文章目录
- 前言
- 一、安装部署
- 安装
- 数据源
- 转换
- 作业
- 监控
- 二、性能优化
- 问题 1 :DMETL 卡顿问题
- 问题 2 :DM -> HIVE 的迁移速度慢
- 问题 3 :ORACLE -> DM 的迁移速度慢
- 问题 4 :GP -> DM 的迁移速度慢
- 问题 5 :DM -> ORACLE 的迁移速度慢
- 问题 6 :DM -> GP 的迁移速度慢
- DMETL 迁移产品优化总结
- 参考内容
前言
达梦数据交换平台(简称 DMETL)是基于大量大数据项目经验和需求,结合最新大数据发展趋势自主研发的具有自主版权的数据处理与集成平台。
DMETL 创新性地将传统的 ETL 工具(抽取、转换、加载)与分布式大数据处理平台相结合,实现了一站式的数据同步、数据处理和数据交换共享支持,大幅降低了用户在大数据整合处理方面的技术门槛。它是构建数据中心、数据仓库、数据交换和数据同步等数据集成应用的理想平台。本篇主要讲使用该工具遇到的一些问题以及优化。
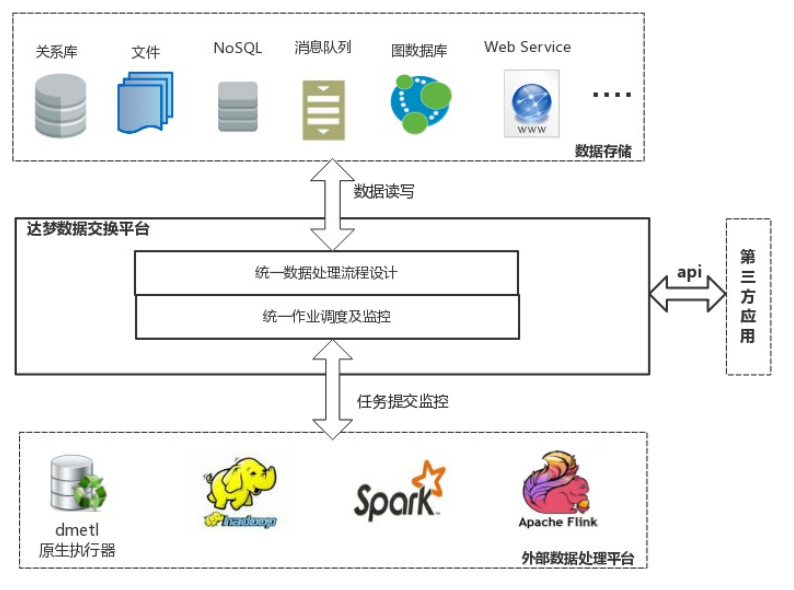
一、安装部署
安装
-
软件安装
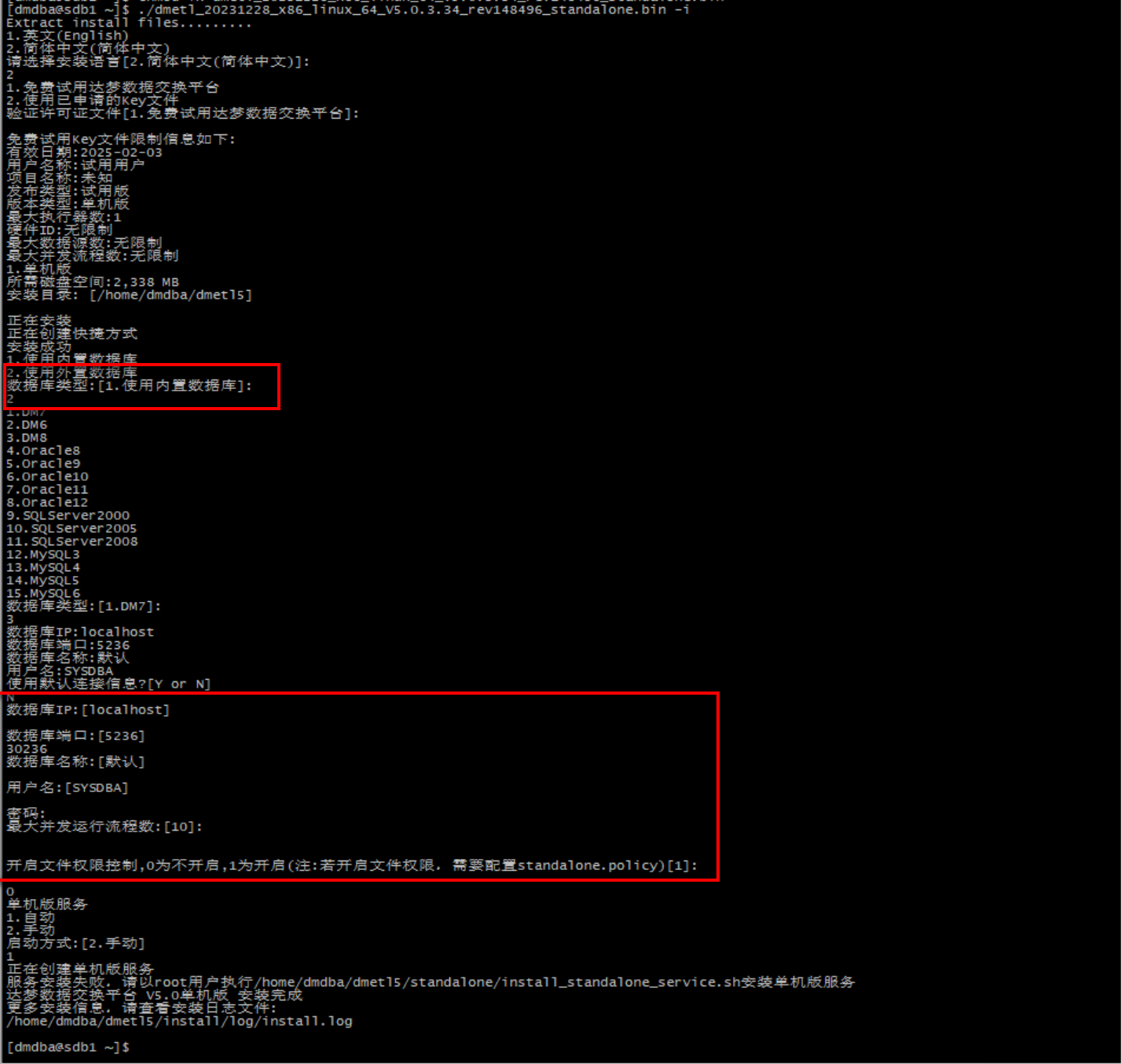
-
DMETL 元数据信息
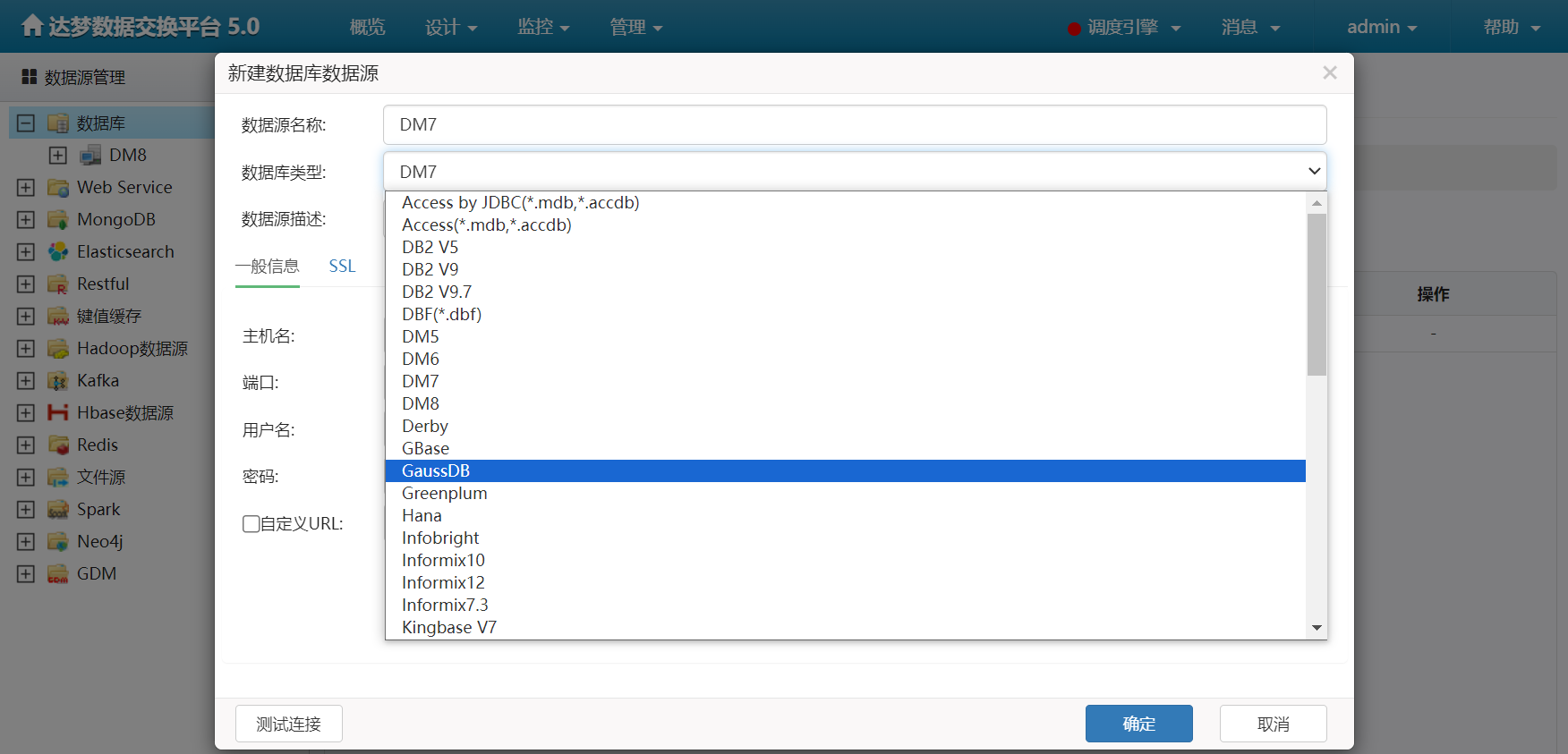
数据源
- 底层可支持多种数据源的配置
转换
- 转换里面可进行多种数据源之间的数据读取、数据质量管理、数据转换以及数据装载
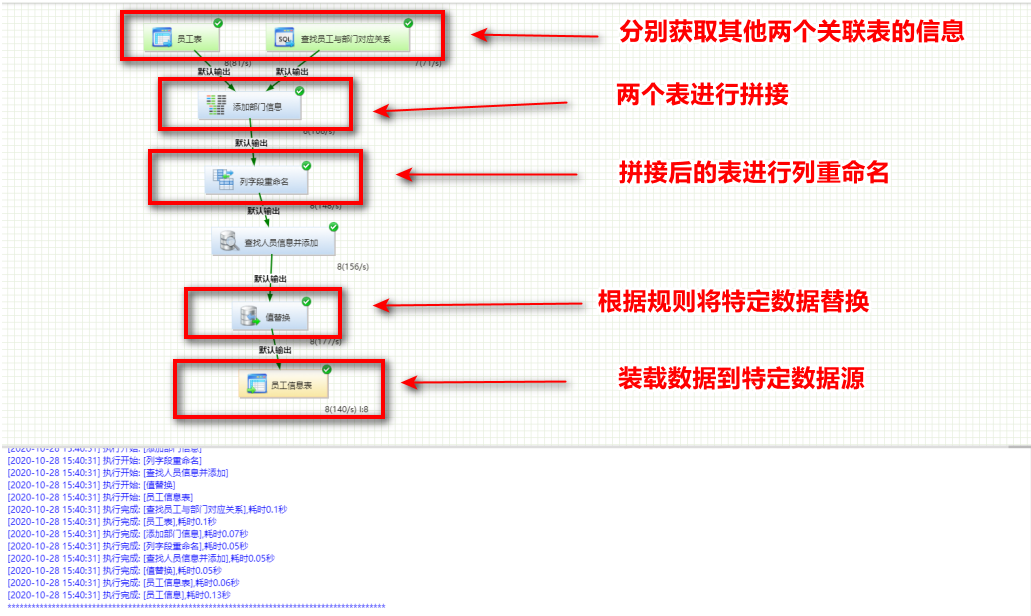
作业
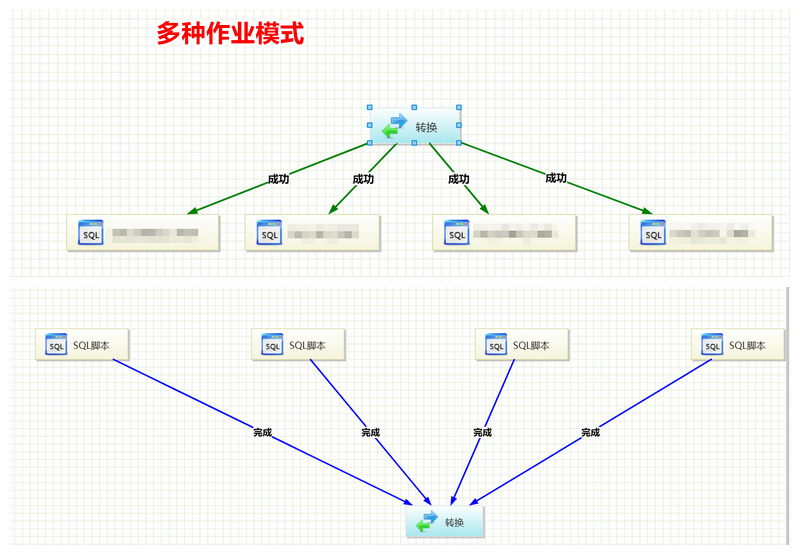
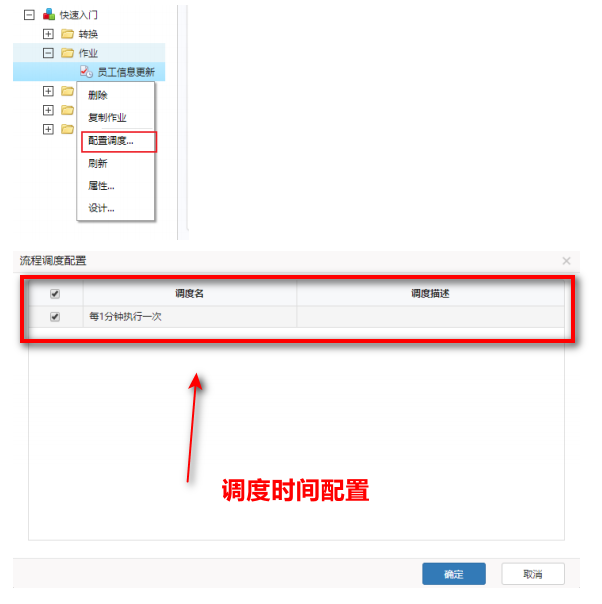
- 根据业务场景自定义作业,可控制转换以及其他任务的执行,配置调度可进行定时作业的发动
监控
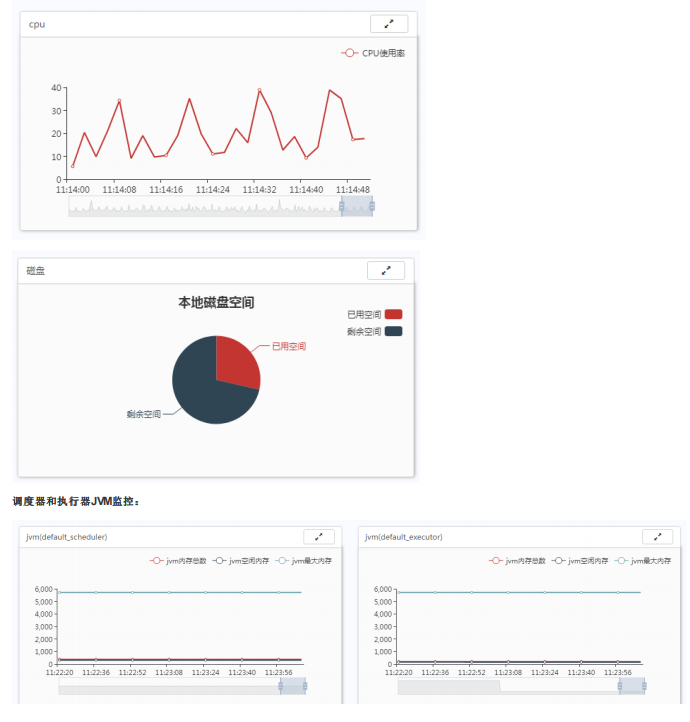
- 可对当前系统资源、流程运行情况、用户在线情况等进行监控
二、性能优化
问题 1 :DMETL 卡顿问题
- 解决方案 :安装部署中没有进行 /etc/hosts 的配置,会导致使用中 DNS 的遍历从而造成卡顿,配置相应的 /etc/hosts 的映射即可;
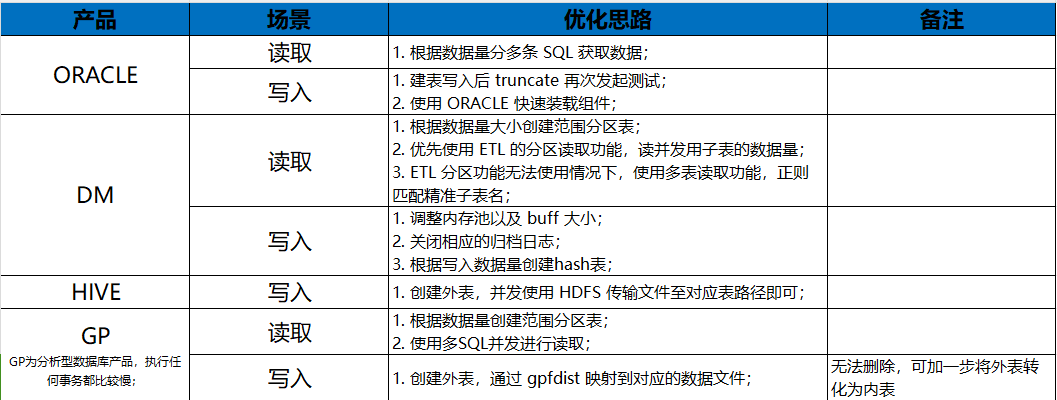
问题 2 :DM -> HIVE 的迁移速度慢
四表并发最初仅有 3W/s (读取写入均慢),优化至 150W/s
- 解决方案 :
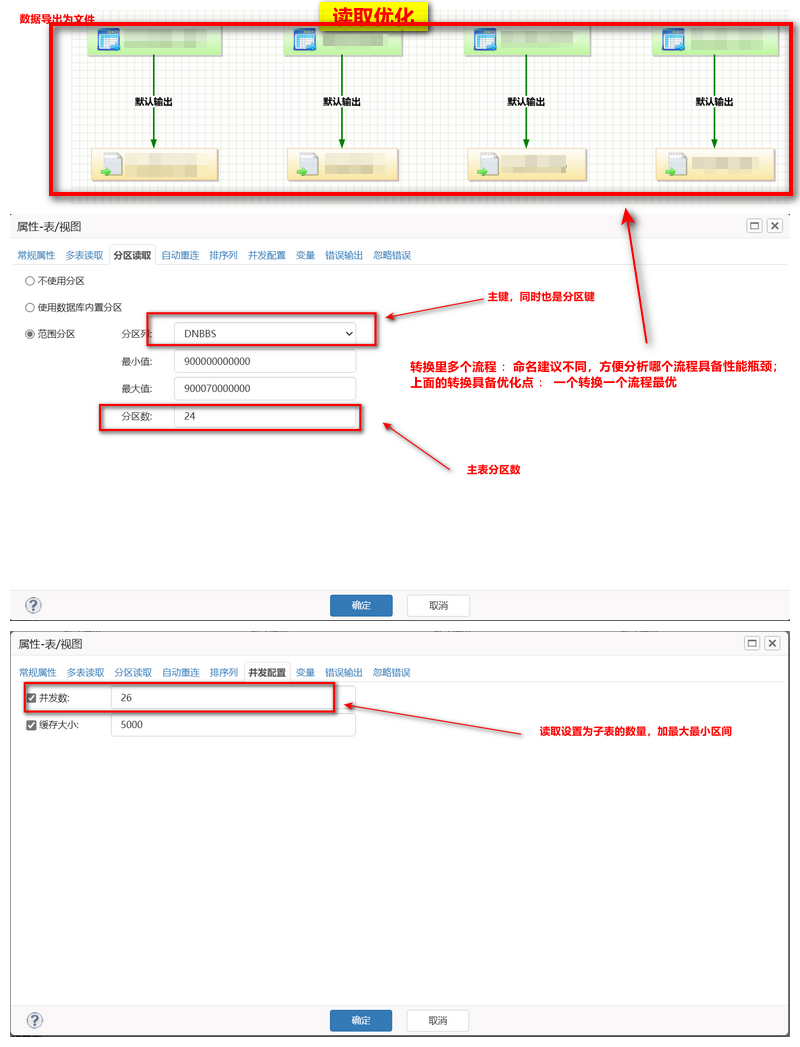
- 读取优化 :DM 表根据测试数据特点做成范围分区表,根据数据量分为 125W 一个分区,共 48 个分区(测试读取最优);
- 读取优化 :DMETL DM 源端根据分区键进行读取,单表 48 个并发进行读取(对应子表数据量);
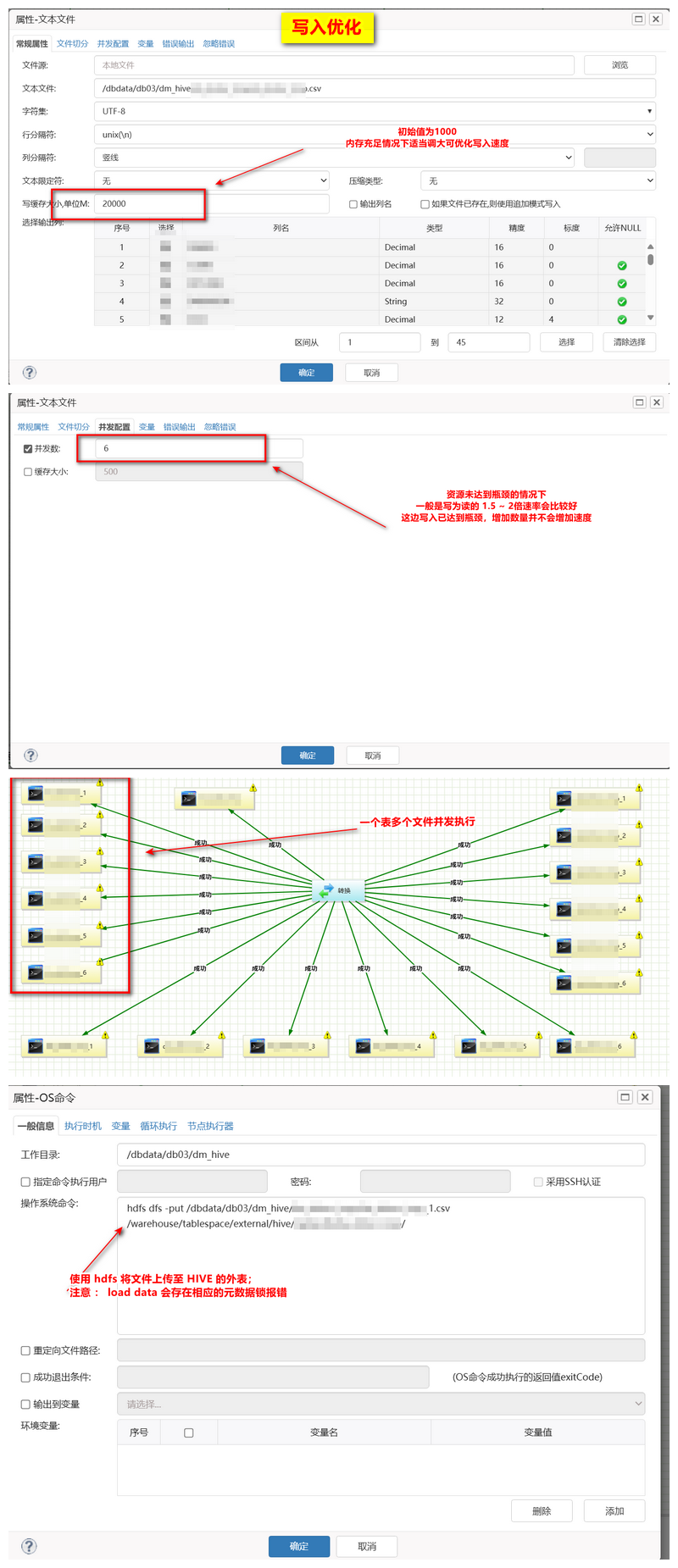
- 写入优化 :建立 HIVE 外表,通过 HDFS 进行并发装载(HIVE 快速装载无法做到真正意义上的并发进行,LOAD DATA 并发存有元数据锁)
问题 3 :ORACLE -> DM 的迁移速度慢
最初仅有 3W/s,优化至110W/s
- 解决方案 :
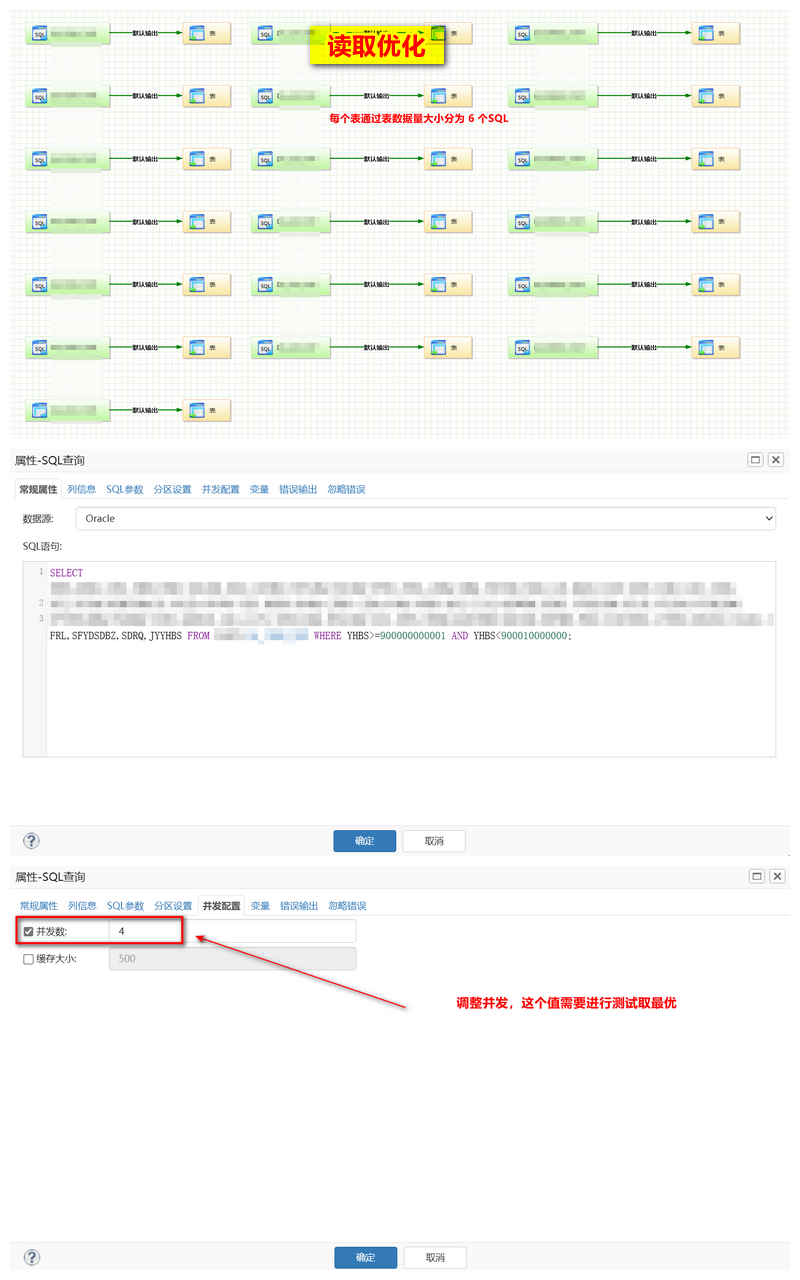
- 读取优化 :ORACLE 根据主键分多条 SQL 进行读取优化,充分调动源端的内存使用;
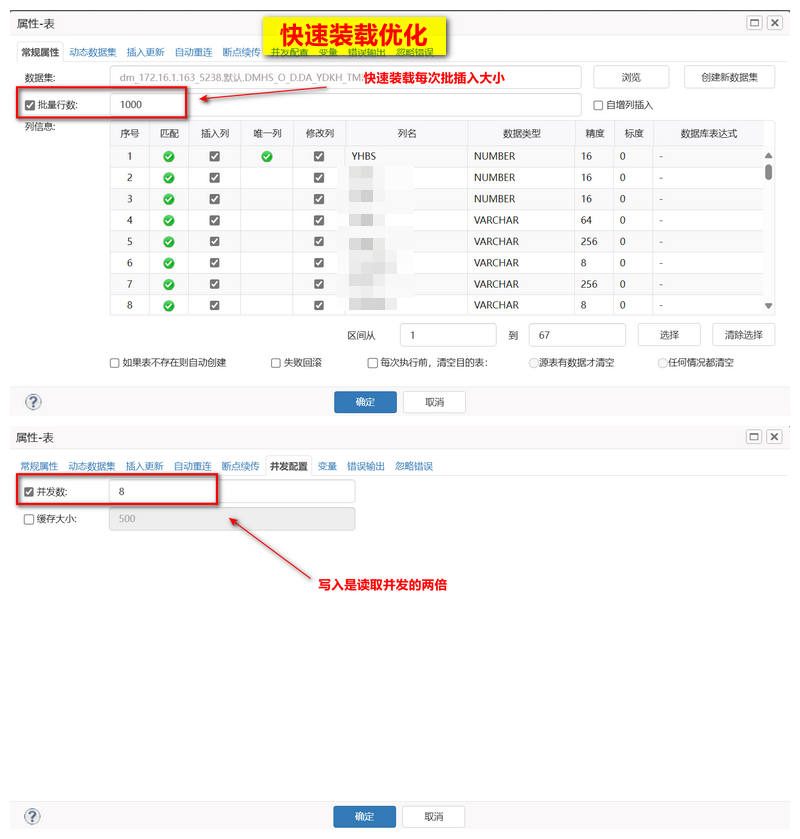
- 写入优化 :DM 端建立以主键进行分区的 HASH 表(32分区),根据主键 HASH 值写入,定点写入固定的分区;
- 写入优化 :dm.ini 增加共享池的大小(MEMORY_POOL)、共享池的个数(MEMORY_N_POOLS),增大 BUFFER_POOLS、BUFFER的大小,调大 PARALLEL_THRD_NUM 的大小;
- 写入优化 : 关闭归档日志
问题 4 :GP -> DM 的迁移速度慢
最初仅有 5W/s,优化至 88W/s
- 解决方案 :
- 读取优化 :GP 根据主键分多条 SQL 进行读取优化,;
- 写入优化 :DM 端建立以主键进行分区的 HASH 表(32分区),根据主键 HASH 值写入,定点写入固定的分区;
- 写入优化 :dm.ini 增加共享池的大小(MEMORY_POOL)、共享池的个数(MEMORY_N_POOLS),增大 BUFFER_POOLS、BUFFER的大小,调大 PARALLEL_THRD_NUM 的大小;
- 写入优化 : 关闭归档日志
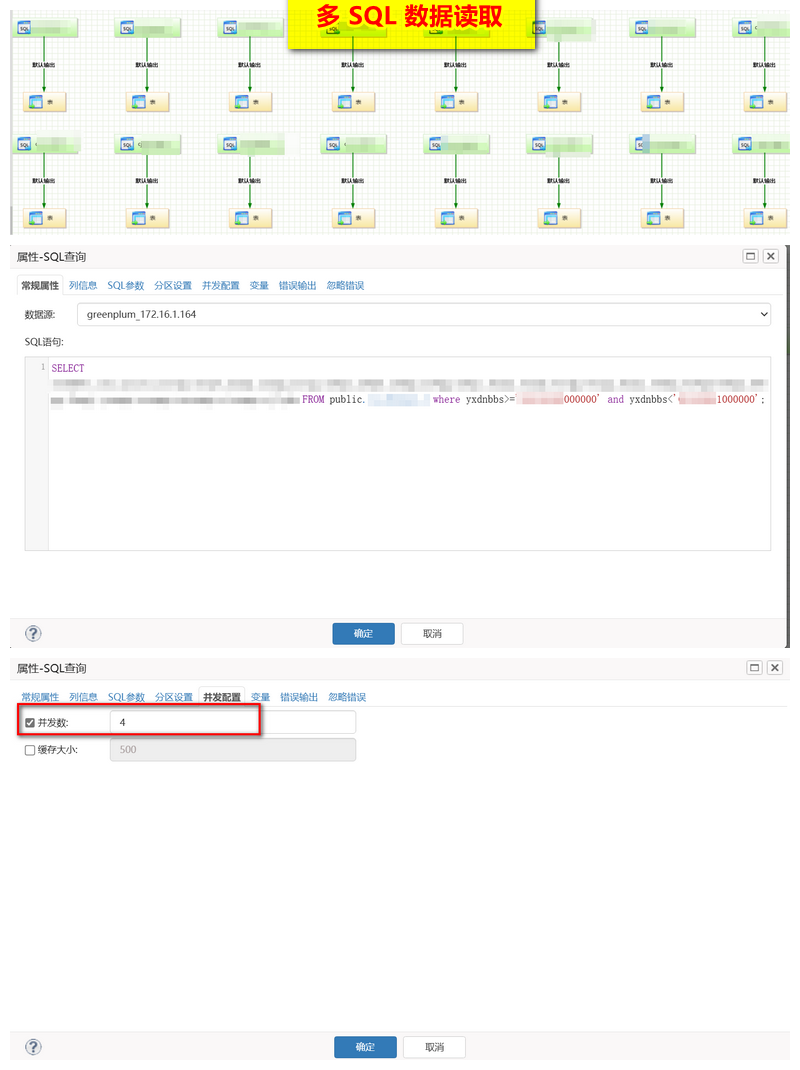
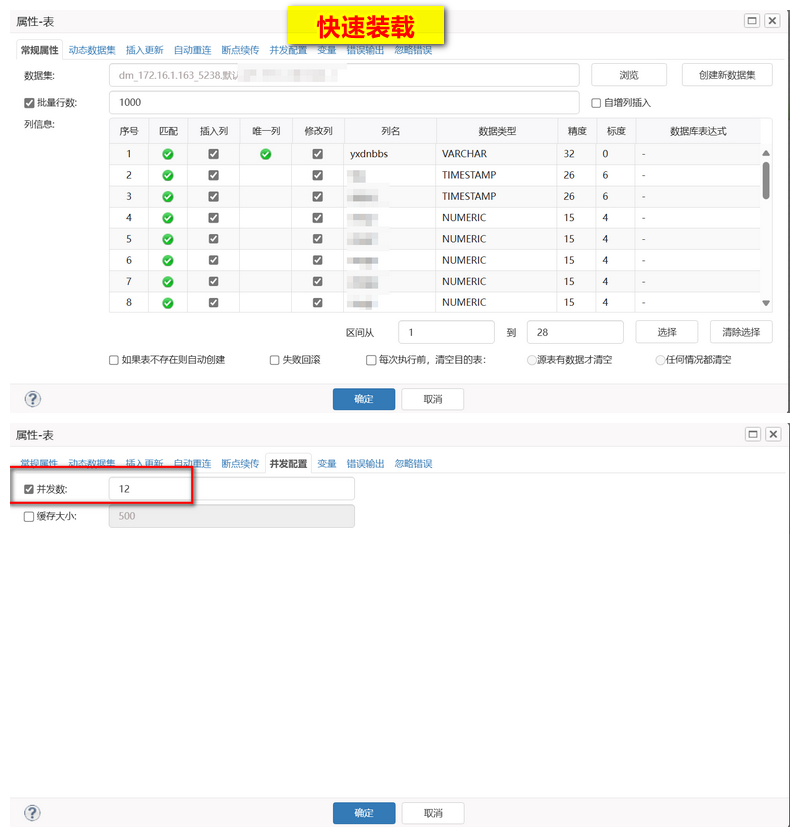
问题 5 :DM -> ORACLE 的迁移速度慢
最初仅有 6W/s,优化至 50~80W/s,主要原因为磁盘性能不稳定
- 解决方案 :
- 读取优化 :源端建立成相应的范围分区表,DMETL 的范围分区仅支持时间类型,不支持 varchar、decimal 等类型,改使用多表读取,通过正则匹配子表的前缀进行;
问题 6 :DM -> GP 的迁移速度慢
最初仅有 500/s,优化至 87W/s
- 解决方案 :
- GP 为分析型数据库,在事务型 SQL 执行
- 读取优化 :源端建立成相应的范围分区表,DMETL 的范围分区仅支持时间类型,不支持 varchar、decimal 等类型,改使用多表读取,通过正则匹配子表的前缀进行;
- 写入优化 : 建立 GP 外表,直接映射到对应读取生成的 CSV 上面,然后直接 insert into … select * from …
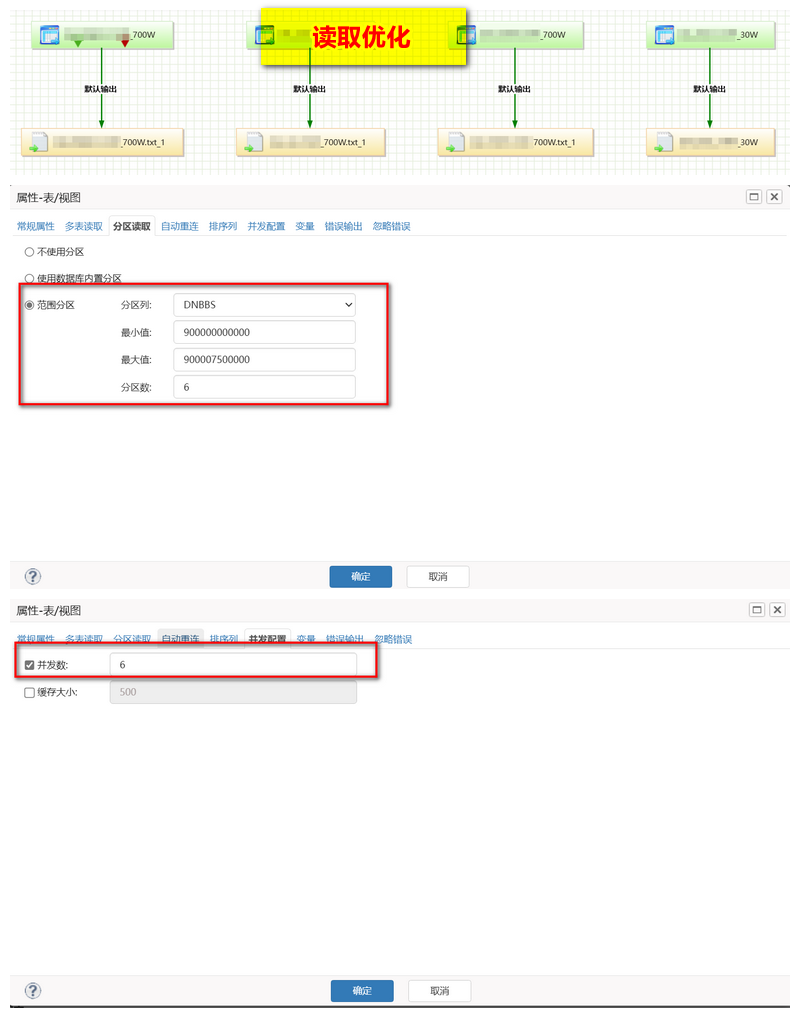
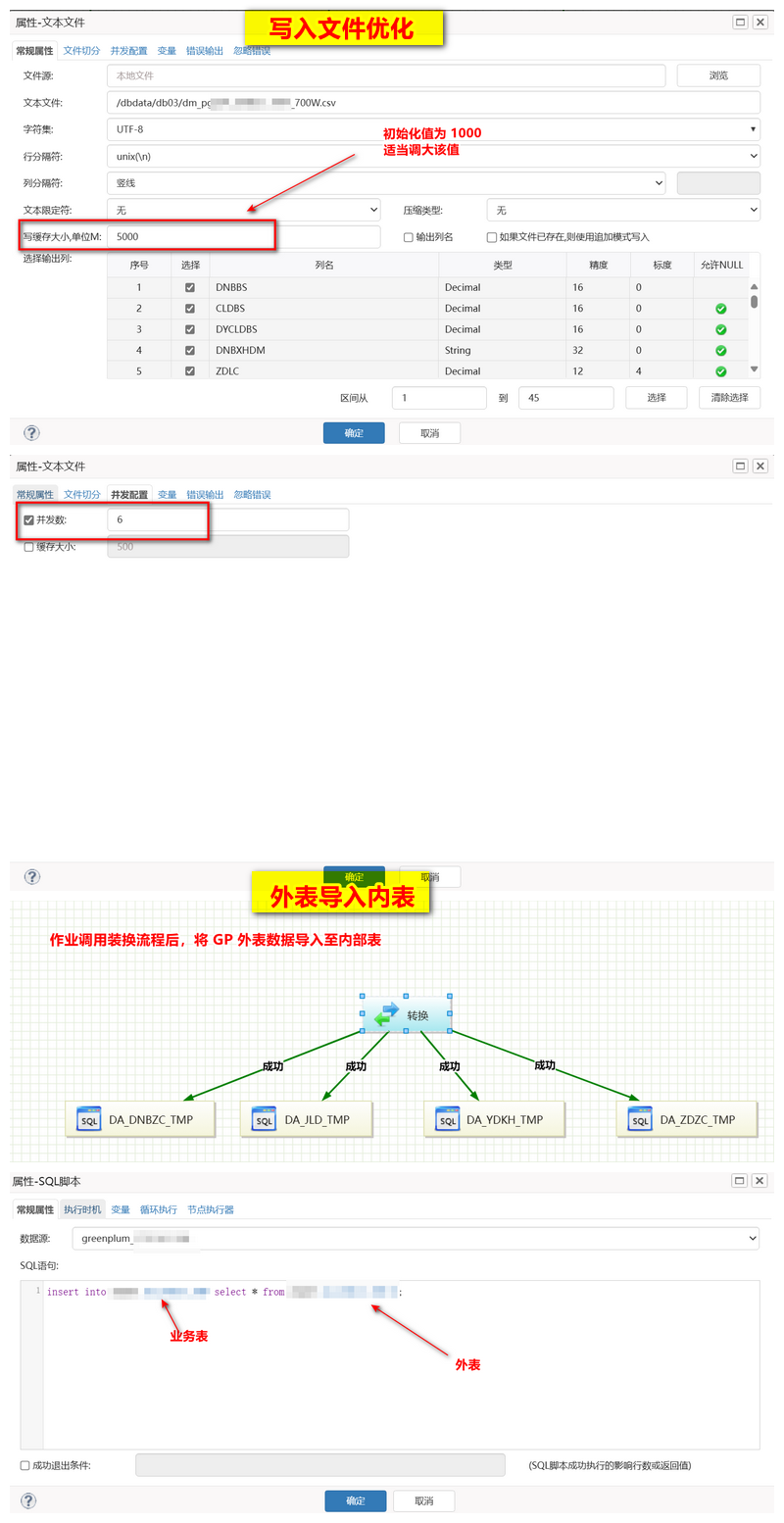
DMETL 迁移产品优化总结
至此对 DMETL 的安装使用有了初步认识,本篇博客到此结束!
参考内容
- Linux安装DMETL4
- 达梦社区






