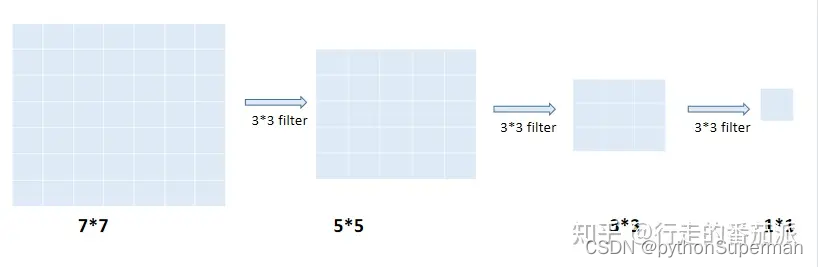
框架
让我们先看一下CNN的框架
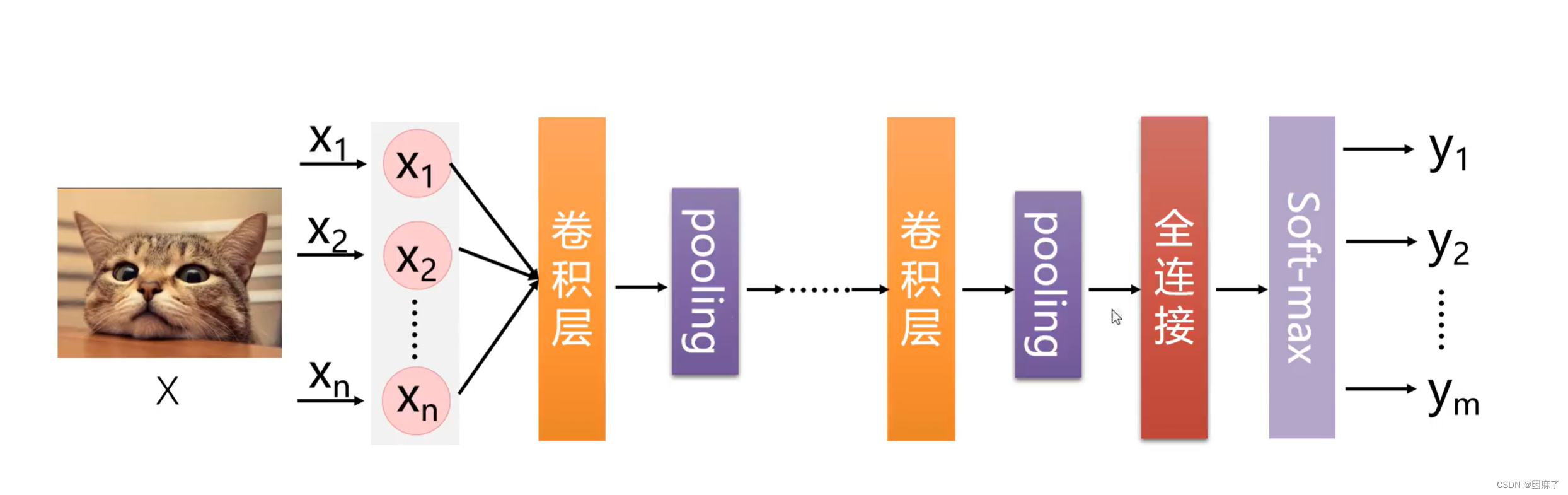
卷积层中后是ReLu激活函数 ,然后是深化池,之后是全连接,最后进行Softmax进行归一化。
所以,我们先逐一了解一下它们各个部分
全连接层
全连接层也称感知机,BP神经网络
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”(下面会讲到这个分布式特征)映射到样本标记空间的作用
优缺点
优点
1.能够自适应,自主学习(能够根据x得出y)
2.有着较强的非线性映射能力(在结点后增加了ReLu激活函数)
3.严谨的推导过程
4.较强的泛化能力
5.降维或升维
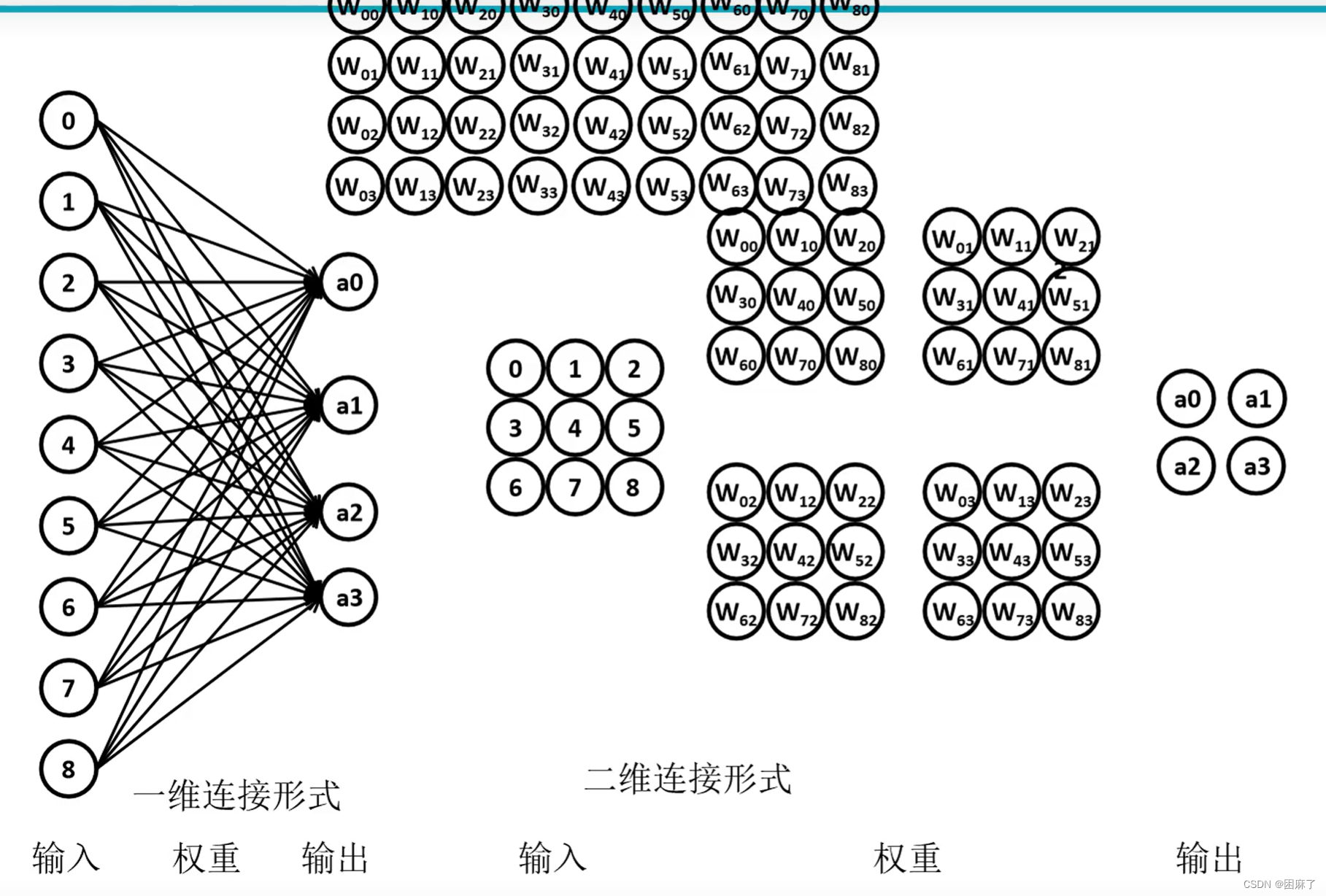
降维呢,也很好理解,由第一列的九维变为第二列的四维
我们再来看看缺点
缺点
1.全局感知(每一结点的值都会影响最后的w)
2.权重参数众多(4*9=36个权重)
3.学习速率慢(因为权重矩阵巨大)
代码演示
在这里,我们只定义了一层全连接层
import torch.nn
class CNNnetwork(torch.nn.Module):self.linear1 = torch.nn.Linear(3*3, 4)self.ReLU1 = torch.nn.ReLU()def forward(self, x):x = x.reshape(x.shape[0], -1)x = self.linear1(x)x = self.ReLU1(x)return x前向传播是我们自己来定义的,而后向传播是自动执行的
为了解决全连接层去全局感知的问题,我们提出了一种解决方案--局部连接
局部连接
图示
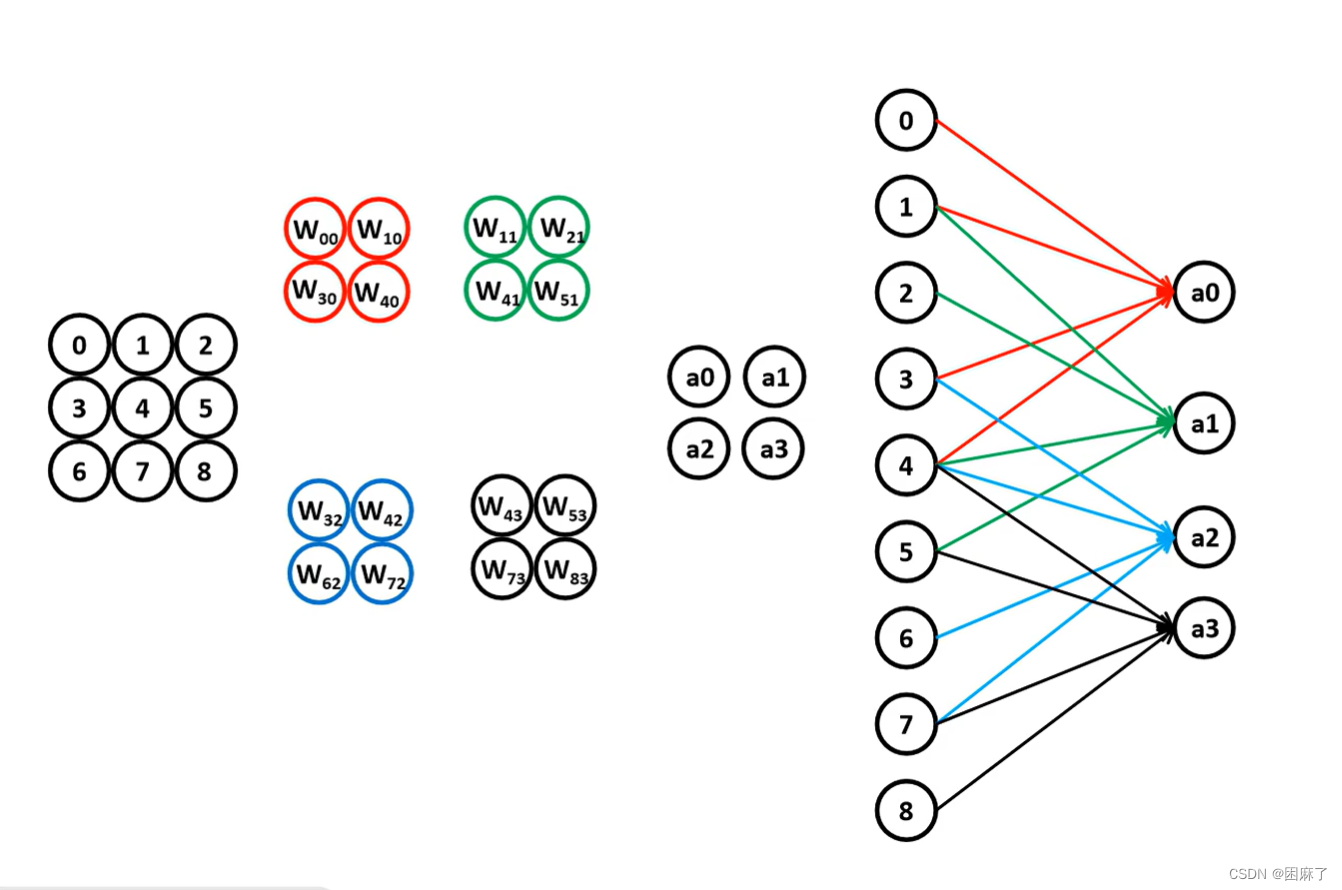
0,1,3,4与w00,w10,w30,w40相乘得到a0,同理
1,2,4,5与w11,w21,w41,w51相乘得到a1
3,4,6,7与w32,w42,w62,w72相乘得到a2
4,5,7,8与w43,w53,w73,w83相乘得到a3
即以1为步长,每4个为一组,进行相乘
优点
显而易见,减少了权重
由原来的4*8=36变为了4*4=16
卷积神经网络--参数共享
局部连接的plus版
图示
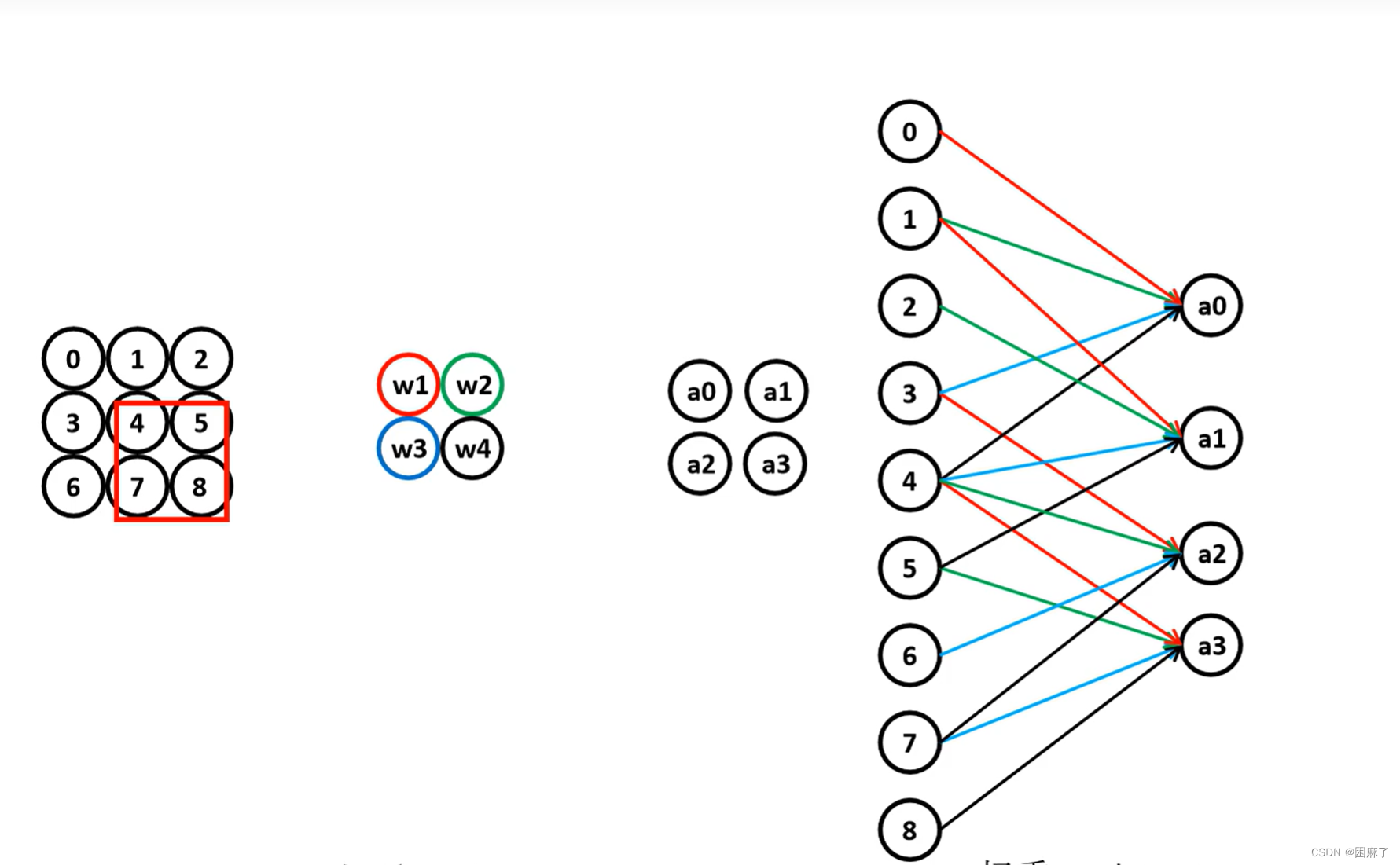
以最后一部分2*2矩阵为例,与局部连接原理相同
4*w1+5*w2+7*w3+8*w4得到a4
a0,a1,a2就是同理啦
这样一来我们的权重就变为了1*4=4
权重更少了
这样就体现出来了参数共享的优点
优点
进一步减少权重
像这样输出比输入减小了,比如输入5*5,输出3*3,则称为下采样
在上图中的w1,w2,w3,w4这一堆,则称为卷积核
单通道卷积核及步长stride
卷积网络之所以工作,完全是卷积核的功劳
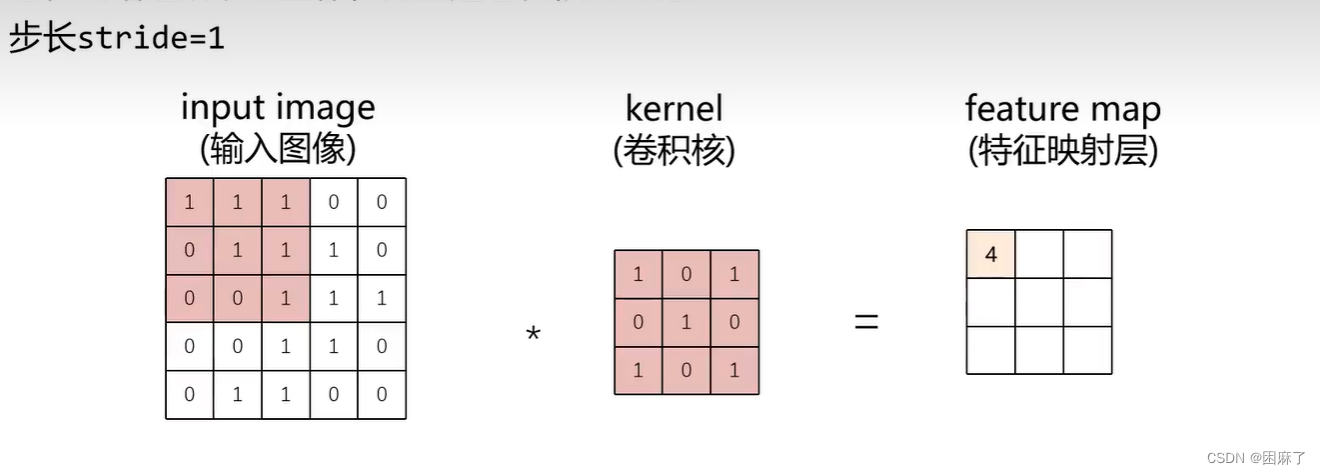
那么feature map是怎么计算的呢?
图中深色部分是计算部分
input image和kernel同一位置上的数相乘,最后将所有相乘的数相加,得到最终结果,也就是4
input image为输入图像,kernel为卷积核,feature map为特征映射层
步长为1 ,2
步长为1,根据步长进行滑动,先从左到右按步长1滑动,再从上到下按步长1滑动
怎么求feature map的大小呢?

i为input image的简写,k为kernel的简写
代码演示
import torch
import torch.nn.functional as Finput=torch.tensor([[1,1,1,0,0],[0,1,1,1,0],[0,0,1,1,1],[0,0,1,1,0],[0,1,1,0,0]])
kernel=torch.tensor([[1,0,1],[0,1,0],[1,0,1]])
print("原尺寸:")
print(input.shape)
print(kernel.shape)# 重新定义尺寸,把尺寸改为4位数,1个batchsize,1个通道,长和宽不变
# 矩阵的个数就是通道数
input=torch.reshape(input,(1,1,5,5))
kernel=torch.reshape(kernel,(1,1,3,3))
print("修改后的尺寸:")
print(input.shape)
print(kernel.shape)
# stride=1时的输出
output1=F.conv2d(input,kernel,stride=1)
print("stride=1时的输出")
print(output1)
# stride=2时的输出
output2=F.conv2d(input,kernel,stride=2)
print("stride=2时的输出")
print(output2)torch.nn.functional.conv2d是用来进行卷积运算的,参数如下:
- input:输入特征图
- weight:卷积核
- bias:偏置参数
- stride:卷积步长
- padding:填充
- dilation:膨胀系数
- groups:分组卷积
结果
原尺寸:
torch.Size([5, 5])
torch.Size([3, 3])
修改后的尺寸:
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
stride=1时的输出
tensor([[[[4, 3, 4],[2, 4, 3],[2, 3, 4]]]])
stride=2时的输出
tensor([[[[4, 4],[2, 4]]]])步长为3
当我们将步长设置为3,移动时,我们发现不能移动完,会缺失一部分,这时候,我们就需要用到padding(填充)

默认padding为VALID有效的
最终feature map的大小可以根据以上公式计算,无论有没有padding,上述公式都适用
当padding为SAME时,得到的结果的长宽与输入的长宽一致
代码演示
import torch
import torch.nn.functional as Finput=torch.tensor([[1,1,1,0,0],[0,1,1,1,0],[0,0,1,1,1],[0,0,1,1,0],[0,1,1,0,0]])
kernel=torch.tensor([[1,0,1],[0,1,0],[1,0,1]])
print("原尺寸:")
print(input.shape)
print(kernel.shape)# 重新定义尺寸,把尺寸改为4位数,1个batchsize,1个通道,长和宽不变
# 矩阵的个数就是通道数
input=torch.reshape(input,(1,1,5,5))
kernel=torch.reshape(kernel,(1,1,3,3))
print("修改后的尺寸:")
print(input.shape)
print(kernel.shape)
# # stride=1时的输出
# output1=F.conv2d(input,kernel,stride=1)
# print("stride=1时的输出")
# print(output1)
# # stride=2时的输出
# output2=F.conv2d(input,kernel,stride=2)
# print("stride=2时的输出")
# print(output2)
output3=F.conv2d(input,kernel,stride=3,padding=2)
print("stride=3,padding=2")
print(output3)
output4=F.conv2d(input,kernel,stride=1,padding=1)
print("stride=1,padding=1")
print(output4)
output5=F.conv2d(input,kernel,stride=1,padding="same")
print("stride=1,padding='same'")
print(output5)结果
原尺寸:
torch.Size([5, 5])
torch.Size([3, 3])
修改后的尺寸:
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
stride=3,padding=2
tensor([[[[1, 1, 0],[0, 4, 0],[0, 1, 0]]]])
stride=1,padding=1
tensor([[[[2, 2, 3, 1, 1],[1, 4, 3, 4, 1],[1, 2, 4, 3, 3],[1, 2, 3, 4, 1],[0, 2, 2, 1, 1]]]])
stride=1,padding='same'
tensor([[[[2, 2, 3, 1, 1],[1, 4, 3, 4, 1],[1, 2, 4, 3, 3],[1, 2, 3, 4, 1],[0, 2, 2, 1, 1]]]])我们可以看出,output4与output5的结果相同,这就能够帮助我们更好地理解padding="same"了
多通道多卷积核
图示
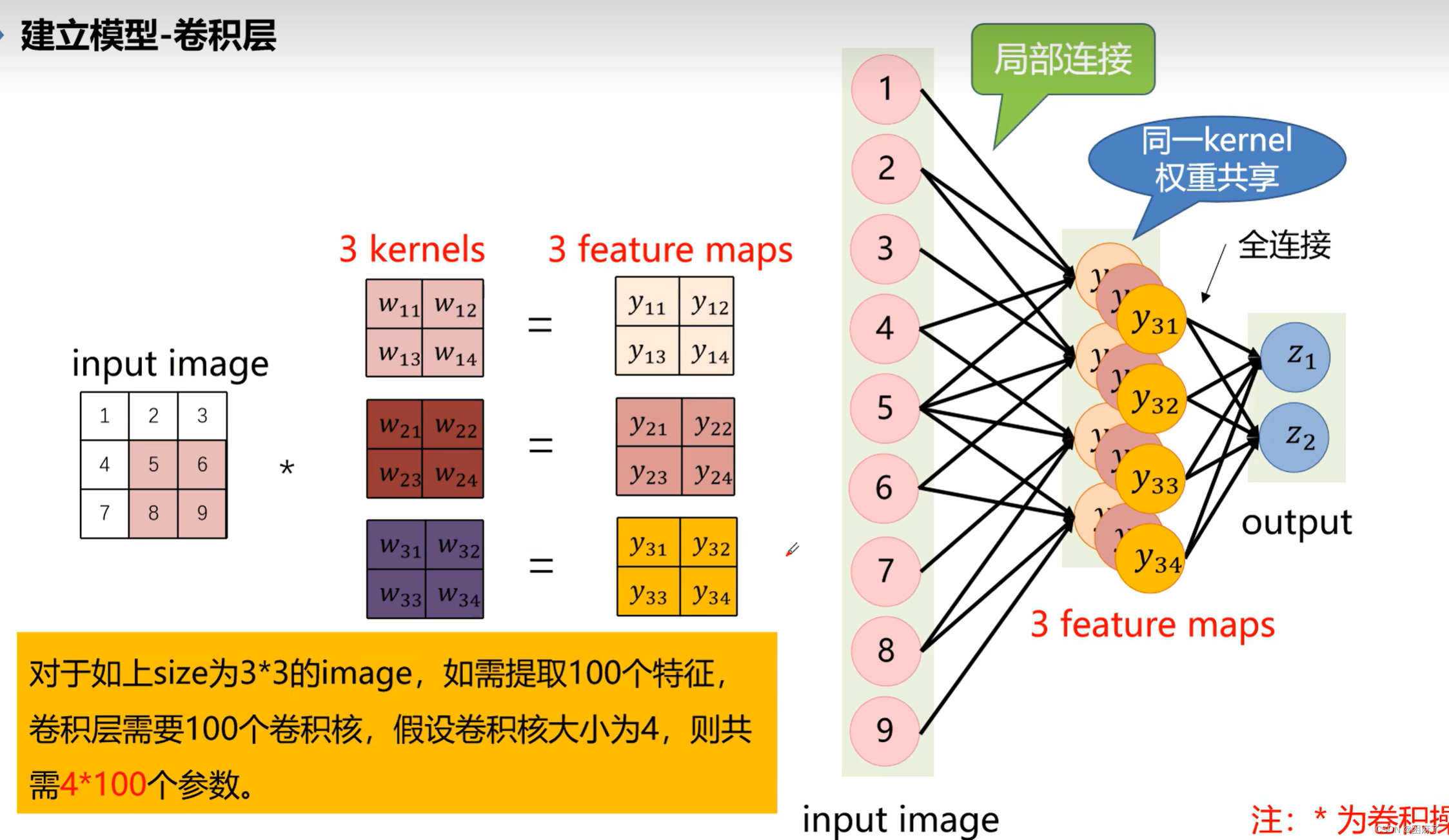
我们知道,有几个矩阵就有几个通道。
通常来说,RGB图像时三通道的
卷积核的通道个数要与输入图像层的通道个数相同,而输出为对应通道在滑动窗口内卷积的和
计算过程图示
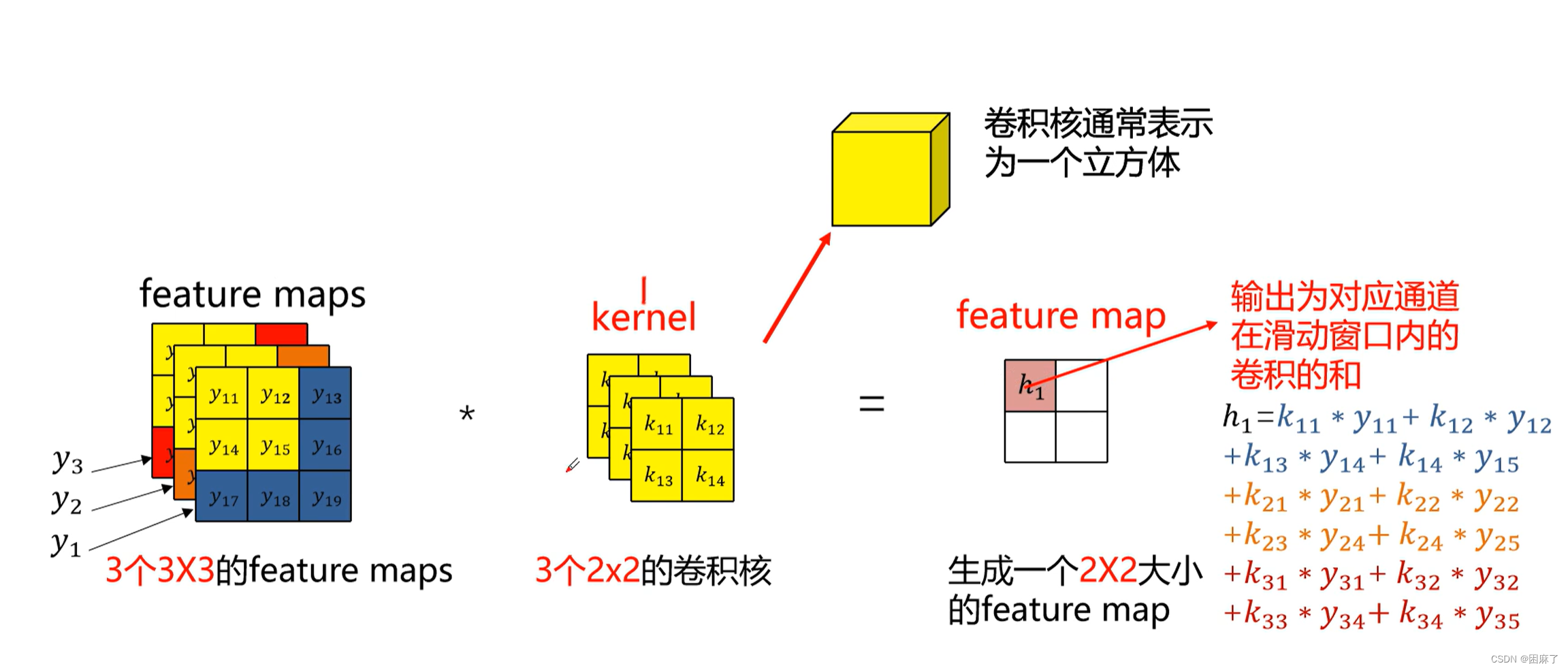
注意:
feature map的个数是根据卷积核来的,有几个卷积核就有几个feature map,
而卷积核的个数是我们自己设置的,卷积核的通道数是根据上一层的通道数确定的
池化层
经过池化层后,图像的大小变小(下采样),通道数保持不变,默认的时减小为原来的一半。
作用
对输入的特征图进行压缩
1.特征不变性,提取主要特征
2.特征降维,简化网络计算复杂度
3.减小过拟合,更方便优化
最常用的:最大池化
图示
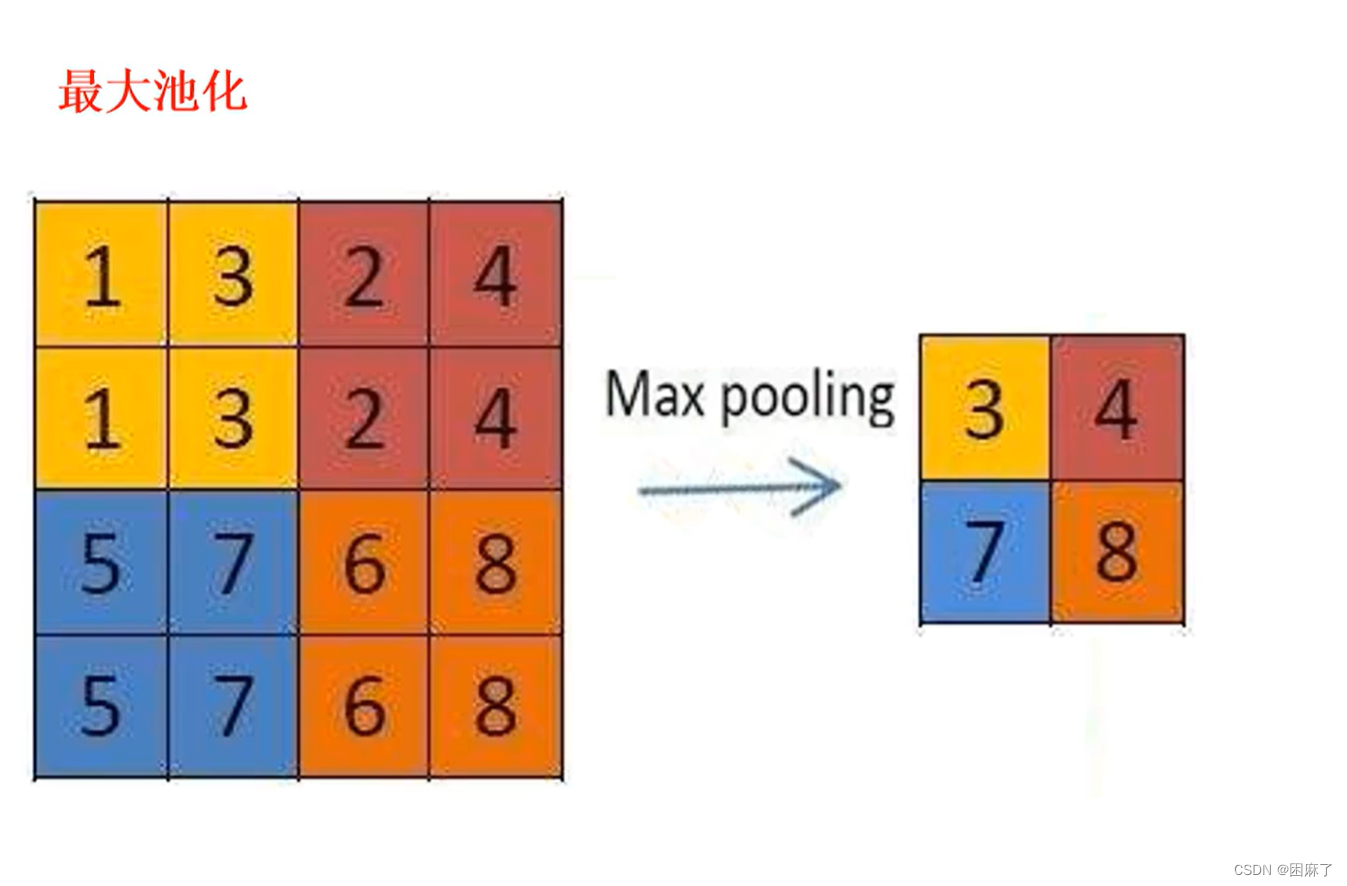
输入层为4*4的矩阵,卷积核为2*2的矩阵,步长为2,进行最大池化
首先我们看第一组,1,3,1,3 最大值为3,那么特征图层的第一个结果就是最大值三,按步长滑动,后面同理,都是取最大值
平均池化

与最大池化同理,不同的地方是平均池化取4个数的平均值
下面让我们来看看神经元连接方式和池化后的大小计算
神经元连接方式和池化后的大小计算
图示
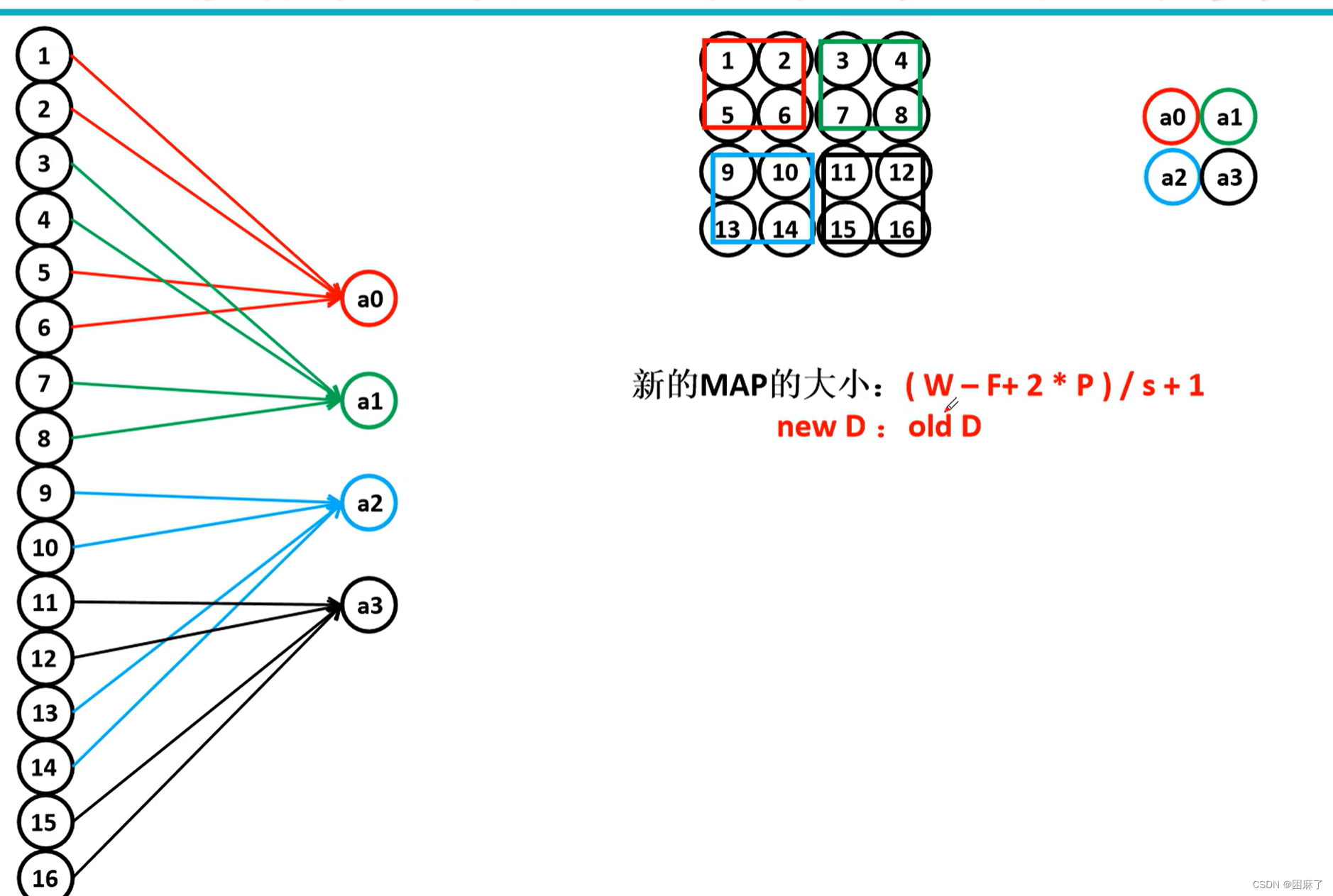
特征
1.没有要学习的参数:池化只是从目标区域中取最大值或平均值,所以没有必要有学习的1参数。
2.通道数不发生改变
3.它是利用图像局部相关性的原理,对图像进行子抽样,这样可以保留有用信息,对微小的位置变化具有鲁棒性(健壮性),输入数据发生微小偏差时,池化仍会返回相同的结果
代码演示
import torch
input=torch.tensor([[1,3,2,4],[1,3,2,4],[5,7,6,8],[5,7,6,8]],dtype=torch.float32)mp=torch.nn.MaxPool2d(kernel_size=2)
ap=torch.nn.AvgPool2d(kernel_size=2)input=torch.reshape((input),(1,1,4,4))output1=mp(input)
print(output1)output2=ap(input)
print(output2)reshape将input的形状转化为1,1,4,4
意思是,1个矩阵,1个通道,input的形状变为4*4
mp=torch.nn.MaxPool2d(kernel_size=2) ap=torch.nn.AvgPool2d(kernel_size=2)
分别为最大池化和平均池化,卷积核大小都是2*2的
结果
tensor([[[[3., 4.],[7., 8.]]]])
tensor([[[[2., 3.],[6., 7.]]]])卷积神经网络框架及实战
框架在文章的最开始部分
下面是代码
代码
这个是修改了猫狗数据集的部分内容
导包
from PIL import Image # 这行代码从Pillow库中导入了Image模块,它提供了许多用于打开、操作和保存图像的函数。
import numpy as np
from torch.utils.data import Dataset # Dataset类是torch.utils.data模块中的一个抽象类,用于表示一个数据集
from torchvision import transforms
import os # os模块提供了与操作系统交互的函数,例如读取目录内容、检查文件是否存在等。
import torch
import matplotlib.pyplot as plt
import matplotlib
#设置字体为楷体
matplotlib.rcParams['font.sans-serif'] = ['KaiTi']自定义数据集
# 自定义数据集
class mydataset(Dataset):def __init__(self,root_dir,lable_dir):self.root_dir=root_dir # 文件主路径dataset/trainself.label_dir=lable_dir # 分路径 cat 和 dogself.path=os.path.join(self.root_dir,self.label_dir) # 将文件路径的两部分连接起来self.img_path=os.listdir(self.path) # 查看self.transform = transforms.Compose([ # 包含:transforms.Resize((224,224)), # 统一大小为224*224transforms.ToTensor() # 转化为Tensor类型])def __len__(self):ilen=len(self.img_path)return ilen # 返回self.img_path列表的长度,即该数据集包含的图像数量。def __getitem__(self,item):img_name=self.img_path[item] # path路径中的第item个图像img_item_path=os.path.join(self.path,img_name) # 该图像的路径img=Image.open(img_item_path) # 打开并读取图像img=self.transform(img) # 转化为(224*224)并转化为Tensor类型if self.label_dir=="cat": # 如果是cat下的图片label=1 # label为猫狗的二分类值,因为二分类不能用文字“猫,狗”表示,所以这里我们用1来表示猫,0来表示狗else:label=0return img,label
root_dir="dataset/train"
lable_cat_dir="cat"
lable_dog_dir="dog"
cat_dataset=mydataset(root_dir,lable_cat_dir)
dog_dataset=mydataset(root_dir,lable_dog_dir)
train_dataset=cat_dataset+dog_datasettest_dir="D:\\猫狗数据集\\PetImages\\test"
cat_test=mydataset(test_dir,lable_cat_dir)
dog_test=mydataset(test_dir,lable_dog_dir)
test_dataset=cat_test+dog_test
训练模型
class CNNnetwork(torch.nn.Module):def __init__(self):super(CNNnetwork, self).__init__()self.cnn1=torch.nn.Conv2d(in_channels=3,out_channels=3,kernel_size=3)self.relu1=torch.nn.ReLU()self.pool1=torch.nn.MaxPool2d(kernel_size=2)self.linear1=torch.nn.Linear(3*111*111,2)def forward(self, x):x=self.cnn1(x)x=self.relu1(x)x=self.pool1(x)x=x.reshape(x.shape[0],-1)x = self.linear1(x)return xtrainloader=torch.utils.data.DataLoader(train_dataset,batch_size=4, shuffle=True)
testloader=torch.utils.data.DataLoader(test_dataset,batch_size=4, shuffle=True)
在这里,我们将BPnetwork修改为CNNnetwork
在init构造方法中,我们根据框架,先定义卷积层,在定义ReLu激活函数,在使用池化层,最后进行全连接。(这里只定义一层来进行简单的示例,当然,我们也可以定义多层卷积层和池化层)
框架中,最后要用到Softmax进行归一化处理,但是由于我们在下面会使用交叉熵损失函数,这一步就可以省略了
测试模型
model=CNNnetwork()
criterion = torch.nn.CrossEntropyLoss()
optimizer= torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)eopchs=25
for i in range(eopchs):sumloss=0for images, lables in trainloader:ypre=model(images)loss=criterion(ypre,lables)loss.backward()optimizer.step()optimizer.zero_grad()sumloss+=loss.item()print("Epoch {}, Loss: {}".format(i+1, sumloss/len(trainloader)))examples=enumerate(testloader)
batch,(images,lables)=next(examples)可视化
fig=plt.figure()
for i in range(4):t=torch.unsqueeze(images[i],dim=0) # 增加一个维度,使t的形状与模型期望的形状相匹配logps=model(t)probab=list(logps.detach().numpy()[0])# logps.detach()从计算图中分离出logps,确保后续的操作不会影响到模型的梯度。# 接着,.numpy()将张量转换为NumPy数组。[0]取出第一个元素(因为t是一个批次大小为1的数据),# 最后list()将这个元素转换为一个列表。此时,probab是一个包含所有类别概率的列表。pred_label=probab.index(max(probab)) # 找出probab列表中概率最大的元素的索引,这个索引即代表模型预测的类别标签。if pred_label==0:pre="狗"else:pre="猫"img=torch.squeeze(images[i]) # 移除大小为1的维度,让它回到原来的形状img1=img.permute(1, 2, 0) # 将图像的维度从(channels, height, width)调整为(height, width, channels)img1=img1.numpy()plt.subplot(2,2,i+1) # 创建一个2*2的子图网格,并选择第i+1个子图作为当前绘图区域plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域并尽量减少重叠plt.imshow(img1,cmap='gray',interpolation='none')plt.title(f"预测值:{pre}")plt.xticks([]) # 设置x轴和y轴的刻度标签为空plt.yticks([])
plt.show()如果代码有不理解的地方,可以看上面的注释,或者查询
深度学习--BP实战猫狗分类数据集-CSDN博客
这篇文章,猫狗数据集的原照片的下载网址也在里面
结果
Epoch 1, Loss: 0.8405862331390381
Epoch 2, Loss: 1.250564288534224
Epoch 3, Loss: 1.7798350632190705
Epoch 4, Loss: 0.6765258073806762
Epoch 5, Loss: 0.6690190553665161
Epoch 6, Loss: 0.6570614218711853
Epoch 7, Loss: 0.6433873891830444
Epoch 8, Loss: 0.621343731880188
Epoch 9, Loss: 0.5983625173568725
Epoch 10, Loss: 0.5741375863552094
Epoch 11, Loss: 0.5408185303211213
Epoch 12, Loss: 0.5043941497802734
Epoch 13, Loss: 0.46845043897628785
Epoch 14, Loss: 0.42693803906440736
Epoch 15, Loss: 0.3808044224977493
Epoch 16, Loss: 0.34137908518314364
Epoch 17, Loss: 0.3042459607124329
Epoch 18, Loss: 0.26810121834278106
Epoch 19, Loss: 0.23699309378862382
Epoch 20, Loss: 0.21158137172460556
Epoch 21, Loss: 0.17672300338745117
Epoch 22, Loss: 0.16740593314170837
Epoch 23, Loss: 0.13847940117120744
Epoch 24, Loss: 0.12489973902702331
Epoch 25, Loss: 0.10602239817380905

完整代码
from PIL import Image # 这行代码从Pillow库中导入了Image模块,它提供了许多用于打开、操作和保存图像的函数。
import numpy as np
from torch.utils.data import Dataset # Dataset类是torch.utils.data模块中的一个抽象类,用于表示一个数据集
from torchvision import transforms
import os # os模块提供了与操作系统交互的函数,例如读取目录内容、检查文件是否存在等。
import torch
import matplotlib.pyplot as plt
import matplotlib
#设置字体为楷体
matplotlib.rcParams['font.sans-serif'] = ['KaiTi']# 自定义数据集
class mydataset(Dataset):def __init__(self,root_dir,lable_dir):self.root_dir=root_dir # 文件主路径dataset/trainself.label_dir=lable_dir # 分路径 cat 和 dogself.path=os.path.join(self.root_dir,self.label_dir) # 将文件路径的两部分连接起来self.img_path=os.listdir(self.path) # 查看self.transform = transforms.Compose([ # 包含:transforms.Resize((224,224)), # 统一大小为224*224transforms.ToTensor() # 转化为Tensor类型])def __len__(self):ilen=len(self.img_path)return ilen # 返回self.img_path列表的长度,即该数据集包含的图像数量。def __getitem__(self,item):img_name=self.img_path[item] # path路径中的第item个图像img_item_path=os.path.join(self.path,img_name) # 该图像的路径img=Image.open(img_item_path) # 打开并读取图像img=self.transform(img) # 转化为(224*224)并转化为Tensor类型if self.label_dir=="cat": # 如果是cat下的图片label=1 # label为猫狗的二分类值,因为二分类不能用文字“猫,狗”表示,所以这里我们用1来表示猫,0来表示狗else:label=0return img,label
root_dir="dataset/train"
lable_cat_dir="cat"
lable_dog_dir="dog"
cat_dataset=mydataset(root_dir,lable_cat_dir)
dog_dataset=mydataset(root_dir,lable_dog_dir)
train_dataset=cat_dataset+dog_datasettest_dir="D:\\猫狗数据集\\PetImages\\test"
cat_test=mydataset(test_dir,lable_cat_dir)
dog_test=mydataset(test_dir,lable_dog_dir)
test_dataset=cat_test+dog_testclass CNNnetwork(torch.nn.Module):def __init__(self):super(CNNnetwork, self).__init__()self.cnn1=torch.nn.Conv2d(in_channels=3,out_channels=3,kernel_size=3)self.relu1=torch.nn.ReLU()self.pool1=torch.nn.MaxPool2d(kernel_size=2)self.linear1=torch.nn.Linear(3*111*111,2)def forward(self, x):x=self.cnn1(x)x=self.relu1(x)x=self.pool1(x)x=x.reshape(x.shape[0],-1)x = self.linear1(x)return xtrainloader=torch.utils.data.DataLoader(train_dataset,batch_size=4, shuffle=True)
testloader=torch.utils.data.DataLoader(test_dataset,batch_size=4, shuffle=True)model=CNNnetwork()
criterion = torch.nn.CrossEntropyLoss()
optimizer= torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)eopchs=25
for i in range(eopchs):sumloss=0for images, lables in trainloader:ypre=model(images)loss=criterion(ypre,lables)loss.backward()optimizer.step()optimizer.zero_grad()sumloss+=loss.item()print("Epoch {}, Loss: {}".format(i+1, sumloss/len(trainloader)))examples=enumerate(testloader)
batch,(images,lables)=next(examples)fig=plt.figure()
for i in range(4):t=torch.unsqueeze(images[i],dim=0) # 增加一个维度,使t的形状与模型期望的形状相匹配logps=model(t)probab=list(logps.detach().numpy()[0])# logps.detach()从计算图中分离出logps,确保后续的操作不会影响到模型的梯度。# 接着,.numpy()将张量转换为NumPy数组。[0]取出第一个元素(因为t是一个批次大小为1的数据),# 最后list()将这个元素转换为一个列表。此时,probab是一个包含所有类别概率的列表。pred_label=probab.index(max(probab)) # 找出probab列表中概率最大的元素的索引,这个索引即代表模型预测的类别标签。if pred_label==0:pre="狗"else:pre="猫"img=torch.squeeze(images[i]) # 移除大小为1的维度,让它回到原来的形状img1=img.permute(1, 2, 0) # 将图像的维度从(channels, height, width)调整为(height, width, channels)img1=img1.numpy()plt.subplot(2,2,i+1) # 创建一个2*2的子图网格,并选择第i+1个子图作为当前绘图区域plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域并尽量减少重叠plt.imshow(img1,cmap='gray',interpolation='none')plt.title(f"预测值:{pre}")plt.xticks([]) # 设置x轴和y轴的刻度标签为空plt.yticks([])
plt.show()
后面会发布另外两个卷积神经网络实战:VGG16和ResNet18 的原理和代码