文章目录
一、基本概念
SQL分类
- 数据库:database
- 表:table,行:row 列:column
- 索引:index
- 视图:view
- 存储过程:procedure
- 存储函数:function
- 触发器:trigger
- 事件调度器:event scheduler,任务计划
- 用户:user
- 权限:privilege
SQL语言规范
- 在数据库系统中,SQL 语句不区分大小写,建议用大写
- SQL语句可单行或多行书写,默认以 " ; " 结尾
- 关键词不能跨多行或简写 select drop create
- 用空格和TAB 缩进来提高语句的可读性
- 子句通常位于独立行,便于编辑,提高可读性
数据库对象和命名
数据库的组件(对象):
数据库、表、索引、视图、用户、存储过程、函数、触发器、事件调度器等
命名规则:
1.必须以字母开头,后续可以包括字母,数字和三个特殊字符(# _ $)
2.不要使用MySQL的保留字,table select show databases
SQL语句分类
- DDL: Data Defination Language 数据定义语言 CREATE,DROP,ALTER
- ML: Data Manipulation Language 数据操纵语言
INSERT,DELETE,UPDATE - DQL:Data Query Language 数据查询语言
SELECT - DCL:Data Control Language 数据控制语言 GRANT,REVOKE
- TCL:Transaction Control Language 事务控制语言
COMMIT,ROLLBACK,SAVEPOINT
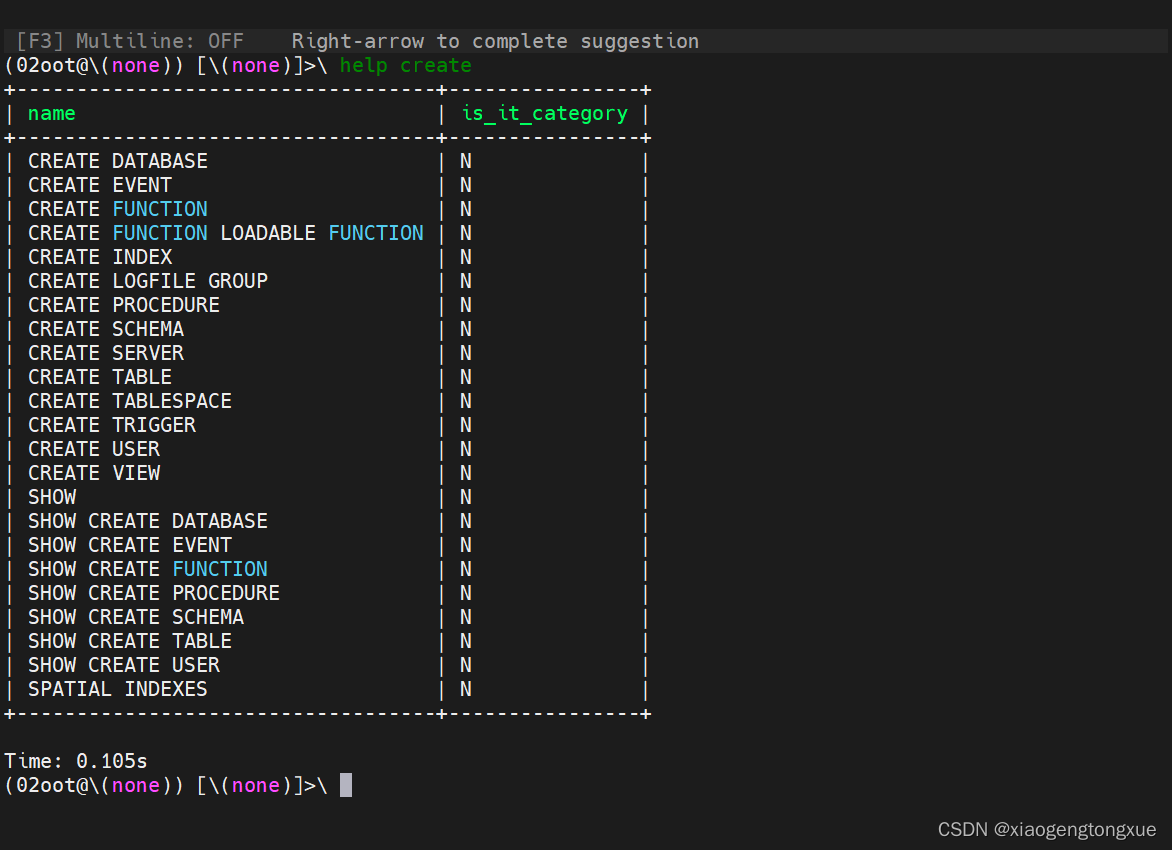
查看帮助信息
help create #help后面跟上具体命令可以查看帮助
查看支持的字符集
show character set
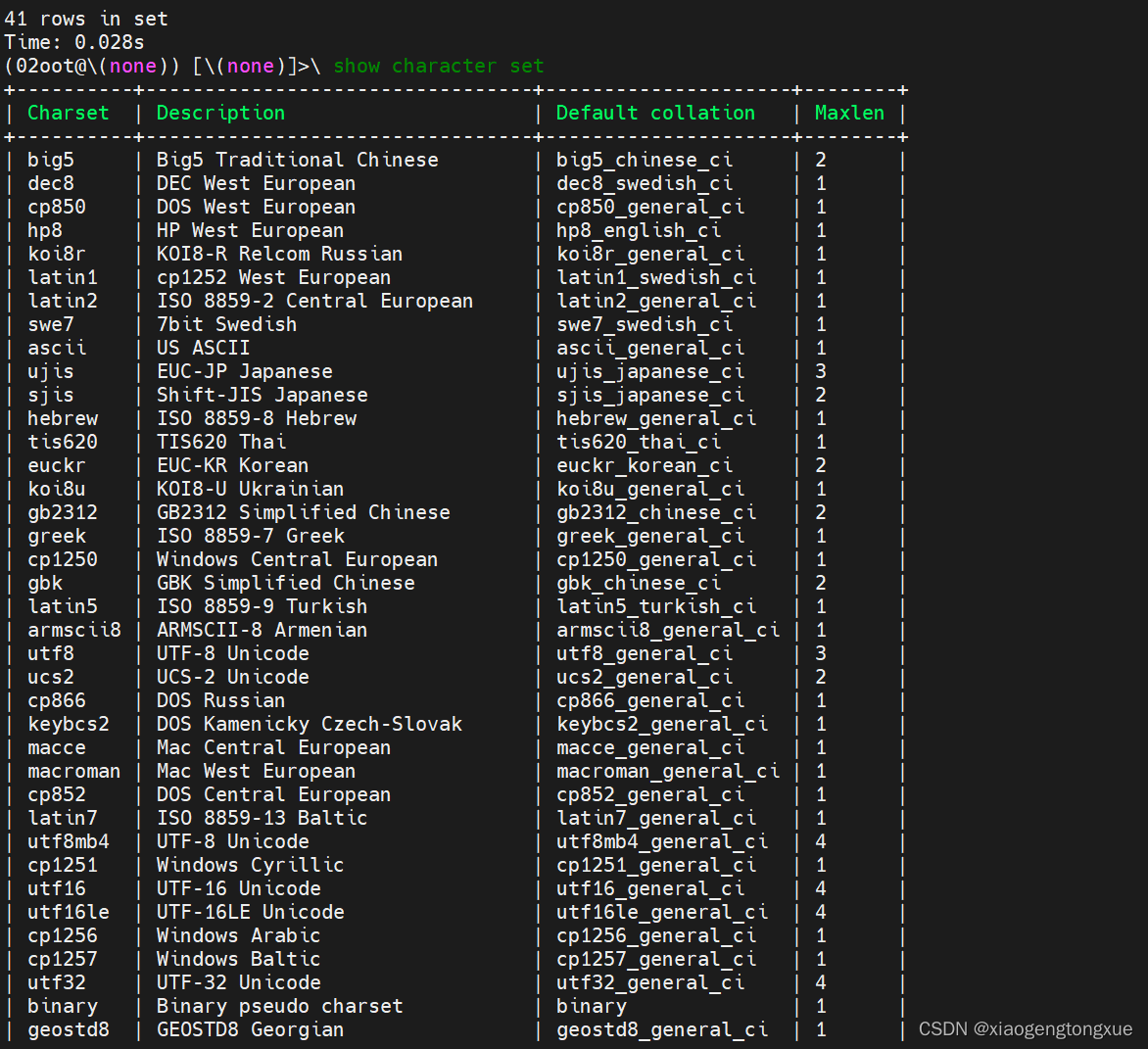
注意: 默认支持拉丁文,这样的数据库我们是肯定看不懂的,所以我们需要使用中文字符集,utf8 | UTF-8 Unicode (阉割版),utf8 | UTF-8 Unicode (真实的版本)。
查看默认使用的字符集
show variables like 'char%';
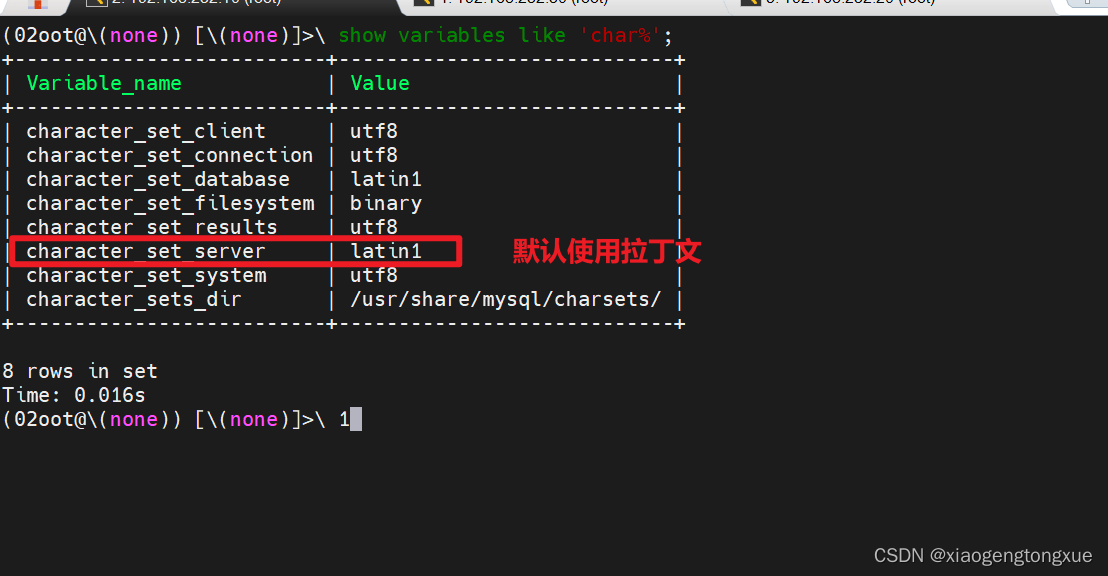
新建数据库默认的字符集是拉丁文。
create database test;
show create database test;
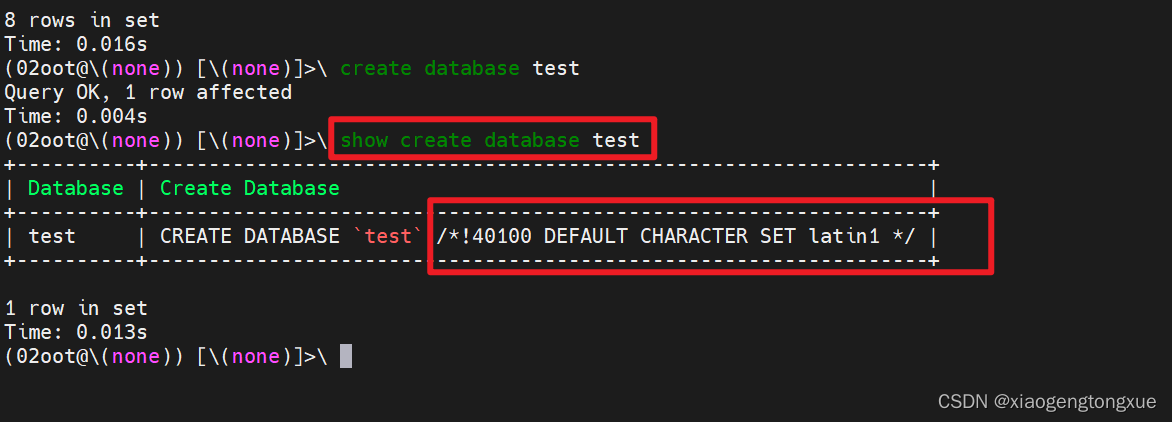
修改默认字符集
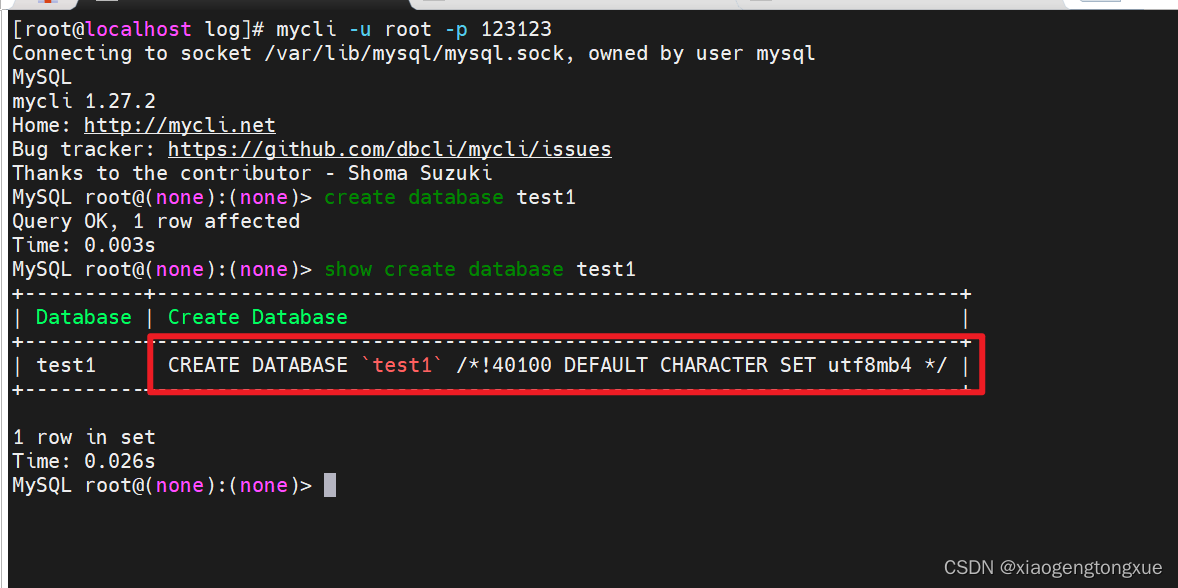
修改字符集
vim /etc/my.cnf
[mysqld]
character-set-server=utf8mb4
二、管理数据库
新建数据库
新建数据库,指定字符集。
create database db1;
建立数据库 db1
show create dadabase db1;
查看数据库的基本信息。
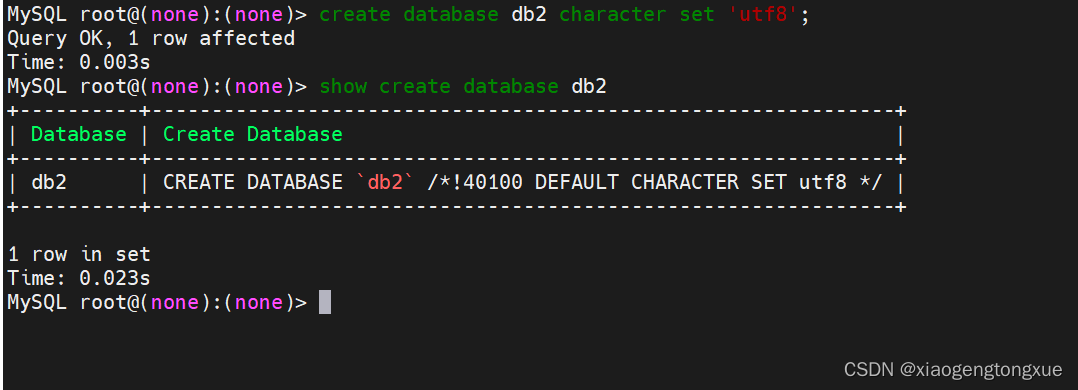
create database db2 character set 'utf8';
create database db2 charset=utf8;
指定utf8字符集
mysql> create database zabbix character set utf8 collate utf8_bin;
指定了数据库的排序规则(collation)为 utf8_bin。排序规则决定了数据库如何对字符串进行排序和比较。utf8_bin 是一种区分大小写的排序规则。
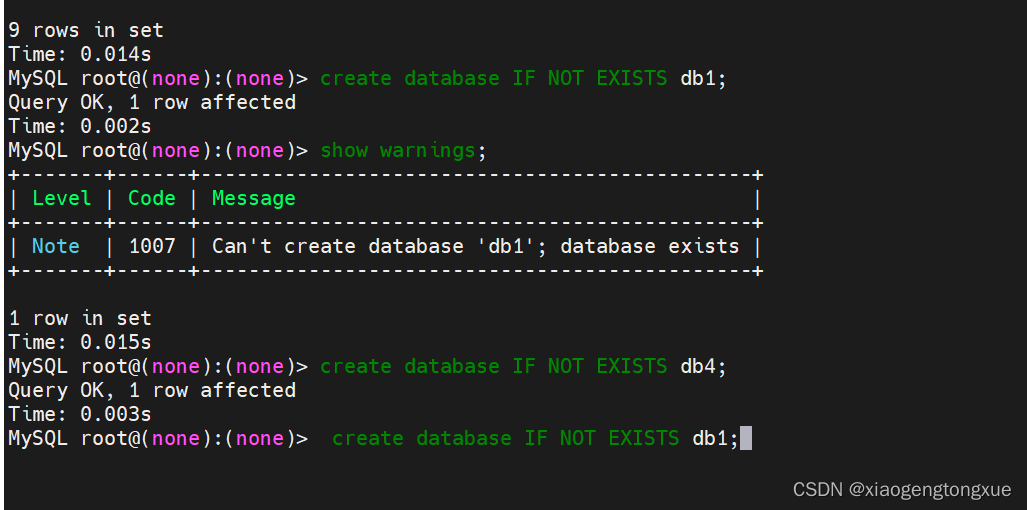
if no exists 先判断数据库是否存在。
create database IF NOT EXISTS db1;
如果数据库 db1 不存在,则创建新的数据库 db1。
如果数据库 db1 已经存在,则忽略这条语句,不会报错。
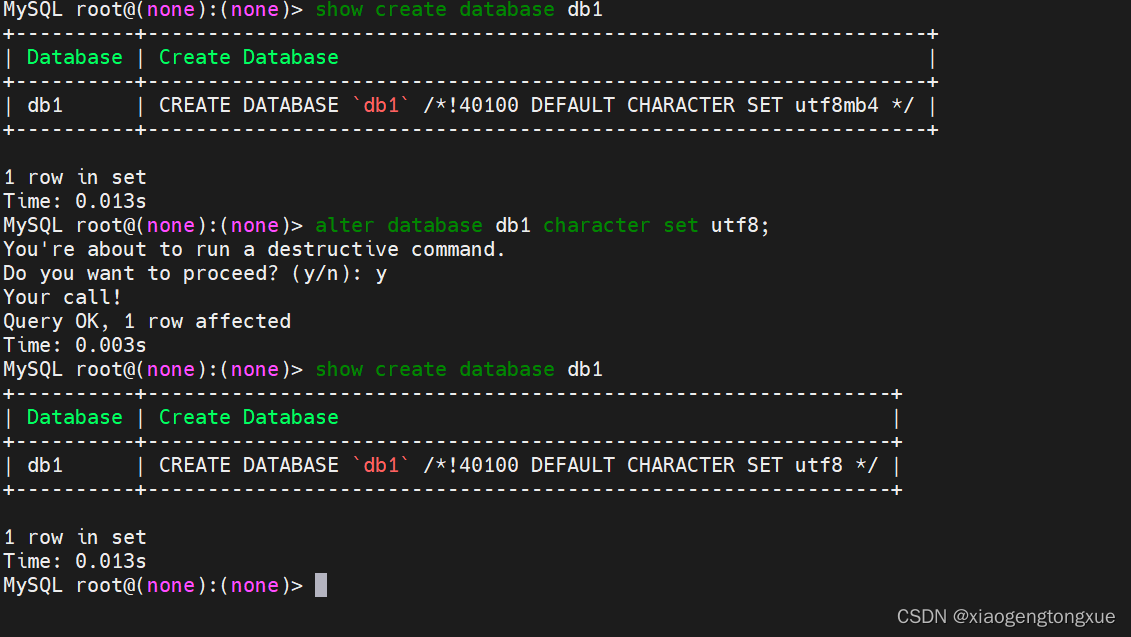
修改数据库
修改字符集
ALTER DATABASE db1 character set utf8;
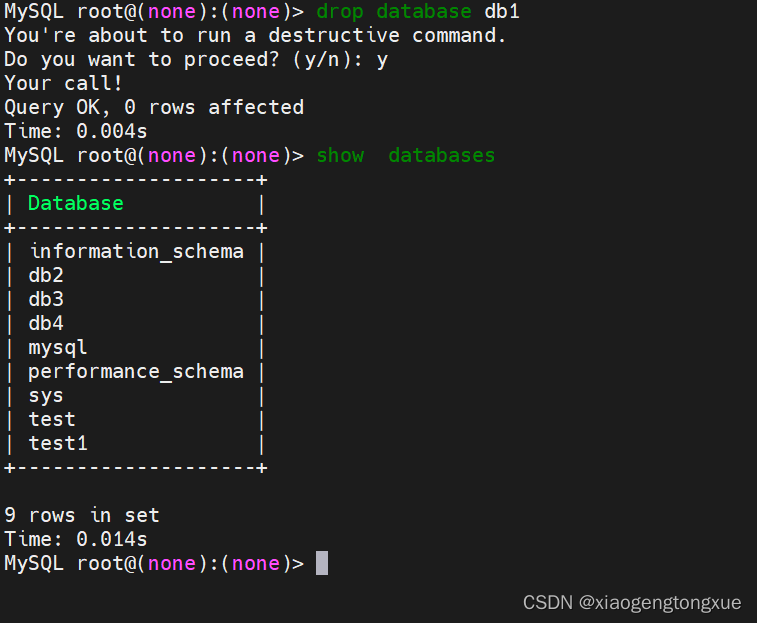
删除数据库

语法
DROP DATABASE|SCHEMA [IF EXISTS] 'DB_NAME';
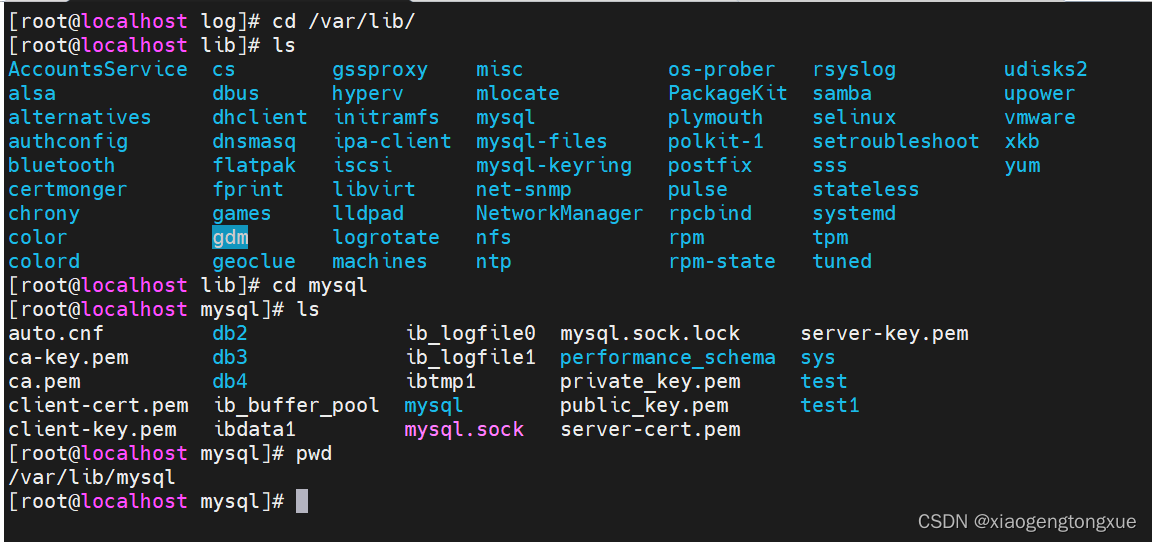
有时数据库比较大,删除起来比较麻烦,还有个手段。
数据库其实就是个文件夹,删除文件夹数据库内的内容就没有了。
查看数据库列表
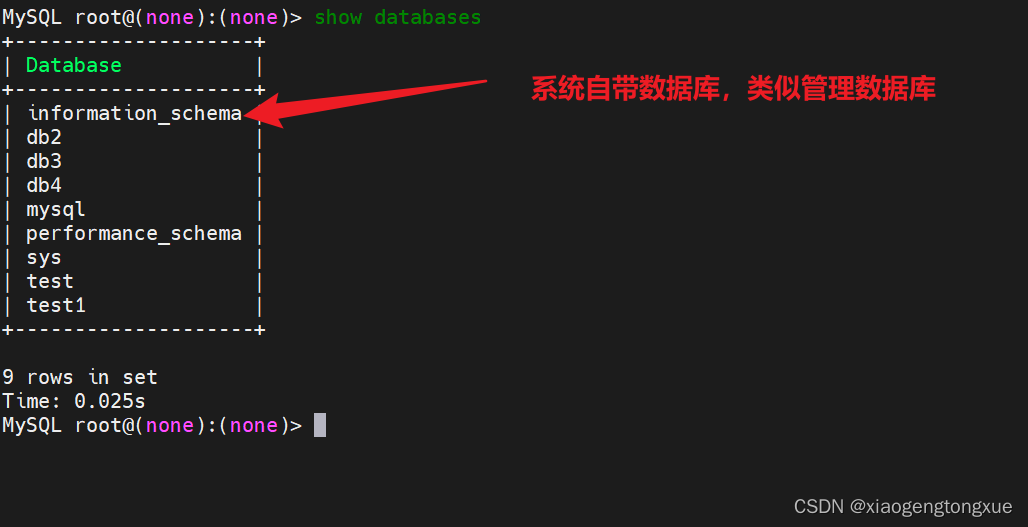
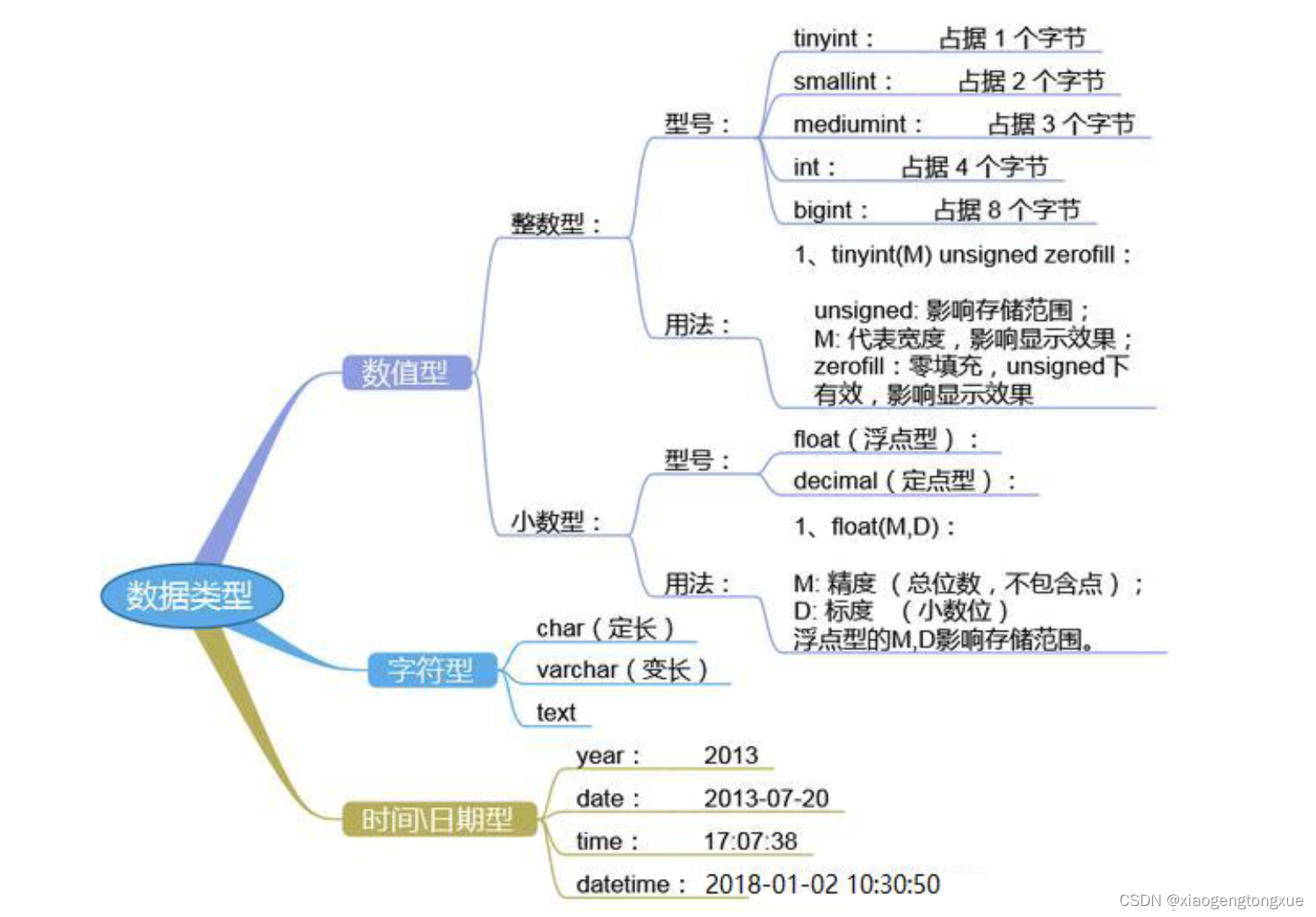
数据类型
数据类型
- 数据长什么样
- 数据需要多少空间来存放
数据类型
- 系统内置数据类型
- 用户定义数据类型
MySQL支持多种内置数据类型
- 数值类型
- 日期/时间类型 yy-mm-dd
- 字符串(字符)类型
https://dev.mysql.com/doc/refman/8.0/en/data-types.html
数据类型参考链接
选择正确的数据类型对于获得高性能至关重要
- 更小的通常更好,尽量使用可正确存储数据的最小数据类型。
- 简单就好,简单数据类型的操作通常需要更少的CPU周期。
- 尽量避免NULL,包含为NULL的列,对MySQL更难优化。
整数型
-
tinyint(m) 1个字节 范围(-128~127)
-
smallint(m) 2个字节 范围(-32768~32767)
-
mediumint(m) 3个字节 范围(-8388608~8388607)
-
int(m) 4个字节 范围(-2147483648~2147483647)(常用)
-
bigint(m) 8个字节 范围(±9.22*10的18次方)
注意:
1.有一个正或负的表示符
2.如果加修饰符unsigned后,则最大值翻倍,表示无符号位。例如:tinyint unsigned的取值范围为(0~255)
浮点型(float和double),近似值
- float(m,d) 单精度浮点型 8位精度(4字节) m总个数,d小数位, 注意: 小数点不占用总个数。
- double(m,d) 双精度浮点型16位精度(8字节) m总个数,d小数位, 注意: 小数点不占用总个数。
例子:设一个字段定义为float(6,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位。
定点数
在数据库中存放的是精确值,存为十进制。
格式 decimal(m,d) 表示 最多 m 位数字,其中 d 个小数,小数点不算在长度内。
比如: DECIMAL(6,2) 总共能存6位数字,末尾2位是小数,字段最大值 9999.99 (小数点不算在长度内)
字符串
- char(n) 固定长度,最多255个字符,注意不是字节。 如果超过限制 1是不让你录入。2是将多余部分截断。
- varchar(n) 可变长度,最多65535个字符。
- tinytext 可变长度,最多255个字符。
- text 可变长度,最多65535个字符。
- mediumtext 可变长度,最多2的24次方-1个字符
- longtext 可变长度,最多2的32次方-1个字符
- BINARY(M) 固定长度,可存二进制或字符,长度为0-M字节
- VARBINARY(M) 可变长度,可存二进制或字符,允许长度为0-M字节
- 内建类型:ENUM枚举, SET集合
注意:M是自定义的。
char和varchar的比较:
1.char(n) 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉,所以char类型存储的字符串末尾不能有空格,varchar不限于此。
2.char(n) 固定长度,char(4)不管是存入几个字符,都将占用4个字节,varchar是存入的实际字符数+1个字节,所以varchar(4),存入3个字符将占用4个字节。
3.char类型的字符串检索速度要比varchar类型的快。因为char的长度是固定的。
问题
varchar(50) 能存放几个 UTF8 编码的汉字?
答:mysql 5.0以上版本 varchar(50) 指的是50字符,无论存放的是数字、字母还是 utf8 编码的汉字,都可以存放50个。
修饰符
适用所有类型的修饰符:
| 名称 | 含义 |
|---|---|
| NULL | 数据列可包含NULL值,默认值 |
| NOT NULL | 数据列不允许包含NULL值,*为必填选项 |
| DEFAULT | 默认值 |
| PRIMARY KEY | 主键,所有记录中此字段的值不能重复,且不能为NULL 一张表中只有一个主键 |
| UNIQUE KEY | 唯一键,所有记录中此字段的值不能重复,但可以为NULL |
| CHARACTER SET | name 指定一个字符集 |
适用数值型的修饰符:
| 名称 | 作用 |
|---|---|
| AUTO_INCREMENT | 自动递增,适用于整数类型 |
| UNSIGNED | 无符号 |
表操作
help create table
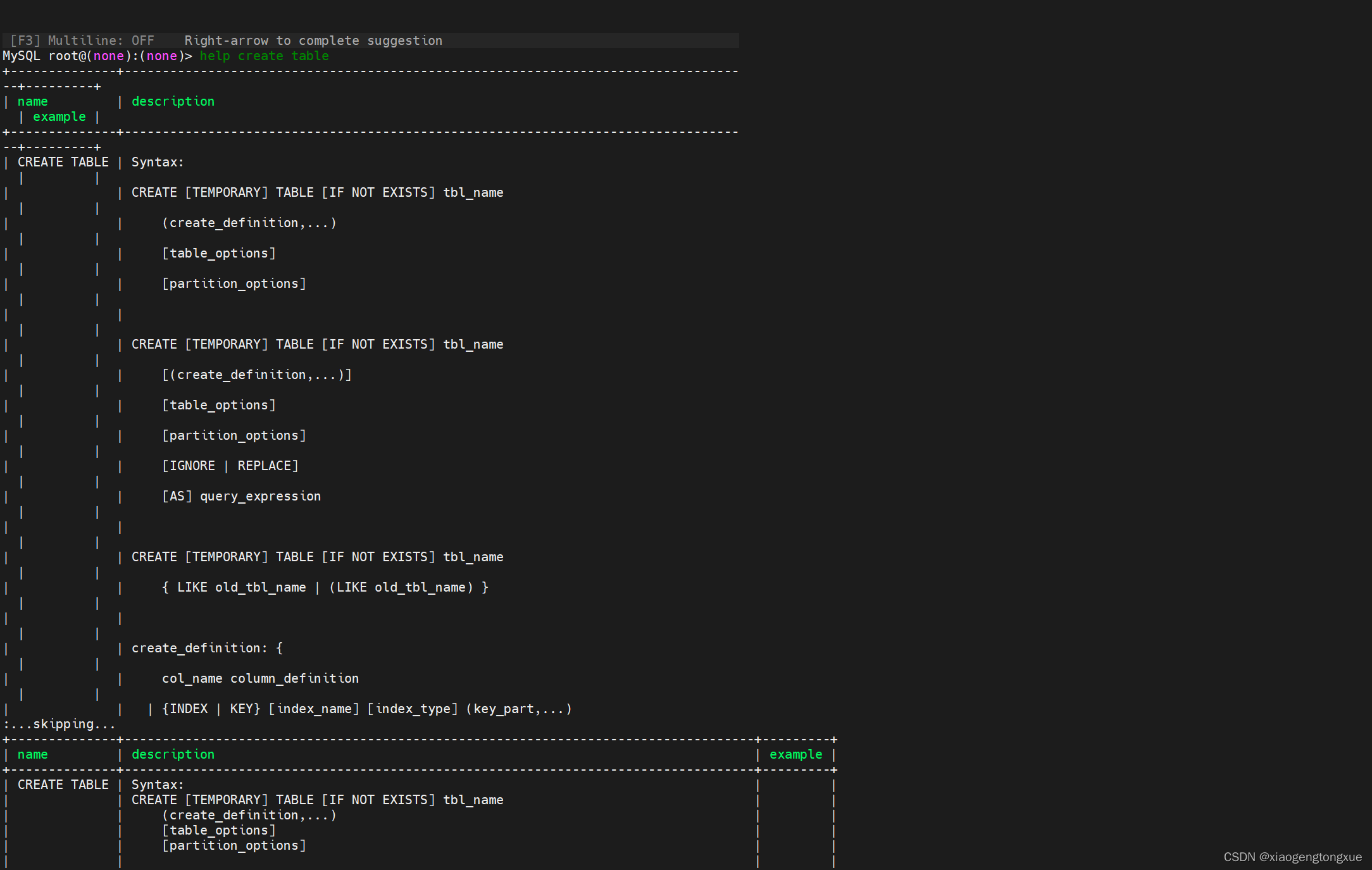
查看数据库结构
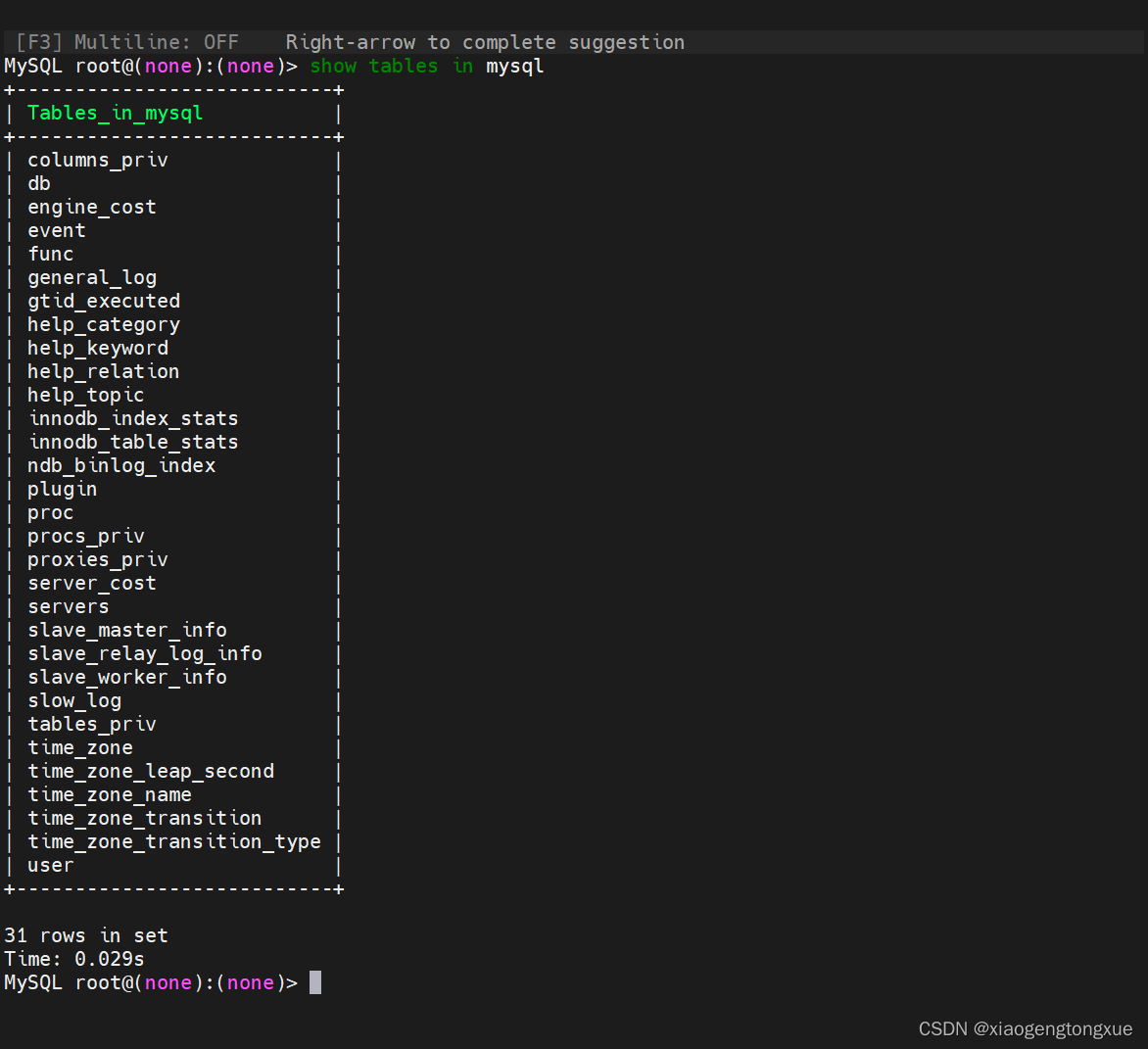
查看数据库
show create database db1;
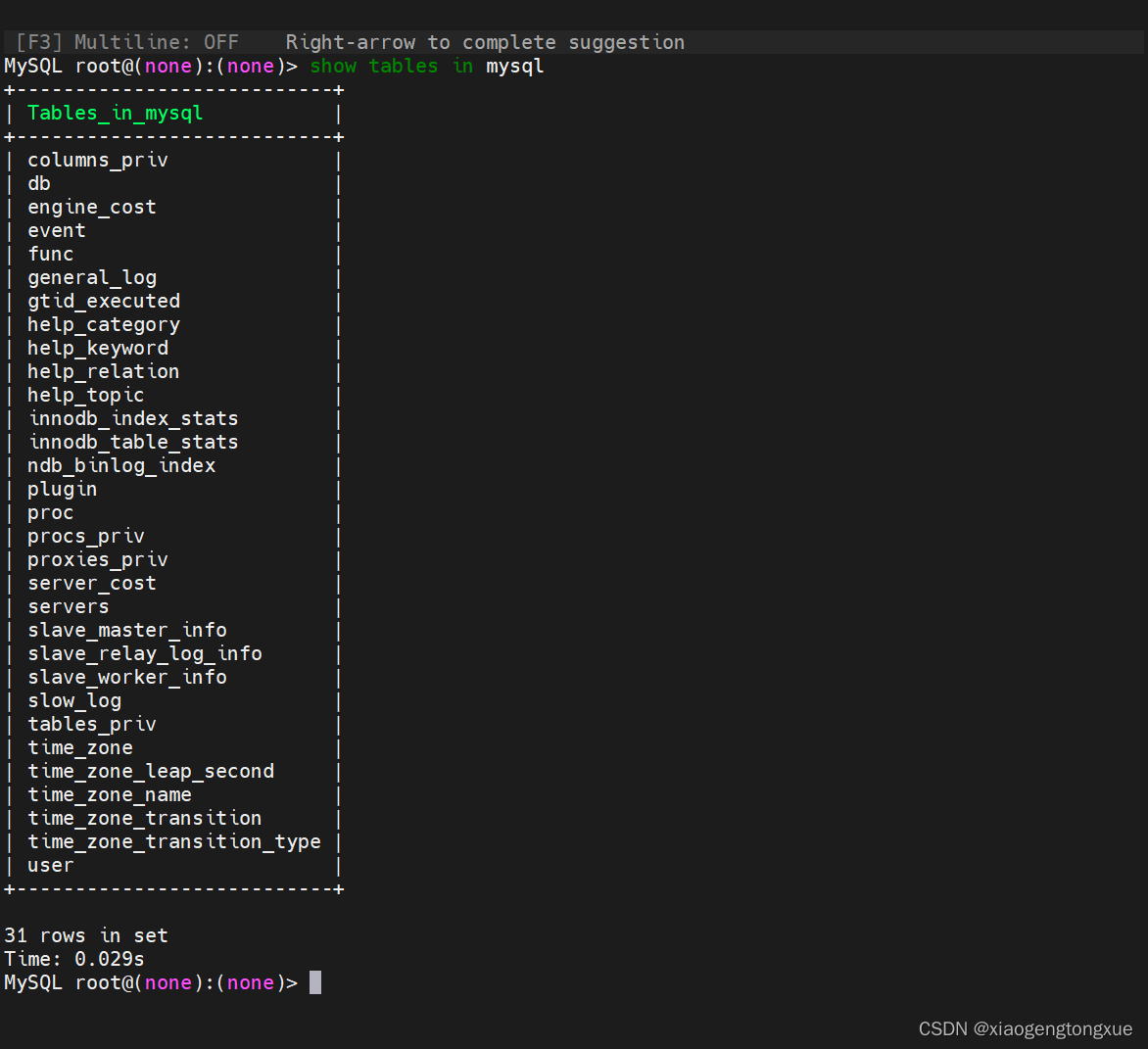
show tables in mysql;
选择数据库,看数据库当中的表格。
查看表结构,即字段。
格式:describe 数据库名.表名
describe mysql.db
新建表
格式
create table 表名 (字段1 数据类型,字段2 数据类型[,…] [,PRIMARY KEY (主键名)]);
主键一般选择唯一字段不允许为空值(null),且一个表只能有一个主键。
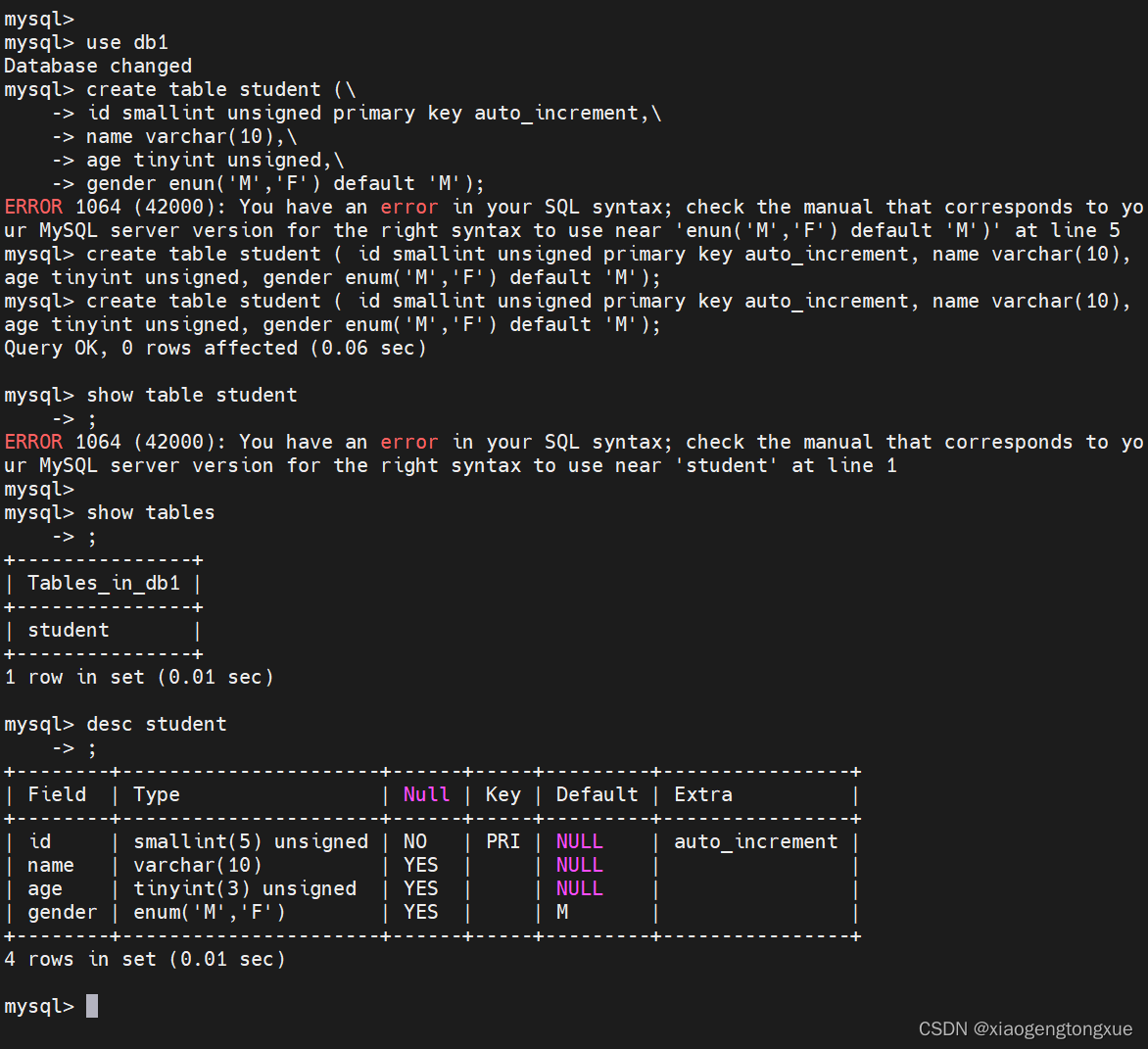
create table student (\-> id smallint unsigned primary key auto_increment,\-> name varchar(10),\-> age tinyint unsigned,\-> gender enun('M','F') default 'M');
代码含义
新建表格student 字段1是id 采用无符号smallint储存数据,设置为主键,且为自增长;字段2是名字,可变长字符串;字段3是年龄;字段4是性别,是选择字段,默认为M。
加入数据
加入空字段
insert student values();
加入数据
insert student (name,age,gender) values ('cxk',33,'M');
注意加入的数据和字段需要一一对应。
如果你觉得麻烦,需要按照字段的顺序把数据一一录入进去才行。
insert student values ('3','cxk',33,'M');
查找表格
select * from student;
修改表结构
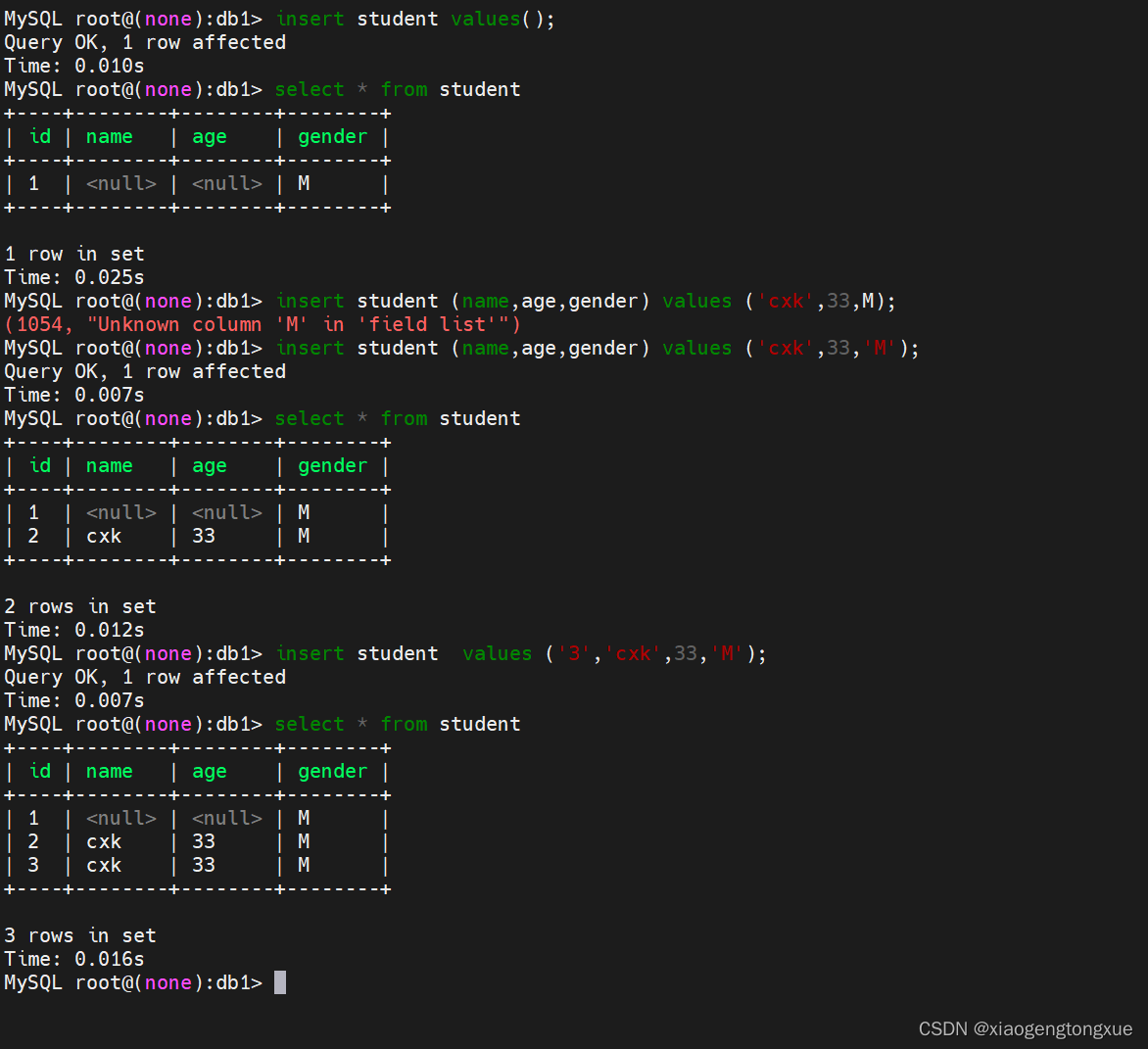
alter 添加字段
alter table student add phone char(11) not null ;
命令字 表名 关键字 字段名称 字段属性
添加新的phone字段到student中,但一般不会用,一张表用来存数据,如果刚开始没有确定好字段,就存入数据,后面又加字段,前面存在的数据就会少这个字段,所以一般不会用。

change 修改字段名称
alter table student change phone mobile char)(11);
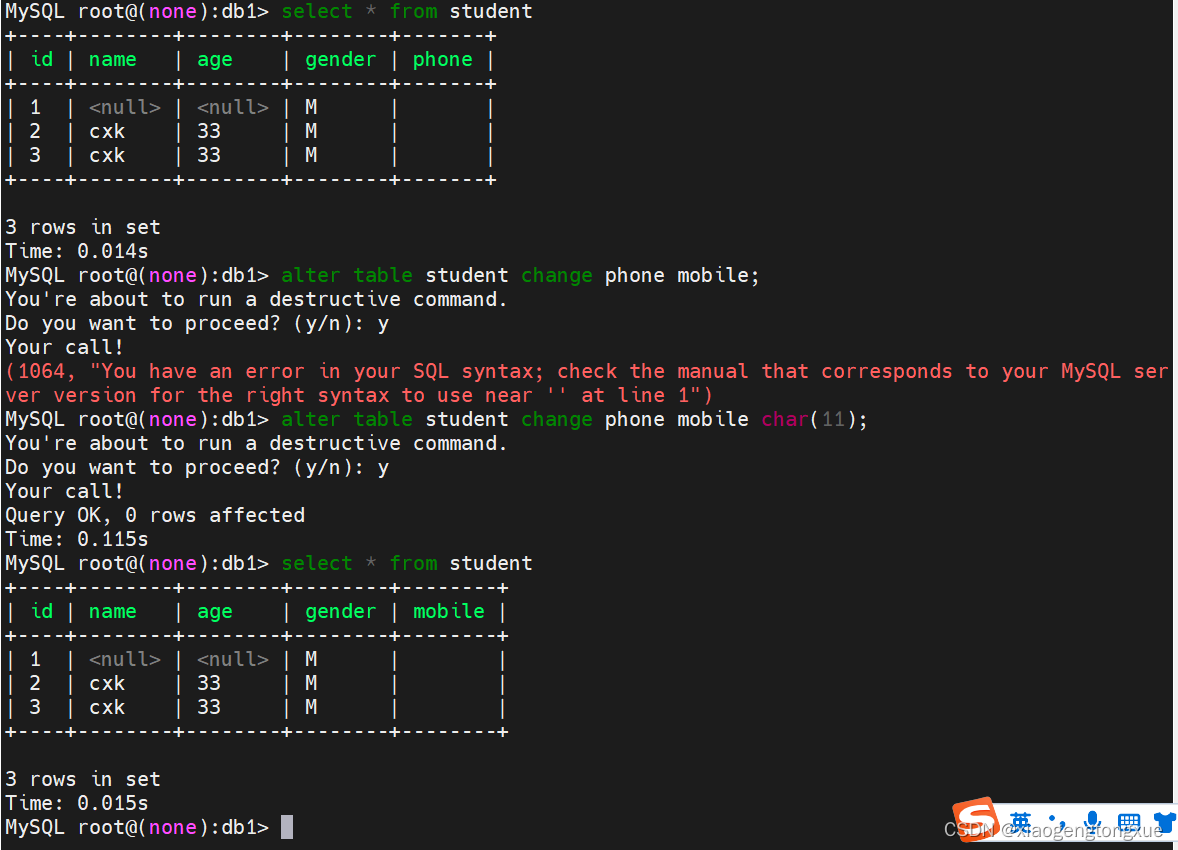
drop 删除字段
alter table student drop mobile;
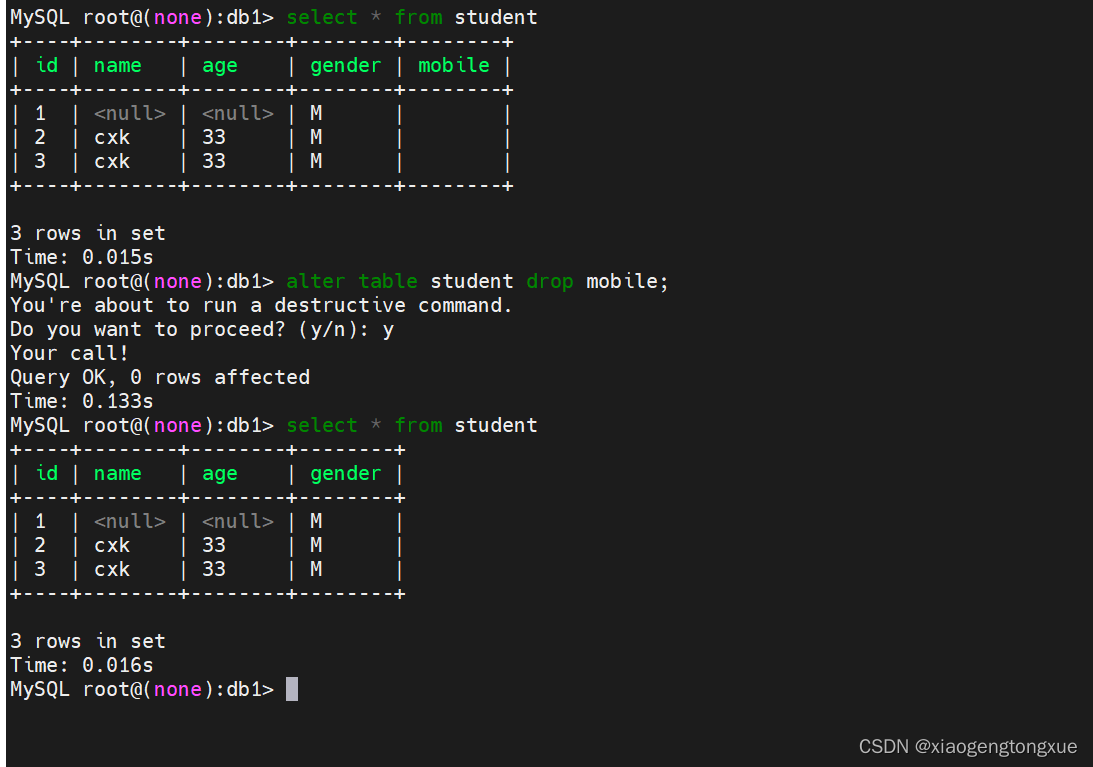
其他例子
ALTER TABLE students RENAME s1;
将表名从students改为是s1;
ALTER TABLE s1 ADD phone varchar(11) AFTER name;
在表 s1 中添加了一个名为 phone 的列,数据类型是 varchar(11),位置在 name 列之后。
ALTER TABLE s1 MODIFY phone int;
将表 s1 中 phone 列的数据类型从 varchar(11) 修改为 int。
ALTER TABLE s1 CHANGE COLUMN phone mobile char(11);
将表 s1 中 phone 列改名为 mobile,数据类型改为 char(11)。
ALTER TABLE s1 DROP COLUMN mobile;
从表 s1 中删除 mobile 列。
ALTER TABLE s1 character set utf8;
将表 s1 的字符集设置为 utf8。
ALTER TABLE s1 change name name varchar(20) character set utf8;
将表 s1 中 name 列的长度改为 20,并将字符集设置为 utf8。
ALTER TABLE students ADD gender ENUM('m','f');
在表 students 中添加了一个名为 gender 的列,数据类型是 ENUM('m','f')。
ALETR TABLE students CHANGE id sid int UNSIGNED NOT NULL PRIMARY KEY;
将表 students 中的 id 列改名为 sid,数据类型改为 int UNSIGNED NOT NULL,并设置为主键
ALTER TABLE students DROP age;
从表 students 中删除 age 列。
CREATE TABLE t1 SELECT * FROM students;
创建了一个新表 t1,并将 students 表中的所有数据复制到 t1 中。
ALTER TABLE t1 add primary key (stuid);
在表 t1 中添加了一个主键列 stuid。
ALTER TABLE t1 drop primary key
删除表 t1 中的主键约束。
DML语言 data manger language
DML: INSERT, DELETE, UPDATE
INSTER语句
功能:一次性插入一行或多行数据
INSERT tbl_name [(col1,...)] VALUES (val1,...), (val21,...)
insert 表名[(字段)] 值(值1,值2....),(值1,值2)......;
使用 insert 语句时 如果不在表后加上字段就要一一对应填写上信息(注意 字符串用引号引起来),也可以指定添加的字段。
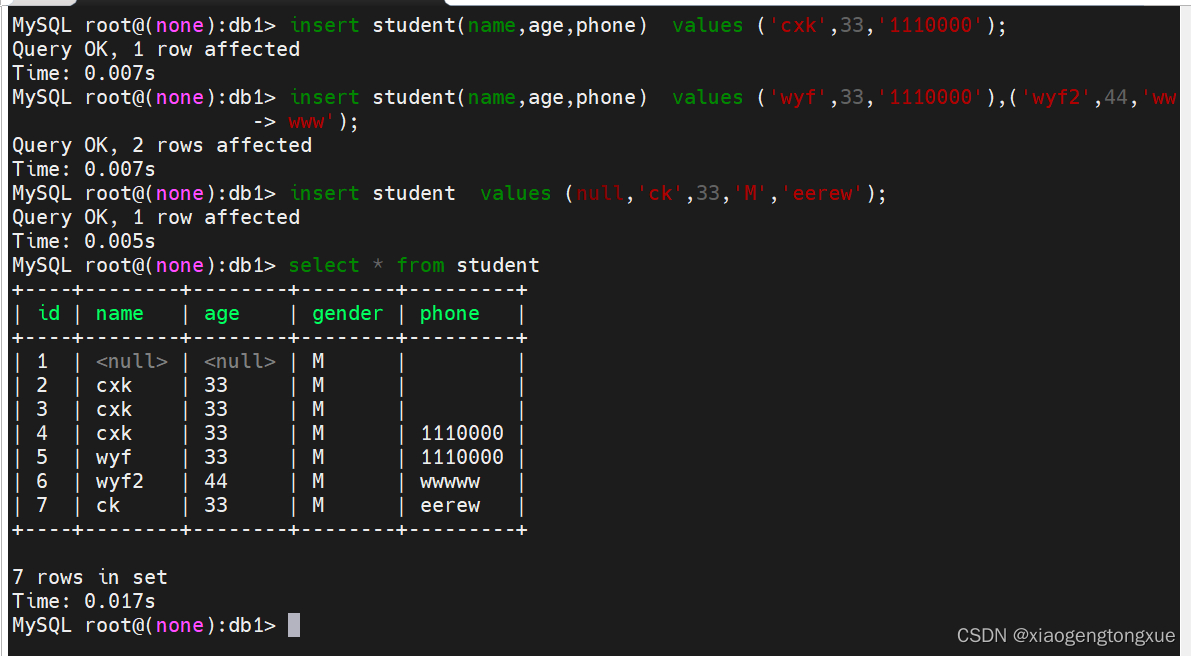
insert student(name,age,phone) values ('cxk',33,'1110000');
添加一条记录
insert student(name,age,phone) values ('wyf',33,'1110000'),('wyf2',44,'wwwww');
用逗号隔添加多条记录
nsert student values( null,'ck',33,'M','eerew');
不指明添加字段,编号字段又自增长可以使用空
UPDATE语句
UPDATE [LOW_PRIORITY] [IGNORE] table_referenceSET col_name1={expr1|DEFAULT} [, col_name2={expr2|DEFAULT}] ...[WHERE where_condition][ORDER BY ...][LIMIT row_count]
update 表名 set 字段=修改的值 指定哪条记录;注意:一定要有限制条件,否则默认修改所有行的指定字段。
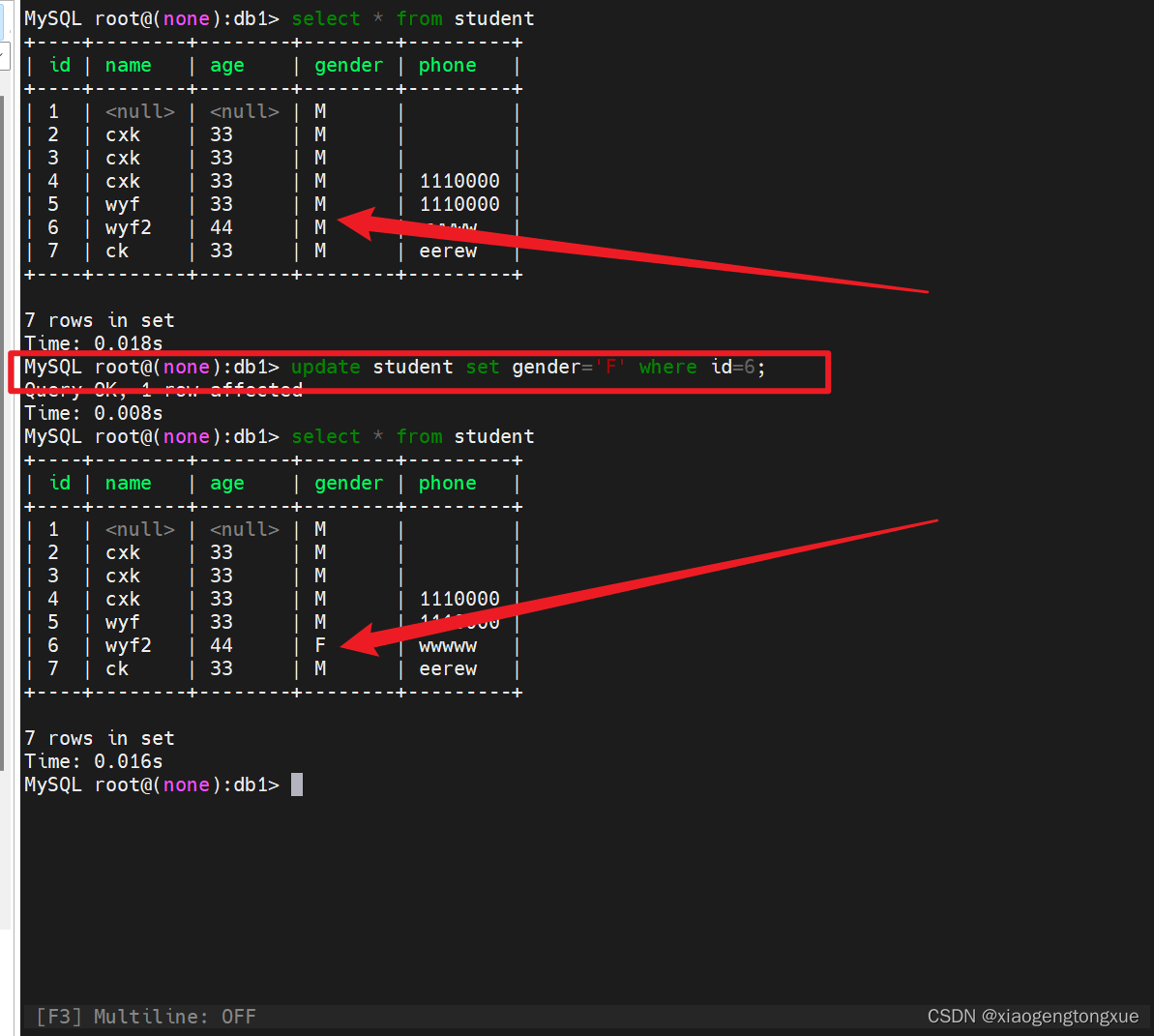
update student set gender='F' where id=6;
修改id为6的行的gender字段为F。
DELETE语句
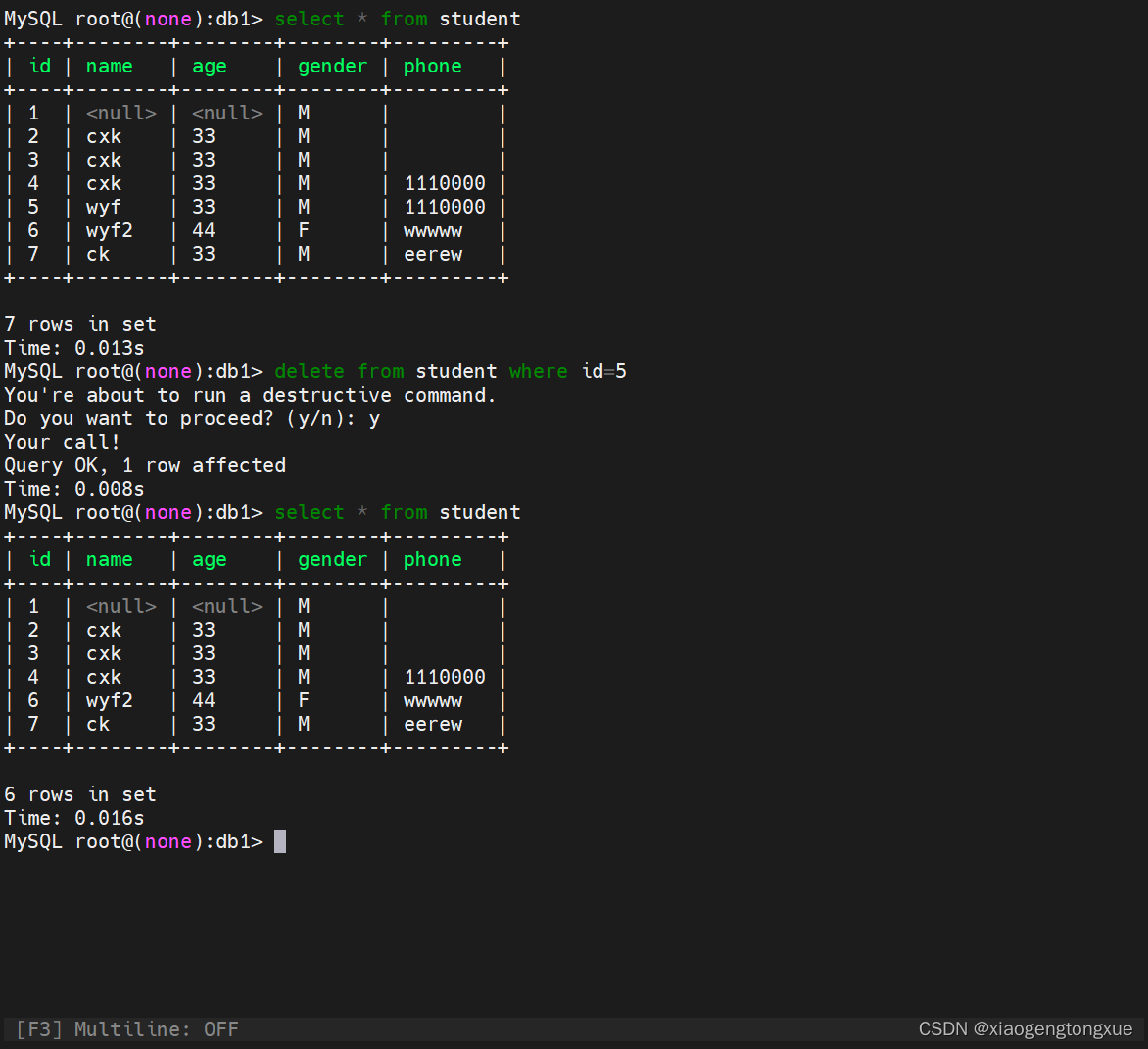
删除表中数据,但不会自动缩减数据文件的大小。
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name[WHERE where_condition][ORDER BY ...][LIMIT row_count]可先排序再指定删除的行数#解释:delete from 表名 指定条件
注意:一定要有限制条件,否则将清空表中所有的数据。
如果想清空表,保留表结构,也可以使用下面语句,此语句会自动缩减数据文件的大小。
TRUNCATE TABLE table_name;
注意:
TRUNCATE TABLE 会从根本上删除表中的所有数据,并释放表占用的数据空间,从而缩小数据文件的大小。
DELETE FROM 只是逻辑上删除表中的数据,但是实际占用的物理空间不会立即被释放。
DQL语句 单表查询
SELECT[ALL | DISTINCT | DISTINCTROW ][SQL_CACHE | SQL_NO_CACHE]select_expr [, select_expr ...][FROM table_references[WHERE where_condition][GROUP BY {col_name | expr | position}[ASC | DESC], ... [WITH ROLLUP]][HAVING where_condition][ORDER BY {col_name | expr | position}[ASC | DESC], ...][LIMIT {[offset,] row_count | row_count OFFSET offset}][FOR UPDATE | LOCK IN SHARE MODE]
SELECT 显示表格中一个或者数个字段的所有数据记录
语法使用:
select 字段 from 表名;
字段可以用*表示 代表所有,也可以挑选出自己想要的。
select * from 表名;

where 过滤查询
语法:
SELECT "字段" FROM "表名" WHERE "条件";
说明:
- 过滤条件:布尔型表达式
- 算术操作符:+, -, *, /, %
- 比较操作符:=,<=>(相等或都为空), <>, !=(非标准SQL), >, >=, <, <=
- 范例查询: BETWEEN min_num AND max_num
- 不连续的查询: IN (element1, element2, …)
- 空查询: IS NULL, IS NOT NULL
- 字段显示可以使用别名
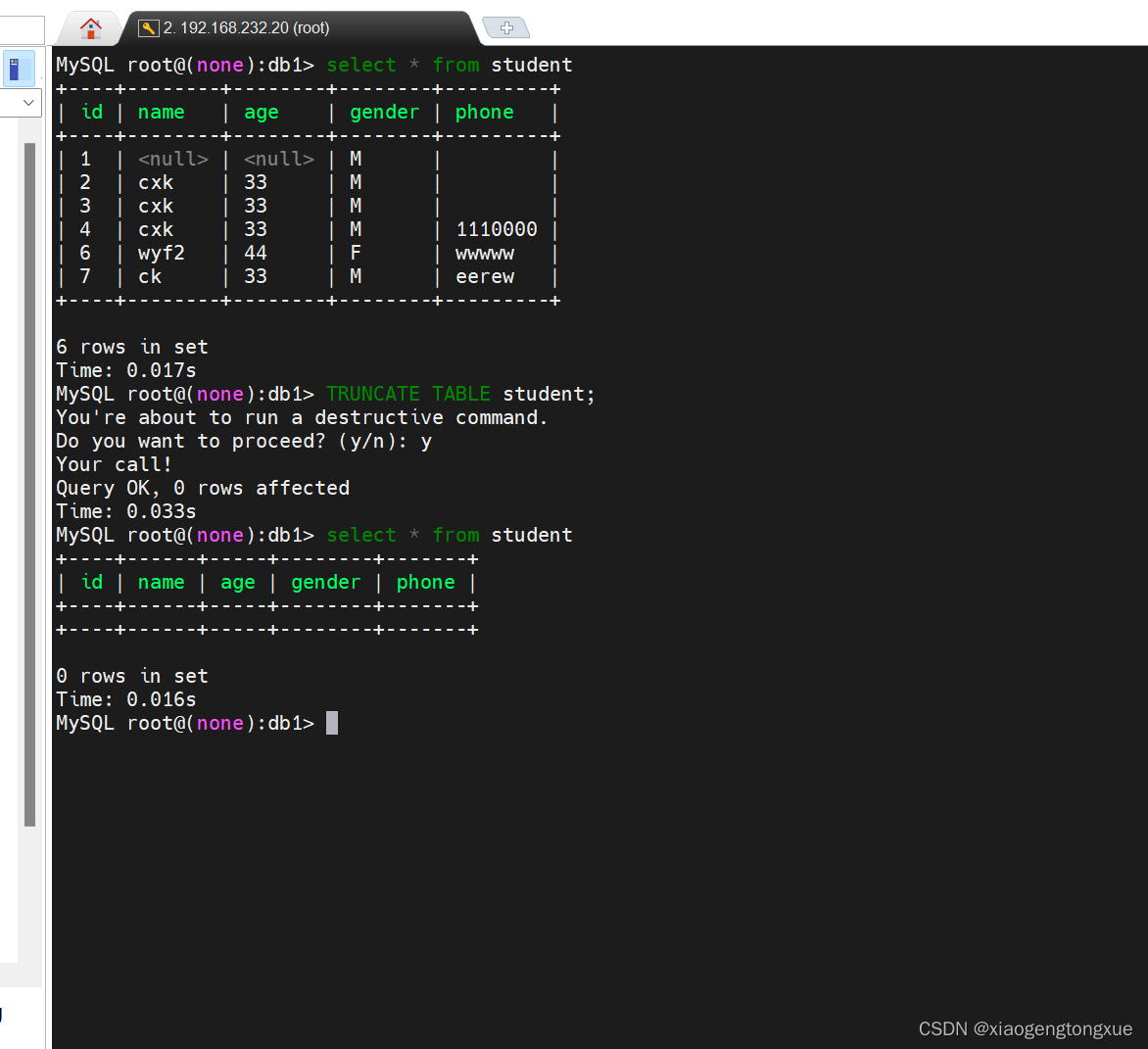
select * from students where name="xi ren"
找出姓名是xiren的数据
select * from students where age >=20 and age<=30;
找出年龄在20岁到30岁
select * from students where age between 20 and 30; 另一种写法
select * from students where age in (20,22,30);查询年龄是20,22,30岁的人
select age 年龄,classid 班级 from students;
字段使用别名
** AND OR (且 或)**
语法:
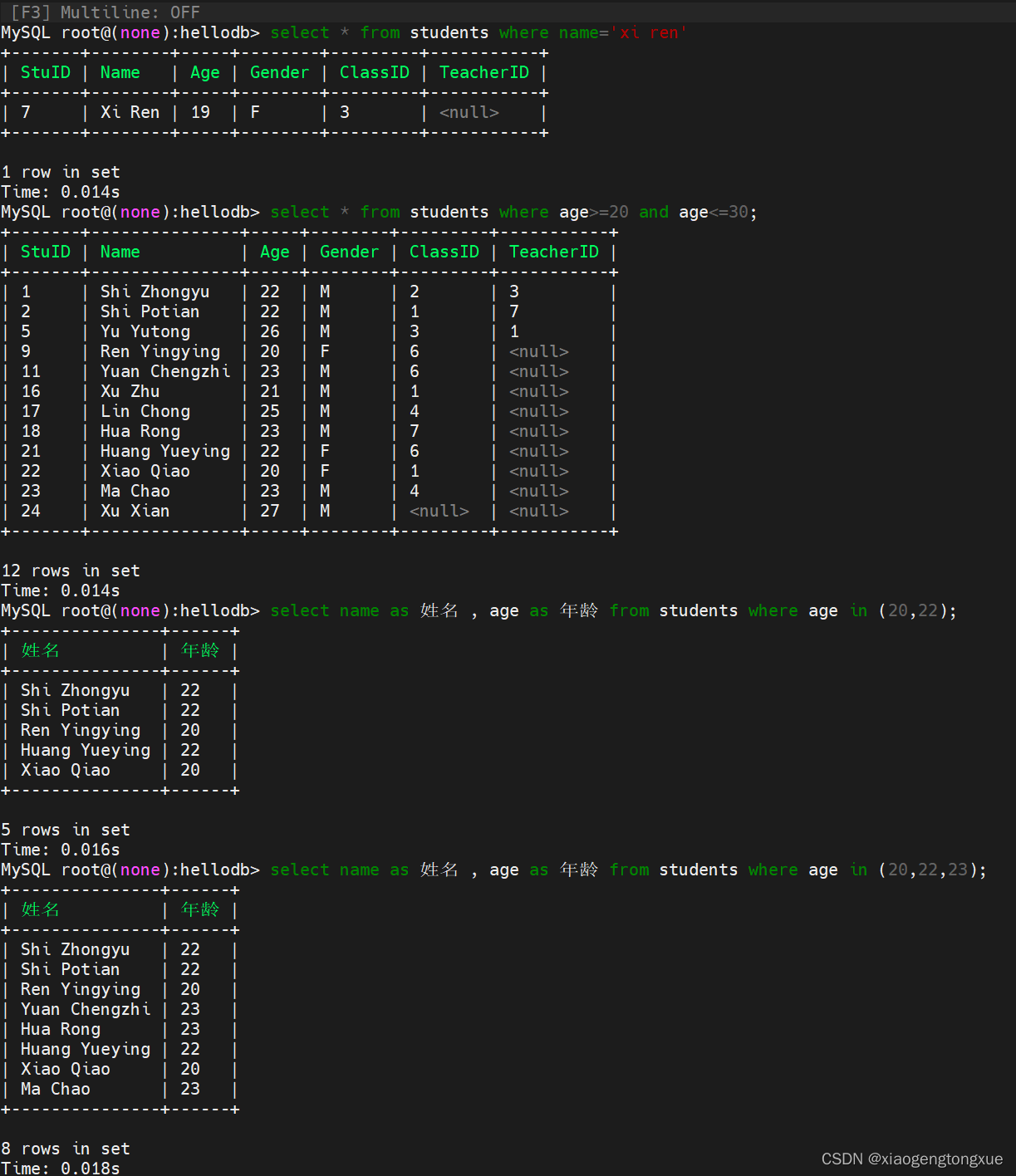
SELECT “字段” FROM “表名” WHERE “条件1” {[AND|OR] “条件2”}+ ;
select * from students where (age >20 and age <30) or age >50; # 20到30之间或大于50
select * from students where age > 50 or age <20; # 大于50或者小于20
select * from students where age > 50 and classid=2; # 年龄大于50 且 班级id 是2的
select * from students where age < 20 and gender="F";
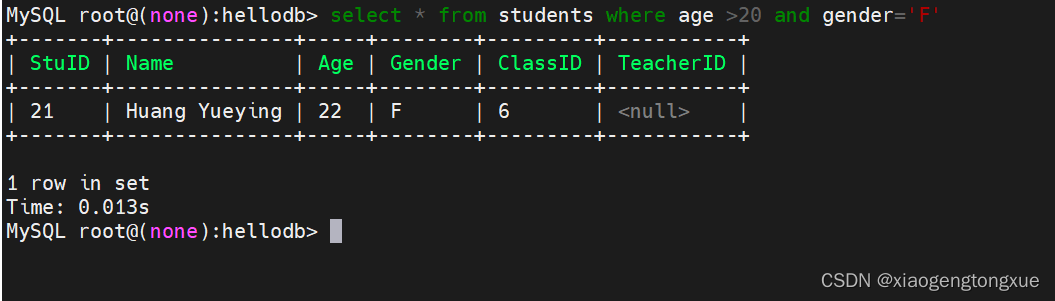
DISTINCT 去除重复行
select age from students;
select distinct age from students; #去重
like 模糊查询与通配符
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符
‘A_Z’:所有以 ‘A’ 起头,另一个任何值的字符,且以 ‘Z’ 为结尾的字符串。
‘ABC%’: 所有以 ‘ABC’ 起头的字符串。
‘%XYZ’: 所有以 ‘XYZ’ 结尾的字符串。
‘%AN%’: 所有含有 'AN’这个模式的字符串。
‘_AN%’:所有第二个字母为 ‘A’ 和第三个字母为 ‘N’ 的字符串。
语法
语法:SELECT "字段" FROM "表名" WHERE "字段" LIKE "匹配表达式";
select * from students where name='xi ren';
精确查找
select * from students where name like 'x%'; 找到X开头的
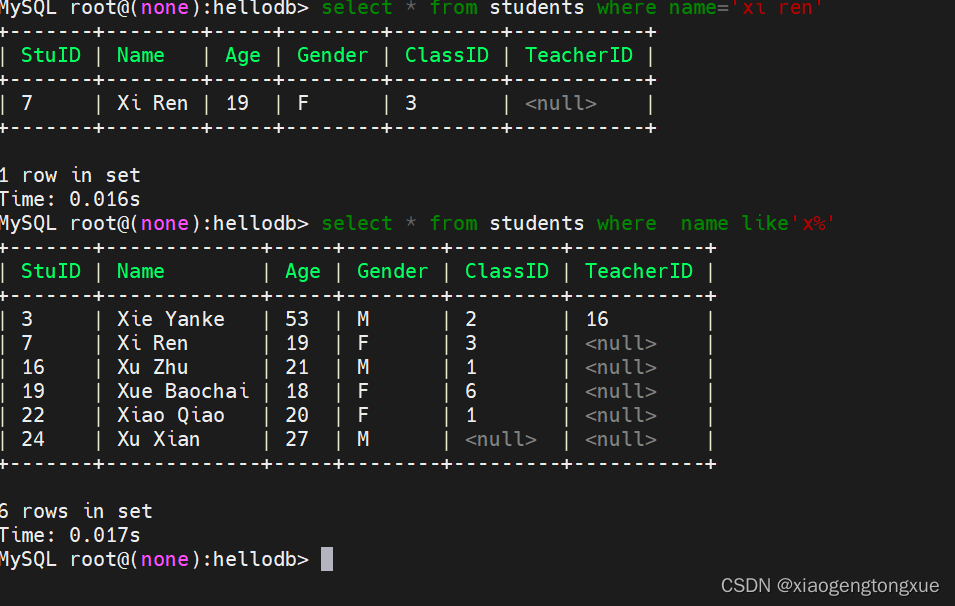
例子:
复制表结构
create table test like students;
sql注入攻击
SQL 注入攻击是一种常见的网络安全攻击方式,它利用应用程序对用户输入数据的不当处理,从而能够修改后端 SQL 语句的执行逻辑,从而获取应用系统的敏感信息或控制应用系统。
具体来说,SQL 注入攻击的原理如下:
1.应用程序在构建 SQL 语句时,将用户的输入直接拼接到 SQL 语句中,而没有进行充分的过滤和转义。
2.攻击者精心构造恶意的输入数据,包含额外的 SQL 语句或语法。
3.当应用程序执行这些拼接好的 SQL 语句时,额外的 SQL 语句或语法会被执行,从而达到攻击的目的。
例如:
一个简单的 SQL 查询语句
SELECT * FROM users WHERE username = '$username' AND password = '$password'
如果 $username 和 $password 变量没有进行充分的过滤,攻击者就可以构造恶意输入,如 ’ OR ‘1’='1 。这样拼接后的查询语句就变成:
SELECT * FROM users WHERE username = '' OR '1'='1' AND password = ''
这个语句会返回所有用户记录,从而绕过身份验证。
函数
数学函数
| 函数名 | 函数值 |
|---|---|
| abs(x) | 返回 x 的绝对值 |
| rand() | 返回 0 到 1 的随机数 |
| mod(x,y) | 返回 x 除以 y 以后的余数 |
| power(x,y) | 返回 x 的 y 次方 |
| round(x ) | 返回离 x 最近的整数 |
| round(x,y) | 保留 x 的 y 位小数四舍五入后的值 |
| sqrt(x) | 返回 x 的平方根 |
| truncate(x,y) | 返回数字 x 截断为 y 位小数的值 |
| ceil(x) | 返回大于或等于 x 的最小整数 |
| floor(x) | 返回小于或等于 x 的最大整数 |
| greatest(x1,x2…) | 返回集合中最大的值,也可以返回多个字段的最大的值 |
| least(x1,x2…) | 返回集合中最小的值,也可以返回多个字段的最小的值 |
select abs(-100); #取绝对值
select rand(); #随机数 0到1 间
select mod(10,3); #10 除3 取余数
select power(2,3) #求2的3次方
select round(2.6); #返回离2.6最近的整数3
select sqrt(9); #返回9 的平方根
select truncate (1.235,2); #返回前两位值
select ceil (1.5); #返回大于等于1.5 的值
select floor (1.5); #返回小于等于1.5 的值
select greatest(1,2,3); #返回集合中的 最大值
select least(1,2,3); #返回集合中的最小值
聚合函数
| 函数名 | 函数意 |
|---|---|
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(x) | 返回指定列的所有值之和 |
语法:
select 函数(*) from 表名; * 代表所有字段
select 函数(单个字段) from 表名;
avg 平均值
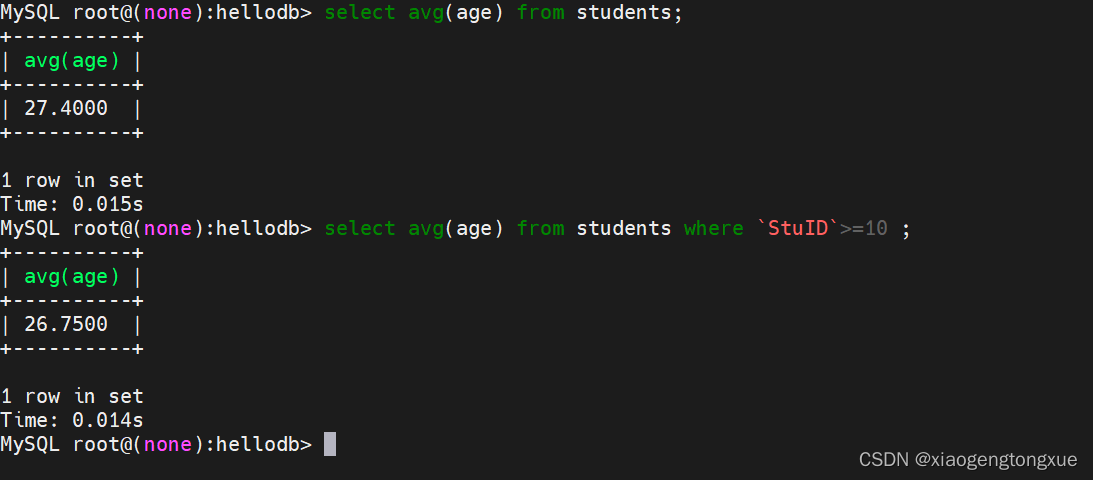
例子:
select avg(age) from students; 所有人的平均值
select avg(age) from students where `StuID`>=10 ;计算students表中stuid大于等于10的平均年龄。
count 返回指定列中非NULL值的个数
select count(classid) from students;
统计非空classid 字段 一共有多少行记录
select count(distinct classid) from students; 一共有几个班级 去重
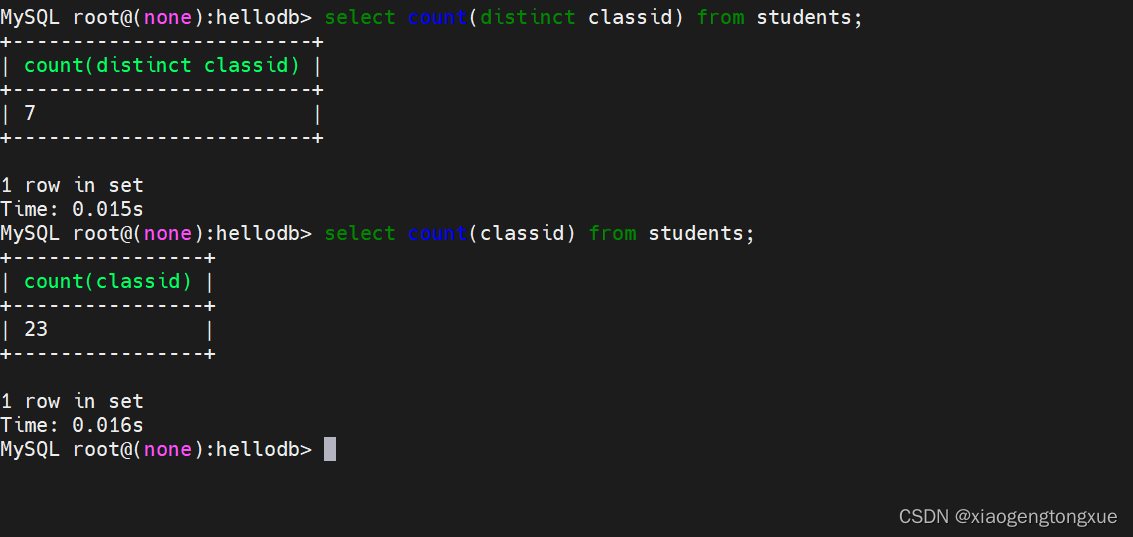
注意:
聚合函数 count()括号中是具体的字段,如果有null 值不统计。count() 括号中是 * 会统计 null。
其他
min最小值
select min(age) from students;
max最大值
select max(age) from students;sum qiuhe
select sum (age) from students; 求年龄总和
select sum(age) from students where classid=1;求1班年龄的总和。
字符串函数
| 函数名 | 函数意义 |
|---|---|
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串, |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
concat
将字段连接在一起
select concat (name,classid) from students where stuid=1将两个字段连接在一起
select concat (name," ",classid) from students where stuid=1将两个字段连接在一起并在中间加上空格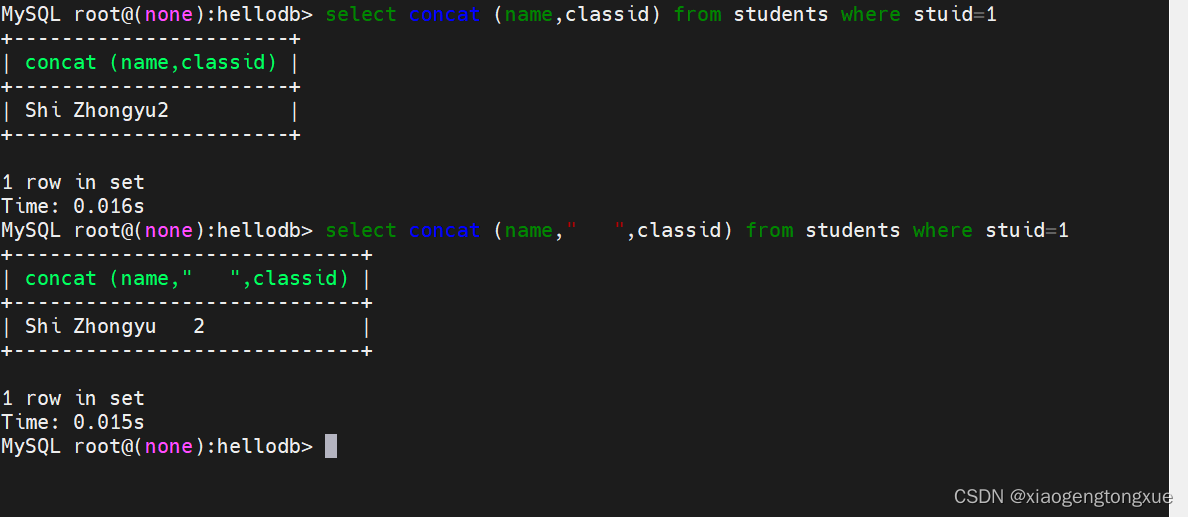
substr
获取字段的前几个字符,作用是去取姓氏什么的。
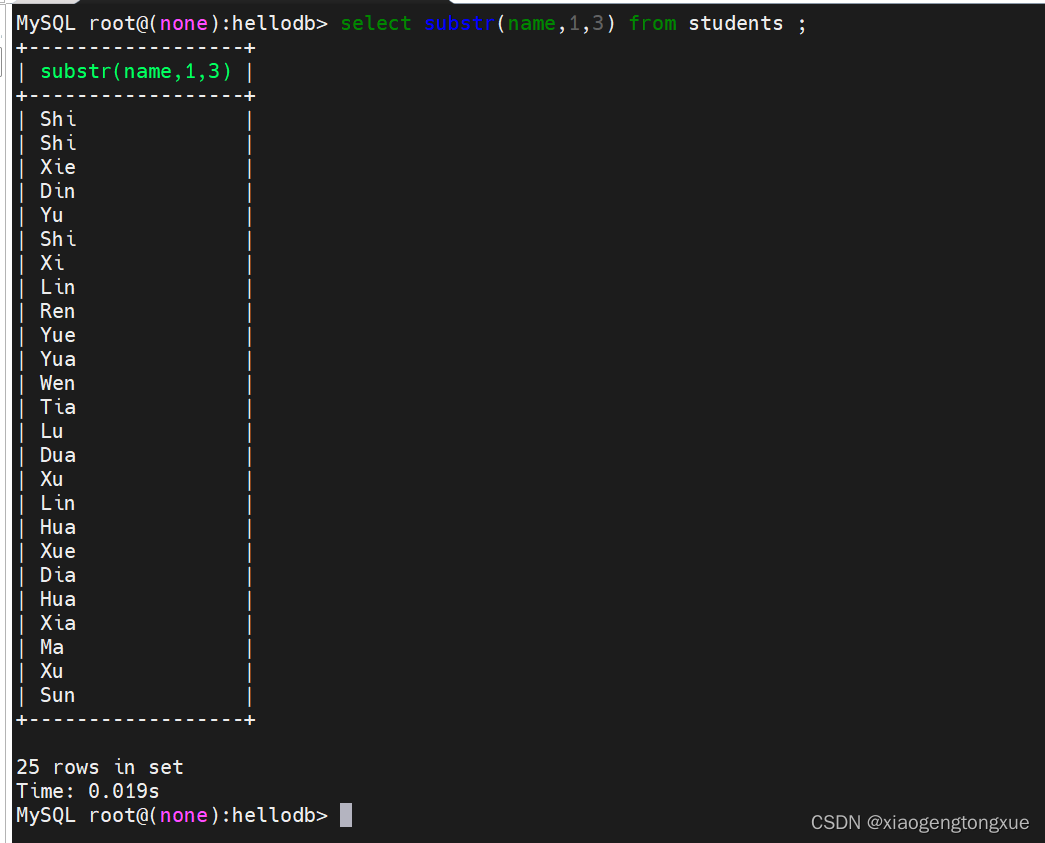
select substr(name,1,3) from students;
获取name 字段的 前1到3 个字符
其他
select length(name) from students where stuid=1;
返回数据的长度
select replace(name,"y",11) from students where stuid=1;
将name 字段中的 y 换成11
select left(name,3) from students where stuid=1;
显示name字段左边三个字符 即最开始的三个
select right(name,3) from students where stuid=1;
显示name字段 右边三个字符 即最后三个
select repeat(name,2) from students where stuid=1;
将name 字段 重复显示2次
select lower(name) from students;
返回结果全是小写字母
select reverse(name) from students where stuid=1;
反向显示字符串
GROUP BY (分组)
对GROUP BY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的GROUP BY 有一个原则,凡是在 GROUP BY 后面出现的字段,必须在 SELECT 后面出现;凡是在 SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在 GROUP BY 后面。
语法
SELECT "字段1", 聚合函数("字段2") FROM "表名" GROUP BY "字段1";
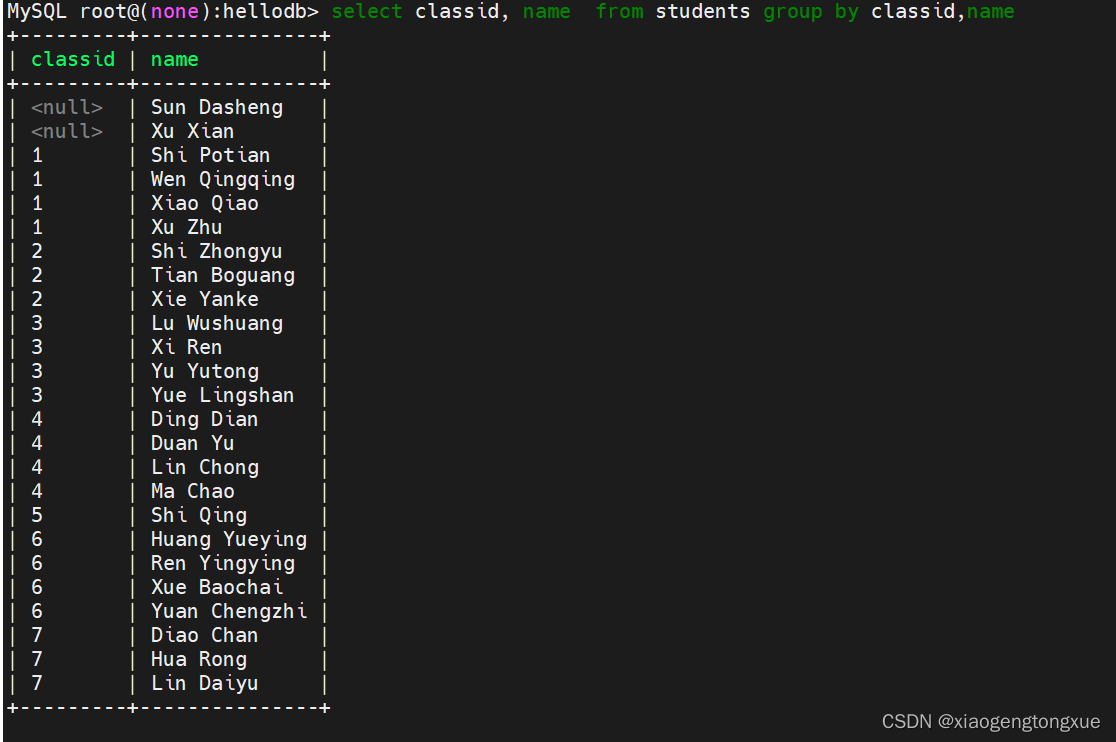
select classid, name from students group by classid,name;
对classid和name字段进行分组。
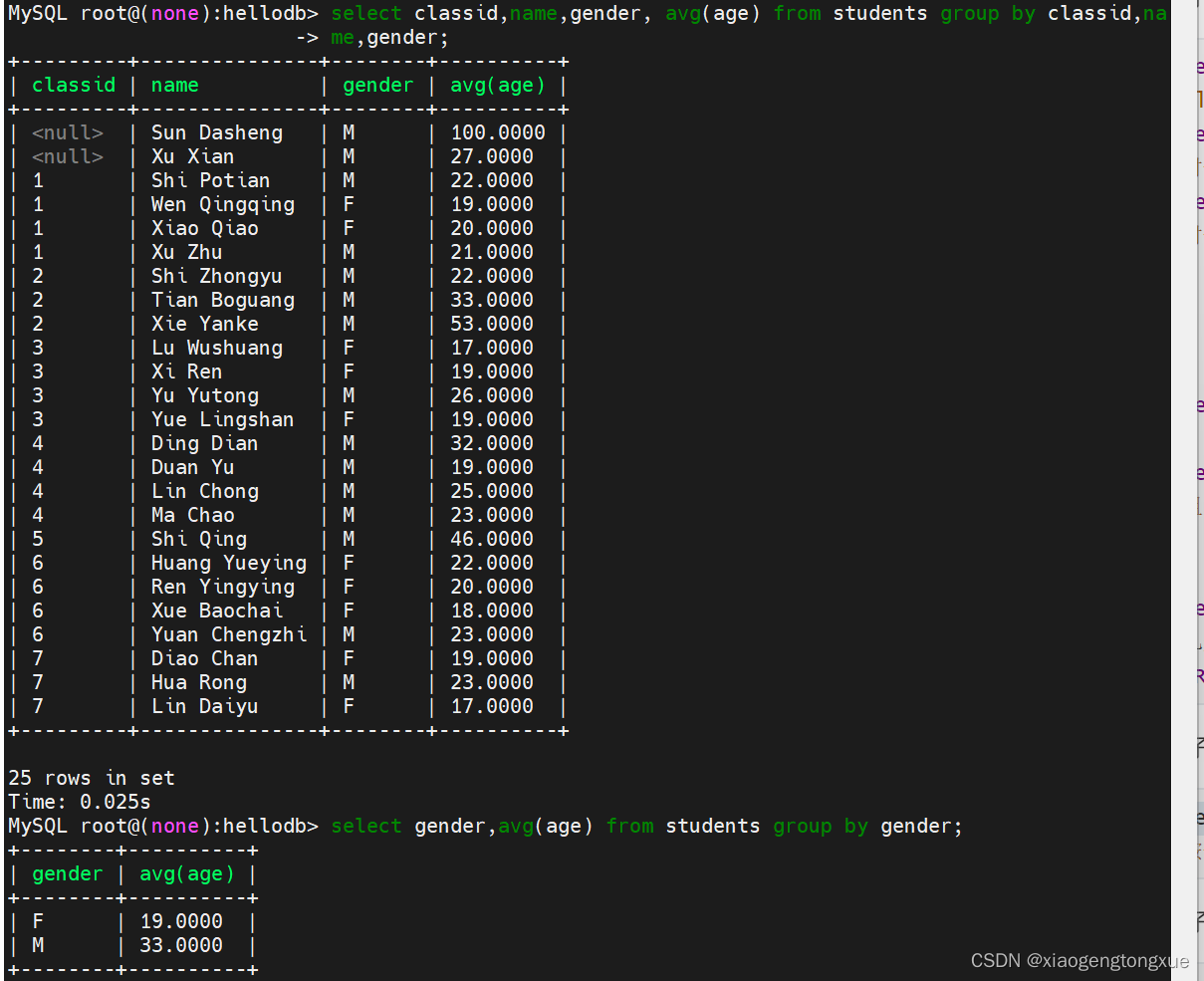
select gender,avg(age) from students group by gender;
按性别分组 求平均值
特别注意:
select classid,count(*) from students group by classid;
凡是在 SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在 GROUP BY 后面。
order by(排序)
语法规则
SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
ASC 是按照升序进行排序的,是默认的排序方式。
DESC 是按降序方式进行排序。
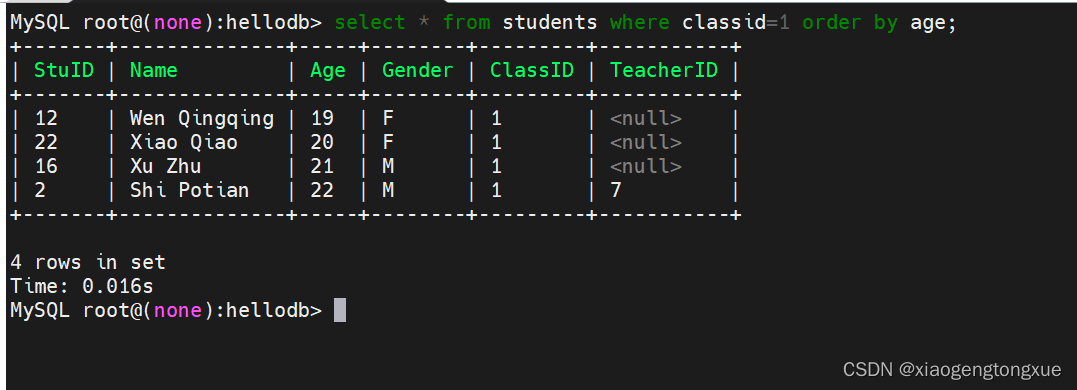
select * from students where classid=1 order by age;
找出一班的人,按照年龄进行升序排序。
limit
LIMIT [[offset,]row_count]
对查询的结果进行输出行数数量限制,跳过offset,显示row_count行,offset默为值为0
select * from students order by age limit 5;
显示表格中前五个小的年龄。
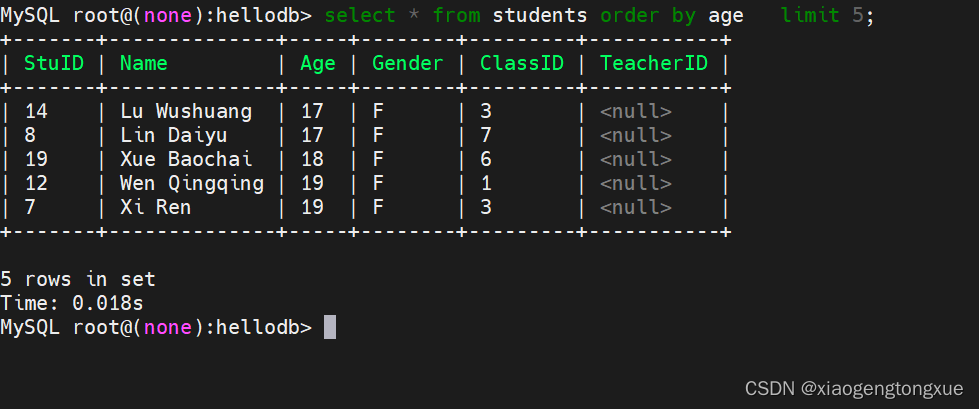
select * from students limit 3,5;
跳过前三个,往后取5个,一个页面可以显示的商品也是靠其实现的。
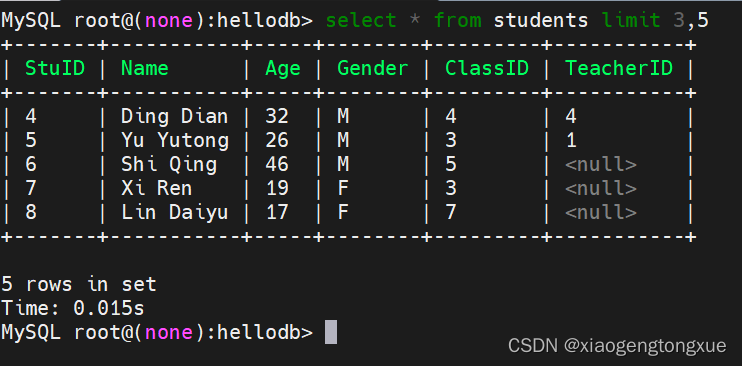
having
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
select classid,count(classid) from students group by classid having classid > 3;
以学生班级排序,统计每个班拥有的学生,并展示4-7班。
select classid,count(classid) from students where classid > 3 group by classid;
此条代码也可以实现。
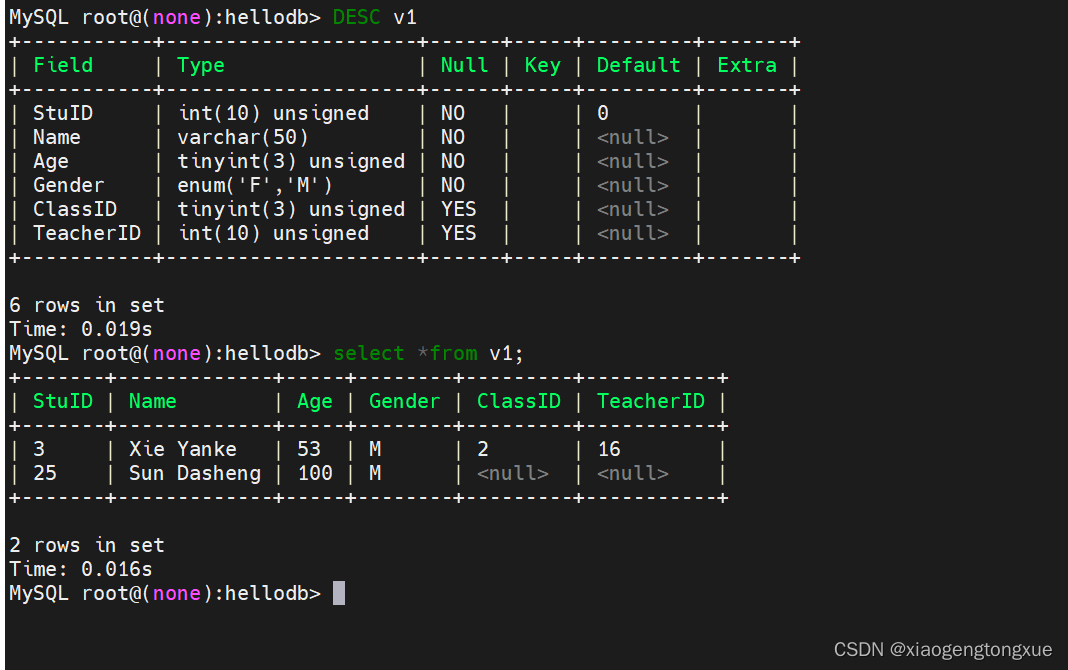
示图view 临时表
视图:数据库中的虚拟表,这张虚拟表中不包含真实数据,只是做了映射。
格式:
create view 视图名 as 查询结果
create view v1 as select * from students where age > 50;
正则表达式
匹配 描述
^ 匹配文本的开始字符
$ 匹配文本的结束字符
. 匹配任何单个字符
* 匹配零个或多个在它前面的字符
+ 匹配前面的字符 1 次或多次字符串 匹配包含指定的字符串
p1|p2 匹配 p1 或 p2
[…] 匹配字符集合中的任意一个字符
[^…] 匹配不在括号中的任何字符
{n} 匹配前面的字符串 n 次
{n,m} 匹配前面的字符串至少 n 次,至多 m 次
{,m} 最多m次
{n,} 最少n次
? 匹配一个字符
在数据库中一般不启用正则表达式,因为一旦启用就会关闭索引查找效率慢。
select name from students where name regexp '^s'
select name from students where name regexp 's';
select name from students where name regexp 's.i';
select name from students where name regexp '^s|l';