BLEU 是 2002 年提出的,而 ROUGE 是 2003 年提出的。这两种指标虽然存在着一些问题,但是仍然是比较主流的评价指标。
BLUE
BLEU 的全称是 Bilingual evaluation understudy,BLEU 的分数取值范围是 0~1,分数越接近1,说明翻译的质量越高。BLEU 主要是基于精确率(Precision)的。
- 核心:比较候选译文和参考译文里的 n-gram 的重合程度,重合程度越高就认为译文质量越高。
- unigram用于衡量单词翻译的准确性,高阶n-gram用于衡量句子翻译的流畅性。
- 通常取N=1~4,再加权平均。下面是BLEU 的整体公式。

- BLEU 需要计算译文 1-gram,2-gram,…,N-gram 的精确率,一般 N 设置为 4 即可,公式中的 Pn 指 n-gram 的精确率。
- Wn 指 n-gram 的权重,一般设为均匀权重,即对于任意 n 都有 Wn = 1/N。
- BP 是惩罚因子,如果译文的长度小于最短的参考译文,则 BP 小于 1。
- BLEU 的 1-gram 精确率表示译文忠于原文的程度,而其他 n-gram 表示翻译的流畅程度。
n-gram 精确率计算
使用机器学习的方法生成文本的翻译之后,需要评价模型翻译的性能,一般用C表示机器翻译的译文,另外还需要提供 m 个参考的翻译S1,S2, …,Sm。评价指标就可以衡量机器翻译的C和参考翻译S1,S2, …,Sm的匹配程度。
假设机器翻译的译文C和一个参考翻译S1如下:
C: a cat is on the table
S1: there is a cat on the table
则可以计算出 1-gram,2-gram,… 的精确率:
- p1 计算 a cat is on the table 分别都在参考翻译S1中 所以 p1 = 1
- p2 (a, cat)在, (cat is) 没在, (is on) 没在, (on the) 在, (the table)在 所以p2 = 3/5
- p3 (a cat is)不在, (cat is on)不在, (is on the)不在, (on the table)在 所以 p3 = 1/4

上面的在或者不在, 说的都是当前词组有没有在参考翻译中,直接这样子计算 Precision 会存在一些问题,例如:
C: there there there there there
S1: there is a cat on the table
这时候机器翻译的结果明显是不正确的,但是其 1-gram 的 Precision 为1,因此 BLEU 一般会使用修正的方法。给定参考译文 S 1 , S 2 , … , S m S_1,S_2,\dots,S_m S1,S2,…,Sm,可以计算C里面 n 元组的 Precision,计算公式如下:

针对上面的例子 p1 = 1/5 。
惩罚因子
上面介绍了 BLEU 计算 n-gram 精确率的方法, 但是仍然存在一些问题,当机器翻译的长度比较短时,BLEU 得分也会比较高,但是这个翻译是会损失很多信息的,例如:
C: a cat
S1: there is a cat on the table
因此需要在 BLEU 分数乘上惩罚因子

优点
它的易于计算且速度快,特别是与人工翻译模型的输出对比;
它应用范围广泛,这可以让你很轻松将模型与相同任务的基准作对比。
缺点
它不考虑语义,句子结构
不能很好地处理形态丰富的语句(BLEU原文建议大家配备4条翻译参考译文)
BLEU 指标偏向于较短的翻译结果(brevity penalty 没有想象中那么强)
ROUGE_53">ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)专注于召回率(关注有多少个参考译句中的 n- gram出现在了输出之中)而非精度(候选译文中的n-gram有没有在参考译文中出现过)。
- ROUGE-N: 在 N-gram 上计算召回率
- ROUGE-L: 考虑了机器译文和参考译文之间的最长公共子序列
- ROUGE-W: 改进了ROUGE-L,用加权的方法计算最长公共子序列
- ROUGE-S 允许n-gram出现跳词(skip)
ROUGE 用作机器翻译评价指标的初衷是这样的:在 SMT(统计机器翻译)时代,机器翻译效果稀烂,需要同时评价翻译的准确度和流畅度;等到 NMT (神经网络机器翻译)出来以后,神经网络脑补能力极强,翻译出的结果都是通顺的,但是有时候容易瞎翻译。
ROUGE的出现很大程度上是为了解决NMT的漏翻问题(低召回率)。所以 ROUGE 只适合评价 NMT,而不适用于 SMT,因为它不管候选译文流不流畅
ROUGEN_64">ROUGE-N
ROUGE-N 主要统计 N-gram 上的召回率,对于 N-gram,可以计算得到 ROUGE-N 分数,计算公式如下:
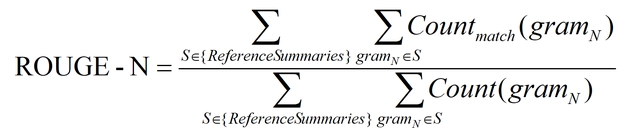
公式的分母是统计在参考译文中 N-gram 的个数,而分子是统计参考译文与机器译文共有的 N-gram 个数。
C: a cat is on the table
S1: there is a cat on the table
上面例子的 ROUGE-1 和 ROUGE-2 分数如下:
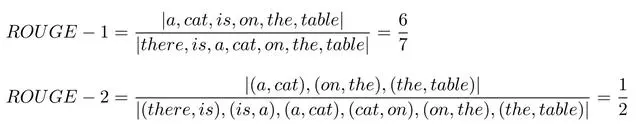
如果给定多个参考译文 S i S_i Si,Chin-Yew Lin 也给出了一种计算方法,假设有 M 个译文 S 1 , . . . , S M S_1, ..., S_M S1,...,SM。ROUGE-N 会分别计算机器译文和这些参考译文的 ROUGE-N 分数,并取其最大值,公式如下。这个方法也可以用于 ROUGE-L,ROUGE-W 和 ROUGE-S。
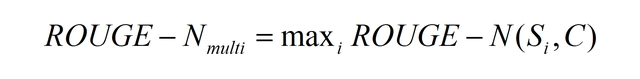
ROUGEL_74">ROUGE-L
ROUGE-L 中的 L 指最长公共子序列 (longest common subsequence, LCS),ROUGE-L 计算的时候使用了机器译文C和参考译文S的最长公共子序列,计算公式如下:
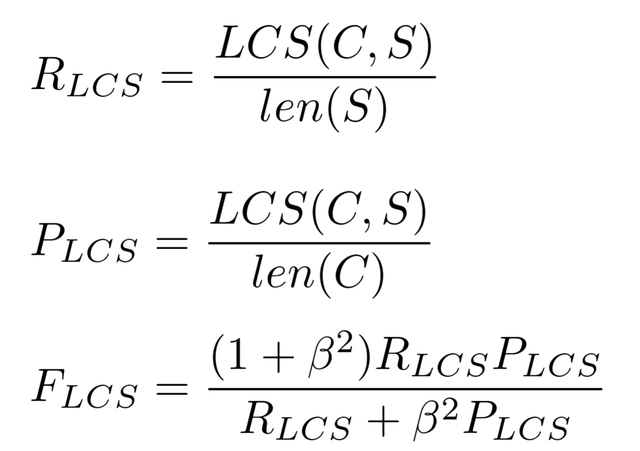
公式中的 RLCS 表示召回率,而 PLCS 表示精确率,FLCS 就是 ROUGE-L。一般 beta 会设置为很大的数,因此 FLCS 几乎只考虑了 RLCS (即召回率)。注意这里 beta 大,则 F 会更加关注 R,而不是 P,可以看下面的公式。如果 beta 很大,则 PLCS 那一项可以忽略不计。
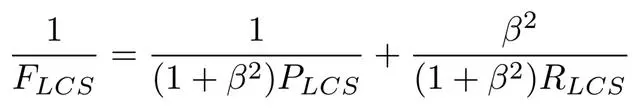
ROUGEW_80">ROUGE-W
ROUGE-W 是 ROUGE-L 的改进版,考虑下面的例子,X表示参考译文,而 Y 1 , Y 2 Y_1,Y_2 Y1,Y2表示两种机器译文。
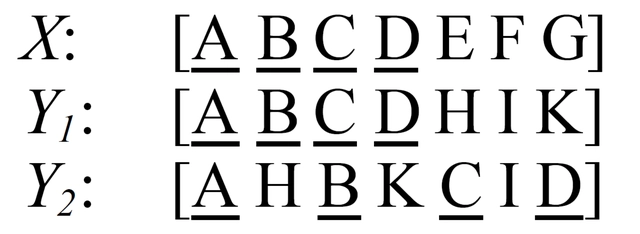
在这个例子中,明显 Y 1 Y_1 Y1的翻译质量更高,因为 Y 1 Y_1 Y1 有更多连续匹配的翻译。但是采用 ROUGE-L 计算得到的分数确实一样的,即 R O U G E − L ( X , Y 1 ) = R O U G E − L ( X , Y 2 ) ROUGE-L(X, Y_1)=ROUGE-L(X, Y_2) ROUGE−L(X,Y1)=ROUGE−L(X,Y2)。
因此作者提出了一种加权最长公共子序列方法 (WLCS),给连续翻译正确的更高的分数,具体做法可以阅读原论文《ROUGE: A Package for Automatic Evaluation of Summaries》。
ROUGES_85">ROUGE-S
ROUGE-S 也是对 N-gram 进行统计,但是其采用的 N-gram 允许"跳词 (Skip)",即单词不需要连续出现。例如句子 “I have a cat” 的 Skip 2-gram 包括 (I, have),(I, a),(I, cat),(have, a),(have, cat),(a, cat)。
NIST
NIST:此方法可被视为是BLEU的一种变体,使用信息熵来加权匹配。为平凡的词组分配较少的权重,以此来降低对常用词的偏好。
GTM
GTM(General Text Matcher)[5]:考虑了F1值作为评判,而非单一的准确率或者召回率,并且为长匹配提供更高的权重。
METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering)[6] :相较于BLEU同时考虑了召回率以及同义词的影响。具体的,考虑了词级、词干、同义词以及重述匹配。在实现时,仅考虑了unigram
BERTScore
https://zhuanlan.zhihu.com/p/380929670
https://baijiahao.baidu.com/s?id=1655137746278637231
https://zhuanlan.zhihu.com/p/144182853