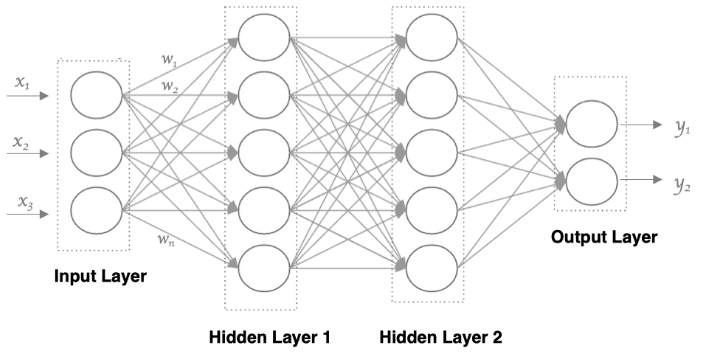
目标检测
YOLOv5 详细介绍
版本与特点
网络结构
技术亮点
YOLOv7 详细介绍
主要贡献
网络结构
技术亮点
性能对比
融合BiFormer注意力机制
融合SImAM注意力机制
CBAM注意力机制
DBB多分枝模块
LSKA注意力机制
CoordConv 坐标卷积
SIoU,CIoU,DIoU,EIoU,Facal损失函数修改
实现过程
环境配置
YOLOv7配置
YOLOv5配置
数据集格式转换
目录以及代码解释
代码运行
训练命令
推理
导出不同格式模型
修改步骤
注意力机制
卷积模块的更改
损失函数的修改
结果展示
无人机数据集训练数据
检测展示
总结
本文所涉及所有资源均在传知代码平台可获取。
目标检测
目标检测是计算机视觉领域的核心任务之一,它使计算机能够识别图像或视频帧中的一个或多个物体,并确定它们的位置,通常以矩形框或更复杂的形状表示。这项技术是许多现代应用的基础,包括但不限于自动驾驶汽车、智能视频监控系统、人脸识别、医疗影像分析以及增强现实。随着深度学习的发展,目标检测模型变得更加精确和高效,能够实时处理大量数据,为各种行业带来创新的解决方案。
YOLOv5 与 YOLOv7 系列详细介绍
YOLOv5 和 YOLOv7 都是目标检测领域的重要进展,YOLOv5 以其易用性和高效性受到社区的欢迎,而 YOLOv7 则在速度和精度上取得了显著的突破,为实时目标检测提供了新的解决方案。
YOLOv5 详细介绍
版本与特点
YOLOv5 系列包含不同规模的模型,包括 YOLOv5s、YOLOv5m、YOLOv5l 和 YOLOv5x,以适应不同的计算能力和实时性需求。
网络结构
● 输入端:对输入图像进行预处理,包括尺寸调整和归一化。
● Backbone:采用 CSPDarknet53 作为特征提取的主体,利用 Cross Stage Partial Network (CSPNet) 结构减少计算量。
● Neck:使用 PANet 结构进行特征融合,增强小物体检测能力。
● Head:包含目标检测的最终输出,使用 CIOU Loss 优化边界框预测。
技术亮点
● Mosaic 数据增强:通过随机拼接四张图片来增加数据多样性,提升模型泛化能力。
● 自适应锚框计算:根据不同数据集自动调整锚框尺寸,提高检测精度。
● 自适应图片缩放:动态调整输入图像尺寸,减少计算量并保持检测性能。
YOLOv7 详细介绍
主要贡献
YOLOv7 在速度和精度上均超越了先前所有已知的实时目标检测器,并在不使用任何预训练权重的情况下,仅在 COCO 数据集上训练。
网络结构
● 模型重参数化:引入模型重参数化技术,提升模型的表达能力和训练效率。
● 标签分配策略:结合跨网格搜索和匹配策略,提高标签分配的准确性。
● ELAN 高效网络架构:提出新的网络结构,优化特征提取和信息融合过程。
● 带辅助头的训练:使用辅助头提供额外的监督信号,增强模型训练。
技术亮点
● E-ELAN 结构:扩展的高效层聚合网络,增强模型在不同尺度上的特征学习能力。
● SPPCSPC 模块:一种新的模块,用于提高特征融合效率和检测精度。
● 动态标签分配:根据 Lead head 的输出动态分配标签,优化训练过程。
性能对比
YOLOv7 在多个指标上超越了 YOLOv5 和其他先进目标检测器,如在 30 FPS 的条件下达到更高的 AP,同时减少参数量和计算量。
Yolov5提供了较为完善以及模块化的目标检测代码,Yolov7基于Yolov5进行开发。基于YOLOv5和YOLOv7系列的多方面创新方法
::: tip
仅展示部分代码,完整代码请下载附件,融合方法请观看视频
:::
融合BiFormer注意力机制
BiFormer是一种先进的视觉Transformer架构,通过其核心创新——双级路由注意力(BRA)机制,实现了对计算资源的动态和内容感知分配。这种机制首先在粗区域级别过滤不相关键值对,然后对剩余的相关区域应用细粒度注意力,有效降低了计算负担和内存占用。BiFormer的设计允许模型专注于最相关的特征,从而在图像分类、目标检测、语义分割等多个视觉任务中展现出高效性能和优异的准确性。
部分代码如下
class BiLevelRoutingAttention_nchw(nn.Module):
def __init__(self, dim, num_heads=8, n_win=7, qk_scale=None, topk=4, side_dwconv=3, auto_pad=False, attn_backend='torch'):
super().__init__()
# local attention setting
self.dim = dim
self.num_heads = num_heads
assert self.dim % num_heads == 0, 'dim must be divisible by num_heads!'
self.head_dim = self.dim // self.num_heads
self.scale = qk_scale or self.dim ** -0.5 # NOTE: to be consistent with old models.
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
self.topk = topk
self.n_win = n_win # number of windows per row/col
self.qkv_linear = nn.Conv2d(self.dim, 3*self.dim, kernel_size=1)
self.output_linear = nn.Conv2d(self.dim, self.dim, kernel_size=1)
if attn_backend == 'torch':
self.attn_fn = regional_routing_attention_torch
else:
raise ValueError('CUDA implementation is not available yet. Please stay tuned.')
def forward(self, x:Tensor, ret_attn_mask=False):
N, C, H, W = x.size()
region_size = (H//self.n_win, W//self.n_win)
# STEP 1: linear projection
qkv = self.qkv_linear.forward(x) # ncHW
q, k, v = qkv.chunk(3, dim=1) # ncHW
# STEP 2: region-to-region routing
# NOTE: ceil_mode=True, count_include_pad=False = auto padding
# NOTE: gradients backward through token-to-token attention. See Appendix A for the intuitio
融合SImAM注意力机制
SimAM(Simultaneous Channel-Spatial Attention Module)是一种创新的无参数注意力机制,专为卷积神经网络设计。它基于神经科学理论,通过优化一个能量函数来推断每个神经元的重要性,从而实现对特征图的3D注意力加权,无需额外参数。SimAM利用了能量函数的快速闭式解,简化了实现过程,能够在不到十行代码中完成,同时避免了复杂的结构调整。实验结果表明,SimAM在多个视觉任务上展现出了提高卷积神经网络表征能力的灵活性和有效性,且由于其无参数特性,可以作为一种通用的注意力模块嵌入到现有网络中,提升性能而不增加计算负担
class SimAM(torch.nn.Module):
def __init__(self, e_lambda=1e-4):
super(SimAM, self).__init__() self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
CBAM注意力机制
CBAM(Convolutional Block Attention Module)是一种先进的注意力机制,它通过结合通道注意力和空间注意力来增强卷积神经网络的特征提取能力。CBAM由两个主要的子模块构成:通道注意力模块(Channel Attention Mechanism)和空间注意力模块(Spatial Attention Mechanism)。
通道注意力模块 利用全局平均池化和全局最大池化来整合输入特征图的空间信息,生成两个不同的空间上下文描述符,这两个描述符分别经过一个共享的多层感知机(MLP),然后相加以生成最终的通道注意力图。这种设计允许模型自适应地调整不同通道的重要性,以突出关键特征 。
空间注意力模块 则关注于特征图中的重要区域。它首先将通道注意力模块的输出作为输入,然后通过在通道维度上执行最大池化和平均池化,并将结果通过卷积层来提取空间特征,最终生成空间注意力图。这一过程有助于模型集中注意力于输入特征图中显著的区域 。
class CBAMBlock(nn.Module): def __init__(self, channel=512, reduction=16, kernel_size=7):
super().__init__()
self.ca = ChannelAttention(channel=channel, reduction=reduction)
self.sa = SpatialAttention(kernel_size=kernel_size) def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0) def forward(self, x):
b, c, _, _ = x.size()
out = x * self.ca(x)
out = out * self.sa(out)
return out
DBB多分枝模块
DBB(Dual-Branch Block)多分枝模块是一种深度学习架构中的创新结构,通过并行处理不同特征分支来增强模型对复杂数据特征的捕捉能力。这种模块通常包含两个或多个处理路径,每个路径可以应用不同的操作或特征提取策略,最终通过融合机制将这些路径的输出结合起来,从而提升模型在图像识别、分类和其他视觉任务中的表现。
class DiverseBranchBlock(nn.Module):
def __init__(self, in_channels, out_channels, k,
s=1, p=None, g=1, act=None,
internal_channels_1x1_3x3=None,
deploy=False, single_init=False):
super(DiverseBranchBlock, self).__init__()
self.deploy = deploy self.nonlinear = act self.kernel_size = k
self.out_channels = out_channels
self.groups = g if p is None:
p = autopad(k, p)
assert p == k // 2 if deploy:
self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=k, stride=s, padding=p, groups=g, bias=True) else: self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=k, stride=s, padding=p, groups=g) self.dbb_avg = nn.Sequential()LSKA注意力机制
Large Separable Kernel Attention(LSKA)是一种创新的注意力机制,旨在解决视觉注意力网络(VAN)中大卷积核的计算效率问题。LSKA通过将深度卷积层的二维卷积核分解为级联的水平和垂直一维卷积核,显著降低了计算复杂度和内存占用,同时保持了与标准大内核注意力(LKA)模块相当的性能。这种分解方法使得LSKA可以直接在注意力模块中使用大卷积核,而无需额外的模块。
class LSKA(nn.Module):
def __init__(self, dim, k_size=7):
super().__init__() self.k_size = k_size if k_size == 7:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,2), groups=dim, dilation=2)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=(2,0), groups=dim, dilation=2)
elif k_size == 11:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,4), groups=dim, dilation=2)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=(4,0), groups=dim, dilation=2)
elif k_size == 23:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 7), stride=(1,1), padding=(0,9), groups=dim, dilation=3)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(7, 1), stride=(1,1), padding=(9,0), groups=dim, dilation=3)
elif k_size == 35:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 11), stride=(1,1), padding=(0,15), groups=dim, dilation=3)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(11, 1), stride=(1,1), padding=(15,0), groups=dim, dilation=3)
elif k_size == 41:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 13), stride=(1,1), padding=(0,18), groups=dim, dilation=3)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(13, 1), stride=(1,1), padding=(18,0), groups=dim, dilation=3)
elif k_size == 53:
self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)
self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)
self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 17), stride=(1,1), padding=(0,24), groups=dim, dilation=3)
self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(17, 1), stride=(1,1), padding=(24,0), groups=dim, dilation=3) self.conv1 = nn.Conv2d(dim, dim, 1)
CoordConv 坐标卷积
CoordConv(坐标卷积)是一种改进的卷积神经网络方法,旨在解决传统卷积在处理空间位置信息时的局限性。传统卷积神经网络(CNN)虽然在图像分类等任务中表现出色,但它们在处理需要理解空间布局的任务时表现不佳,因为它们缺乏对输入空间内绝对位置的感知能力。
CoordConv通过在卷积层中引入显式的坐标信息来解决这个问题。具体来说,它在卷积的输入特征图后面增加了两个额外的通道,分别表示原始输入的x和y坐标。这样,卷积滤波器在进行局部运算时,可以感知到当前卷积核所处的空间位置,从而增强网络对空间信息的感知能力。
这种方法不仅继承了传统卷积的参数少和计算高效的特点,还允许网络根据任务需求学习不同程度的平移不变性和平移依赖性。如果坐标通道没有学习到任何信息,CoordConv就等价于传统卷积,具备完全的平移不变性;如果坐标通道学习到了一定的信息,则具备一定的平移依赖性
class AddCoords(nn.Module):
def __init__(self, with_r=False):
super().__init__()
self.with_r = with_r def forward(self, input_tensor):
"""
Args:
input_tensor: shape(batch, channel, x_dim, y_dim)
"""
batch_size, _, x_dim, y_dim = input_tensor.size() xx_channel = torch.arange(x_dim).repeat(1, y_dim, 1)
yy_channel = torch.arange(y_dim).repeat(1, x_dim, 1).transpose(1, 2) xx_channel = xx_channel.float() / (x_dim - 1)
yy_channel = yy_channel.float() / (y_dim - 1) xx_channel = xx_channel * 2 - 1
yy_channel = yy_channel * 2 - 1 xx_channel = xx_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)
yy_channel = yy_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3) ret = torch.cat([
input_tensor,
xx_channel.type_as(input_tensor),
yy_channel.type_as(input_tensor)], dim=1) if self.with_r:
rr = torch.sqrt(torch.pow(xx_channel.type_as(input_tensor) - 0.5, 2) + torch.pow(yy_channel.type_as(input_tensor) - 0.5, 2))
ret = torch.cat([ret, rr], dim=1) return ret
SIoU,CIoU,DIoU,EIoU,Facal损失函数修改
部分代码如下,相关
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, SIoU=False, EIoU=False, WIoU=False, Focal=False, alpha=1, gamma=0.5, scale=False, eps=1e-7):
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
if scale:
self = WIoU_Scale(1 - (inter / union))
实现过程
环境配置
YOLOv7配置
克隆项目
git clone https://github.com/WongKinYiu/yolov7.git
相关包配置
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
YOLOv5配置
克隆项目
git clone https://github.com/ultralytics/yolov5.git
相关包配置
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
数据集格式转换
数据集格式转换相对简单,可以通过以下链接把voc格式数据集转为yolo格式
CSDN–voc格式数据集转为yolo格式
目录以及代码解释
yolov7-main/
├── cfg/ # 配置目录
│ ├── baseline/ # 基线配置目录
│ ├── deploy/ # 部署配置目录
│ └── training/ # 训练配置目录
│
├── data/ # 数据目录
│ ├── coco.yaml # COCO数据集配置文件
│ ├── hyp.scratch.custom.yaml # 自定义超参数配置文件
│ ├── hyp.scratch.p5.yaml # P5模型超参数配置文件
│ ├── hyp.scratch.p6.yaml # P6模型超参数配置文件
│ └── hyp.scratch.tiny.yaml # Tiny模型超参数配置文件
│
├── deploy/ # 部署目录
│
├── models/ # 模型目录
│
├── utils/ # 工具目录
├── detect.py # 检测代码
├── export.py # 导出代码
│── hubconf.py # hub配置文件
├── requirements.txt # 项目依赖文件
├── test.py # 测试代码
├── train.py # 训练代码
└── train_aux.py # 辅助训练脚本代码运行
训练命令
● --workers 8: 设置训练过程中的工作线程数为8。这可以提高数据加载的效率。
● --device 0: 指定训练使用的设备编号为0,通常用于GPU编号。
● --batch-size 32: 设置每个训练批次的样本数量为32。较小的批次大小可以提供更频繁的更新,但可能影响训练稳定性。
● --data data/coco.yaml: 指定数据集配置文件的路径,这里是 data/coco.yaml,它包含了数据集的相关信息和设置。
● --img 640 640: 设置训练过程中使用的图像尺寸为640x640像素。这通常决定了模型输入的分辨率。
● --cfg cfg/training/yolov7.yaml: 指定模型配置文件的路径,这里是 cfg/training/yolov7.yaml,其中包含了模型架构和训练过程的详细配置。
● --weights '': 指定预训练权重文件的路径,空字符串表示从头开始训练,不使用预训练权重。
● --name yolov7: 为本次训练运行指定一个名称,这里是 yolov7,用于在保存模型和日志时区分不同的训练。
● --hyp data/hyp.scratch.p5.yaml: 指定超参数配置文件的路径,这里是 data/hyp.scratch.p5.yaml,包含了用于优化训练过程的超参数设置。
python train.py --workers 8 --device 0 --batch-size 32 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
推理
● --weights yolov7.pt: 指定模型权重文件 yolov7.pt。
● --conf 0.25: 置信度阈值设定为25%,意味着只有当预测置信度超过这个值时,结果才会被采纳。
● --img-size 640: 图像尺寸设置为640x640像素,这通常与模型训练时使用的尺寸一致。
● --source inference/images/horses.jpg: 指定图像文件 horses.jpg 作为检测源,该文件位于 inference/images/ 目录下。
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source yourvideo.mp4
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
导出不同格式模型
● --weights yolov7-tiny.pt: 指定要导出的模型权重文件,这里是 yolov7-tiny.pt。
● --grid: 启用网格化输出,可能用于模型推理时的并行处理。
● --end2end: 表示端到端模型导出,包括模型的所有部分。
● --simplify: 对模型进行简化,移除冗余操作,减小模型大小。
● --topk-all 100: 在所有类别中选择置信度最高的前100个预测结果。
● --iou-thres 0.65: 设置IOU(交并比)阈值,用于非极大值抑制(NMS),0.65表示重叠程度超过65%的预测框将被抑制。
● --conf-thres 0.35: 设置置信度阈值,只有超过这个阈值的预测结果才会被保留。
● --img-size 640 640: 设置模型输入图像的尺寸为640x640像素。
● --max-wh 640: 设置输出图像的最大宽度和高度限制为640像素,保持图像尺寸的一致性。
python export.py --weights yolov7-tiny.pt --grid --end2end --simplify \
--topk-all 100 --iou-thres 0.65 --conf-thres 0.35 --img-size 640 640 --max-wh 640
修改步骤
注意力机制
1. 有序列表先将注意力机制的相关代码加入到common的文件中,然后对Conv进行修改

2. 将相应的模块加入到yolo中的以下代码模块中

3. 在相应的网络结构配置文件中进行修改

卷积模块的更改
卷积模块的更改与注意力机制类似,从上面第二部开始便可

损失函数的修改
损失函数的修改位置有两个


结果展示
无人机数据集训练数据
以上模型创新结果数据
| 模型 | P | R | mAP50 | mAP95 |
| Yolov7-tiny | 0.803 | 0.752 | 0.767 | 0.461 |
| Yolov7-tiny-BiFormer | 0.839 | 0.749 | 0.773 | 0.469 |
| Yolov7-tiny-SIoU | 0.797 | 0.772 | 0.782 | 0.476 |
| Yolov7-tiny-SIoU-BiFormer | 0.838 | 0.746 | 0.783 | 0.474 |
| 模型 | 时间 | P | R | mAP50 | mAP95 |
| yolov5s-v6.1 | 91.1ms | 0.830 | 0.757 | 0.776 | 0.462 |
| yolov5s v1 | 99ms | 0.614 | 0.779 | 0.750 | 0.459 |
| yolov7-tiny | 75.2ms | 0.809 | 0.764 | 0.774 | 0.466 |
| yolov7-tiny-bi-si | 76.0ms | 0.839 | 0.747 | 0.784 | 0.474 |
| yolov7-tiny-si | 74.7 | 0.812 | 0.758 | 0.782 | 0.476 |
检测展示


总结
该教程主要包含了注意力机制,卷积模块和损失函数等方面的创新,所有代码均在附件中,且经过实际的运行试测,均无bug,但创新或者提升针对不同数据集有不同的效果,读者可以反复尝试,另外对于不同的模块可以在网络结构中放置到不同的位置,可以反复尝试确定能够提升的点。
感觉不错,点击我,立即使用




![vcpkg install libtorch[cuda] -allow-unsupported-compiler](https://i-blog.csdnimg.cn/direct/36b15e279696405e9efe0e8ac15df564.png)