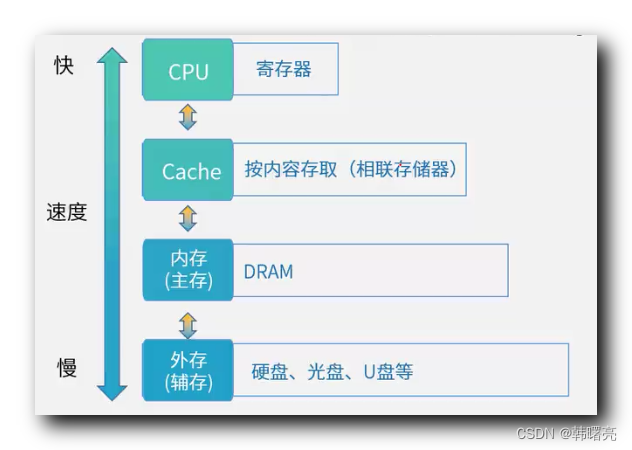
- 趋势分析:折线图
- 静态比较:条形图
- 分布分析:箱线图
- 离散情况:散点图
python">import matplotlib.pylab as plt
from abc import ABC, abstractmethod
import seaborn as sns
import pandas as pd
import plotly.graph_objects as go
import plotly.io as pio
import altair as alt
from bokeh.plotting import figure, output_file, show
from bokeh.io import output_file, show
from bokeh.palettes import Category20c
from bokeh.plotting import figure, show
from bokeh.transform import cumsum
from math import pi
import numpy as np
from bokeh.models import ColumnDataSource
from bokeh.models import ColumnDataSource, DatetimeTickFormatter
import matplotlib.dates as mdates
from colorcet import fire
import plotly.express as px
import holoviews as hv
from holoviews.operation.datashader import datashadeclass PlotStrategy(ABC):# 抽象类:强制子类实现此方法@abstractmethoddef plot(self, x_data, y_data, desc):passclass LineMulPlotStrategy(PlotStrategy):def plot(self, x_data, y_data, desc):print('折线图')plt.clf() # 清除当前图形内容arr_data = [d[list(d.keys())[0]] for d in y_data] # 提取数据arr_key = [list(d.keys())[0] for d in y_data]plt.plot(x_data, arr_data[0], label=arr_key[0])plt.plot(x_data, arr_data[1], label=arr_key[1])plt.xlabel(desc[1])plt.ylabel(desc[2])plt.title(desc[0])plt.legend()# plt.show()plt.savefig('./lineMul.png')class BarMulPlotStrategy(PlotStrategy):def plot(self, x_data, y_data, desc):print('柱状图')plt.clf() # 清除当前图形内容arr_data = [d[list(d.keys())[0]] for d in y_data] # 提取数据arr_key = [list(d.keys())[0] for d in y_data]bar_width = 0.35 # 条形宽度x_offset = 0.2 # 每个条形图的水平偏移量# 绘制第一个条形图# np.arange() 函数的作用是生成一个等差序列的一维数组。# 如果 x_data 是一个有 5 个元素的列表,那么 np.arange(len(x_data)) 将生成一个包含 0、1、2、3、4 的整数数组plt.bar(np.arange(len(x_data)) - x_offset, arr_data[0], width=bar_width, label=arr_key[0])# 绘制第二个条形图plt.bar(np.arange(len(x_data)) + x_offset, arr_data[1], width=bar_width, label=arr_key[1])# plt.bar(x_data, arr_data[0])# plt.bar(x_data, arr_data[1])plt.xlabel(desc[1])plt.ylabel(desc[2])plt.title(desc[0])# plt.show()plt.savefig('./BarMul.png')class BoxMulPlotStrategy(PlotStrategy):def plot(self, x_data, y_data, desc):print('箱线图')plt.clf() # 清除当前图形内容arr_data = [d[list(d.keys())[0]] for d in y_data] # 提取数据arr_key = [list(d.keys())[0] for d in y_data]plt.boxplot(arr_data, tick_labels=arr_key)plt.xlabel(desc[1])plt.ylabel(desc[2])plt.title(desc[0])# plt.show()plt.savefig('./BoxMul.png')class ScatterMulPlotStrategy(PlotStrategy):def plot(self, x_data, y_data, desc):print('散点图')plt.clf() # 清除当前图形内容arr_data = [d[list(d.keys())[0]] for d in y_data] # 提取数据arr_key = [list(d.keys())[0] for d in y_data]plt.scatter(x_data, arr_data[0], label=arr_key[0])plt.scatter(x_data, arr_data[1], label=arr_key[1])plt.xlabel(desc[1])plt.ylabel(desc[2])plt.title(desc[0])# 显示label对应的图例plt.legend()# plt.show()plt.savefig('./ScatterMul.png')class BigDataCSVPlotStrategy(PlotStrategy):def plot(self, x_data, y_data, desc):print('大数据量:Matplotlib + Downsampling')plt.clf() # 清除当前图形内容# 假设 df 是包含股票数据的 DataFrame,且有 'Date' 和 'Close' 列df = pd.read_csv('stock_data.csv', parse_dates=['Date'], index_col='Date')# 确保日期列被正确解析df.index = pd.to_datetime(df.index, format='%Y/%m/%d %H:%M')# 对数据进行重采样,比如按日、周或月df_resampled = df['Close'].resample('D').mean() # 按天重采样并取平均值# 对数据进行重采样,比如按日、周或月df_resampled1 = df['High'].resample('D').mean() # 按天重采样并取平均值plt.figure(figsize=(10, 6))plt.plot(df_resampled.index, df_resampled.values)plt.plot(df_resampled1.index, df_resampled1.values)# 设置横轴日期格式plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=1)) # 按天显示刻度# 自动格式化日期标签以避免重叠plt.gcf().autofmt_xdate()plt.xlabel('Date')plt.ylabel('Close Price')plt.title('Stock Close Price Over Time')# plt.show()plt.savefig('./BigDataCSV_plt.png')class BigDataDatashaderPlotStrategy(PlotStrategy):def plot(self, x_data, y_data, desc):print('大数据量:Datashader')class BigDataPlotlyPlotStrategy(PlotStrategy):def plot(self, x_data, y_data, desc):print('大数据量:Plotly')# 读取 CSV 文件并解析日期df = pd.read_csv('stock_data.csv', parse_dates=['Date'])# 假设 df 是包含股票数据的 DataFramefig = px.line(df, x='Date', y=['Close','High'], title='Stock Close and High Price Over Time')# fig.show()fig.write_html('./BigDataplotly.html')class BigDataBokehPlotStrategy(PlotStrategy):def plot(self, x_data, y_data, desc):print('大数据量:Bokeh')# 读取 CSV 文件并解析日期df = pd.read_csv('stock_data.csv')# 创建 Bokeh 的数据源 ColumnDataSourcesource = ColumnDataSource(df)# 创建 Bokeh 图表对象 figure,并设置图表属性p = figure(title='Stock Prices', x_axis_label='Time', y_axis_label='Price')# 在图表上添加绘图元素(折线图)p.line(x='Date', y='Close', source=source, legend_label='Close', line_width=2, color='blue')p.line(x='Date', y='High', source=source, legend_label='High', line_width=2, color='red')# 添加图例位置p.legend.location = "top_left"# 显示图表output_file("BigDatabokeh.html") # 不显示折现,显示label# show(p)class BigDataHoloviewsPlotStrategy(PlotStrategy):def plot(self, x_data, y_data, desc):print('大数据量:Holoviews')# 读取 CSV 文件并解析日期df = pd.read_csv('stock_data.csv')# 将日期时间字符串转换为 datetime 对象df['Date'] = pd.to_datetime(df['Date'])hv.extension('bokeh')# 假设 df 是包含股票数据的 DataFramecurve = hv.Curve(df, 'Date', ['Close', 'High'])shaded = datashade(curve)hv.save(shaded, 'BigDataHoloviews.html')# Context类持有PlotStrategy的引用。可以通过set_strategy方法动态地更改策略
class Context:def __int__(self, strategy: PlotStrategy):# _ 开头的变量,表示这是一个受保护的变量# 该变量只在类内部及其子类中使用,而不应在类外部直接访问self._strategy = strategydef set_strategy(self, strategy: PlotStrategy):self._strategy = strategydef execute_strategy(self, x_data, y_data, desc):self._strategy.plot(x_data, y_data, desc)x = ['A','B','C','D','E']
y = [{'key1':[2, 3, 6, 1, 4]},{'key2':[1, 2, 3, 4, 5]}]
desc = ['title', 'x', 'y']context = Context()context.set_strategy(LineMulPlotStrategy())
context.execute_strategy(x, y, desc)context.set_strategy(BarMulPlotStrategy())
context.execute_strategy(x, y, desc)context.set_strategy(BoxMulPlotStrategy())
context.execute_strategy(x, y, desc)context.set_strategy(ScatterMulPlotStrategy())
context.execute_strategy(x, y, desc)context.set_strategy(BigDataCSVPlotStrategy())
context.execute_strategy(x, y, desc)# context.set_strategy(BigDataDatashaderPlotStrategy())
# context.execute_strategy(x, y, desc)context.set_strategy(BigDataPlotlyPlotStrategy())
context.execute_strategy(x, y, desc)# context.set_strategy(BigDataBokehPlotStrategy())
# context.execute_strategy(x, y, desc)context.set_strategy(BigDataHoloviewsPlotStrategy())
context.execute_strategy(x, y, desc)折线图
柱状图
箱线图
散点图