目录
1.归并排序
1.1二路归并操作的功能
1.2算法思想
1.3代码分析
1.4性能分析
2.基数排序
2.1算法思想
2.2基数排序的中间过程的分析
2.3性能分析
3.计数排序
3.1算法思想
3.2代码分析
3.3性能分析
知识回顾
1.归并排序
1.1二路归并操作的功能
归并排序与上述基于交换、选择等排序的思想不一样,归并的含义是将两个或两个以上的有序表合并成一个新的有序表。
假定待排序表含有n个记录,则可将其视为n个有序的子表,每个子表的长度为1,然后两两归并,得到个长度为 2 或 1 的有序表;
继续两两归并……如此重复,直到合并成一个长度为n的有序表为止,这种排序算法称为二路归并排序。
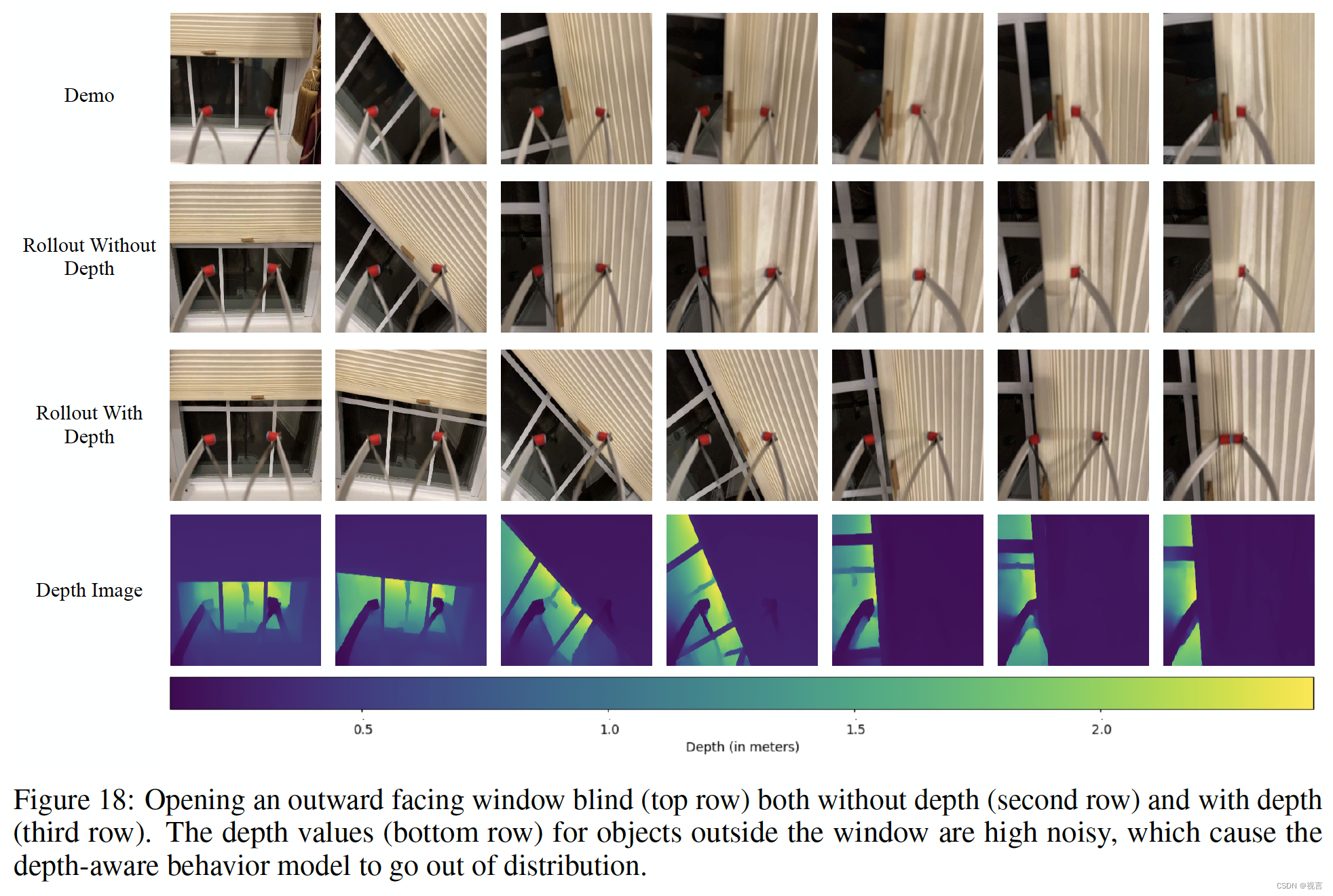
图8.9所示为二路归并排序的一个例子,经过三趟归并后合并成了有序序列。
1.2算法思想
Merge()的功能是将前后相邻的两个有序表归并为一个有序表。
设两段有序表 A[low..mid]、A[mid+1..high]存放在同一顺序表中的相邻位置,先将它们复制到辅助数组 B中。
每次从B的两段中取出一个记录进行关键字 的比较,将较小者放入中,当B中有一段的下标超出其对应的表长(即该段的所有元素都已复制到中)时,将另一段的剩余部分直接复制到A中。
1.3代码分析
算法如下:
ElemType *B=(ElemType *)malloc((n+1)*sizeof(ElemType));//辅助数组 B
void Merge(ElemType A[],int low,int mid,int high){
//表A的两段A[low..mid]和a[mid+1..high]各自有序,将它们合并成一个有序表int i,j,k;for(k=low;k<=high;k++)B[k]=A[k]; //将A中所有元素复制到B中for(i=low,j=mid+1,k=i;i<=mid && j<=hiqh;k++){if(B[i]<=B[j]) //比较B的两个段中的元素A[k]=B[i++]; //将较小值复制到A中elseA[k]=B[j++];}while(i<=mid) A[k++]=B[i++]; //若第一个表未检测完,复制while(j<=high) A[k++]=B[j++]; //若第二个表未检测完,复制
}注意:在上面的代码中,最后两个 while 循环只有一个会执行。
一趟归并排序的操作是,调用次算法 merge(),将 L[1..n]中前后相邻且长度为h的有序段进行两两归并,得到前后相邻、长度为2h的有序段,整个归并排序需要进行
趟。
递归形式的二路归并排序算法是基于分治的,其过程如下。
- 分解:将含有n个元素的待排序表分成各含n/2个元素的子表,采用二路归并排序算法对两个子表递归地进行排序。
- 合并:合并两个已排序的子表得到排序结果。
void MergeSort(ElemType A[],int low,int high){if(low<high){int mid=(low+high)/2; //从中间划分两个子序列MergeSort(A,low,mid); //对左侧子序列进行递归排序MergeSort(A,mid+1,high); //对右侧子序列进行递归排序Merge(A,low,mid,high); //归并}
}
1.4性能分析
二路归并排序算法的性能分析如下:
空间效率:Merge()操作中,辅助空间刚好为n个单元,因此算法的空间复杂度为O(n)。
时间效率:每趟归并的时间复杂度为 O(n),共需进行
趟归并,因此算法的时间复杂度为
。
稳定性:由于 Merge()操作不会改变相同关键字记录的相对次序,因此二路归并排序算法是一种稳定的排序算法。
适用性:归并排序适用于顺序存储和链式存储的线性表。
注意:一般而言,对于N个元素进行 k 路归并排序时,排序的趟数 m 满足
,从而
,又考虑到 m 为整数,因此
。这和前面的二路归并排序算法是一致的。
2.基数排序
2.1算法思想
基数排序是一种很特别的排序算法,它不基于比较和移动进行排序,而基于关键字各位的大小进行排序。
基数排序是一种借助多关键字排序的思想对单逻辑关键字进行排序的方法。
假设长度为 n 的线性表中每个结点 的关键字由 d 元组
组成,满足(0≤j<n,0≤i≤d-1)。
其中为最主位关键字,
为最次位关键字。
为实现多关键字排序,通常有两种方法:
- 第一种是最高位优先(MSD)法,按关键字位权重递减依次逐层划分成若干更小的子序列,最后将所有子序列依次连接成一个有序序列;
- 第二种是最低位优先(LSD)法,按关键字位权重递增依次进行排序,最后形成一个有序列。
下面描述以 r 为基数的最低位优先基数排序的过程,在排序过程中,使用 r 个队列 Q0,Q1…Qr-1。基数排序的过程如下:
对 i=0,1.,d-1,依次做一次分配和收集(其实是一次稳定的排序过程)。
① 分配:开始时,把Q0,Q1…Qr-1各个队列置成空队列,然后依次考察线性表中的每个结
点 (j=0,1,…,n-1),若
的关键字
,就把
放进
队列中。
② 收集:把Q0,Q1…Qr-1各个队列中的结点依次首尾相接,得到新的结点序列,从而组成新的线性表。
2.2基数排序的中间过程的分析
通常采用链式基数排序,假设对如下10个记录进行排序:

每个关键字是 1000 以下的正整数,基数r=10,在排序过程中需借助 10 个链队列,每个关键字由3位子关键字构成--K¹K²K³,分别代表百位、十位和个位,一共进行三趟“分配”和“收集”操作。
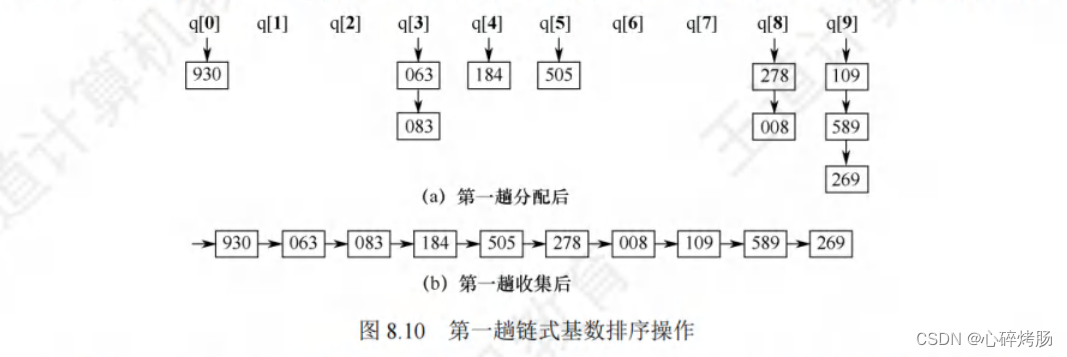
第一趟分配用最低位子关键字K³进行,将所有最低位子关键字(个位)相等的记录分配到同一个队列,如图8.10(a)所示,然后进行收集操作。
第一趟收集后的结果如图 8.10(b)所示。
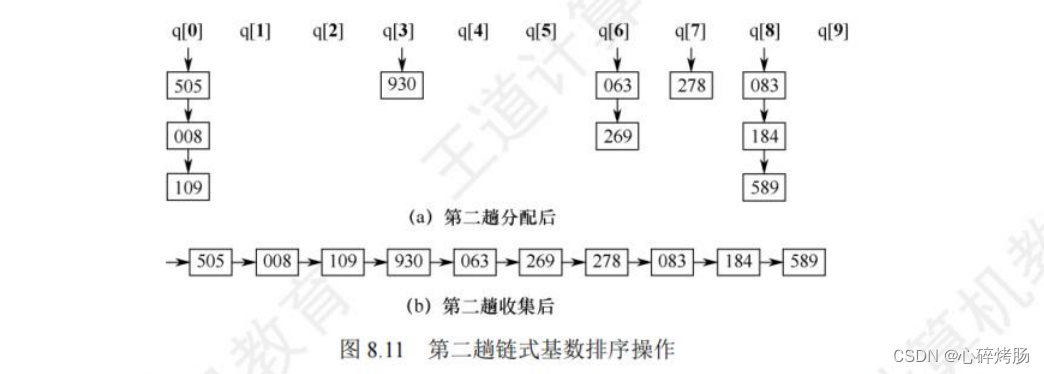
第二趟分配用次低位子关键字K²进行,将所有次低位子关键字(十位)相等的记录分配到同一个队列,如图 8.11(a)所示。
第二趟收集后的结果如图 8.11(b)所示。
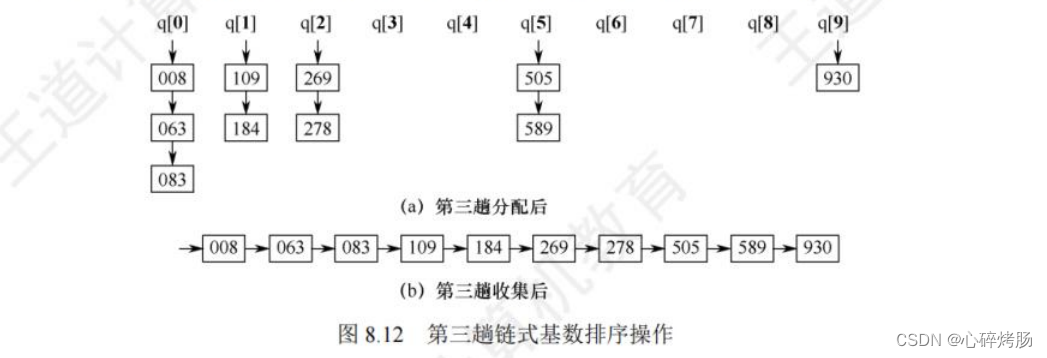
第三趟分配用最高位子关键字K¹进行,将所有最高位子关键字(百位)相等的记录分配到同一个队列,如图8.12(a)所示,
第三趟收集后的结果如图 8.12(b)所示,至此整个排序结束。
2.3性能分析
基数排序算法的性能分析如下。
空间效率:一趟排序需要的辅助存储空间为r (r个队列:r个队头指针和r个队尾指针),但以后的排序中会重复使用这些队列,所以基数排序的空间复杂度为O(r)。
时间效率:
- 基数排序需要进行 d趟“分配”和”收集”操作。
- 一趟分配需要遍历所有关键字,时间复杂度为 O(n);
- 一趟收集需要合并r个队列,时间复杂度为 O(r)。
- 因此基数排序的时间复杂度为 O(d(n+r)),它与序列的初始状态无关。
稳定性:每一趟分配和收集都是从前往后进行的,不会交换相同关键字的相对位置,因此基数排序是一种稳定的排序算法。
适用性:基数排序适用于顺序存储和链式存储的线性表。
3.计数排序
3.1算法思想
计数排序的思想是:对每个待排序元素x,统计小于x的元素个数,利用该信息就可确定x的最终位置。
例如,若有8个元素小于x,则x就排在第9号位置上。当有几个元素相同时,该排序方案还需做一定的优化。
注意:计数排序并不在统考大纲的范围内,但其排序思想在历年真题中多次涉及。
在计数排序算法的实现中,假设输入是一个数组 A[n],序列长度为 n,我们还需要两个数组:B[n]存放输出的排序序列,C[k]存储计数值。
用输入数组A中的元素作为数组C的下标(索引),而该元素出现的次数存储在该元素作为下标的数组C中。
3.2代码分析
算法如下:
void CountSort (ElemType A[],ElemType B[],int n,int k){int i,C[k];for(i=0;i<k;i++)C[i]=0; //初始化计数数组for(i=0;i<n;i++) //遍历输入数组,统计每个元素出现的次数C[A[i]]++; //C[A[i]]保存的是等于A[i]的元素个数for(i=1;i<k;i++)C[i]=C[i]+C[i-1]; //c[x]保存的是小于或等于x的元素个数for(i=n-l;i>=0;i--){ //从后往前遍历输入数组B[C[A[i]-1]]=A[i]; //将元素A[i]放在输出数组B[]的正确位置上C[A[i]]=C[A[i]]-1;}
}第一个 for 循环执行完后,数组C的值初始化为 0。
第二个 for 循环遍历输入数组 ,若一个输入元素的值为 x,则将C[x]值加 1,该 for 循环执行完后,C[x]中保存的是等于x的元素个数。
第三个 for 循环通过累加计算后,C[x]中保存的是小于或等于x的元素个数。
第四个 for 循环从后往前遍历数组 A,把每个元素 A[i] 放入它在输出数组B的正确位置上。
若数组 A中不存在相同的元素,则 C[A[i]]-1 就是 A[i] 在数组 B 中的最终位置,这是因为共有 C[A[i]]个元素小于或等于 A[i]。
若数组A中存在相同的元素,将每个元素 A[i] 放入数组 B[] 后,都要将 C[A[i]]减 1,这样,当遇到下一个等于A[i]的输入元素(若存在)时,该元素就可放在数
组B中 A[i] 的前一个位置上。
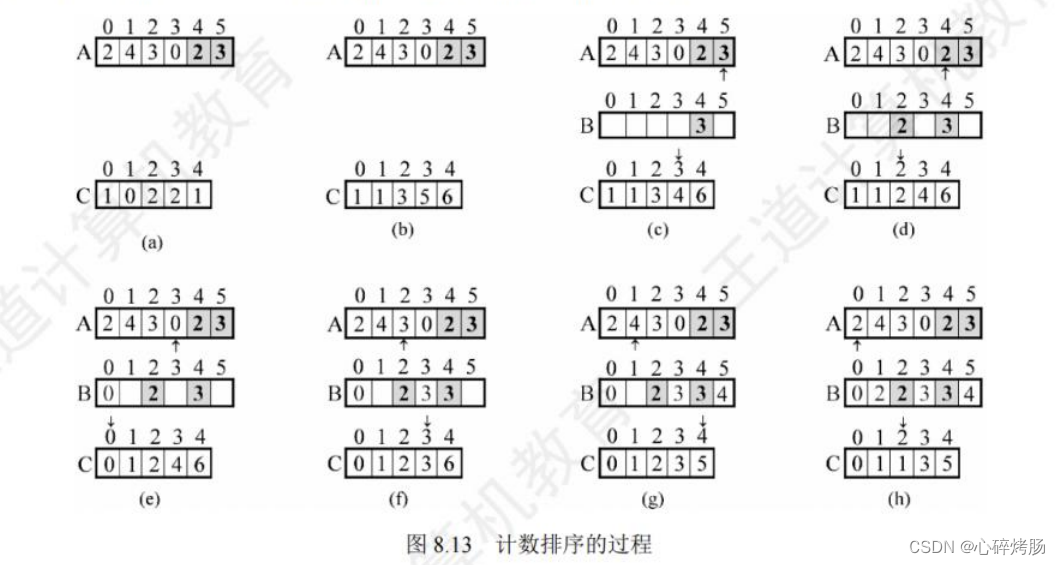
假设输入数组A[ ]={2,4,3,0,2,3},第二个for 循环执行完后,辅助数组C的情况如图8.13(a)所示;
第三个 for 循环执行完后,辅助数组C的情况如图 8.13(b)所示。
图 8.13(c)至图 8.13(h)分别是第四个 for 循环每迭代一次后,输出数组B和辅助数组C的情况。
由上面的过程可知,计数排序的原理是:数组的索引(下标)是递增有序的,通过将序列中的元素作为辅助数组的索引,其个数作为值放入辅助数组,遍历辅助数组来排序。
3.3性能分析
计数排序算法的性能分析如下。
空间效率:计数排序是一种用空间换时间的做法。
- 输出数组的长度为n;
- 辅助的计数数组的长度为 k,空间复杂度为 O(n+k)。
- 若不把输出数组视为辅助空间,则空间复杂度为 O(k)。
时间效率:
- 上述代码的第1个和第3个for 循环所花的时间为 O(k),
- 第2个和第4个 for 循环所花的时间为 O(n),
- 总时间复杂度为 O(n+ k)。
- 因此,当 k=O(n) 时,计数排序的时间复杂度为O(n);
- 但当 k>O(nlog₂n)时,其效率反而不如一些基于比较的排序(如快速排序、堆排序等)。
稳定性:上述代码的第4个 for 循环从后往前遍历输入数组,相同元素在输出数组中的相对位置不会改变,因此计数排序是一种稳定的排序算法。
适用性:计数排序更适用于顺序存储的线性表。计数排序适用于序列中的元素是整数且元素范围(0~k-1)不能太大,否则会造成辅助空间的浪费。
知识回顾


![[数据集][图像分类]茶叶叶子病害分类数据集304张4类别](https://img-blog.csdnimg.cn/direct/93319603e46f4b8f8b626fcb5291e56c.png)