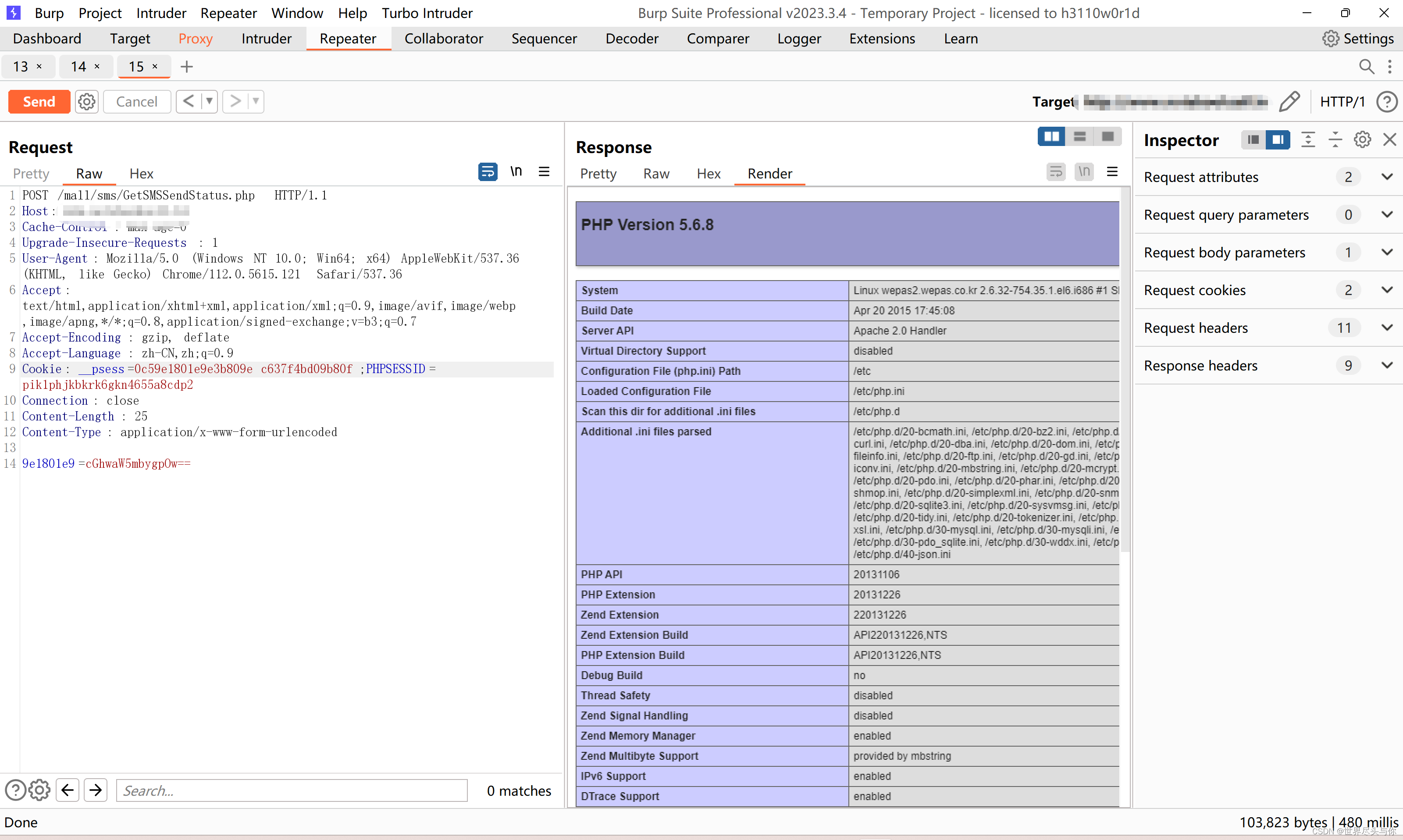
字符串匹配算法
- KMP算法
- Booyer-Moore算法
KMP算法
KMP算法在匹配失败时总是将j设为某个值以使i不回退。在查找过程的开始,从文本的开头进行查找,起始状态为0,它停留在0状态并扫描文本,直到找到一个和模式的首字母相同的字符。这是它移动到下一个状态并开始运行。在这个过程的最后,当它找到一个匹配时,它会不断地匹配模式中的字符和文本,自动机的状态会不断前进直到状态M。每次匹配成功会将DFA带入下一个状态,匹配失败会使DFA回到较早之前的状态。
public class KMP {private String pat;private int[][] dfa;public KMP(String pat) {this.pat = pat;int M = pat.length();int R = 256;dfa[pat.charAt(0)][0] = 1;for (int x = 0, j = 1; j < M; ++j) {for (int c = 0; c < R; ++c) {dfa[c][j] = dfa[c][x]; // 设置匹配失败情况下的值}dfa[pat.charAt(j)][j] = j + 1; // 设置匹配成功情况下的值x = dfa[pat.charAt(j)][x]; // 更新匹配到j时的重启状态}}public int search(String txt) {int i, j, N = txt.length();int M = pat.length();for (i = 0, j = 0; i < N && j < M; ++i) {j = dfa[txt.charAt(i)][j];}if (j == M) return i - M;else return N;}
}
Booyer-Moore算法
使用right[]记录字母表中的每个字符在模式中出现的最靠右的地方(如果字符在模式中不存在则表示为-1)。这个值揭示了如果该字符出现在文本中且在查找时造成一次匹配失败应该向右跳跃多远。计算完right[]数组之后,我们用一个索引i在文本中从左向右移动,用另一个索引j在模式中从右往左移动。内循环会检查正文和模式字符串在位置i是否一致。如果从M-1到0的所有j,txt.charAt(i + j)都和pat.charAt(j)相等,那么就找到了一个匹配。否则匹配失败,就会遇到以下三种情况:
- 如果造成匹配失败的字符不包含在模式字符串中,模式字符串向右移动 j + 1 个位置(即将i增加 j + 1)。小于这个偏移量只可能使该字符与模式中的某个字符重叠。事实上,这次移动也会将模式字符串前面一部分已知的字符和模式结尾的一部分已知字符对齐。通过预先计算一张类似于KMP算法的表格,还可以将i的值变得更大。
- 如果造成匹配失败的字符包含在模式字符串中,那就可以使用right[]数组来将模式字符串和文本对齐,使得该字符和它在模式字符串中出现的最右位置相匹配。和刚才一样,小于这个偏移量只可能使该字符和模式中的与它无法匹配的字符(比它出现的最右边位置更靠右的字符)重叠。我们可以用一张类似于KMP算法的表格将 i 变得更大。
- 如果这种方式无增大i,那就直接将i加1来保证模式字符串至少向右移动了一个位置。
public class BooyerMoore {private int[] right;private String pat;BooyerMoore (String pat) {this.pat = pat;int M = pat.length();int R = 256;right = new int[R];for (int c = 0; c < R; ++c) {right[c] = -1;}for (int j = 0; j < M; ++j) {right[pat.charAt(j)] = j;}}public int search(String txt) {int N = txt.length();int M = pat.length();int skip;for (int i = 0; i < N - M; i += skip) {skip = 0;for (int j = M - 1; j >= 0; --j) {skip = j - right[txt.charAt(i + j)];if (skip < 1) skip = 1;break;}if (skip == 0) return i;}return N;}}