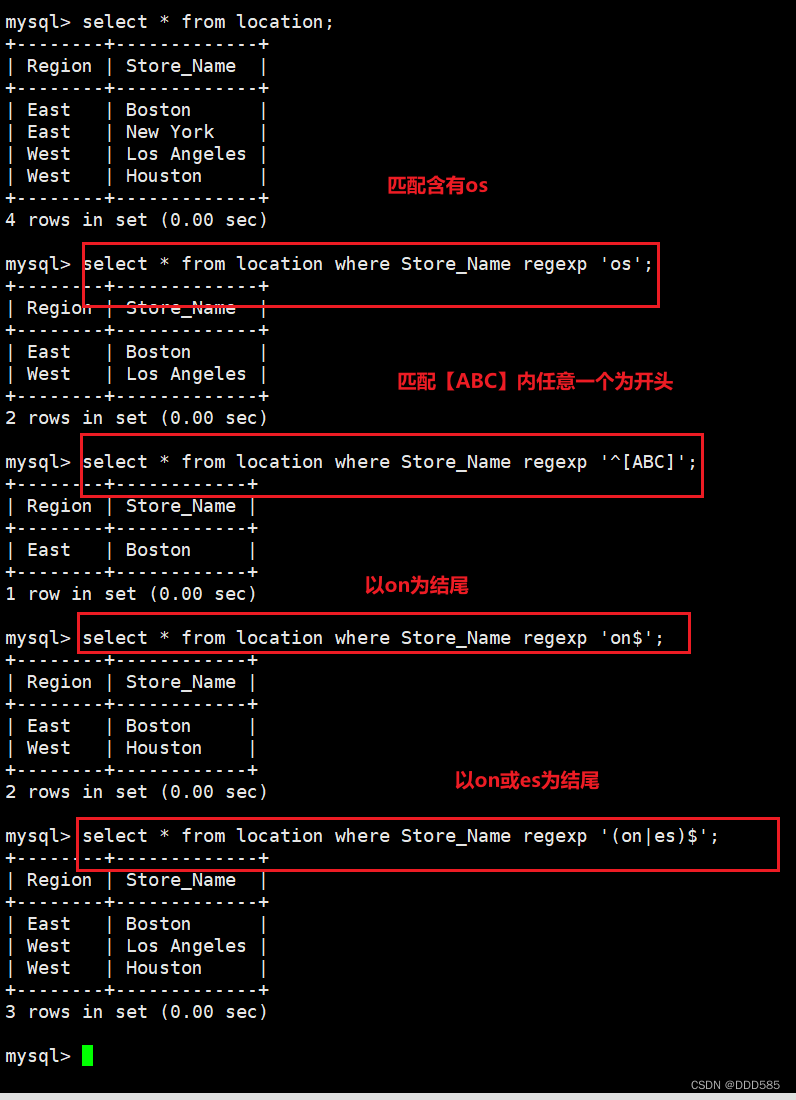
引言
在机器学习的广阔领域中,无监督学习扮演着至关重要的角色。不同于有监督学习,无监督学习处理的是没有标签的数据集,即我们不知道每个数据点的正确答案或分类。然而,这并不意味着无监督学习无法为我们提供有价值的信息。相反,它能够通过发现数据中的内在规律和结构,为我们揭示数据的深层含义。
无监督学习的核心概念
1. 聚类分析
聚类分析是无监督学习中最常用的技术之一。它的目标是将相似的数据点分组在一起,形成不同的簇。每个簇内的数据点具有相似的特征或属性,而不同簇之间的数据点则具有较大的差异。聚类分析不仅可以帮助我们更好地理解数据的分布和结构,还可以用于异常检测、图像分割等任务。
2. 异常检测
异常检测是识别数据集中与大多数数据显著不同的数据点的过程。这些异常值可能是由于错误、噪声或新的、未知的数据生成过程而产生的。异常检测在欺诈检测、网络安全、医疗诊断等领域具有广泛的应用。通过无监督学习的方法,我们可以有效地识别出这些异常值,并采取相应的措施进行处理。
3. 降维
降维是将高维数据转换为低维数据的过程,同时保留数据中的关键信息。在高维数据中,往往存在大量的冗余信息和噪声,这会影响我们对数据的理解和分析。通过降维技术,我们可以将数据投影到一个低维空间中,从而简化数据的表示和计算过程。常见的降维方法包括主成分分析(PCA)、t-SNE等。
无监督学习的应用场景
1. 推荐系统
在推荐系统中,无监督学习可以帮助我们发现用户之间的相似性。通过分析用户的行为和偏好,我们可以将相似的用户划分为一个簇,并为他们推荐可能感兴趣的内容或产品。这种基于用户相似性的推荐方法可以提高推荐的准确性和个性化程度。

2. 社交网络分析
在社交网络分析中,无监督学习可以帮助我们发现用户群体和社区结构。通过分析社交网络中的用户互动和关系,我们可以将具有相似兴趣或行为的用户划分为一个社区,并进一步研究这些社区的特点和演变过程。这对于社交网络优化、个性化服务和舆情分析等方面都具有重要意义。

3. 图像处理
在图像处理中,无监督学习可以用于图像分割、目标检测等任务。通过聚类分析等方法,我们可以将图像中的像素或区域划分为不同的类别,从而实现图像的分割。此外,无监督学习还可以用于发现图像中的关键特征和结构,提高图像处理的准确性和效率。
4. 金融领域
在金融领域,无监督学习可以用于欺诈检测、市场趋势预测等任务。通过异常检测等方法,我们可以识别出异常交易和市场动态,为金融机构提供风险管理和决策支持。此外,无监督学习还可以用于分析金融数据中的模式和结构,为投资决策提供有价值的参考。

总结与展望
无监督学习是机器学习领域的一个重要分支,它能够从无标签的数据中发现数据内在的结构和规律。通过聚类分析、异常检测和降维等方法,我们可以对数据进行深入的分析和挖掘,从而为我们提供关于数据的深刻见解。随着大数据和人工智能技术的不断发展,无监督学习将在更多领域发挥重要作用。未来,我们可以期待无监督学习在图像识别、自然语言处理、生物信息学等领域取得更多的突破和应用。