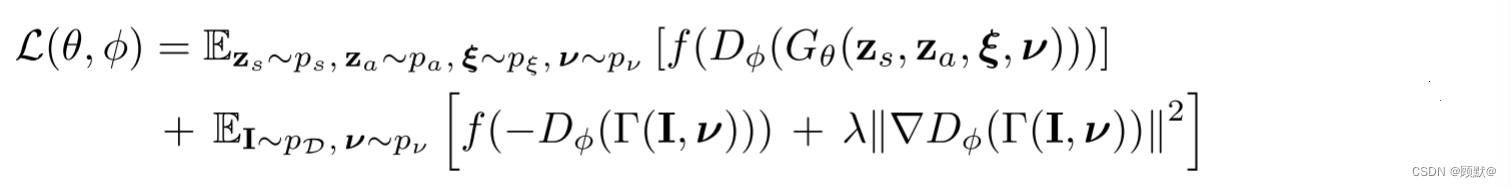1.define和const的区别?
(1)define 是预处理指令,用于创建符号常量。const 是 C 和 C++ 的关键字,用于创建具有常量值的变量,本质是只读变量。
(2)define 在预处理阶段执行。const 在编译阶段执行。
(3)define 没有类型检查,仅进行文本替换。const 有类型检查,可以与变量类型关联。
2.数组和链表的区别?
(1)数组内存连续,链表内存不连续。
(2)数组访问速度比链表快
(3)链表增加删除操作比数组快
3.指针和引用的区别?
(1)指针:指针是地址,而指针变量是保存着内存地址的变量。
引用:引用是已存在变量的别名,没有自己的内存地址。
(2)指针变量可以具有空值(NULL),引用不能为空,必须在初始化时指向一个有效的对象。
(3)可以修改指针变量的指向,可以将指针变量重新赋值为另一个地址。一旦引用被初始化,它始终指向同一个对象,不可更改。
(4)指针变量需要额外的内存空间来存储地址值。引用不需要额外的内存空间,因为它是对已存在变量的别名。
4. 什么是野指针,什么情况会产生野指针?
什么是野指针
指向已被释放或无效的内存地址的指针是野指针。
什么情况下产生野指针
(1)内存释放后未置空指针
int *ptr = (int*)malloc(sizeof(int));
free(ptr);
*ptr = 10; // 这里ptr成为了野指针(2)返回局部变量的指针
int* getIntPointer()
{ int num = 5; return # // 返回局部变量的指针
}int *ptr = getIntPointer();
*ptr = 10; // getIntPointer返回一个野指针(3)未初始化指针
char* p;5.数组和指针的区别
数组是一块连续的内存空间,其大小在编译时确定,访问元素使用下标操作;而指针变量是一个变量,存储地址值,大小固定,可以指向不同类型的数据,通过解引用操作访问内存中的数据。
6.如何防止重复引用头文件
(1)使用预处理指令
#ifndef HEADER_FILE_NAME_H#define HEADER_FILE_NAME_H// 想要包含的头文件内容#endif // HEADER_FILE_NAME_H(2)使用#pragma once
7. 栈和队列的区别?
(1)栈是后进先出的数据结构,而队列是先进先出的数据结构。
(2)栈常用于表达式求值、函数调用的调用栈、括号匹配等需要后进先出的场景。队列常用于任务调度、缓冲区管理、消息传递等需要先进先出的场景。
8.static的作用?
控制变量生命周期,控制作用域,控制文件可见性
9.C语言中的内存分配方式有几种?
(1)静态内存分配
(2)栈上内存分配
(3)堆上内存分配
10.struct和class的区别
(1)默认访问权限不同,struct的默认访问权限是public,class的默认访问权限是private。
(2)继承方式不同,struct的默认继承方式是公有继承,class的继承访问是私有继承。
(3)在一般情况下,struct被用于表示数据结构,而class则更多用于表示具有行为和数据的对象。
11.怎么判断链表是否有环?
使用快慢指针。
思路:
(1)创建两个指针,一个指针称为快指针(fast),另一个指针称为慢指针(slow),初始时都指向链表的头节点。
(2)快指针每次向前移动两个节点,慢指针每次向前移动一个节点。
(3)如果链表中存在环,那么快指针和慢指针最终会相遇。
(4)如果链表中不存在环,那么快指针最终会先到达链表尾部,此时可以判断链表无环。
12.new和malloc的区别?
(1)new是C++中的关键字,malloc是标准库中的函数。
(2)使用new创建对象会调用构造函数,使用malloc创建对象不会调用构造函数。
(3)使用new不需要指定对象的大小,使用malloc需要指定对象的大小。
(4)new返回的是一个对象的指针,malloc返回的是void*
13.可执行程序生成的过程?
预处理-编译-汇编-链接
14. 内联函数和宏函数的区别
(1)内联函数在编译时展开,而宏函数在预处理时展开。
(2)内联函数会进行错误检查,宏函数是直接替换不会进行错误检查。
(3)内联函数可以进行调试,宏函数无法进行调试。
(4)内联函数有作用域规则,只能在定义它的源文件内使用,不能被其他源文件调用。而宏函数没有作用域限制,可以在整个程序中使用。
15. C语言中struct和C++中struct的区别?
(1)C++中的struct可以支持继承,C语言中的struct不支持继承。
(2)C++中的struct可以包含成员函数,C语言中的struct不可以包含成员函数。
16.volatile的本质和作用?
volatile的本质是防止编译器对所修饰的变量进行优化。
(1)使用 volatile 可以确保编译器每次访问变量值时都从内存中读取或写入,而不是从寄存器的缓存中获取值。
(2)处理并发访问和中断:在多线程或多进程环境中,多个线程或进程可能同时访问共享的变量。
17.什么是大小端?
大小端(Endian)指的是在计算机存储和处理多字节数据时,字节的存储顺序。
-
大端序(Big Endian):高位字节存储在低地址,低位字节存储在高地址。类似于将数字的高位放在左边,低位放在右边的表示方式。例如整数值
0x12345678在内存中按照大端序排列为12 34 56 78。 -
小端序(Little Endian):低位字节存储在低地址,高位字节存储在高地址。类似于将数字的低位放在左边,高位放在右边的表示方式。例如整数值
0x12345678在内存中按照小端序排列为78 56 34 12。
18. 判断系统大小端?
在C语言中,可以使用联合(union)的特性来判断系统的大小端(Big Endian 或 Little Endian)。
#include <stdio.h>union EndianCheck
{int i;char c[sizeof(int)];
};int main()
{union EndianCheck ec;ec.i = 1;if (ec.c[0] == 1) {printf("Little Endian\n");} else {printf("Big Endian\n");}return 0;
}19.define和typedef的区别?
(1)define 用于创建宏定义,在预处理时进行简单的文本替换。
(2)typedef 用于创建类型别名,在编译时进行类型检查,并为已有类型创建新的名称。
(3)define 是预处理指令,typedef 是关键字。
(4)define 不会进行类型检查,而 typedef 会。
(5)typedef 在定义新类型时更为灵活和安全。
20.什么是交叉编译?
交叉编译(Cross-compilation)是指在一台计算机上使用特定的编译工具链将代码编译成目标平台上可执行的程序或库。
21.static和const的区别?
可变性
22.构造函数能否是虚函数?
构造函数不能被声明为虚函数。
23.析构函数能否是虚函数?
析构函数可以被声明为虚函数。