写在前面
1、基于2022级软件工程/计算机科学与技术实验指导书
2、成品仅提供参考
3、如果成品不满足你的要求,请寻求其他的途径
运行环境
window11家庭版
Navicat Premium 16
Mysql 8.0.36
实验要求
在实验三的基础上完成下列查询:
1、查询医生“陈斌”值班的日期、时段、诊室名称、诊室位置。
2、查询级别名称为 “二级专家”的医生姓名、诊疗费用、科室名称。
3、查询在2022年4月18一天中上午、下午均值班的医生的工作证号。
4、查询在2022年4月18和4月19日两天均未值班的医生的工作证号、姓名、科室名称。
5、查询每个科室的科室编码及医生人数(要求按科室编码分组)。
6、查询科室级别为”2”的每个科室的科室编码及医生人数(要求按科室编码分组)。
7、查询各个医生级别的级别编码、级别名称及其人数。(要求只按医生级别分组,统计人数建议用派生表)
8、查询每个医生的工作证号、姓名和值班次数。(半天算值班1次,要求只按工作证号分组,统计次数建议用派生表实现)
实验过程
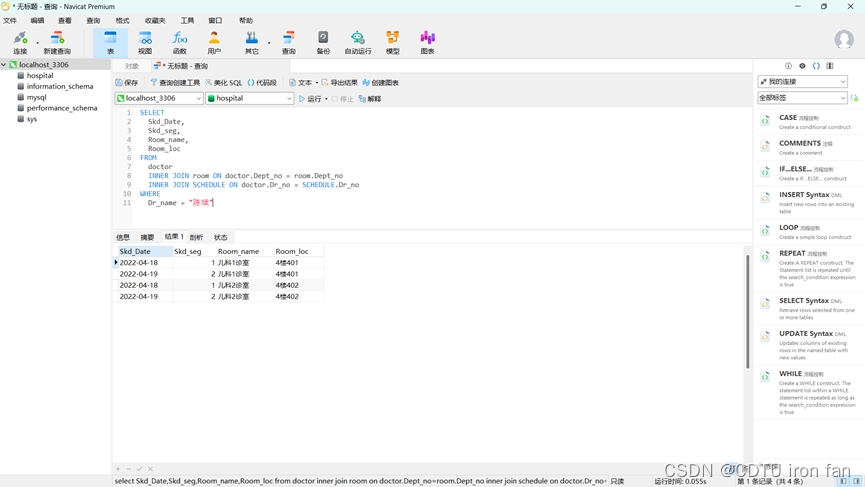
1、查询医生“陈斌”值班的日期、时段、诊室名称、诊室位置。
SELECTSkd_Date,Skd_seg,Room_name,Room_loc
FROMdoctorINNER JOIN room ON doctor.Dept_no = room.Dept_noINNER JOIN SCHEDULE ON doctor.Dr_no = SCHEDULE.Dr_no
WHEREDr_name = "陈斌"
2、查询级别名称为 “二级专家”的医生姓名、诊疗费用、科室名称。
SELECTDr_name,Drlv_fee,Room_name
FROMdoctorINNER JOIN doctorlevel ON doctor.Drlv_no=doctorlevel.Drlv_noINNER JOIN room ON doctor.Dept_no = room.Dept_noWHEREDrlv_name = "二级专家"

3、查询在2022年4月18一天中上午、下午均值班的医生的工作证号。
SELECTDr_no
FROM
SCHEDULE
WHEREdate( Skd_Date )= "2022-4-18"
GROUP BYDr_no
HAVINGcount(*)>1

4、查询在2022年4月18和4月19日两天均未值班的医生的工作证号、姓名、科室名称。
SELECTdoctor.Dr_no,Dr_name,Dept_name
FROMdoctorINNER JOIN SCHEDULE ON doctor.Dr_no = SCHEDULE.Dr_noINNER JOIN department ON doctor.Dept_no = department.Dept_no
GROUP BYdoctor.Dr_no
HAVINGcount(*)=0

5、查询每个科室的科室编码及医生人数(要求按科室编码分组)。
SELECTdepartment.Dept_no,COUNT(Dr_no)
FROMdepartmentINNER JOIN doctor ON department.Dept_no = doctor.Dept_no
GROUP BYDept_no

6、查询科室级别为”2”的每个科室的科室编码及医生人数(要求按科室编码分组)。
SELECTdepartment.Dept_no,COUNT(Dr_no)
FROMdepartmentINNER JOIN doctor ON department.Dept_no = doctor.Dept_noWHERE Dept_level=2
GROUP BYDept_no

7、查询各个医生级别的级别编码、级别名称及其人数。(要求只按医生级别分组,统计人数建议用派生表)
SELECTdoctorlevel.Drlv_no,Drlv_name,COUNT( Dr_no ) AS Dr_num
FROMdoctorlevelINNER JOIN doctor ON doctorlevel.Drlv_no = doctor.Drlv_no
GROUP BY
doctorlevel.Drlv_no;

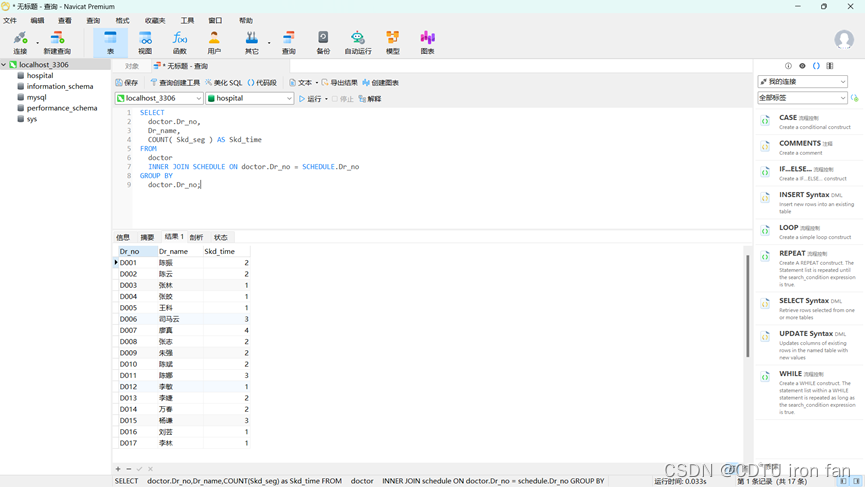
8、查询每个医生的工作证号、姓名和值班次数。(半天算值班1次,要求只按工作证号分组,统计次数建议用派生表实现)
SELECTdoctor.Dr_no,Dr_name,COUNT( Skd_seg ) AS Skd_time
FROMdoctorINNER JOIN SCHEDULE ON doctor.Dr_no = SCHEDULE.Dr_no
GROUP BYdoctor.Dr_no;