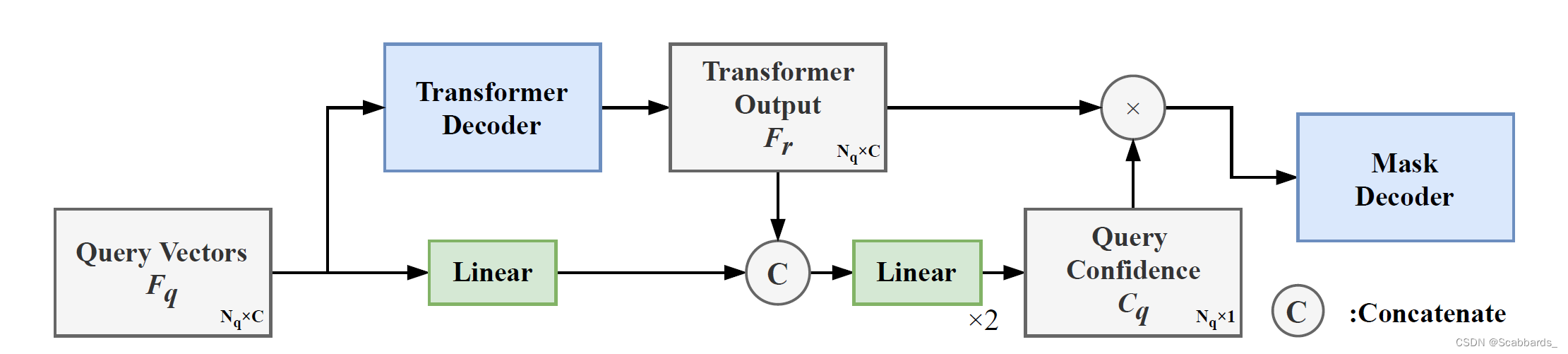
我们从查询生成模块得到了Nq个不同的查询向量,每个查询表示对输入语言表达式的特定理解。如前所述,输入图像和语言表达都具有高度随机性。因此,需要自适应地选择更好的理解方式,让网络专注于更合理、更合适的理解方式。另一方面,由于在Transformer Decoder 中保持了每个查询向量的独立性,但我们只需要一个掩码输出,因此需要平衡不同q的影响
查询平衡模块接受来自查询生成模块的查询向量Fq及其来自Transformer DecoderFr的响应,其大小与Fq相同。设Frn表示Fqn对应的响应。在查询平衡模块中,首先将查询及其相应的响应连接在一起。
然后,由两个连续的线性层生成一组大小为nq*1的查询置信水平Cq。每一个标量
Cqn显示查询Fqn在多大程度上符合其预测的上下文,并控制其响应Frn对掩码解码的影响。第二个线性层使用sigmoid作为激活函数来控制输出范围。每个响应Frn乘以相应的查询置信度Cqn,并发送给掩码解码。
实验
基本配置
我们严格遵循先前的工作[19,29]进行实验设置,包括准备Darknet-56骨干网作为CNN编码器。输入图像的大小调整为416 X 416。每个Transformer块有8个heads,所有heads中的隐藏层大小设置为256。
对于RefCOCO和RefCOCO+,输入语言表达式的最大长度设置为15,对于G-Ref设置为20。
我们使用Adam优化器训练网络50个epoch,学习率 = 0.001。使用shallow transformer架构,我们能够以32GB VRAM的每个GPU的32个批量大小来训练模型。
评估标准
掩码IoU和Precision@X。IoU度量显示了输出掩码的质量,它反映了方法的总体性能,包括目标和掩码生成能力。Precision@X报告了IoU阈值X下的成功瞄准率,重点是该方法的瞄准能力。
数据集
RefCOCO & RefCOCO+
是两个最大和最常用的参考分割数据集。RefCOCO数据集包含19,994张图像,其中包含50,000个对象的142,209个引用表达式,而UNC+数据集包含19,992张图像,其中包含49,856个对象的141,564个表达式。
G-Ref
它包含26,711张图片和104,560个表达式,涉及54,822个对象。
实验结果

我们认为效果好原因是,一方面,长句和复杂句通常包含更多的信息和更多的重点,而我们的查询生成和平衡模块可以检测多个重点,并找到信息更丰富的重点。另一方面,较困难的情况也可能包含需要全局视图的复杂场景,多头注意力作为global operator更适合此问题。

消融实验
在一个更困难的数据集上做消融研究,RefCOCO+的testB。
Parameter Size

我们的基于注意力的模块的参数大小仅大致相当于7个卷积层,而具有更优越的性能。Transformer模块性能优于7卷积模块,IoU提升超过5%,Prec@0.5提升超过7%。这证明了该Transformer模块的有效性。
Query Generation

学习得到的固定查询向量不能像查询生成模块在线生成的查询那样有效地表示目标对象。
Query Number


结果表明,虽然只输出一个掩码,但变压器网络仍然需要多个查询。
查询生成模块生成的多个查询表示信息的不同方面。